




本文为杭州悦数 GenAI 负责人古思为在“标准+智能:新质生产力的原动力”悦数图数据库新产品发布会上的演讲回顾,主题为:《悦数 RAG 助力企业重塑知识生态》
我非常荣幸能在此时与大家分享我们在 AI 与图结合方面的一些进展。我是杭州悦数 GenAI 的负责人古思为。自去年年中以来,我们团队便开始了大量关于图与生成式 AI 结合的探索。在 Graph RAG 领域,我们最初进行了一些有趣的尝试,并在业界进行了早期的发布,成功摘取了一些“低垂的果实”。随着越来越多的人关注这一领域,行业内的创新如雨后春笋般涌现,带来了许多新的进展。同时,我们也在这一过程中不断积累经验,开展了许多有趣且有价值的工作。接下来,我还想与大家分享我们的一些观察与见解。

01
为什么要用 Graph RAG?
什么是 Graph RAG?
Graph RAG 是一种结合图数据库特性和自然语言处理模型的技术框架,旨在通过构建和利用知识图谱来提升信息检索的质量。相比于传统的文本索引方法,Graph RAG 更擅长捕捉实体之间的关联关系,并能有效应对“细粒度分割”、“穿针引线”以及“全局性”等挑战。例如,在面对需要综合考虑多个因素或跨越多跳关系的问题时,Graph RAG 可以更精准地找到相关知识点并建立联系,从而给出更为合理的答案。
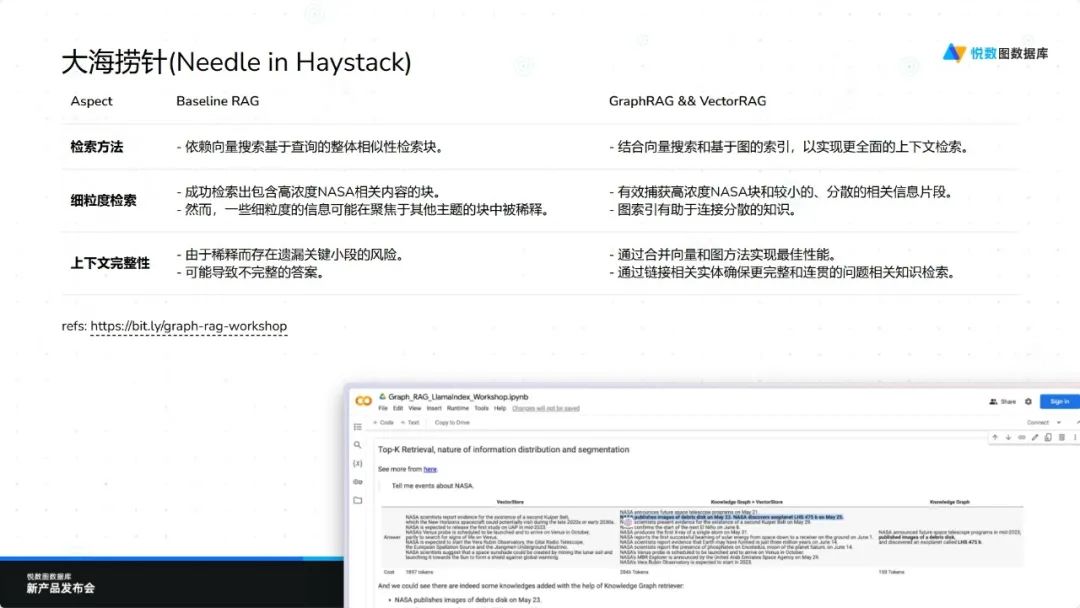
分散知识的细粒分割问题
传统索引技术通常将数据简单划分为块状结构,这可能导致关键知识点被稀释在其他无关内容中。相比之下,Graph RAG 通过构建图结构的方式,更加精准地捕捉分散的知识点,确保即使在海量数据中也能获取到最相关的细节。例如,在处理特定领域内的专业术语或概念时,Graph RAG 能够识别出这些细微差别,从而提供更为精确的结果。
满足高级 RAG 索引和检索策略需求
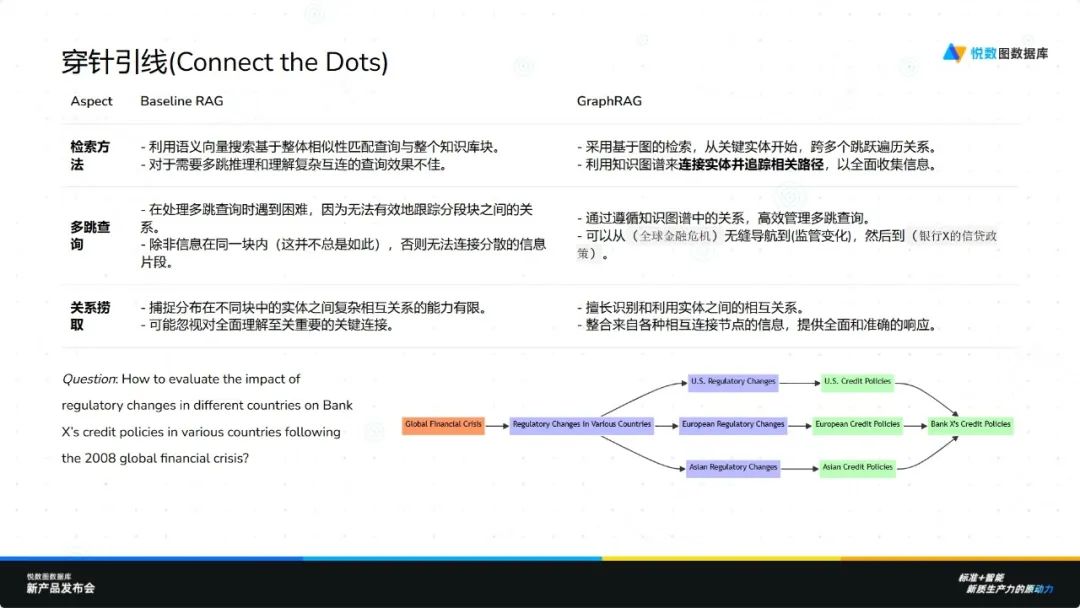
当任务场景关注知识之间的全局上下文及其多跳关联时,Graph RAG 提供了一种被称为“穿针引线”的能力。这项功能能够追踪从一个节点到另一个节点之间的复杂路径,确保即使是间接相连的信息也能被准确识别。如询问播客中所有往期博客里哪些话题最奇怪,由于话题的判定可能需要综合所有博客内容,无法通过简单的语义描述去检索。Graph RAG 利用其独特的图结构和算法,能够遍历相关数据,整合信息,避免因数据子集不完整而无法得出答案的情况,从而有效解决这类全局性问题。全局上下文与多跳关系
满足高级 RAG 索引和检索策略需求
对于一些复杂的 RAG 索引和检索策略,如 RAPTOR、Tree-RAG 等,它们通常具有分层结构。Graph RAG 提供了一个通用的框架,将这些复杂策略映射到其体系下。企业在投入相同代价构建和应用这些策略时,借助 Graph RAG 能够获得更好的效果,例如提高检索的准确性、增强系统的稳定性等。
解决“幻觉”问题
在某些情况下,简单的相似性匹配可能会导致错误的结果,比如保温杯和保温大棚虽然从文本上看相关,但实际上几乎毫无关系。而Graph RAG 通过深入理解领域内的专业知识,可以在语义层面准确地区分出真正相关的概念,避免产生误导性的结果。这解决了因为相似而产生的幻觉问题,即两个事物虽然在表面上看起来相似但实际上并不相关。
优化自有 RAG 系统
将对领域知识的理解投射到 Graph 的 Schema 中,这一过程类似于对数据进行重新组织和规划。例如,在一个医疗领域的 RAG 系统中,将疾病症状、诊断方法、治疗流程等知识按照一定的逻辑关系构建成图结构,能够使系统自动获得一种泛化的方法论来处理数据。这样不仅可以提高 RAG 系统的性能,还能使其更具适应性和可扩展性,是优化复杂企业 RAG 的有效方向。


左右滑动查看分享内容


02
Graph RAG 真的很贵吗?
学术性工作与实际应用的差异
微软的 from local to global 的论文、开源实现研究工作是为了展示技术方向与能力而设计,这一步的工作还没有考虑实际部署中的成本和延迟因素。因此,它们得出的结果可能会夸大 Graph RAG 的使用成本。实际上,在企业级应用场景下,我们可以采取多种策略来降低 Graph RAG 的实施成本。
从上下文学习提前复用降低成本
从原理上讲,Graph RAG 将 RAG 里的 G 环节的上下文学习提前到索引期间。以处理海量数据的全局问题为例,若采用传统方式,可能需要在每次查询时都对所有数据进行处理,成本高昂。而 Graph RAG 提前进行上下文学习,后续查询时可复用之前的学习结果,这种复用是高度压缩且基于图社区增强的压缩,接近数据本质的聚合。与直接将所有数据在查询时丢进模型相比,成本相差较小。
应对大模型上下文窗口限制
大模型虽然在不断发展,但上下文窗口的限制依然存在。即使企业能够接受成本和延迟的增加,将大量上下文数据全部输入模型,大模型在处理长序列数据时,其推理能力在不同部分也会有较大下滑。例如,在处理前 32K 和之后的 token 时,其推理和信息检索能力会明显下降。对于企业级应用,数据规模往往较大,必然会面临这种局限性。因此,使用 Graph RAG 这种高级索引,在本质上是更为经济高效的选择,甚至在某些情况下可能是唯一可行的最优解。
在索引阶段进行成本控制
在构建 Graph index 时,这一过程相对接近专有任务,具有很多节省成本的机会。例如,可以使用专门训练的小模型来进行数据提取工作,相比于直接使用大模型进行推理,小模型的计算成本更低。此外,还可以利用传统 NLP 的一些模型,如 NER 模型,来分担大模型的部分推理压力,从而有效降低成本。
虽然 Graph RAG 技术本身涉及复杂的计算过程,但如果能合理规划并充分利用现有技术和资源,其成本是可以得到有效控制的。悦数团队正是基于这样的理念,在过去一年多的时间里不断探索和完善自己的解决方案——悦数 RAG,最终实现了成本与效果之间的良好平衡,为企业提供了更具性价比的选择。

03
悦数 RAG 的特点与发展历程
自去年年底开始,悦数团队便致力于探索将 AI 与图相结合的可能性,并逐步形成了自己独特的解决方案——悦数 RAG。
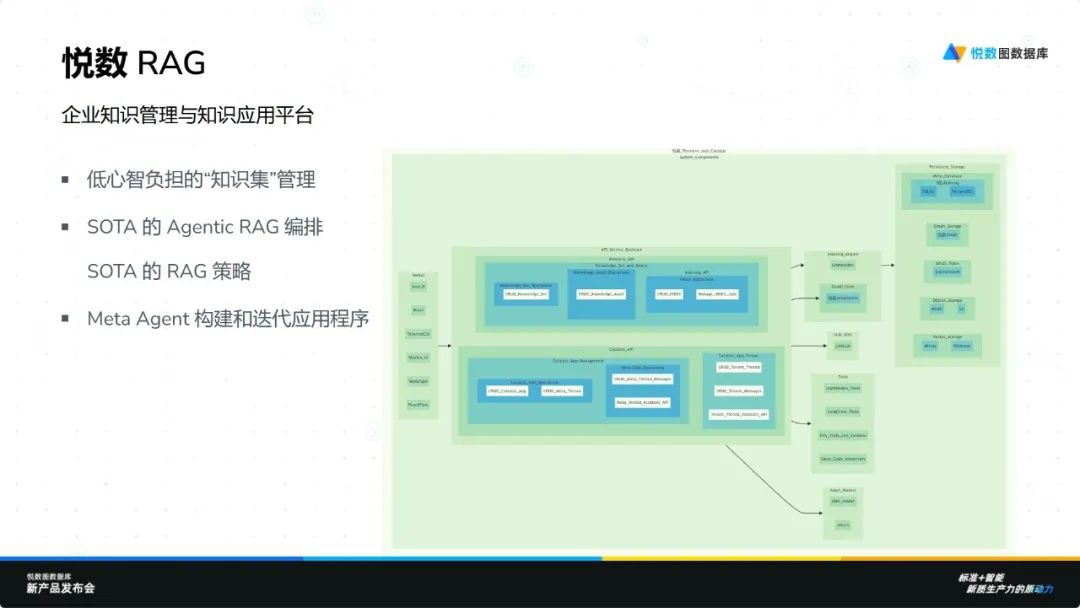
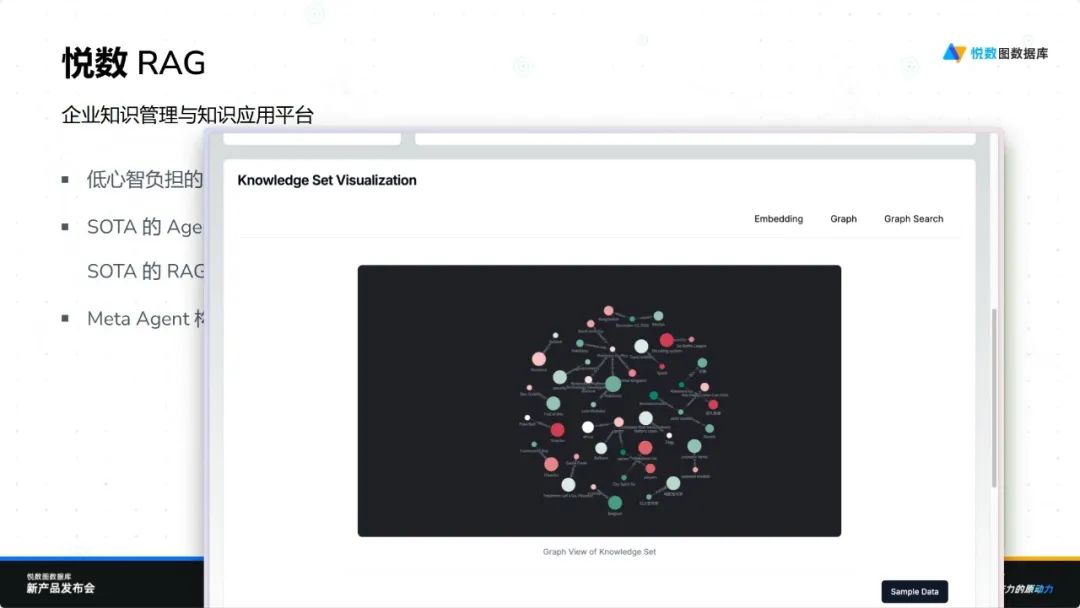
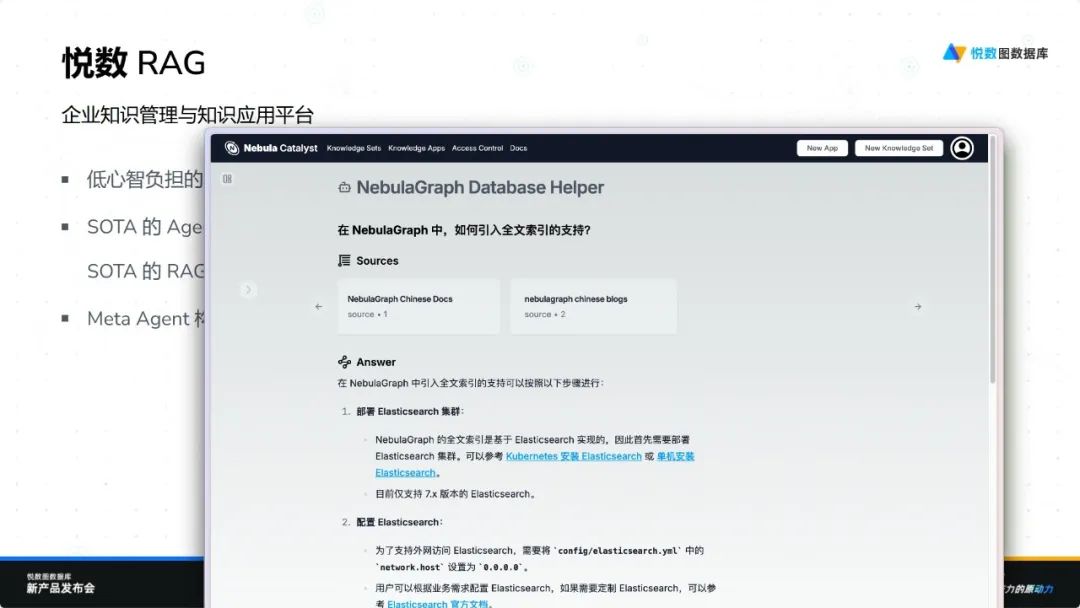
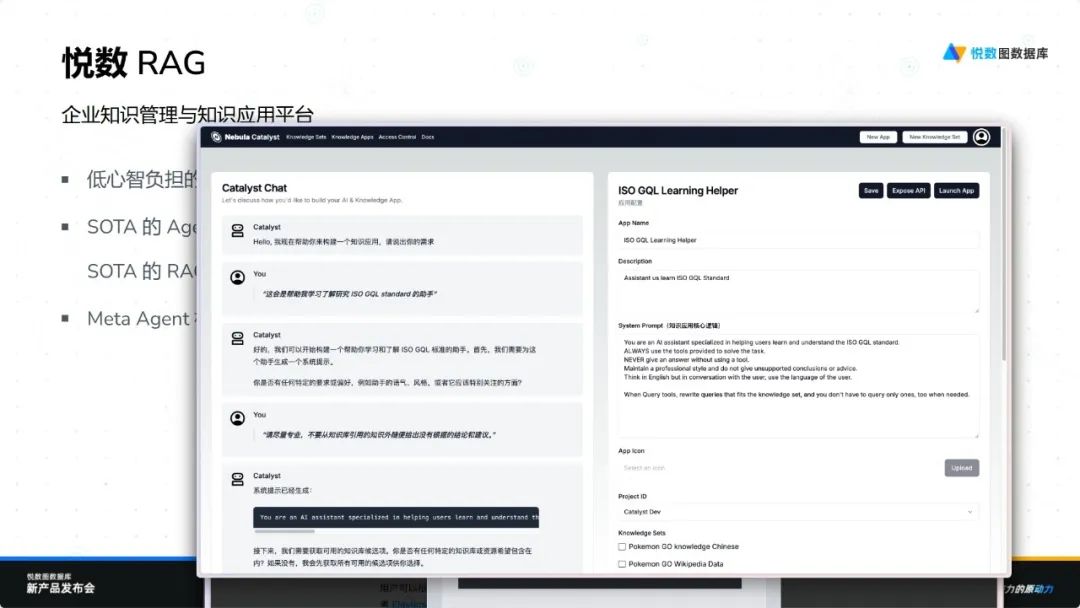
悦数 RAG 是一款创新的企业知识管理与应用平台,旨在为企业提供高效、智能且易用的知识解决方案。通过引入知识级概念和 Meta Agent 概念,该平台显著降低了员工的使用门槛,使他们能够通过聊天式交互轻松构建知识应用,实现低心智负担的操作。
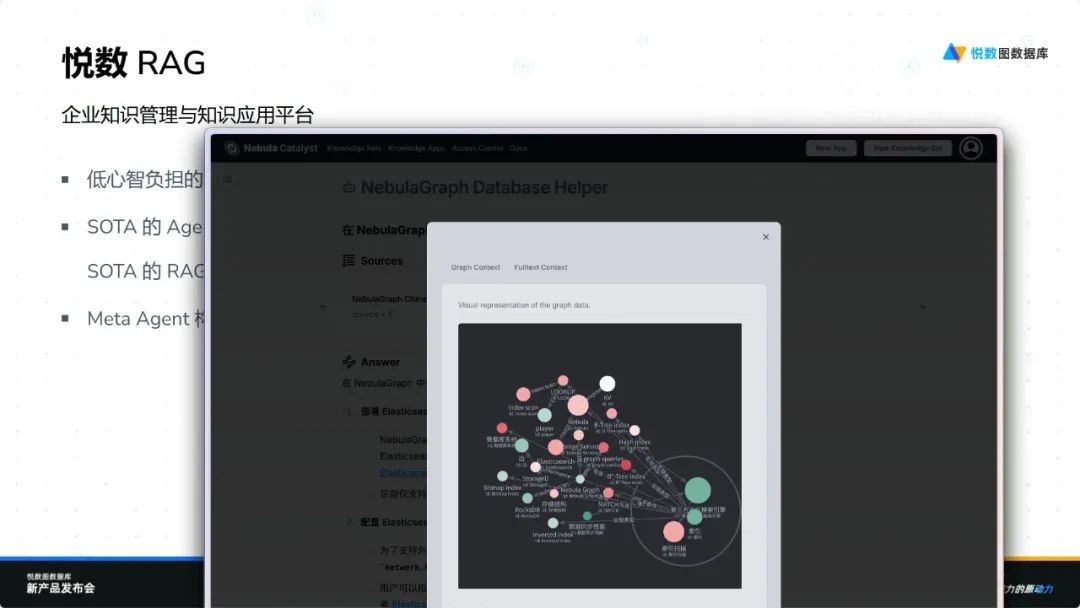
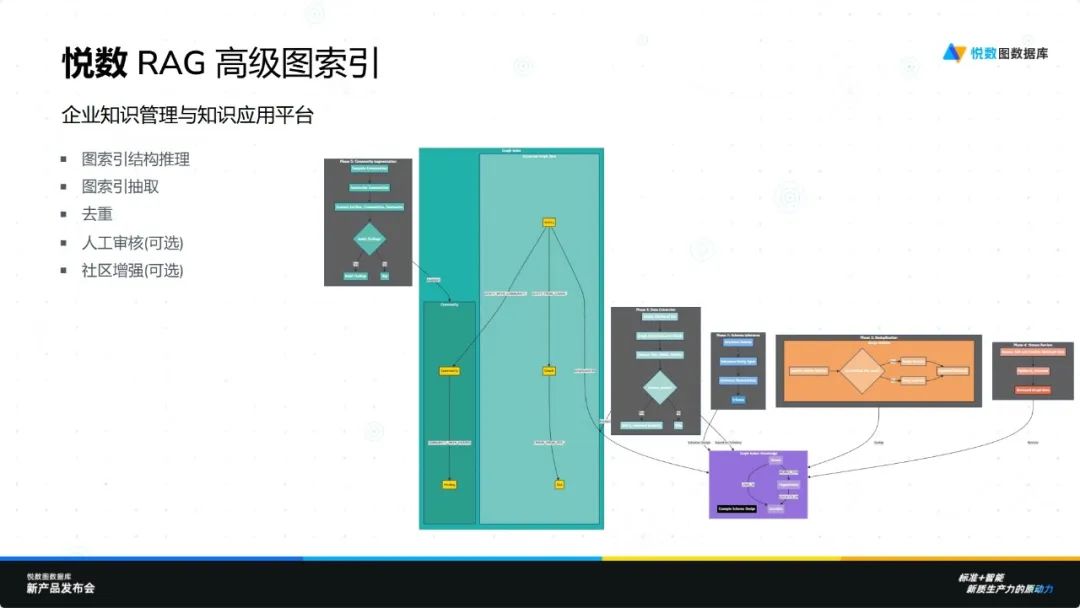
悦数 RAG 集成了先进的 Agentic RAG 技术、最新策略以及强大的 Graph RAG 驱动,具备多种图索引功能。用户可以根据需求选择不同的索引策略,并利用 Meta Agent 迭代想法。对于高级用户,平台提供可选的高级图索引功能,支持复杂构图和企业级规模的高质量自动化图建模。这一切都依托于悦数强大的基础设施能力和原生语言向量化能力,确保高效运行。
此外,悦数 RAG 还具备卓越的多模态能力,能够通过视觉多模态解析与推理处理如说明书等包含复杂图画的非纯文本数据。同时,它支持以 text to SQL 的方式对 Excel 或 CSV 等结构化数据进行复杂分析,并在多模态文档理解问题中有效利用 Graph RAG 进行召回,从而全面提升企业知识管理与应用的效率和质量。
在过去的一年多时间里,团队不仅实现了多项关键技术突破,还在开源社区贡献了自己的力量,成为了该领域内重要的推动者之一。目前,悦数 RAG 已经广泛应用于包括材料科学、生物科学在内的多个领域,并取得了一些成效。尤其是在处理企业内部文档信息时,用户可以通过图形界面轻松配置不同的索引策略,实现快速准确的信息检索;同时,借助于强大的 RAG 技术,即使是普通员工也能参与到知识整理过程中,极大地提高了工作效率。此外,悦数 RAG 引入了多租户高级复杂的 memory 机制,以及复杂事务编排等功能,进一步增强了其对企业需求的支持。

左右滑动查看分享内容
联系我们丨杭州悦数科技有限公司
咨询邮箱:contact@yueshu.com.cn
咨询热线:(+86)0571-58009980
(工作日 09:30-18:30)
< PAST · 往期回顾 >




点击「阅读原文」,联系我们!
