




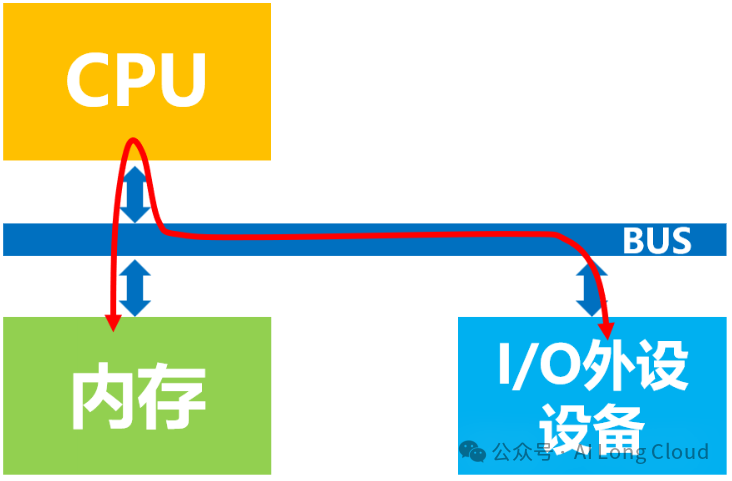
无DMA控制器时,数据经CPU访问模式
CPU的最主要工作是计算,是一台计算机的“大脑”,而不是用来专门进行数据复制或传输的,这种工作属于白白浪费了它的计算能力。为了给CPU“减负”,让它投入到更有意义的工作中去,后来人们设计了DMA机制和技术,即在总线上挂载一个DMA控制器,专门用来读写内存的设备。
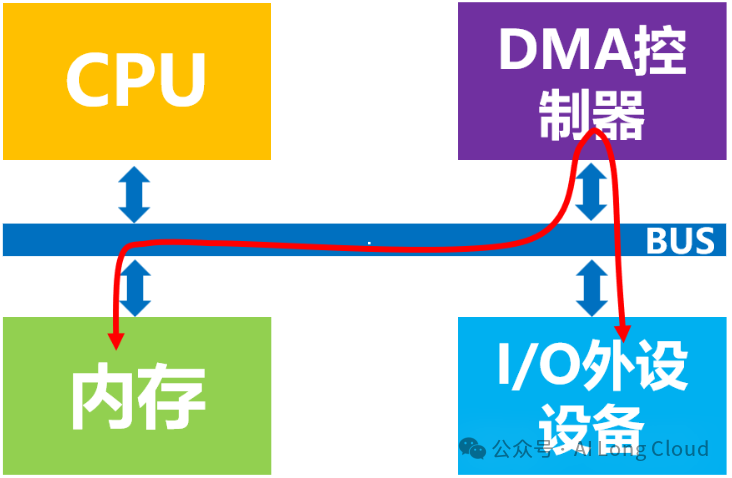
有DMA控制器时,内存直接访问模式
经过技术不断迭代和发展,DMA控制器一般都是和I/O设备集成在一起了,也就是说一块DMA网卡中既有负责数据收发的模块,也有DMA模块。

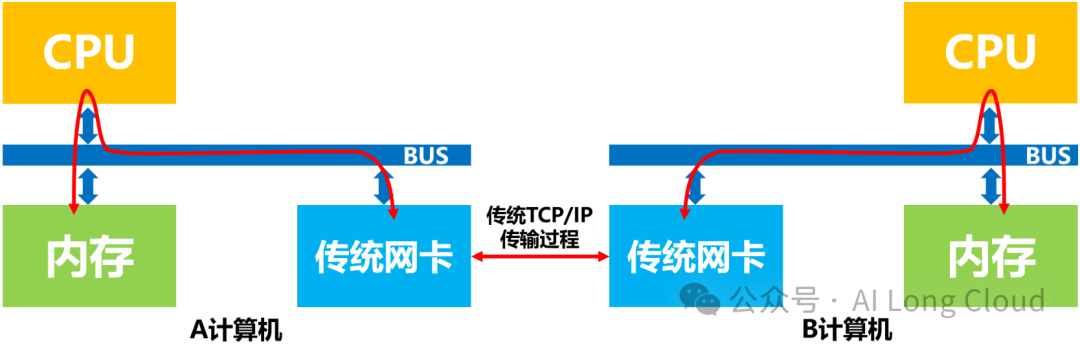
传统网络中,A计算机给B计算机发送数据,实际上需要做的是”把A计算机内存中的一段数据,通过网络链路搬移到B计算机的内存中”,而这一过程无论是发送端还是接收端,数据都是需要经过CPU,包括CPU对网卡的控制,中断的处理,报文的封装和解析等等。
而引入RDMA技术之后呢,数据就可以绕开CPU通过RDMA网卡直接进行内存访问,从而大大提高了数据的传输速率和减少了时延。同时也大大的释放了CPU的工作负载和”压力”,提升了计算的工作效率。如下图所示:
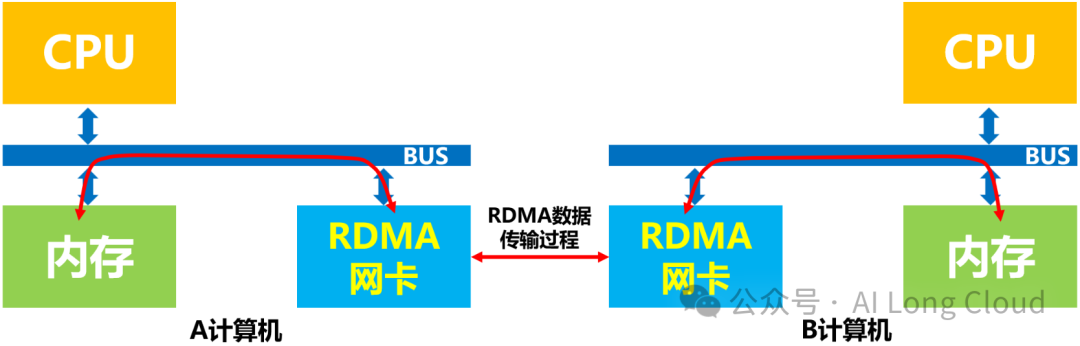
计算机的CPU:除了在建立连接、注册调用、控制管理等之外,在整个RDMA数据传输过程中并不提供服务,因此没有给系统带来任何的“负载”,相反还能释放出较多空闲时间,可以处理很多额外的CPU计算工作。
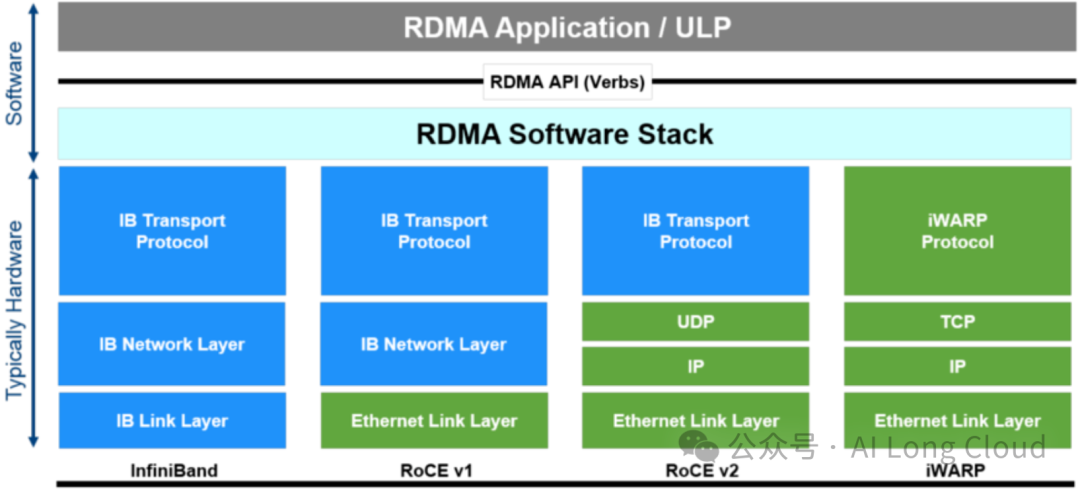
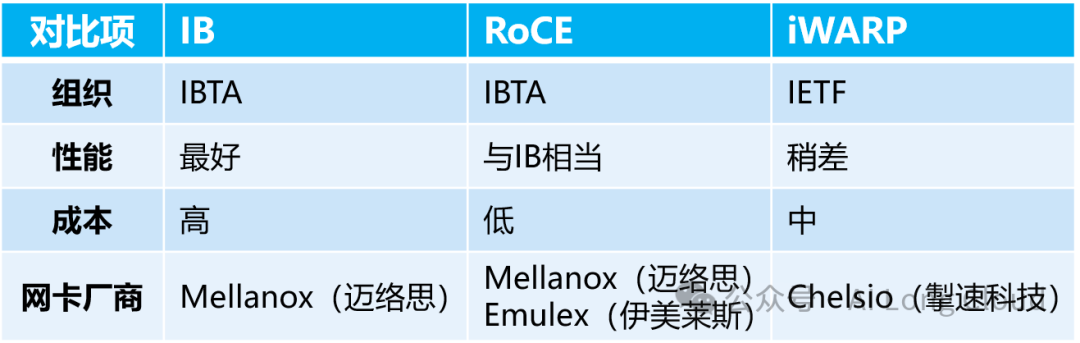
Infiniband(IB):InfiniBand(直译为“无限带宽”技术,缩写为IB)是一个用于高性能计算的计算机网络通信标准,它具有极高的吞吐量和极低的延迟,用于计算机与计算机之间的数据互连,是一种RDMA原生的网络协议。InfiniBand也用作服务器与存储系统之间的直接或交换互连,以及存储系统之间的互连。IB网络需要通过专用硬件才能实现最优的性能,但是由于专用硬件的原因(即Infiniband要求从L2到L4到需要自己的专用硬件),设备成本非常高,现在做InfiniBand网络的厂商主要就是Mellanox(为以色列一家芯片制造商,现已被英伟达收购)。
ROCE:ROCE基于以太网链路层的协议,v1版本网络层仍然使用了IB规范,而v2使用了UDP+IP作为网络层和传输层,使得数据包也可以被路由。RoCE可以被认为是IB的“低成本解决方案”,将IB的报文封装成以太网包进行收发。由于RoCE v2可以使用以太网的交换设备,所以现在在企业中应用也比较多,但是相同场景下相比IB性能要有一些损失。
iWARP:iWARP基于TCP/IP协议的RDMA技术,由IETF标准定义。iWARP支持在标准以太网基础设施上使用RDMA技术,而不需要交换机支持无损以太网传输。因为TCP是面向连接的可靠协议,这使得iWARP在面对有损网络场景(可以理解为网络环境中可能经常出现丢包)时相比于RoCE v2和IB具有更好的可靠性,在大规模组网时也有明显的优势。但是大量的TCP连接会耗费很多的内存资源,另外TCP复杂的流控等机制会导致性能问题,所以从性能上看iWARP要比UDP的RoCE v2和IB差。
如果对算力不是很熟悉的话,建议可先看看以下的文章,先对算力及相关的技术有个基本的了解,欢迎点赞收藏。
一文让你彻底了解算力到底是如何计算出来的-算力的计算方法(CPU和GPU)
AI DC的到来,你还不知道什么是数据中心?30页PPT让你快速了解数据中心
