





点击蓝字关注我们
上篇我们完成的PGD单站点的部署与安装,本篇我们介绍一下PGD集群的连接与故障转移(failover)方面的内容。
一、 连接到PGD
应用或客户端连接到新安装EDB PGD涉及几个方面的内容:
获取凭证
默认用户 enterprisedb 是由 tpaexec 在集群部署过程中创建的。作为配置的一部分,它还为该用户生成了密码。要获取密码,请运行:
tpaexec show-password <cluster名称> <用户名>[nuser@linuxhost-1 ~]$ tpaexec show-password pgddemo1 enterprisedbxlsBIP9bSBwppl$EINWxCJUd2#g8jWQ&PLAY [Check for old repositories] ********************************************************************TASK [assert] ****************************************************************************************ok: [linuxhost-1 -> localhost] => {"changed": false,"msg": "All assertions passed"}PLAY RECAP *******************************************************************************************linuxhost-1 : ok=1 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
命令第一行字符串返回的就是用户enterprisedb的密码凭据。如果需要,可以在系统提示输入密码时使用该字符串。同理,也可以通过该命令获取复制用户replication的密码:
tpaexec show-password pgddemo1 replication
创建 .pgpass 文件
在用户主目录中创建.pgpass文件来避免输入其他psql Postgres客户端的密码。它包含应用程序在连接时可以查找的密码详细信息。获取密码后,在.pgpass中填加。
*:*:bdrdb:enterprisedb:<your password>*:*:*:replication:<your password>
修改.pgpass权限为0600仅用户属主读写权限。
chmod 0600 ~/.pgpass
连接到集群
psql -h 192.168.31.247 -p 6432 -U enterprisedb bdrdbpsql (16.2.0)SSL connection (protocol: TLSv1.3, cipher: TLS_AES_256_GCM_SHA384, compression: off)Type "help" for help.bdrdb=#
上面端口6432是pgd-proxy的运行端口,EDB AS数据库的运行端口是5444。
[nuser@linuxhost-1 ~]$ sudo netstat -nltpActive Internet connections (only servers)Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program nametcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1402176/sshdtcp 0 0 0.0.0.0:5444 0.0.0.0:* LISTEN 1350562/edb-postgretcp6 0 0 :::22 :::* LISTEN 1402176/sshdtcp6 0 0 :::6432 :::* LISTEN 1411235/pgd-proxytcp6 0 0 :::5444 :::* LISTEN 1350562/edb-postgre
使用代理故障转移将客户端连接到群集
通过将所有代理地址列为主机,您可以确保客户端在代理发生故障时始终能够进行故障转移并连接到第一个可用的代理。
psql -h <节点1>,<节点2>,<节点3> -U enterprisedb -p 6432 bdrdb
[nuser@linuxhost-1 ~]$ psql -h linuxhost-1,linuxhost-2,linuxhost-3 -U enterprisedb bdrdbpsql (16.2.0)SSL connection (protocol: TLSv1.3, cipher: TLS_AES_256_GCM_SHA384, compression: off)Type "help" for help.bdrdb=#
许多应用程序使用连接 URL 来连接数据库。要创建连接 URL,需要按以下格式组合:
postgresql://<user>@<节点1>:6432,<节点2>:6432,<节点3>:6432/bdrdb
[nuser@linuxhost-1 ~]$ psql postgresql://enterprisedb@linuxhost-1:6432,linuxhost-2:6432,linuxhost-3:6432/bdrdbpsql (16.2.0)SSL connection (protocol: TLSv1.3, cipher: TLS_AES_256_GCM_SHA384, compression: off)Type "help" for help.bdrdb=#
对于JDBC连接URL如下所示:
jdbc:postgresql://enterprisedb@linuxhost-1:6432,linuxhost-2:6432,linuxhost-3:6432/bdrdb
二、 PGDv5 的故障转移处理测试
对于高可用性集群,故障转移能力对于集群的整体恢复能力至关重要。当主要数据节点因任何原因停止工作时,应用程序需要能够继续使用数据库,几乎没有中断。对于 PGD 来说,这意味着将应用程序定向到新的潜在写领导者数据节点,该节点会自动接管。这就是 PGD 代理的主要作用。它与集群一起工作,并自动将流量定向到主要数据节点。
在本示例中将创建一个定期向数据库发送数据的应用程序。然后,将首先通过PGD CLI 请求更改来软切换写领导者数据节点。然后,再强制关闭数据库实例,并查看 PGD 如何处理它。
为了更直观地观察变化,我们采用tmux分屏技术来实现,为此我们安装xpanes(基于tmux的高级分屏功能软件)。
在当前环境下我们用的是xpanes-4.1.3-1,从repository可以方便安装。
连接到四台服务器节点
安装 xpanes 后,可以通过运行以下命令创建与所有四台服务器的 SSH 会话:
[nuser@linuxhost-1 ~]$ cd pgddemo1/[nuser@linuxhost-1 pgddemo1]$ xpanes -d -c "ssh -F ssh_config {}" "linuxhost-1" "linuxhost-2" "linuxhost-3" "linuxhost-4"
按 Control-b,然后按 q 可简要显示每个窗格的序号。
使用 Control-b ↓ Control-b → 或 Control-b q 3 将焦点移至右下窗格,即linuxhost-4主机。该节点负责执行备份。我们使用它作为演示应用程序的操作基础。我们可以使用 Barman 凭据连接到linuxhost-1节点数据库服务器和代理:
[nuser@linuxhost-4 ~]$ sudo -iu barman[barman@linuxhost-4 ~]$ psql -h linuxhost-1 -p 6432 bdrdb
创建一个表,表名ping
bdrdb=# drop table if exists ping cascade;│NOTICE: table "ping" does not exist, skipping DROP TABLEbdrdb=# CREATE TABLE ping (id SERIAL PRIMARY KEY, node TEXT, timestamp TEXT) ;CREATE TABLE
然后切换窗口到左上方linuxhost-1主机,
[nuser@linuxhost-1 ~]$ sudo -iu enterprisedb[nuser@linuxhost-1 ~]$ psql bdrdb
在linuxhost-1上连接本地数据库实例。使用 \dt 查看可用的表:
bdrdb=# \dtList of relationsSchema | Name | Type | Owner--------+------------------+-------+--------------public | pgbench_accounts | table | enterprisedbpublic | pgbench_branches | table | enterprisedbpublic | pgbench_history | table | enterprisedbpublic | pgbench_tellers | table | enterprisedbpublic | ping | table | barman(5 rows)
运行\d ping显示创建的表 ping 的 DDL 位于 linuxhost-1服务器上:
bdrdb=# \d ping │Table "public.ping" │Column | Type | Collation | Nullable | Default-----------+---------+-----------+----------+----------------------------------id | integer | | not null | nextval('ping_id_seq'::regclass)node | text | | |timestamp | text | | |Indexes:"ping_pkey" PRIMARY KEY, btree (id)
如果想确保在PGD集群环境中该表已复制到其它节点,可以连接到集群中的另一个节点并查看。如连接到 linuxhost-3节点:
bdrdb=# \c - - linuxhost-3 │SSL connection (protocol: TLSv1.3, cipher: TLS_AES_256_GCM_SHA384, compression:off)You are now connected to database "bdrdb" as user "enterprisedb" on host "linuxhost-3" (address "192.168.31.249") at port "5444".
运行\dt和\d ping,您将在linuxhost-3节点上看到相同的结果。
要重新连接到linuxhost-1节点,
bdrdb=# \c - - linuxhost-1
设置表变动监视器
我们要监视 ping 表的活动。输入以下 SQL 以显示最近的 10 条记录, 我们要多次运行此命令,通过\watch 1命令,定期执行最后一个查询,且每秒更新一次。
bdrdb=# select * from ping order by timestamp desc limit 10;bdrdb=# \watch 1
目前滚动显示空记录
id | node | timestamp----+------+-----------(0 rows)
表中插入记录
使用 Control-b ↓ Control-b → 或 Control-b q 3 返回 linuxhost-4主机窗口,该会话仍然登录到 psql 会话中,\q退出psql会话,回到shell环境中。
在shell终端环境中运行脚本给ping表插入记录:
[barman@linuxhost-4 ~]$while true; \do psql -h linuxhost-1,linuxhost-2,linuxhost-3 -p 6432 bdrdb -c \"INSERT INTO ping(node, timestamp) select node_name, current_timestamp from bdr.local_node_summary;";\done
在无限循环中,psql连接到三个代理节点中的任何一个,代理端口6432并选择 bdrdb 数据库。将两个值插入到 ping 表中。其中一个值来自bdr.local_node_summary,值为实际连接到的节点的名称。另一个值是当前时间。
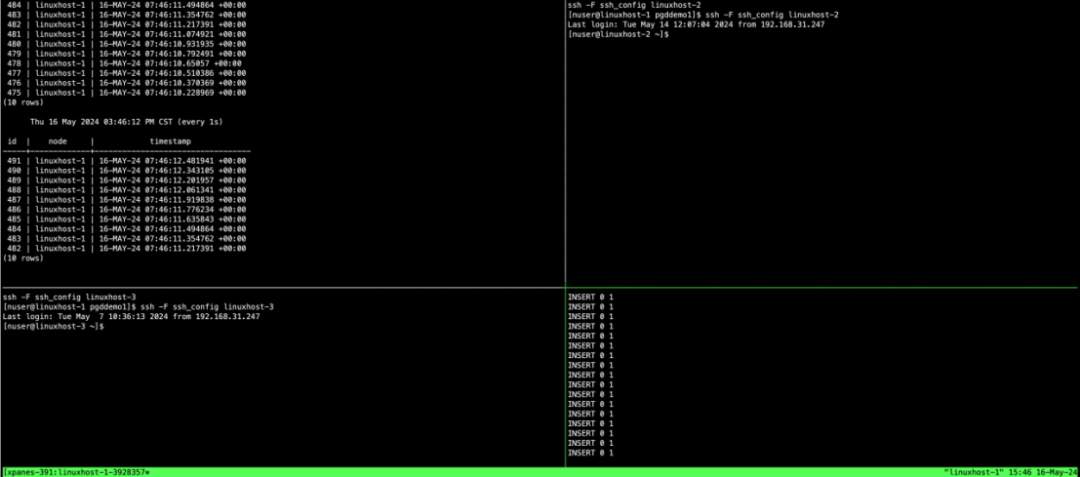
运行后会在左上方面窗口中看到滚动的记录。
查看当前集群的write leader
使用 Control-b ← 或 Control-b q 2 将焦点切换到linuxhost-3(左下窗口),sudo到enterprisedb用户,在终端窗口下运行pgd-cli相关命令相看集群的相关信息。
[enterprisedb@linuxhost-3:~ ]$ pgd show-groupsGroup Group ID Type Parent Group Location Raft Routing Write Leader------------- -------- ------ ------------ -------- ----- ------ -----------pgddemo1 1394575963 global true falsedatacenter1_subgroup 1488060427 data pgddemo1 datacenter1 true true linuxhost-1
目前显示linuxhost-1是write leader
全局组pgddemo1包括所有子组。这里datacenter1_subgroup是我们正在使用的数据集群。组名称来自于我们配置时,定义集群时的数据中心名称datacenter1。在多数据中心多位置环境中,每个数据中心都有自己的子组,因此我们可以独立管理,而不依整于其他数据中心位置或集群。
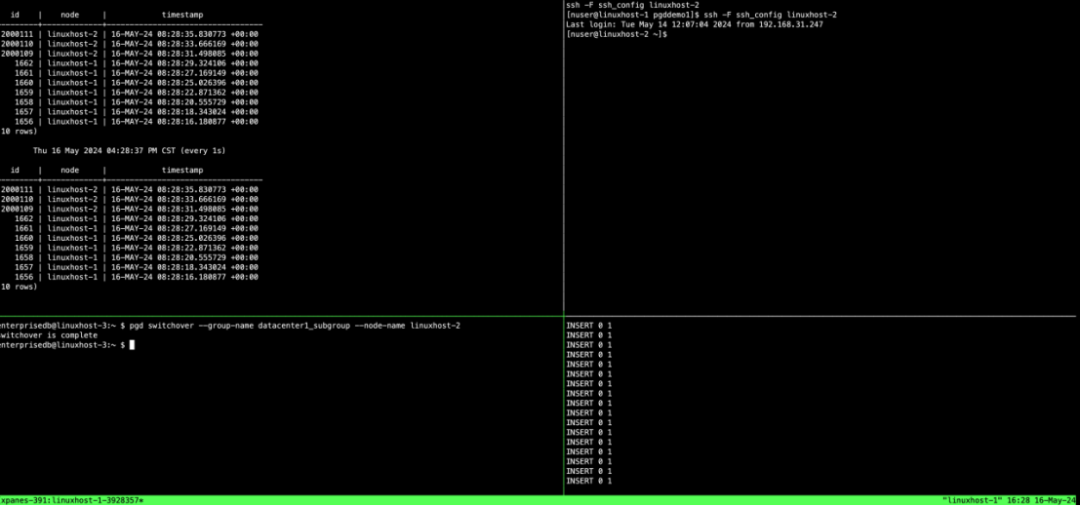
我们可以向集群发送切换命令来更改write leader到linuxhost-2上。
[enterprisedb@linuxhost-3:~ ]$ pgd switchover --group-name datacenter1_subgroup --node-name linuxhost-2switchover is complete
此时窗口0和窗口3还在循环运行插入指令,在切换前窗口0表记录id从1开始增加,且node字段显示为linuxhost-1。切换后,表记录id会跳跃到另外一个起时段值(本例2000001)开始增加,且node字段显示为linuxhost-2,整个过程是插入记录是没有中断的,如下图所示:
注意:生成的 ID 号也来自完全不同的值范围。这是因为系统透明地使生成 ID 的序列成为全局序列。可以查看有关全局序列及其在Sequences中如何工作的更多信息。
节点失败测试
能够切换write leader写领导者对于计划性维护很有用;下面我们验证节点失败的情况,目前我们环境的write leader是linuxhost-2
enterprisedb@linuxhost-1:~ $ pgd show-groupsGroup Group ID Type Parent Group Location Raft Routing Write Leader----- -------- ---- ------------ -------- ---- ------- ------------pgddemo1 1394575963 global true falsedatacenter1_subgroup 1488060427 data pgddemo1 datacenter1 true true linuxhost-2
通过 Control-b ↑ Control-b → 或 Control-b q 1 将焦点更改到右上方窗格,这是linuxhost-2主机的会话。通过运行以下命令关闭 Postgres 服务器:
[nuser@linuxhost-2 ~]$ sudo systemctl stop postgres.service
在左上方窗格中,当集群子组选择新的写领导者时,会看到受监控的表从linuxhost-2切换到另一个节点。当更新被取消时,右下窗格中的脚本可能会显示一些错误。然而,一旦选出新的写领导者,它就会开始将流量路由到该写领导者。
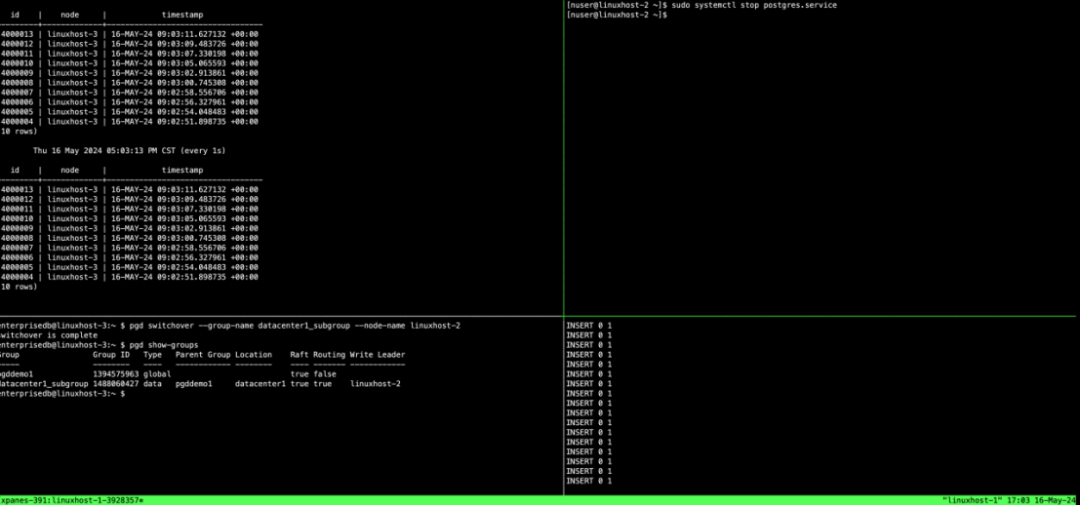
我们看到node自动切换到linuxhost-3,插入脚本继续运行。
使用 Control-b ↓ Control-b ← 或 Control-b q 2 切换到左下窗格,然后运行:
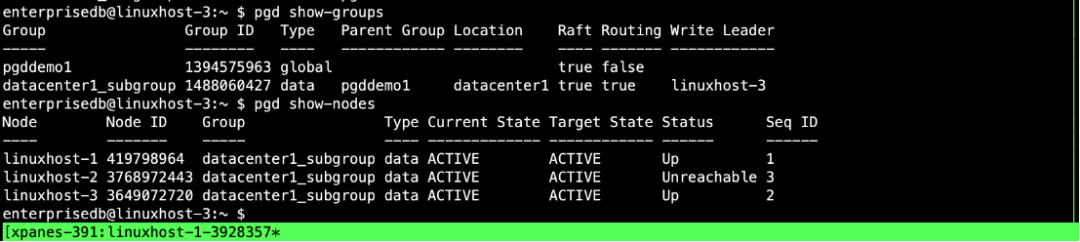
pgd show-groups 显示write leader为linuxhost-3
pgd show-nodes 显示linuxhost-2状态为Unreachable不可达状态。此时linuxhost-2节点的服务不可用。
监控lag
当linuxhost-2停机时,PGD核心的逻辑复制正在跟踪linuxhost-2与集群不同步的程度。运行命令查看:
enterprisedb@linuxhost-3:~ $ psql bdrdb -c "select * from bdr.node_replication_rates;"peer_node_id | target_name | sent_lsn | replay_lsn | replay_lag | replay_lag_bytes | replay_lag_size | apply_rate | catchup_interval----------+----------+----------+------------+------------+-----------+---------+------------+---------------419798964 | linuxhost-1 | 0/2A7B2A90 | 0/2A7B2A90 | 00:00:00.001432 | 0 | 0 bytes | 322 | 00:00:00| linuxhost-2 | 0/2A767E50 | 0/2A767E50 | 00:11:24.378295 | 306240 | 299 kB | |
可以看到linuxhost-2有11分半的时间重播延迟,如果现在返回,则需要大约 299KB 的数据来追赶。linuxhost-2失败的时间越长,重放延迟就越大。如果重新运行监控命令,将会看到数字的增加。
重启节点
使用 Control-b ↑ Control-b → 或 Control-b q 1 切换回右上方窗格,然后运行:
sudo systemctl start postgres.service
这时不会看到任何变化。尽管数据库服务已备份并开始运行,但集群未进行选举,因此write leader写领导者仍然在linuxhost-3。
使用 Control-b ↓ Control-b ← 或 Control-b q 2 切换到左下窗格,然后运行:
pgd show-nodesenterprisedb@linuxhost-3:~ $ pgd show-nodesNode Node ID Group Type Current State Target State Status Seq ID---- ------- ----- ---- ------------- ------------ ------ ------linuxhost-1 419798964 datacenter1_subgroup data ACTIVE ACTIVE Up 1linuxhost-2 3768972443 datacenter1_subgroup data ACTIVE ACTIVE Up 3linuxhost-3 3649072720 datacenter1_subgroup data ACTIVE ACTIVE Up 2
linuxhost-2一旦回到集群中,它就开始与集群同步。它通过追赶重播数据来实现。再次运行查看replay lag状态。
enterprisedb@linuxhost-3:~ $ psql bdrdb -c "select * from bdr.node_replication_rates;"

现在linuxhost-2已经没有重播延迟了,因为linuxhost-2已经完全自动赶上了。
随着linuxhos-2完全恢复使用,我们可以保持一切不变。无需更改写领导者的服务器。故障转移机制随时准备在需要时将另一台服务器提升为写领导者。
三、 pgd proxy代理故障转移
pgd proxy代理也可以进行故障转移。下面我们来进行验证,请确保您的焦点仍在左下窗格上,然后运行:
pgd show-proxiesenterprisedb@linuxhost-3:~ $ pgd show-proxiesProxy Group Listen Addresses Listen Port----- ----- ---------------- -----------linuxhost-1 datacenter1_subgroup [0.0.0.0] 6432linuxhost-2 datacenter1_subgroup [0.0.0.0] 6432linuxhost-3 datacenter1_subgroup [0.0.0.0] 6432
退出enterprisedb用户,在nuser用户下运行:
sudo systemctl stop pgd-proxy.service
当脚本切换到另一个代理时,右下窗口中会出现一个简短的错误。不过,写领导者不会更改,因此代理的切换不会显示在运行监视器查询的左上角窗格中。
恢复linuxhost-2上的proxy服务。
sudo systemctl start pgd-proxy.service
最后,快速退出Tmux和所有关联的会话。首先终止任何正在运行的进程,否则它们还是会在会话终止后继续运行。按 Control-B,然后输入 :kill-session。这种方法比使用 Control-D 或 exit 一次退出每个窗格的会话更简单。
四、 其他场景
本示例采用3个数据节点和1个备份节点的快速启动配置。我们也可以将集群配置为具有两个数据节点和一个见证节点,这对节点故障的恢复能力较差。或者,也可以配置五个数据节点,这对节点故障的恢复能力要强得多。通过此配置,您可以探索应用程序的故障转移如何工作。对于具有多个数据中心位置的集群配置,适用相同的基本规则:关闭服务节点,pgd会自动选举出新的write leader写领导者,不间断对外提供服务。
发现“分享”和“赞”了吗,戳我看看吧
