




一、确定恢复的起点
-
选取最近发生的那次
checkpoint的信息。 -
衡量
checkpoint发生时间早晚的信息就是所谓的checkpoint_no,只要把checkpoint1和checkpoint2这两个block中的checkpoint_no值读出来比一下大小,哪个的checkpoint_no值更大,说明哪个block存储的就是最近的一次checkpoint信息。这样就能拿到最近发生的checkpoint对应的checkpoint_lsn值以及它在redo日志文件组中的偏移量checkpoint_offset。 -
为什么要把
checkpoint信息存储到2个block中? -
万一就在某次写
checkpoint信息的过程中MySQL崩溃了,有可能导致正在写入的这个block中的checkpoint信息不正确。这种情况下,另一个block中的checkpoint信息肯定是正确的了,因为它里面的信息是上一次正常写入的。 -
能够用这种冗余方式来保证
checkpoint block的安全性,基于一个前提:last_checkpoint_lsn不需要那么精确。 -
last_checkpoint_lsn比实际需要应用Redo日志起点处的lsn小是没关系的,不会造成数据页不正确,应用Redo日志时会过滤已经刷盘的脏页对应的Redo日志。
二、确定恢复的终点

- 普通block的
log block header部分有一个称之为LOG_BLOCK_HDR_DATA_LEN的属性,该属性值记录了当前block里使用了多少字节的空间。对于被填满的block来说,该值永远为512。如果该属性的值不为512,那么就是它了,它就是此次崩溃恢复中需要扫描的最后一个block。
三、怎么恢复
1、恢复checkpoint_lsn前面的日志

2、使用哈希表根据redo日志的space ID和page number属性计算出散列值,把space ID和page number相同的redo日志按顺序放到哈希表的同一个槽里
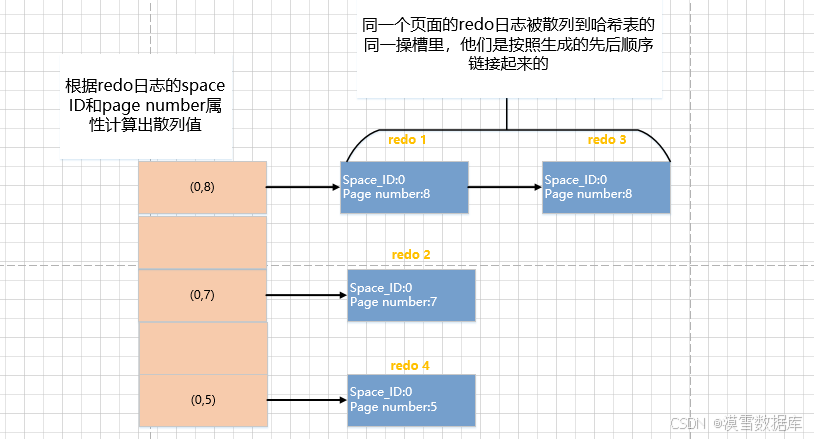
3、遍历哈希表,将同一个槽内的页面一次性修复好
4、跳过已经刷新到磁盘的页面
如果在做了某次checkpoint之后有脏页被刷新到磁盘中,那么该页对应的FIL_PAGE_LSN代表的lsn值肯定大于checkpoint_lsn的值,凡是符合这种情况的页面就不需要重复执行lsn值小于FIL_PAGE_LSN的redo日志了,所以更进一步提升了崩溃恢复的速度。
四、源码分析
本节将针对崩溃恢复前的解析工作和崩溃恢复后的结束工作的源码进行分析。
4.1 解析前解析工作
recv_recovery_from_checkpoint_start()函数流程
dberr_t
recv_recovery_from_checkpoint_start(
lsn_t flush_lsn)
{
log_group_t* group;
log_group_t* max_cp_group;
ulint max_cp_field;
lsn_t checkpoint_lsn;
bool rescan;
ib_uint64_t checkpoint_no;
lsn_t contiguous_lsn;
byte* buf;
byte log_hdr_buf[LOG_FILE_HDR_SIZE];
dberr_t err;
/* Initialize red-black tree for fast insertions into the
flush_list during recovery process. */
buf_flush_init_flush_rbt();
if (srv_force_recovery >= SRV_FORCE_NO_LOG_REDO) {
ib::info() << "The user has set SRV_FORCE_NO_LOG_REDO on,"
" skipping log redo";
return(DB_SUCCESS);
}
recv_recovery_on = true;
log_mutex_enter();
/* Look for the latest checkpoint from any of the log groups */
err = recv_find_max_checkpoint(&max_cp_group, &max_cp_field);
if (err != DB_SUCCESS) {
log_mutex_exit();
return(err);
}
log_group_header_read(max_cp_group, max_cp_field);
buf = log_sys->checkpoint_buf;
checkpoint_lsn = mach_read_from_8(buf + LOG_CHECKPOINT_LSN);
checkpoint_no = mach_read_from_8(buf + LOG_CHECKPOINT_NO);
/* Read the first log file header to print a note if this is
a recovery from a restored InnoDB Hot Backup */
const page_id_t page_id(max_cp_group->space_id, 0);
fil_io(IORequestLogRead, true, page_id, univ_page_size, 0,
LOG_FILE_HDR_SIZE, log_hdr_buf, max_cp_group);
if (0 == ut_memcmp(log_hdr_buf + LOG_HEADER_CREATOR,
(byte*)"ibbackup", (sizeof "ibbackup") - 1)) {
if (srv_read_only_mode) {
log_mutex_exit();
ib::error() << "Cannot restore from mysqlbackup,"
" InnoDB running in read-only mode!";
return(DB_ERROR);
}
/* This log file was created by mysqlbackup --restore: print
a note to the user about it */
ib::info() << "The log file was created by mysqlbackup"
" --apply-log at "
<< log_hdr_buf + LOG_HEADER_CREATOR
<< ". The following crash recovery is part of a"
" normal restore.";
/* Replace the label. */
ut_ad(LOG_HEADER_CREATOR_END - LOG_HEADER_CREATOR
>= sizeof LOG_HEADER_CREATOR_CURRENT);
memset(log_hdr_buf + LOG_HEADER_CREATOR, 0,
LOG_HEADER_CREATOR_END - LOG_HEADER_CREATOR);
strcpy(reinterpret_cast<char*>(log_hdr_buf)
+ LOG_HEADER_CREATOR, LOG_HEADER_CREATOR_CURRENT);
/* Write to the log file to wipe over the label */
fil_io(IORequestLogWrite, true, page_id,
univ_page_size, 0, OS_FILE_LOG_BLOCK_SIZE, log_hdr_buf,
max_cp_group);
}
/* Start reading the log groups from the checkpoint lsn up. The
variable contiguous_lsn contains an lsn up to which the log is
known to be contiguously written to all log groups. */
recv_sys->mlog_checkpoint_lsn = 0;
ut_ad(RECV_SCAN_SIZE <= log_sys->buf_size);
ut_ad(UT_LIST_GET_LEN(log_sys->log_groups) == 1);
group = UT_LIST_GET_FIRST(log_sys->log_groups);
ut_ad(recv_sys->n_addrs == 0);
contiguous_lsn = checkpoint_lsn;
switch (group->format) {
case 0:
log_mutex_exit();
return(recv_log_format_0_recover(checkpoint_lsn));
case LOG_HEADER_FORMAT_CURRENT:
break;
default:
ut_ad(0);
recv_sys->found_corrupt_log = true;
log_mutex_exit();
return(DB_ERROR);
}
/** Scan the redo log from checkpoint lsn and redo log to
the hash table. */
rescan = recv_group_scan_log_recs(group, &contiguous_lsn, false);
if ((recv_sys->found_corrupt_log && !srv_force_recovery)
|| recv_sys->found_corrupt_fs) {
log_mutex_exit();
return(DB_ERROR);
}
if (recv_sys->mlog_checkpoint_lsn == 0) {
if (!srv_read_only_mode
&& group->scanned_lsn != checkpoint_lsn) {
ib::error() << "Ignoring the redo log due to missing"
" MLOG_CHECKPOINT between the checkpoint "
<< checkpoint_lsn << " and the end "
<< group->scanned_lsn << ".";
if (srv_force_recovery < SRV_FORCE_NO_LOG_REDO) {
log_mutex_exit();
return(DB_ERROR);
}
}
group->scanned_lsn = checkpoint_lsn;
rescan = false;
}
/* NOTE: we always do a 'recovery' at startup, but only if
there is something wrong we will print a message to the
user about recovery: */
if (checkpoint_lsn != flush_lsn) {
if (checkpoint_lsn + SIZE_OF_MLOG_CHECKPOINT < flush_lsn) {
ib::warn() << " Are you sure you are using the"
" right ib_logfiles to start up the database?"
" Log sequence number in the ib_logfiles is "
<< checkpoint_lsn << ", less than the"
" log sequence number in the first system"
" tablespace file header, " << flush_lsn << ".";
}
if (!recv_needed_recovery) {
ib::info() << "The log sequence number " << flush_lsn
<< " in the system tablespace does not match"
" the log sequence number " << checkpoint_lsn
<< " in the ib_logfiles!";
if (srv_read_only_mode) {
ib::error() << "Can't initiate database"
" recovery, running in read-only-mode.";
log_mutex_exit();
return(DB_READ_ONLY);
}
recv_init_crash_recovery();
}
}
log_sys->lsn = recv_sys->recovered_lsn;
if (recv_needed_recovery) {
err = recv_init_crash_recovery_spaces();
if (err != DB_SUCCESS) {
log_mutex_exit();
return(err);
}
if (rescan) {
contiguous_lsn = checkpoint_lsn;
recv_group_scan_log_recs(group, &contiguous_lsn, true);
if ((recv_sys->found_corrupt_log
&& !srv_force_recovery)
|| recv_sys->found_corrupt_fs) {
log_mutex_exit();
return(DB_ERROR);
}
}
} else {
ut_ad(!rescan || recv_sys->n_addrs == 0);
}
/* We currently have only one log group */
if (group->scanned_lsn < checkpoint_lsn
|| group->scanned_lsn < recv_max_page_lsn) {
ib::error() << "We scanned the log up to " << group->scanned_lsn
<< ". A checkpoint was at " << checkpoint_lsn << " and"
" the maximum LSN on a database page was "
<< recv_max_page_lsn << ". It is possible that the"
" database is now corrupt!";
}
if (recv_sys->recovered_lsn < checkpoint_lsn) {
log_mutex_exit();
/* No harm in trying to do RO access. */
if (!srv_read_only_mode) {
ut_error;
}
return(DB_ERROR);
}
/* Synchronize the uncorrupted log groups to the most up-to-date log
group; we also copy checkpoint info to groups */
log_sys->next_checkpoint_lsn = checkpoint_lsn;
log_sys->next_checkpoint_no = checkpoint_no + 1;
recv_synchronize_groups();
if (!recv_needed_recovery) {
ut_a(checkpoint_lsn == recv_sys->recovered_lsn);
} else {
srv_start_lsn = recv_sys->recovered_lsn;
}
ut_memcpy(log_sys->buf, recv_sys->last_block, OS_FILE_LOG_BLOCK_SIZE);
log_sys->buf_free = (ulint) log_sys->lsn % OS_FILE_LOG_BLOCK_SIZE;
log_sys->buf_next_to_write = log_sys->buf_free;
log_sys->write_lsn = log_sys->lsn;
log_sys->last_checkpoint_lsn = checkpoint_lsn;
if (!srv_read_only_mode) {
/* Write a MLOG_CHECKPOINT marker as the first thing,
before generating any other redo log. */
fil_names_clear(log_sys->last_checkpoint_lsn, true);
}
MONITOR_SET(MONITOR_LSN_CHECKPOINT_AGE,
log_sys->lsn - log_sys->last_checkpoint_lsn);
log_sys->next_checkpoint_no = checkpoint_no + 1;
mutex_enter(&recv_sys->mutex);
recv_sys->apply_log_recs = TRUE;
mutex_exit(&recv_sys->mutex);
log_mutex_exit();
recv_lsn_checks_on = true;
/* The database is now ready to start almost normal processing of user
transactions: transaction rollbacks and the application of the log
records in the hash table can be run in background. */
return(DB_SUCCESS);
}
1、在设置全局状态 recv_recovery_on = true之前,调用buf_flush_init_flush_rbt(),该函数为每个instance的flush list初始化了红黑树,在NCNDB中将该部分工作放到buf_pool_init()完成。
2、检查强制恢复模式:
- 如果服务器被设置为强制不进行日志重做(SRV_FORCE_NO_LOG_REDO),则函数会跳过日志重做步骤并返回成功。
if (srv_force_recovery >= SRV_FORCE_NO_LOG_REDO) {
ib::info() << "The user has set SRV_FORCE_NO_LOG_REDO on,"
" skipping log redo";
return(DB_SUCCESS);
}
3、设置恢复状态:
- 将
recv_recovery_on标志设置为true,表示开始恢复过程。
4、查找最大检查点:
- 通过调用
recv_find_max_checkpoint函数,在日志组中找到最新的检查点。
5、读取检查点信息:
- 从找到的最大检查点对应的日志组中读取检查点信息,包括检查点日志序列号(LSN)和检查点编号。
buf = log_sys->checkpoint_buf; checkpoint_lsn = mach_read_from_8(buf + LOG_CHECKPOINT_LSN); checkpoint_no = mach_read_from_8(buf + LOG_CHECKPOINT_NO);
6、检查日志文件创建者:
- 通过比较日志文件头中的创建者标识(
creator),判断日志文件是否由mysqlbackup工具创建。如果是,并且服务器处于只读模式,则报错并退出,因为无法从mysqlbackup创建的备份中恢复。
const page_id_t page_id(max_cp_group->space_id, 0);
fil_io(IORequestLogRead, true, page_id, univ_page_size, 0,
LOG_FILE_HDR_SIZE, log_hdr_buf, max_cp_group);
if (0 == ut_memcmp(log_hdr_buf + LOG_HEADER_CREATOR,
(byte*)"ibbackup", (sizeof "ibbackup") - 1)) {
if (srv_read_only_mode) {
log_mutex_exit();
ib::error() << "Cannot restore from mysqlbackup,"
" InnoDB running in read-only mode!";
return(DB_ERROR);
}
/* This log file was created by mysqlbackup --restore: print
a note to the user about it */
ib::info() << "The log file was created by mysqlbackup"
" --apply-log at "
<< log_hdr_buf + LOG_HEADER_CREATOR
<< ". The following crash recovery is part of a"
" normal restore.";
/* Replace the label. */
ut_ad(LOG_HEADER_CREATOR_END - LOG_HEADER_CREATOR
>= sizeof LOG_HEADER_CREATOR_CURRENT);
memset(log_hdr_buf + LOG_HEADER_CREATOR, 0,
LOG_HEADER_CREATOR_END - LOG_HEADER_CREATOR);
strcpy(reinterpret_cast<char*>(log_hdr_buf)
+ LOG_HEADER_CREATOR, LOG_HEADER_CREATOR_CURRENT);
/* Write to the log file to wipe over the label */
fil_io(IORequestLogWrite, true, page_id,
univ_page_size, 0, OS_FILE_LOG_BLOCK_SIZE, log_hdr_buf,
max_cp_group);
}
7、日志格式处理:
- 根据日志文件的格式,执行相应的恢复操作。如果日志格式未知或损坏,则设置错误标志并返回错误。
recv_sys->mlog_checkpoint_lsn = 0;
ut_ad(RECV_SCAN_SIZE <= log_sys->buf_size);
ut_ad(UT_LIST_GET_LEN(log_sys->log_groups) == 1);
group = UT_LIST_GET_FIRST(log_sys->log_groups);
ut_ad(recv_sys->n_addrs == 0);
contiguous_lsn = checkpoint_lsn;
switch (group->format) {
case 0:
log_mutex_exit();
return(recv_log_format_0_recover(checkpoint_lsn));
case LOG_HEADER_FORMAT_CURRENT:
break;
default:
ut_ad(0);
recv_sys->found_corrupt_log = true;
log_mutex_exit();
return(DB_ERROR);
}
8、扫描日志记录:
- 通过
recv_group_scan_log_recs函数扫描日志记录,并根据需要决定是否重新扫描。
rescan = recv_group_scan_log_recs(group, &contiguous_lsn, false);
if ((recv_sys->found_corrupt_log && !srv_force_recovery)
|| recv_sys->found_corrupt_fs) {
log_mutex_exit();
return(DB_ERROR);
}
if (recv_sys->mlog_checkpoint_lsn == 0) {
if (!srv_read_only_mode
&& group->scanned_lsn != checkpoint_lsn) {
ib::error() << "Ignoring the redo log due to missing"
" MLOG_CHECKPOINT between the checkpoint "
<< checkpoint_lsn << " and the end "
<< group->scanned_lsn << ".";
if (srv_force_recovery < SRV_FORCE_NO_LOG_REDO) {
log_mutex_exit();
return(DB_ERROR);
}
}
group->scanned_lsn = checkpoint_lsn;
rescan = false;
}
9、检查日志和检查点的一致性:
- 比较检查点LSN和传入的
flush_lsn(系统表空间中的LSN),检查是否一致。如果不一致,可能需要执行崩溃恢复。
if (checkpoint_lsn != flush_lsn) {
if (checkpoint_lsn + SIZE_OF_MLOG_CHECKPOINT < flush_lsn) {
ib::warn() << " Are you sure you are using the"
" right ib_logfiles to start up the database?"
" Log sequence number in the ib_logfiles is "
<< checkpoint_lsn << ", less than the"
" log sequence number in the first system"
" tablespace file header, " << flush_lsn << ".";
}
if (!recv_needed_recovery) {
ib::info() << "The log sequence number " << flush_lsn
<< " in the system tablespace does not match"
" the log sequence number " << checkpoint_lsn
<< " in the ib_logfiles!";
if (srv_read_only_mode) {
ib::error() << "Can't initiate database"
" recovery, running in read-only-mode.";
log_mutex_exit();
return(DB_READ_ONLY);
}
recv_init_crash_recovery();
}
}
10、初始化崩溃恢复:
- 如果需要执行崩溃恢复,则初始化相关的恢复步骤。
log_sys->lsn = recv_sys->recovered_lsn;
if (recv_needed_recovery) {
err = recv_init_crash_recovery_spaces();
if (err != DB_SUCCESS) {
log_mutex_exit();
return(err);
}
if (rescan) {
contiguous_lsn = checkpoint_lsn;
recv_group_scan_log_recs(group, &contiguous_lsn, true);
if ((recv_sys->found_corrupt_log
&& !srv_force_recovery)
|| recv_sys->found_corrupt_fs) {
log_mutex_exit();
return(DB_ERROR);
}
}
} else {
ut_ad(!rescan || recv_sys->n_addrs == 0);
}
11、更新日志系统状态:
- 更新日志系统的状态,包括日志序列号、下一个检查点LSN和编号等。
log_sys->next_checkpoint_lsn = checkpoint_lsn;
log_sys->next_checkpoint_no = checkpoint_no + 1;
12、同步日志组:通过recv_synchronize_groups函数同步日志组的状态。
recv_synchronize_groups();
13、准备日志缓冲区:将最后一个日志块复制到日志缓冲区,并更新缓冲区的状态和写入LSN。
ut_memcpy(log_sys->buf, recv_sys->last_block, OS_FILE_LOG_BLOCK_SIZE); log_sys->buf_free = (ulint) log_sys->lsn % OS_FILE_LOG_BLOCK_SIZE; log_sys->buf_next_to_write = log_sys->buf_free; log_sys->write_lsn = log_sys->lsn; log_sys->last_checkpoint_lsn = checkpoint_lsn;
14、清除文件名称:
- 如果服务器不在只读模式下,调用
fil_names_clear()函数清除与最后一个检查点LSN相关的文件名称。
15、设置恢复标志:
- 设置
recv_sys->apply_log_recs为TRUE,表示可以开始应用日志记录了。
16、开启LSN检查:
- 设置
recv_lsn_checks_on为true,表示开启LSN的检查。
17、返回成功:
- 如果所有步骤都成功完成,则返回
DB_SUCCESS。
4.2 崩溃恢复结束
recv_recovery_from_checkpoint_finish()函数流程
void
recv_recovery_from_checkpoint_finish(void)
{
mutex_enter(&recv_sys->writer_mutex);
recv_recovery_on = false;
buf_flush_wait_LRU_batch_end(); // 等待缓冲池flush链表完成操作
mutex_exit(&recv_sys->writer_mutex);
ulint count = 0;
while (recv_writer_thread_active) {
++count;
os_thread_sleep(100000);
if (srv_print_verbose_log && count > 600) {
ib::info() << "Waiting for recv_writer to"
" finish flushing of buffer pool";
count = 0;
}
}
recv_sys_debug_free(); // 释放recv_sys结构
buf_flush_free_flush_rbt(); // 释放红黑树结构
mtr_t mtr;
buf_block_t* block;
mtr.start();
mtr.set_sys_modified();
block = buf_page_get(
page_id_t(IBUF_SPACE_ID, FSP_IBUF_HEADER_PAGE_NO),
univ_page_size, RW_X_LATCH, &mtr);
fil_block_check_type(block, FIL_PAGE_TYPE_SYS, &mtr);
block = buf_page_get(
page_id_t(TRX_SYS_SPACE, TRX_SYS_PAGE_NO),
univ_page_size, RW_X_LATCH, &mtr);
fil_block_check_type(block, FIL_PAGE_TYPE_TRX_SYS, &mtr);
block = buf_page_get(
page_id_t(TRX_SYS_SPACE, FSP_FIRST_RSEG_PAGE_NO),
univ_page_size, RW_X_LATCH, &mtr);
fil_block_check_type(block, FIL_PAGE_TYPE_SYS, &mtr);
block = buf_page_get(
page_id_t(TRX_SYS_SPACE, FSP_DICT_HDR_PAGE_NO),
univ_page_size, RW_X_LATCH, &mtr);
fil_block_check_type(block, FIL_PAGE_TYPE_SYS, &mtr);
mtr.commit();
if (srv_force_recovery < SRV_FORCE_NO_TRX_UNDO) {
trx_rollback_or_clean_recovered(FALSE); // 回滚所有已恢复的数据字典事务,以便数据字典表不会被任何锁占用
}
}
1、确保recv_writer线程完成:
- 通过进入
recv_sys->writer_mutex互斥锁,确保recv_writer线程已经完成了它的工作。这是因为recv_writer线程会持有多个互斥锁,而我们希望在启用sync_order_checks时,没有任何线程持有互斥锁。
2、释放恢复系统的资源:
- 将
recv_recovery_on设置为false,表示恢复操作已经完成,可以释放相关资源。
3、等待LRU批次完成:
- 通过
buf_flush_wait_LRU_batch_end()函数,确保当前正在进行的LRU批次操作完成。这是在获取了writer_mutex互斥锁之后进行的,以确保recv_writer线程不会触发更多的LRU批次。
4、等待recv_writer线程完全停止:
- 使用一个循环,不断检查
recv_writer_thread_active标志,并在该线程仍然活跃时睡眠100,000微秒(即0.1秒)。如果启用了srv_print_verbose_log,并且已经等待超过60秒(即循环超过600次),则打印一条信息日志,表明正在等待recv_writer完成缓冲池的刷新。
ulint count = 0;
while (recv_writer_thread_active) {
++count;
os_thread_sleep(100000);
if (srv_print_verbose_log && count > 600) {
ib::info() << "Waiting for recv_writer to"
" finish flushing of buffer pool";
count = 0;
}
}
5、释放系统调试资源:
- 调用
recv_sys_debug_free()函数释放与恢复系统相关的调试资源。
6、释放flush_rbt:
- 调用
buf_flush_free_flush_rbt()函数释放与刷新操作相关的红黑树资源。
7、验证系统页面类型:
- 使用一个
mtr_t来确保某些系统页面类型被正确设置。这是为了修复旧版本MySQL中可能未正确初始化的页面类型。
mtr_t mtr;
buf_block_t* block;
mtr.start();
mtr.set_sys_modified();
/* Bitmap page types will be reset in buf_dblwr_check_block()
without redo logging. */
block = buf_page_get(
page_id_t(IBUF_SPACE_ID, FSP_IBUF_HEADER_PAGE_NO),
univ_page_size, RW_X_LATCH, &mtr);
fil_block_check_type(block, FIL_PAGE_TYPE_SYS, &mtr);
/* Already MySQL 3.23.53 initialized FSP_IBUF_TREE_ROOT_PAGE_NO
to FIL_PAGE_INDEX. No need to reset that one. */
block = buf_page_get(
page_id_t(TRX_SYS_SPACE, TRX_SYS_PAGE_NO),
univ_page_size, RW_X_LATCH, &mtr);
fil_block_check_type(block, FIL_PAGE_TYPE_TRX_SYS, &mtr);
block = buf_page_get(
page_id_t(TRX_SYS_SPACE, FSP_FIRST_RSEG_PAGE_NO),
univ_page_size, RW_X_LATCH, &mtr);
fil_block_check_type(block, FIL_PAGE_TYPE_SYS, &mtr);
block = buf_page_get(
page_id_t(TRX_SYS_SPACE, FSP_DICT_HDR_PAGE_NO),
univ_page_size, RW_X_LATCH, &mtr);
fil_block_check_type(block, FIL_PAGE_TYPE_SYS, &mtr);
mtr.commit();
8、回滚恢复的数据字典事务:
- 如果
srv_force_recovery低于SRV_FORCE_NO_TRX_UNDO,则调用trx_rollback_or_clean_recovered(FALSE)函数来回滚或清理恢复的数据字典事务。这确保了数据字典表不受任何锁的影响。
