




项目提要
主要知识点
scrapy中设置代理IP
scrapy架构中从一个组件向另一组件传递特定信息,譬如本文所说的目录名
settings文件需要处理的事项
大型项目的暂停与唤醒
爬虫目标
网上有一部漫画挺好看,手机浏览总是需要刷新浏览器——不友好啊,干脆我们把它爬取并存储到本地,即使以后收费了我们照样看。这部漫画叫《一人之下》
使用框架
scrapy
工作流程
分析网页
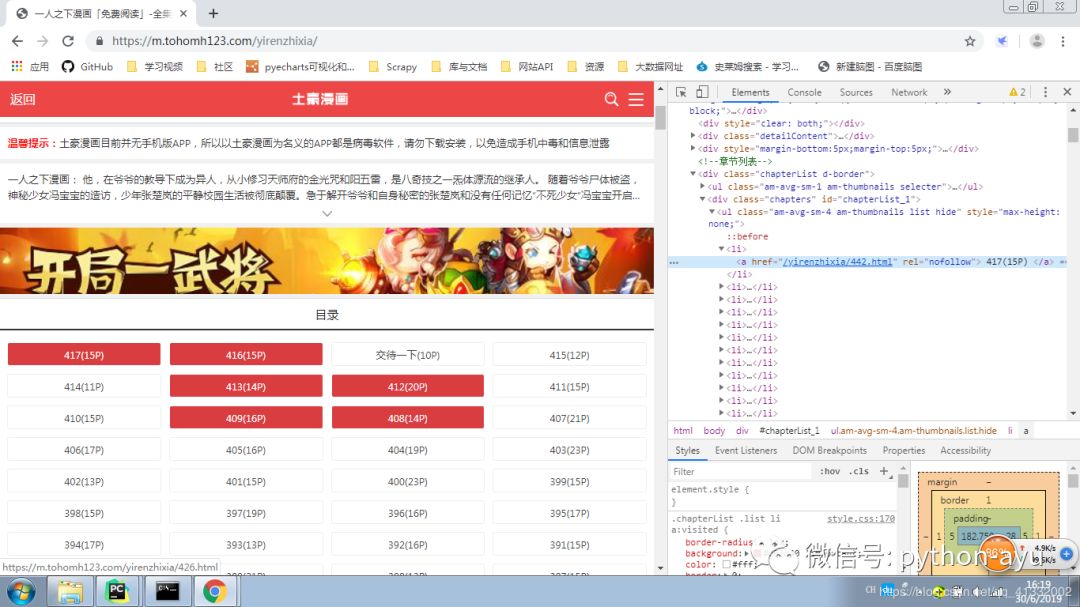
我们可以看见从章节目录页爬取章节URL很容易,有点难度的是从具体章节爬取相应的图片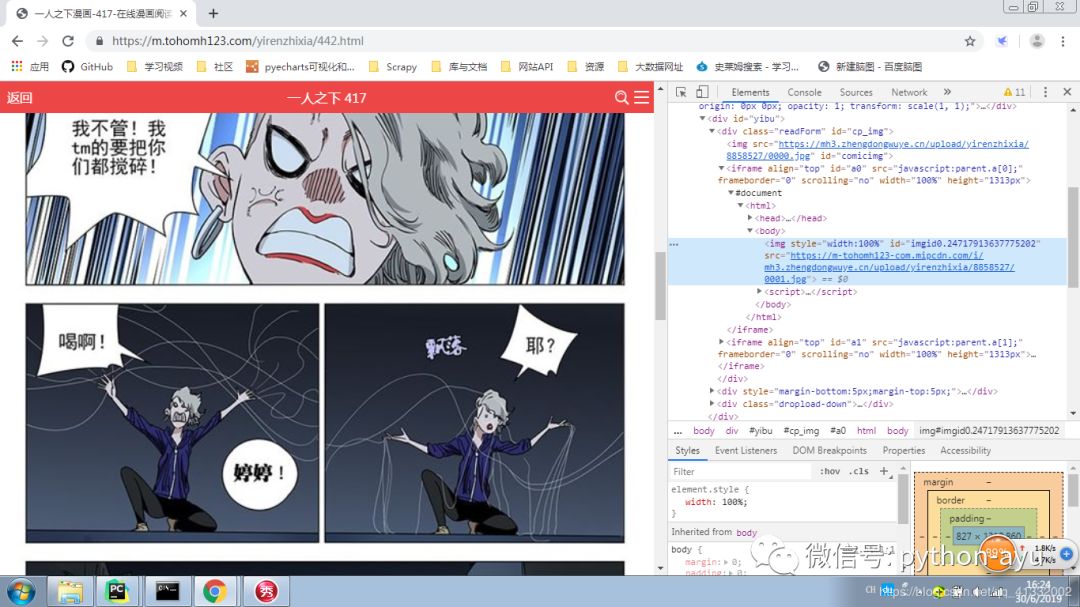
这里我们仔细看一下,页面是随着我们滚动鼠标而异步加载的,另外这里面有iframe——真是个糟糕的组合。
我们有两个解决方案:一是使用selenium来实现异步加载与虚拟鼠标滚动,听着就头大;二是找找json数据源。
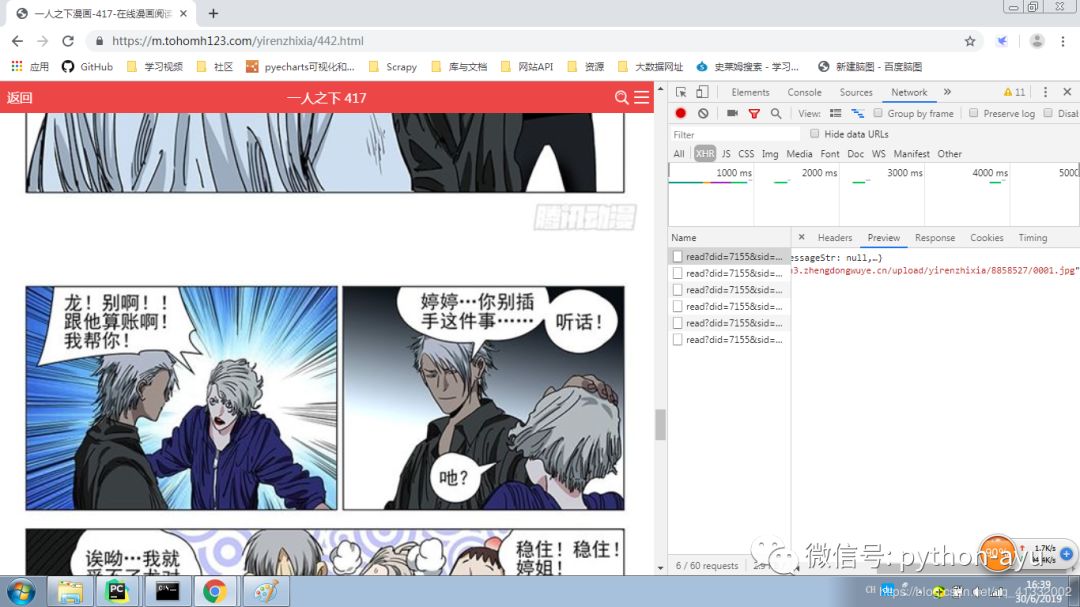
可以发现随着鼠标滚动XHR列不断有新的异步会话出现,点一下——有JSON数据,OK了
确定Item
import scrapyclass ManhuaItem(scrapy.Item):# define the fields for your item here like:# name = scrapy.Field()image_urls = scrapy.Field() #名字不要改images = scrapy.Field() #这两个名字是scrapy.pipelines.images. ImagesPipeline定制的directory = scrapy.Field()
定制Pipeline
from scrapy.pipelines.images import ImagesPipelineimport scrapyclass ManhuaPipeline(ImagesPipeline):def get_media_requests(self, item, info):for img_url in item['image_urls']:yield scrapy.Request(img_url,meta={'directory':item['directory']})def file_path(self, request, response=None, info=None):'https://mh3.zhengdongwuye.cn/upload/yirenzhixia/4905770/0000.jpg' #这是一URL个样本# 提取url前面名称作为图片名。iid = request.url.split('/')[-1]directoy = request.meta['directory']return u'{}/{}'.format(directoy,iid)
有意思的是,手动写入文件的时候会遇到的“文件目录不存在”的问题被scrapy解决掉了——没有相应目录就会自动创建,很方便对不?
设置settings
BOT_NAME = 'manhua'SPIDER_MODULES = ['manhua.spiders']NEWSPIDER_MODULE = 'manhua.spiders'DOWNLOAD_DELAY = 2# The download delay setting will honor only one of:#CONCURRENT_REQUESTS_PER_DOMAIN = 16CONCURRENT_REQUESTS_PER_IP = 16COOKIES_ENABLED = FalseDEFAULT_REQUEST_HEADERS = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36',}DOWNLOADER_MIDDLEWARES = {'manhua.middlewares.ManhuaDownloaderMiddleware': 543,}PROXIES = ['http://140.143.142.14:1080','http://106.15.42.179:33543','https://119.27.177.238:8080','http://183.196.168.194:9000','http://117.191.11.111:8080','http://123.207.66.220:1080','https://210.34.24.103:3128','http://113.12.202.50:5032','http://117.191.11.112:80']ITEM_PIPELINES = {'manhua.pipelines.ManhuaPipeline': 300,}IMAGES_STORE = '某个目录'
编写Spider
# -*- coding: utf-8 -*-import scrapyfrom manhua.items import ManhuaItemimport jsonclass YirenzhixiaSpider(scrapy.Spider):name = 'yirenzhixia'# allowed_domins = ['tohomh123.com']def start_requests(self):''''想必大家能够搞明白这个meta是被我如何利用的'''for sid in range(1,442):for iid in range(1,20):read_url = 'https://m.tohomh123.com/action/play/read?did=7155&sid={}&iid={}'.format(str(sid),str(iid))yield scrapy.Request(read_url,callback=self.parse,meta={'directory':sid})def parse(self, response):link_data = json.loads(response.text)link = link_data["Code"]item = ManhuaItem()item['directory'] = response.meta['directory']item['image_urls'] = [link]if link:yield item
这里面唯一的难点是我通过meta来将目录名(也就是章节序号)传给file_path方法的过程。这里着重说两句…
meta是request的属性,通常为空字典。
meta通常的作用是加入代理IP
这里我们通过它来接力式的把目录名传给file_path方法
处理DownloaderMiddleWare
class ImgDownloaderMiddleware(ManhuaDownloaderMiddleware):''''我们仅仅需要定义三个方法即可完成代理IP的插入'''def __init__(self, ip=''):self.ip = ipdef from_crawler(cls, crawler):return cls(ip=crawler.settings.get('PROXIES'))def process_request(self, request, spider):ip = random.choice(self.ip)request.meta['proxy'] = ipreturn None
最后说说启动,使用scrapy爬取的时候,往往要发生至少几十万次的请求,我们很可能需要暂停与唤醒爬虫,那么问题来了,怎么做呢?
很简单,启动命令改成 “scrapy crawl 爬虫名称 -s JOBDIR=保存记录信息的路径” 就可以了。这样我们就可以放心的停止了,重启是同样的命令。详细的内容参考官方文档,搜一下’pause’或者’resume’
是不是挺有趣的,我用了4个多小时将422章全部下完,主要是消耗在等待上了,有问题或者建议可以留言,交流一下
————————————————
