





点击蓝字关注我们
本文翻译自EDB blog,由EDB TEAM撰写。https://www.enterprisedb.com/blog/rag-app-postgres-and-pgvector,在EPAS环境下通过pgvector扩展,亲测有效。
RAG(检索增强生成)应用程序现在非常流行,我们决定专门使用 Postgres 和 pgvector 开发一款应用程序。在这篇博文中,我将简单介绍一下 RAG 是什么,详细介绍如何从头开始构建 RAG 应用程序,分享构建 RAG 应用程序的基本元素,并在此过程中提供一些有用的提示。
所有代码都可以在 GitHub (https://github.com/gulcin/pgvector-rag-app)上找到,我还录制了运行该应用程序的视频(https://youtu.be/-pi7uqLbrg4),以向您展示它是如何工作的。
什么是检索增强生成 (RAG)?
检索增强生成 (RAG) 已成为使大语言模型 (LLM) 应用程序变得更加智能的首选方法。我们通过添加LLM不知道的我们自己的数据来实现这一目标。
RAG 将传统语言生成模型与基于检索的方法相结合,例如使用我们自己的Postgres 等数据库中的数据,以提高生成文本的质量和相关性。我们收集问题或任务的相关数据,并将其作为LLM的背景。通过结合检索步骤和附加上下文,RAG 提高了生成文本的连贯性、准确性和特异性,使其对于问答、摘要和对话创建等任务特别有用。
所有这些步骤都会使LLM对该主题有更深入的理解,从而使其变得更加智能。众所周知,RAG 还可以防止生成的响应中出现被称为“幻觉”的错误。
应用程序的动机
在过去的几个月中,我一直在各种会议和聚会上介绍 pgvector,并与渴望探索 Postgres 和 pgvector 潜力的客户建立联系。他们中的许多人有兴趣将自己的数据纳入LLM,以开发利用其特定领域知识的聊天机器人式应用程序。
观察到他们的请求存在一些一致的趋势,这推动了应用程序背后的动机:
用户希望能够将不同类型的数据源(从 Jira 和 Github 问题到 Confluence 文档、博客文章、内部培训材料和 PDF 文档)注入到他们的 RAG 应用程序中。
由于数据隐私问题,他们倾向于本地 LLM 部署,以避免将数据发送到 OpenAI API 等外部 API。
他们希望使用 pgvector 直接在 Postgres 中存储和查询矢量数据,从而简化数据管理流程。这是特别可以理解的,因为他们已经熟悉 Postgres 并在生产中使用它。
他们希望根据提出问题的用户的角色或特权来控制和规范矢量搜索。不同的项目、利益相关者和部门需要访问自己的信息,同时限制其他人的访问。
RAG 应用程序的限制
虽然检索增强生成 (RAG) 架构提供了许多好处,但它也带来了一些挑战,特别是在本地运行大型语言模型 (LLM) 时:
在 CPU 上运行 LLM 具有挑战性,因为大多数模型都针对 GPU 进行了优化(例如 Llama 模型)。值得注意的是,本地运行 LLM 并不是 RAG 架构的要求;我们在应用程序中选择了这种方法,以符合我们在客户需求中观察到的趋势。
由于典型笔记本电脑的内存、缓存和 CPU 限制,本地开发和测试可能非常耗时。
RAG 的指令受到模型上下文窗口的限制,该窗口是指 LLM 在生成响应时可以作为输入处理的令牌数量。这种固定的令牌限制可能会限制模型基于长或复杂输入理解和生成响应的能力。
扩展系统以处理增加的负载或更大的模型可能很困难,需要仔细规划和资源管理。
例如AWS实例的环境成本,特别是 g5.2xlarge 等 GPU 优化实例,可能会相当高。
RAG应用的流程
在设计应用程序时,工作流程如下:
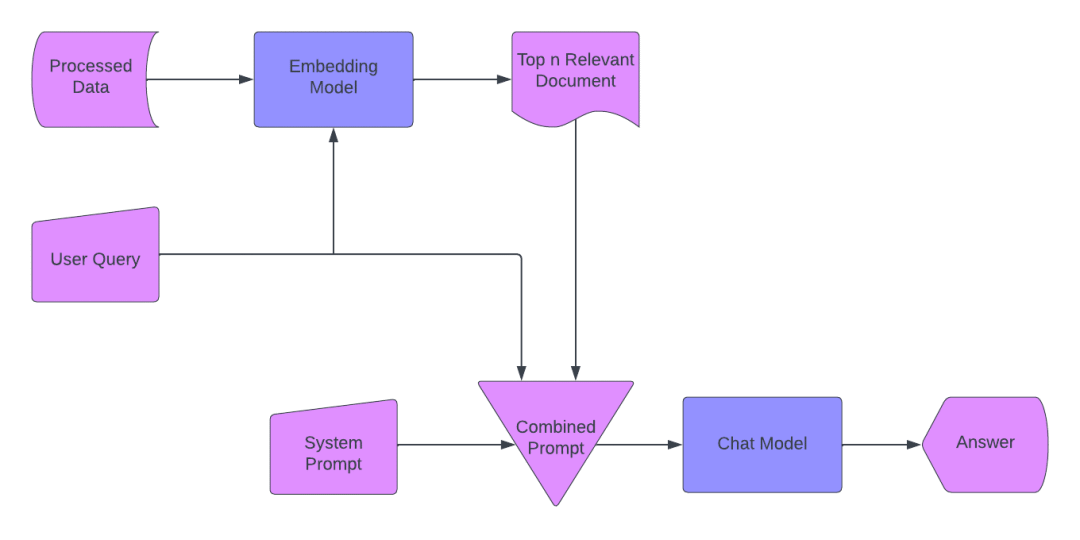
第1步:数据处理
摄取 PDF 和文档。
将块编码为向量并使用 pgvector 将它们存储在 PostgreSQL 中。
第2步:嵌入模型
将文本块转换为嵌入向量。
为聊天模型准备数据。
第3步:用户查询
允许用户输入问题。
使用查询来提示系统。
第4步:检索相关部分
使用向量识别前 N 个相关文档部分。
优化模型的token使用。
第 5 步:创建复合提示
生成包含相关向量、系统提示和用户问题的提示。
包括最近的对话历史记录以了解上下文。
第 6 步:向聊天模型发送提示
将复合提示转发到聊天模型。
第 7 步:提供答案
从聊天模型中检索响应。
将响应发送回用户。
然后,我开始开发并将所有这些构建块组合在一起。
应用架构
正如我们之前讨论的,该应用程序遵循标准 RAG(检索增强生成)工作流程。这里的关键元素是用于存储向量和构建聊天机器人的 Postgres 和 pgvector,以及在本地运行 LLM 的方面。这些组件构成了我们应用程序设计的支柱。
需求:
PostgreSQL(版本 12 或更高版本,因为 pgvector 需要 12+)
pgvector PG向量扩展插件
Python 3
该应用程序涉及三个主要步骤:创建数据库、导入数据和启动聊天功能。这些步骤封装在“app.py”中,您可以使用以下命令运行应用程序:
python app.py --helpusage: app.py [-h] {create-db,import-data,chat} ...Application Descriptionoptions:-h, --help show this help message and exitSubcommands:{create-db,import-data,chat}Display available subcommandscreate-db Create a databaseimport-data Import datachat Use chat feature
接下来,让我们看一下代码并了解一下实现细节。
5.1 create_db.py
我们使用 ENV 参数( DB_USER 、 DB_PASSWORD 、 DB_HOST 、 DB_PORT )创建数据库。然后,我们启用作为要求的一部分安装的 pgvector 扩展。最后,我们设置了嵌入表。
完整代码(create_db.py):
import osimport psycopg2def create_db(args, model, device, tokenizer):db_config = {"user": os.getenv("DB_USER"),"password": os.getenv("DB_PASSWORD"),"host": os.getenv("DB_HOST"),"port": os.getenv("DB_PORT"),}conn = psycopg2.connect(**db_config)conn.autocommit = True # Enable autocommit for creating the databasecursor = conn.cursor()cursor.execute(f"SELECT 1 FROM pg_database WHERE datname = '{os.getenv('DB_NAME')}';")database_exists = cursor.fetchone()cursor.close()if not database_exists:cursor = conn.cursor()cursor.execute(f"CREATE DATABASE {os.getenv('DB_NAME')};")cursor.close()print("Database created.")conn.close()db_config["dbname"] = os.getenv("DB_NAME")conn = psycopg2.connect(**db_config)conn.autocommit = Truecursor = conn.cursor()cursor.execute("CREATE EXTENSION IF NOT EXISTS vector;")cursor.close()cursor = conn.cursor()cursor.execute("CREATE TABLE IF NOT EXISTS embeddings (id serial PRIMARY KEY, doc_fragment text, embeddings vector(4096));")cursor.close()print("Database setup completed.")
运行create-db 命令后,接下来我们必须运行 import-data 命令来导入我们的文档。当 import_data.py 执行时,它会调用 db.py 和 embedding.py。这是导入数据过程中发生的情况:
连接到数据库
读 PDF 文件
以PDF文件路径作为输入,读取PDF文件中每个页面的文本内容,将其拆分为行,并将行作为
生成embeddings
获取输入文本,对其进行标记,将其传递给 LLM,从模型的输出中检索隐藏状态,计算平均嵌入,并返回原始文本及其相应的嵌入向量。
将嵌入存储在数据库中
将文档片段及其embeddings存储在数据库中
5.2 import_data.py:
import numpy as npfrom db import get_connectionfrom embedding import generate_embeddings, read_pdf_filedef import_data(args, model, device, tokenizer):data = read_pdf_file(args.data_source)embeddings = [generate_embeddings(tokenizer=tokenizer, model=model, device=device, text=line)for line in data]conn = get_connection()cursor = conn.cursor()# Store each embedding in the databasefor i, (doc_fragment, embedding) in enumerate(embeddings):cursor.execute("INSERT INTO embeddings (id, doc_fragment, embeddings) VALUES (%s, %s, %s)",(i, doc_fragment, embedding[0]),)conn.commit()print("import-data command executed. Data source: {}".format(args.data_source))
db.py的代码如下:
import osimport psycopg2def get_connection():conn = psycopg2.connect(dbname=os.getenv("DB_NAME"),user=os.getenv("DB_USER"),password=os.getenv("DB_PASSWORD"),host=os.getenv("DB_HOST"),port=os.getenv("DB_PORT"),)return conn
embedding.py代码如下:
# importing all the required modulesimport PyPDF2import torchfrom transformers import pipelinedef generate_embeddings(tokenizer, model, device, text):inputs = tokenizer(text, return_tensors="pt", truncation=True, max_length=512).to(device)with torch.no_grad():outputs = model(**inputs, output_hidden_states=True)return text, outputs.hidden_states[-1].mean(dim=1).tolist()def read_pdf_file(pdf_path):pdf_document = PyPDF2.PdfReader(pdf_path)lines = []for page_number in range(len(pdf_document.pages)):page = pdf_document.pages[page_number]text = page.extract_text()lines.extend(text.splitlines())return lines
5.3 chat.py
运行 create-db 和 import-data 命令后,我们需要运行 chat 命令。当 chat.py 执行时,它会调用 rag.py。我们将在下一节中更多地讨论 rag.py。
聊天过程定义了便于与用户进行交互式聊天的聊天功能。它不断提示用户提出问题,使用指定的模型生成响应,并向用户显示响应,直到他们选择退出聊天。
def chat(args, model, device, tokenizer):
上面的行定义了一个名为 chat 的函数,它有四个参数:
args :可以传递给函数的附加参数(如果有)
model :用于生成问题响应的 PyTorch 模型
device :模型运行的设备(CPU 或 GPU)
tokenizer :用于标记输入问题的tokenizer实例
answer = rag_query(tokenizer=tokenizer, model=model, device=device, query=question)
上面的这一行使用提供的 tokenizer 、 model 、 device 和用户问题调用 rag_query 函数。它生成对问题的回答。
通过调用 rag_query 函数来形成答案,我们将在查看 rag.py 时详细探讨它。
chat.py代码段
from rag import rag_querydef chat(args, model, device, tokenizer):print("Chat started. Type 'exit' to end the chat.")while True:question = input("Ask a question: ")if question.lower() == "exit":breakanswer = rag_query(tokenizer=tokenizer, model=model, device=device, query=question)print(f"You Asked: {question}")print(f"Answer: {answer}")print("Chat ended.")
5.4 rag.py
该脚本包含该应用程序主要功能所需的基本 RAG 逻辑。
template = """[INST]You are a friendly documentation search bot.Use following piece of context to answer the question.If the context is empty, try your best to answer without it.Never mention the context.Try to keep your answers concise unless asked to provide details.Context: {context}Question: {question}[/INST]Answer:"""
上面的模板提供了用于呈现问题、上下文(如果可用)和机器人答案的结构化格式。它确保响应呈现的一致性,并为模型处理每个查询提供清晰的说明(以及上下文,如果适用)。
5.5 get_retrieval_condition 函数
每个 RAG 都依赖于检索机制,这是 RAG 架构的核心组件。我们从自己的数据库中检索数据,并使用这些数据为LLM提供背景。这就是为什么我们使用我们开发的 rag_query 构建检索条件来获取相关信息(嵌入)。
我们使用 get_retrieval_condition 函数生成 SQL 条件,用于从数据库检索相关嵌入。
def get_retrieval_condition(query_embedding, threshold=0.7):# Convert query embedding to a string format for SQL queryquery_embedding_str = ",".join(map(str, query_embedding))# SQL condition for cosine similaritycondition = f"(embeddings <=> '{query_embedding_str}') < {threshold} ORDER BY embeddings <=> '{query_embedding_str}'"return condition
该函数构造一个 SQL 条件,根据嵌入与给定查询嵌入的余弦相似度 (<=>) 查找嵌入并对其进行排序。它将查询嵌入和阈值作为输入:
query_embedding :表示用户查询的嵌入向量的列表或数组
阈值:一个浮点值(默认值 = 0.7),指定嵌入被视为相关所允许的最大余弦距离。阈值越低,匹配就越接近。
query_embedding_str = ",".join(map(str, query_embedding))
上面的这一行将 query_embedding 列表转换为适合 SQL 查询的字符串格式。
condition = f"(embeddings <=> '{query_embedding_str}') < {threshold} ORDER BY embeddings <=> '{query_embedding_str}'"
上面的这一行构造了一个 SQL 条件字符串,该字符串使用 <=> 运算符来计算存储的嵌入和 query_embedding 之间的余弦相似度。它确保仅考虑余弦相似度小于指定阈值的嵌入。它还根据与 query_embedding 的余弦相似度对结果进行排序,因此最相关的结果会首先列出。
该函数返回构造的 SQL 条件字符串。
5.6 rag_query 函数
rag_query 函数集成了查询嵌入生成、Postgres 数据库中的文档检索、查询和上下文组合以及使用 LLM 生成响应以生成输入查询的相关答案。它可以说是 RAG 系统中最关键的组件。
整个函数如下:
def rag_query(tokenizer, model, device, query):# Generate query embeddingquery_embedding = generate_embeddings(tokenizer=tokenizer, model=model, device=device, text=query)[1]# Retrieve relevant embeddings from the databaseretrieval_condition = get_retrieval_condition(query_embedding)conn = get_connection()register_vector(conn)cursor = conn.cursor()cursor.execute(f"SELECT doc_fragment FROM embeddings WHERE {retrieval_condition} LIMIT 5")retrieved = cursor.fetchall()rag_query = ' '.join([row[0] for row in retrieved])query_template = template.format(context=rag_query, question=query)input_ids = tokenizer.encode(query_template, return_tensors="pt")# Generate the responsegenerated_response = model.generate(input_ids.to(device), max_new_tokens=50, pad_token_id=tokenizer.eos_token_id)return tokenizer.decode(generated_response[0][input_ids.shape[-1]:], skip_special_tokens=True)
下面逐步分解 rag_query 函数来了解每个部分的作用。
生成查询嵌入
query_embedding = generate_embeddings(tokenizer=tokenizer, model=model, device=device, text=query)
在这里,我们为输入查询生成查询嵌入。 generate_embeddings 函数返回一个包含原始文本及其相应嵌入向量的元组。我们提取返回元组的第二个元素,即查询嵌入。
从数据库中检索相关嵌入
retrieval_condition = get_retrieval_condition(query_embedding)
在这里,我们创建一个条件,根据与查询嵌入的余弦相似度从数据库中检索相关文档。
请参阅上一节以了解 get_retrieval_condition 函数的工作原理。
conn = get_connection()register_vector(conn)cursor = conn.cursor()cursor.execute(f"SELECT doc_fragment FROM embeddings WHERE {retrieval_condition} LIMIT 5")retrieved = cursor.fetchall()
这里我们连接到数据库。然后,我们执行 SQL 查询,根据检索条件从嵌入表中选择文档片段,并将结果限制为前五个最相关的嵌入。
准备查询模板
rag_query = ' '.join([row[0] for row in retrieved])
上面的代码将检索到的文档片段连接成一个由空格分隔的字符串 ( rag_query )。它获取所有文档片段并将每个元组的第一个元素连接到 returned 中。
这里,我们使用检索到的文档片段(上下文)和原始查询文本(问题)来格式化模板字符串。
生成响应
input_ids = tokenizer.encode(query_template, return_tensors="pt")
tokenizer.encode 将文本转换为输入 ID,return_tensors="pt" 确保输出采用 PyTorch 张量格式。我们这样做是为了标记查询模板并将其转换为适合模型输入的张量格式。
generated_response = model.generate(input_ids.to(device), max_new_tokens=50, pad_token_id=tokenizer.eos_token_id)
该代码使用提供的模型生成标记化输入。它将新令牌的最大数量限制为 50(响应长度),并指定用于填充的序列结束令牌 ID。
generated_response 包含生成的文本 ID。
return tokenizer.decode(generated_response[0][input_ids.shape[-1]:], skip_special_tokens=True)
在这里,代码将生成的响应令牌解码为人类可读的字符串。 rag_query 函数的输出是最终生成的响应文本。
你可以看到下面的rag.py:
from itertools import chainimport torchfrom pgvector.psycopg2 import register_vectorfrom db import get_connectionfrom embedding import generate_embeddingsfrom pgvector.psycopg2 import register_vectortemplate = """[INST]You are a friendly documentation search bot.Use following piece of context to answer the question.If the context is empty, try your best to answer without it.Never mention the context.Try to keep your answers concise unless asked to provide details.Context: {context}Question: {question}[/INST]Answer:"""def get_retrieval_condition(query_embedding, threshold=0.7):# Convert query embedding to a string format for SQL queryquery_embedding_str = ",".join(map(str, query_embedding))# SQL condition for cosine similaritycondition = f"(embeddings <=> '{query_embedding_str}') < {threshold} ORDER BY embeddings <=> '{query_embedding_str}'"return conditiondef rag_query(tokenizer, model, device, query):# Generate query embeddingquery_embedding = generate_embeddings(tokenizer=tokenizer, model=model, device=device, text=query)[1]# Retrieve relevant embeddings from the databaseretrieval_condition = get_retrieval_condition(query_embedding)conn = get_connection()register_vector(conn)cursor = conn.cursor()cursor.execute(f"SELECT doc_fragment FROM embeddings WHERE {retrieval_condition} LIMIT 5")retrieved = cursor.fetchall()rag_query = ' '.join([row[0] for row in retrieved])query_template = template.format(context=rag_query, question=query)input_ids = tokenizer.encode(query_template, return_tensors="pt")# Generate the responsegenerated_response = model.generate(input_ids.to(device), max_new_tokens=50, pad_token_id=tokenizer.eos_token_id)return tokenizer.decode(generated_response[0][input_ids.shape[-1]:], skip_special_tokens=True)
5.7 app.py
我们在文章开头介绍了 app.py 的大部分内容。请参阅 create-db 、 import-data 、 chat 命令。
if hasattr(args, "func"):if torch.cuda.is_available():device = "cuda"bnb_config = BitsAndBytesConfig(load_in_4bit=True,bnb_4bit_use_double_quant=True,bnb_4bit_quant_type="nf4",bnb_4bit_compute_dtype=torch.bfloat16)else:device = "cpu"bnb_config = Nonetokenizer = AutoTokenizer.from_pretrained(os.getenv("TOKENIZER_NAME"),token=os.getenv("HUGGING_FACE_ACCESS_TOKEN"),)model = AutoModelForCausalLM.from_pretrained(os.getenv("MODEL_NAME"),token=os.getenv("HUGGING_FACE_ACCESS_TOKEN"),quantization_config=bnb_config,device_map=device,torch_dtype=torch.float16,)args.func(args, model, device, tokenizer)else:print("Invalid command. Use '--help' for assistance."
值得强调上面的代码块。在这里我们检查 GPU 设备是否可用。如果CUDA可用,我们将设备变量设置为cuda,表示将使用GPU加速。否则我们将设备设置为 cpu 以供 CPU 执行。
如果 CUDA 可用,我们会使用特定的量化配置来初始化 BitsAndBytesConfig 对象。然后,它使用 HF Transformers 库初始化用于因果语言建模的分词器和模型。
你可以看到下面的app.py:
import argparsefrom enum import Enumfrom dotenv import load_dotenvimport osimport torchfrom transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfigfrom commands.chat import chatfrom commands.create_db import create_dbfrom commands.import_data import import_dataload_dotenv()class Command(Enum):CREATE_DB = "create-db"IMPORT_DATA = "import-data"CHAT = "chat"def main():parser = argparse.ArgumentParser(description="Application Description")subparsers = parser.add_subparsers(title="Subcommands",dest="command",help="Display available subcommands",)# create-db commandsubparsers.add_parser(Command.CREATE_DB.value, help="Create a database").set_defaults(func=create_db)# import-data commandimport_data_parser = subparsers.add_parser(Command.IMPORT_DATA.value, help="Import data")import_data_parser.add_argument("data_source", type=str, help="Specify the PDF data source")import_data_parser.set_defaults(func=import_data)# chat commandchat_parser = subparsers.add_parser(Command.CHAT.value, help="Use chat feature")chat_parser.set_defaults(func=chat)args = parser.parse_args()if hasattr(args, "func"):if torch.cuda.is_available():device = "cuda"bnb_config = BitsAndBytesConfig(load_in_4bit=True,bnb_4bit_use_double_quant=True,bnb_4bit_quant_type="nf4",bnb_4bit_compute_dtype=torch.bfloat16)else:device = "cpu"bnb_config = Nonetokenizer = AutoTokenizer.from_pretrained(os.getenv("TOKENIZER_NAME"),token=os.getenv("HUGGING_FACE_ACCESS_TOKEN"),)model = AutoModelForCausalLM.from_pretrained(os.getenv("MODEL_NAME"),token=os.getenv("HUGGING_FACE_ACCESS_TOKEN"),quantization_config=bnb_config,device_map=device,torch_dtype=torch.float16,)args.func(args, model, device, tokenizer)else:print("Invalid command. Use '--help' for assistance.")if __name__ == "__main__":main()
未来的改进
展望未来,有一些想法可以增强 pgvector-rag-app 。首先,开发用户界面将是有益的。我们已经开始尝试使用Streamlit,它似乎有希望创建一个快速演示界面。由于此应用程序主要用于演示目的,因此您可以灵活地使用您喜欢的前端堆栈对其进行编码。
到目前为止,该应用程序仅使用单个 PDF 文档进行了测试,因此在处理多个PDF方面还需要做更多的工作。也可能有更好的模型来处理这项任务,尝试不同的模型并进行评估总是一个好主意。
目前,该应用程序无法识别哪个用户正在发出查询。通过根据用户的角色和权限定制查询,我们可以个性化他们的体验并满足更严格的安全要求。
总结
仅使用Postgres和pgvector构建 RAG 应用程序是完全可行的。这里就是一个很好的例子,pgvector本身只是其一部分。虽然 Postgres 和 pgvector 的组合使我们能够利用 Postgres 作为矢量数据库,但完整的 AI 应用程序需要更多。
了解我们的 EDB Postgres AI,这是一个专为现代分析和 AI 工作负载而设计的集成平台。通过我们新的 Postgres AI 扩展的增强,我们的平台可以加快 AI 应用程序的开发和部署。凭借强大的安全性和全面的支持,您可以快速有效地构建企业级人工智能应用程序。
关于公司
感谢您关注新智锦绣科技(北京)有限公司!作为 Elastic 的 Elite 合作伙伴及 EnterpriseDB 在国内的唯一代理和服务合作伙伴,我们始终致力于技术创新和优质服务,帮助企业客户实现数据平台的高效构建与智能化管理。无论您是关注 Elastic 生态系统,还是需要 EnterpriseDB 的支持,我们都将为您提供专业的技术支持和量身定制的解决方案。
欢迎关注我们,获取更多技术资讯和数字化转型方案,共创美好未来!
 |  |
Elastic 微信群 | EDB 微信群 |
发现“分享”和“赞”了吗,戳我看看吧
