






01
摘要
研究团队创建了OHRBench,这是首个用于理解OCR对RAG系统级联影响的基准,包含350份来自六个实际应用领域的非结构化PDF文档,以及基于文档中多模态元素的问答对。研究识别了两种OCR噪声类型:语义噪声和格式噪声,并通过扰动生成不同程度的噪声数据集。研究使用OHRBench全面评估了当前的OCR解决方案,发现没有一种方案能够构建高质量的RAG系统知识库,并系统地评估了这两种噪声类型的影响,揭示了RAG系统的脆弱性。此外,研究还讨论了在RAG系统中使用无需OCR的视觉语言模型(VLMs)的潜力。
02
OHRBench
OHRBench:量化OCR噪声对RAG系统的影响
数据集统计
文档数量:350份PDF文档,涵盖六个领域 页面数量:4012页,包含Q&A生成的1370页,剩余为知识库部分 平均每页词汇数:482.61个 问题和答案:4598个Q&A对,问题平均包含18.56个词汇,答案平均包含7.91个词汇

评测方法
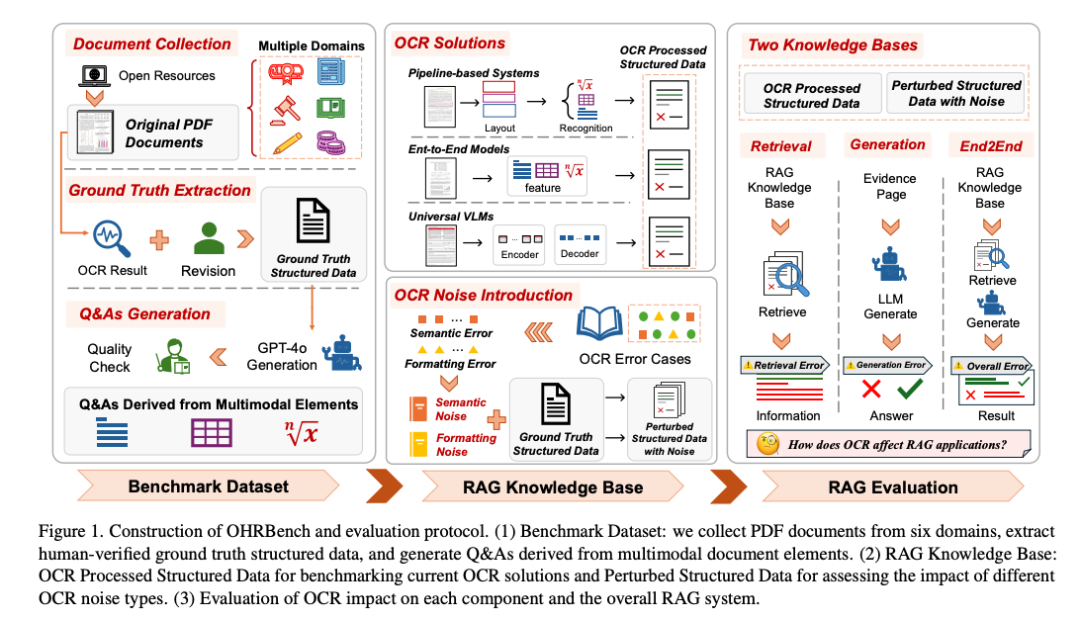
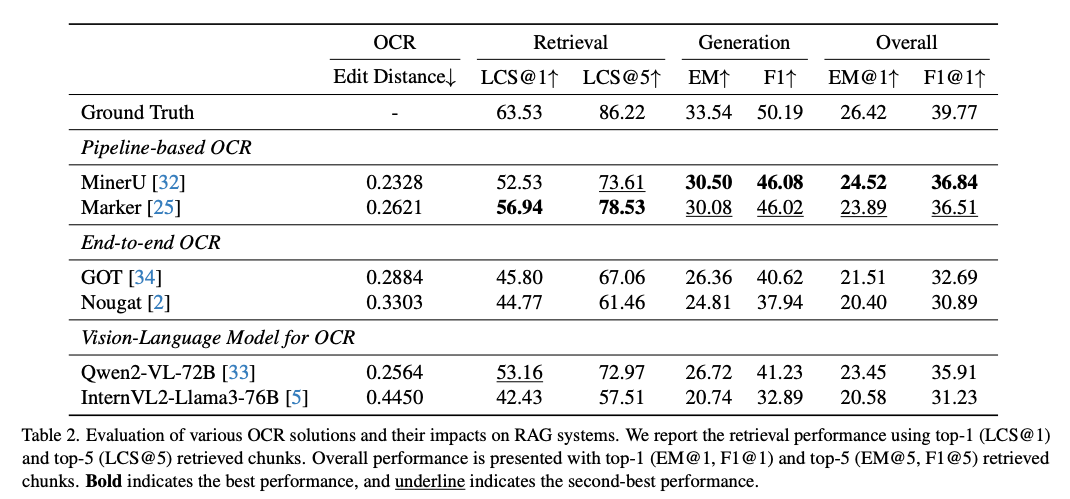
OHRBench的实验结果表明,OCR噪声对RAG系统的性能有显著影响。具体表现如下:
语义噪声对RAG系统的影响最为显著,尤其是在检索和生成阶段,随着噪声级别的增加,性能显著下降。
格式噪声主要影响与多模态元素相关的问题,如表格和公式。不同检索器和LLM对格式噪声的敏感性有所不同。
检索性能:BGEM3和BM25是表现较好的检索器,但随着噪声增多,性能下降明显。
生成性能:Qwen2和Llama-3.1表现较好,但噪声影响显著,尤其是与表格相关的问题。
整体系统性能:语义噪声对系统性能的影响最大,格式噪声影响较小
使用图像输入时,VLMs的性能较差;
使用OCR文本输入时,VLMs的表现提升;
图像和OCR文本结合输入时,VLMs的性能最为接近ground_truth数据。
03
总结
04
编者简介
文章转载自AI 搜索引擎,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
