




作为取证人,你一定遇见过这样的"бЇЯАзЪСЯ"、"�????????"?“鬼画符”,作为一个合格的取证人,你一定知道切换不同的编码方式“翻译”这段乱码。
为什么不同的编码方式会呈现截然不同的字符?今天我们来聊聊关于字符编码与字符集的前世今生。
一切还要从源头说起:
比特(bit):
都知道计算机底层只能处理二进制数据,因此每一个二进制数据,我们管它叫比特,这是计算机能读懂的语言。
字节(byte):
一个比特只有两种状态,只能表示两种含义,需要表示更多的含义,就必须要更多的比特,所以有人规定了将8个比特定为一个字节,最多就能表示256种状态(2的8次方)。
字符(character):
各类文字、符号的总称;文字、数字、标点符号、运算符号,这些都可以成为字符,这是人能看懂的语言。
字符集(character set):
一组特定字符组成的集合,大致可以理解为某一文字系统所有字符加上一些符号的总称
例如:
ASCII字符集主要包含了26个英文字母、阿拉伯数字及一些符号,可以认为这是一个英语字符集。
GB2312字符集主要记录了最常见的6000多个简体汉字,因此可以认为这是一个简体汉字字符集。
除了以上举例的两个字符集,在计算机世界还存在着许许多多的字符集。
字符编码方式(character encoding):
到现在为止,计算机能认识的字节有了,人能认识的字符集也有了,现在还差一种方法进行人机“语言”互换就能实现人机操作了,因此字符编码诞生了。
字符编码如同一本双语词典,只不过它翻译的是人类语言与计算机语言;依照字符集收录的字符,将不同字符对应上不同的字节,一本完整的字符编码表就有了。
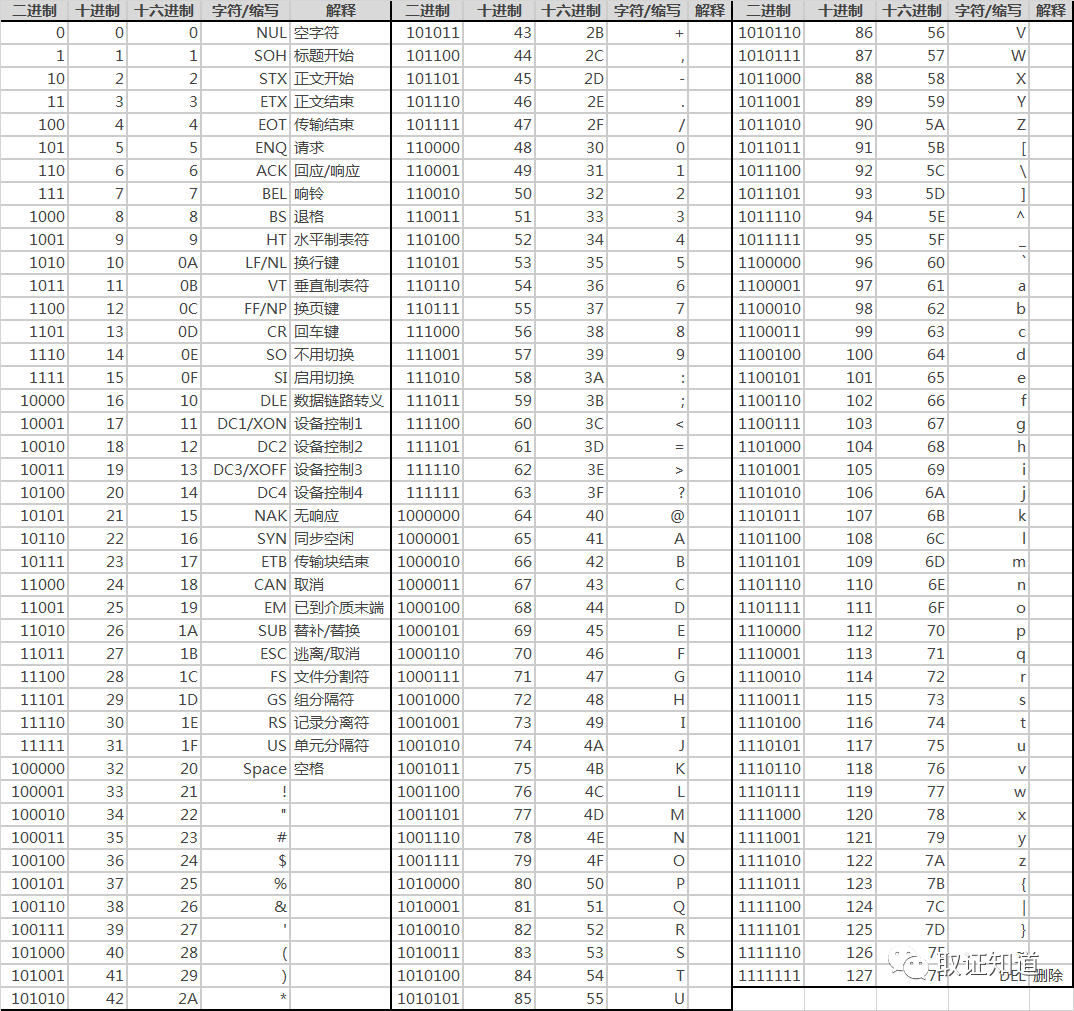
上图是一张ASCII字符编码对照表,当使用者在键盘输入字符时,计算机将按照此表转换为能识别的二进制信息,处理完成后,将二进制信息转换为人能看懂的字符,
ASCII作为计算机系统中最早诞生的字符编码,只使用了一个字节的7bit,但是对于计算机的发明者,英语系国家来说已经完全足够了。
看到这里一定有细心的朋友发现了,刚才你说ASCII是字符集,为啥到这里又是字符编码?
没错,ASCII是字符集,也是字符编码,它不但圈定了字符的数量,也规定了字符和字节的对应关系。
所以,我们在谈论字符集的时候往往谈的是字符编码。
计算机最开始的字符编码是由漂亮国人制定的ASCII码,随着计算机的普及,越来越多的国家也需要在计算机上显示自己的文字,只能表示128种字符的ASCII码显然无法承担这个重任。
这时,漂亮国的权威们又站出来了,我们要让全世界人民都能在电脑用上自己的文字,现在开始我们要用两个字节表示一个文字,这样就可以将字符扩展到65536个(2的16次方),够全世界所有语言使用了。这就是ANSI编码标准。
ANSI编码兼容ASCII编码,前128个字符仍然与ASCII编码相同,0x80-0xFFFF留给其他文字语言使用。
虽然ANSI规定了其他文字可以使用的编码段,但似乎忘记了对编码段做分配,就好像给了一本字典,只有前面128页有翻译对照,后面的6万多页都是空白,拿到本的人想怎么填就怎么填。
结果就是各个国家、地区开足马力,在这本字典中按照自己的想法,想怎么写就怎么写,于是计算机世界字符编码百花齐放,诞生了数不清的编码。
GB2312:中国国家编码标准,收录了6000多个常用简体汉字,GB为“国标”的拼音缩写。
GBK:GB2312的扩充,增加了日韩文字级BIG5中的所有汉字,字符集扩充到21000多个字符。
GB18030:GBK的扩充,增加了中国少数民族文字,字符集扩充到42000多个字符。
BIG5:繁体中文世界的编码
Shift_JIS:霓虹国的编码表
。。。
到现在全世界人民终于实现了在电脑中用上自己的文字。
只不过此时计算机世界的巴别塔也诞生了,即便都是懂中文的人,计算机中使用繁体字的人完全看不懂的简体字,因为相同的编码对应的是完全不同的字符,这就是我们说的乱码。
一起来看看这个例子:
在GB2312中“汉”的编码是0xBABA,这个编码到了BIG5中对应的字符是“犖”,你认得这个字吗?
老网民们一定还记得当初玩仙剑需要装个南极星“翻译”乱码,根源就在这。
用一句话总结ANSI编码:好心办坏事。
为了解决不同国家ANSI编码的冲突问题,伟大的Unicode应运而生,这是一件如同秦始皇统一六国的大事,从此计算机世界终于“书同文”了。
Unicode收集了世界上所有能出现的字符,且规定了每个字符的对应编码,从此再也不会出现不同字符共用一个二进制码的情况了。
Unicode还规定了用四字节表示一个字符,最多可表达40多亿种含义,这下全世界所有语言文字、字符全都包含进去了还绰绰有余。
目前Unicode仍在不断扩充,现在字符数已超过10万,除了文字,还涵盖了大量图标,像常用的聊天表情其实都是Unicode字符。
Unicode的问题:
1.字节顺序问题:计算机有两种字节存储读取方式,就如同汉字可以从左往右,也可以从右往左,例如“汉”的Unicode编码是0x00006C49,在某些系统同读取顺序是0x496C0000,如何确定一个字符采用哪种字节存储顺序就成了问题。
解决这个问题办法就是在一串字符流的开头标记它采用哪种字节序,
如果开头是“FEFF”两个字节,就表明这个字节流是 Big-Endian 的。
如果开头是“FFFE”两个字节,就表明这个字节流是 Little-Endian 的。
2.存储空间浪费:四个字节表示一个字符,对于不满四个字节的字符,浪费大量存储空间,例如英文只用到了一个字节,为了满足Unicode标准,其他三个字节都得用0填充。
这个问题的解决方案是优化空间占用,去除不必要的占位字节,于是诞生了UTF-16与UTF-8两种编码方式(UTF-8/16只是编码方式,不是字符集)。
8和16表示的是采用该编码方式的字符最少占用比特数(1字节或2字节)
UTF-8编码:
当前互联网最常用的编码格式,它基于Unicode字符集进行编码设计。它最大的特点是变长字节的编码设计,一个字符最长4个字节,最少1个字节,且不需要处理字节顺序问题。
编码规则如下:
用一个字节表示的字符,第一位设为 0,后面的 7 位对应这个字符的 Unicode 码点。
由于这128个字符的Unicode完全对照ASCII编码,可以完全兼容ASCII编码;即ASCII编码的文件可以用UTF-8打开而不乱码。
用一个字节以上表示的字符,假设是N个字节表示这个字符:则该字符第一个字节的前N位都为1,第N+1位为0,剩下的N-1个字节的前两位都设为10,剩下没有主动设值的位置则使用这个字符的Unicode二进制代码点从低位到高位填充,不够用0补足。
编码对照表如下:
仍然以“汉”字演示UTF-8是如何编码和解码的:
“汉”在Unicode中的编码是6C49,位于上表第三行区间,故需3个字节来表示字符,把6C49的二进制0110 1100 0100 1001从低位对应补足到1110xxxx 10xxxxxx 10xxxxxx。
成为1110-0110 10-110001 10-001001,即十六进制E6 B1 89,这就是“汉”的UTF-8编码。
解码(decode):由以上规则逆向转化Unicode码再对应到具体字符。
在UTF-8中绝大多数汉字都是3个字节。
UTF-16编码:
UTF-16以2或者4个字节编码表示unicode字符
Unicode字符集中,000000-00FFFF表示的字符,在UTF-16中用2字节直接编码表示,不需要编码转换。
Unicode字符集中,010000-10FFFF表示的字符,在UTF-16中用4字节编码表示,但是需要进行编码转换。
比如010000-10FFFF中的某个字符X的uicode编码为AAAA AAAA AABB BBBB BBBB,分为高10位和低10位,高10位加上高位代理位D8(110110),低10位加上低位代理位DF(110111),即组成字符X的UTF-16编码110110AAAAAAAAAAA 110111BBBBBBBBBB。
UTF-16中,大部分汉字采用两个字节编码,少量不常用汉字采用四个字节编码。
通过比较不难发现,UTF编码方式确实相较Unicode更节省存储空间、更利于网络传输,但对于汉字使用者UTF-16是明显优于UTF-8的。
最后,大致总结出与我们汉字相关的编码进化过程:
ASCII--->ANSI--->GB2312--->GBK--->GB18030--->Unicode--->UTF-16/8
喜欢小知的话请不要忘了关注,点赞,转发!

