




小编导读:
本文将重点介绍如何利用物化视图进行查询改写。文章将全面介绍物化视图的基本原理、关键特性、应用案例、使用场景、代码细节以及主流大数据产品的物化视图改写能力对比。
设计与创建:首先,我们需要仔细分析查询的特点,以选择构建最适合的物化视图。 视图维护:当基础表的数据发生变化时,物化视图也需要及时更新,以确保数据的一致性。 查询改写:利用预计算的数据,物化视图能有效地加速查询处理过程,提供更快的响应速度。

本文重点讨论物化视图的第三阶段:如何利用物化视图进行查询改写。StarRocks 的异步物化视图采用了广泛认可的 SPJG(Select-Projection-Join-Groupby)算法。这允许系统在用户无需修改任何查询的前提下,自动将原始查询转换为对物化视图的查询。借助物化视图中预计算的结果,这种自动化的查询改写大幅降低了计算代价,从而实现了显著的查询加速。
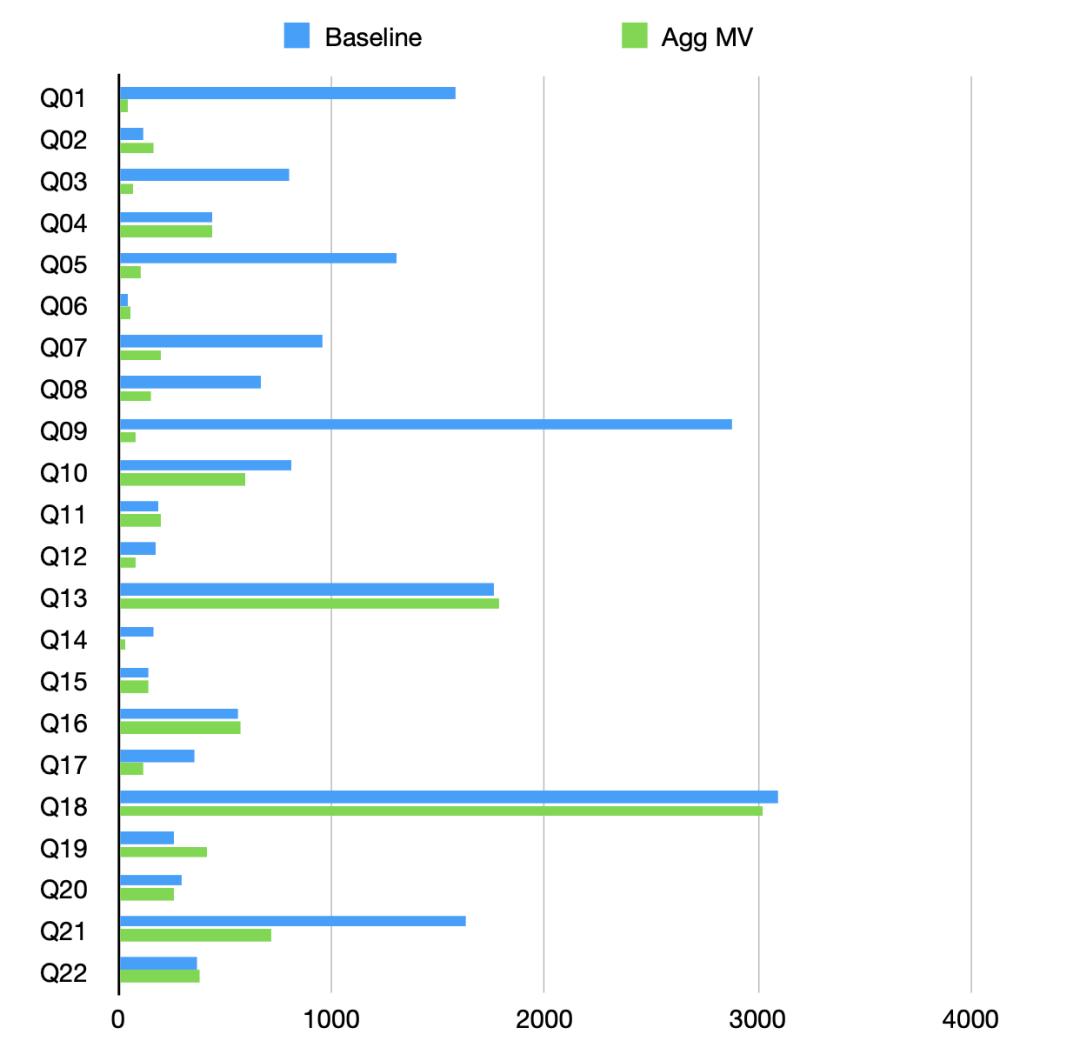
SSB 100GB:与传统的星形模型相比,物化视图能将总体查询耗时减少至原来的 1/3。
TPC-H 100GB:这种技术能加速一半的查询,平均耗时降至原来的 1/5。
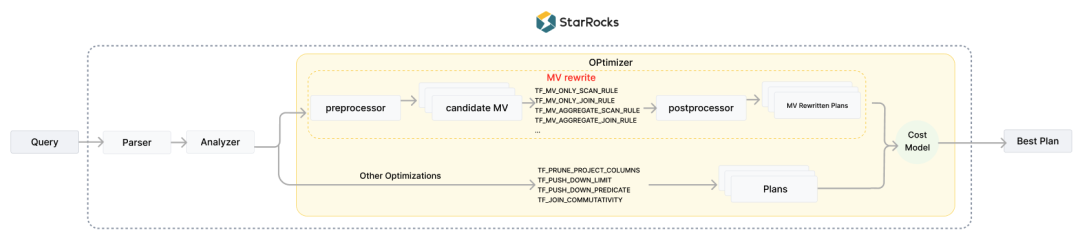
(StarRocks 物化视图改写流程)
预处理:在 Analyzer 处理后得到的逻辑计划树的基础上,系统会识别出相关的物化视图候选集。此阶段还包括过滤掉无法用于改写的物化视图,以缩小搜索空间并确保物化视图数据的新鲜度。 SPJG 物化视图改写:应用基于cost-based的 SPJG 物化视图改写规则,自动遍历搜索空间中可用于改写的子树,并尝试进行改写,并且最终会根据 Cost Model 选择最优的改写方案。 后处理:对物化视图改写后的 Plan 执行列裁剪、谓词下推、分区裁剪等优化操作,以提升改写后 Plan 的执行性能。
举例说明,对于一条具体的查询,物化视图的改写可以分为以下几个步骤处理:
预处理: 分析访问表:首先分析查询涉及的基表, 根据这些基表与物化视图之间的依赖关系,识别可能有用的物化视图 候选视图筛选:对于复杂的查询可能存在大量的候选物化视图,直接考虑所有视图会导致计算开销过大。因此,因此,需要根据视图的“适用性”对候选视图进行排序,并选择一个子集进行进一步分析 新鲜度验证:检查候选物化视图的数据新鲜度,若物化视图数据不满足查询的要求,则抛弃这些视图 TEXT 改写 当查询与某个物化视图在 AST tree/语法树结构上完全一致时,可以通过文本匹配直接将查询改写为对该视图的访问 SPJG 查询改写 SPJG 改写适用于查询与物化视图有所差异的场景,可以对物化视图进行补偿改写,提供了更大的灵活性,但实现上也更为复杂 在 SQL 优化器中应用多种规则来匹配视图和查询,对所有可能的 Query Plan 进行改写,这一过程的计算开销相对较高 改写后,对于产生的所有可能的改写结果,使用 Cost Model 来评估并选择最优的改写方案 后置处理 对改写后的查询计划应用更多优化器规则,如列裁剪、谓词下推和分区裁剪等
select sum(lo_revenue) as lo_revenue, d_year, p_brand
from lineorder
join dates on lo_orderdate = d_datekey
join part on lo_partkey = p_partkey
join supplier on lo_suppkey = s_suppkey
where p_category = 'MFGR#12' and s_region = 'AMERICA'
group by d_year, p_brand
order by d_year, p_brand;
除核心能力之外,StarRocks 物化视图自动改写还包括以下关键特性:
数据一致性: 内部表一致性:确保物化视图改写的结果与查询原始表结果完全一致,实现强数据一致性。 过期数据处理:支持配置数据过期容忍时间,适应数据频繁变更的场景,通过 staleness 改写技术应对数据变化。 复杂查询支持 多表 Join 支持:支持各种类型的 join,包括 view delta join 和 join derivability rewrite 等复杂 join 场景的改写,优化大宽表查询。 聚合查询加速:通过聚合改写技术加速聚合查询,提升报表查询性能。 嵌套视图改写:支持嵌套物化视图改写,解决复杂查询的改写问题,扩展改写范围。 复杂表达式支持:够处理包括函数调用和四则运算在内的复杂表达式,满足复杂的分析计算需求 实时数据融合 新鲜数据查询加速:利用 union 改写和 TTL 功能联合使用,加速新鲜数据查询,并实现历史数据自动回查原表。
多数据源支持 逻辑视图物化:允许在逻辑视图上创建物化视图,支持基于 view 建模的场景下的查询加速 外部表物化视图:支持包括 Hive、Iceberg、Hudi、DeltaLake、Paimon、JDBC(MySQL Dialet)等,提升数据湖场景下的查询性能
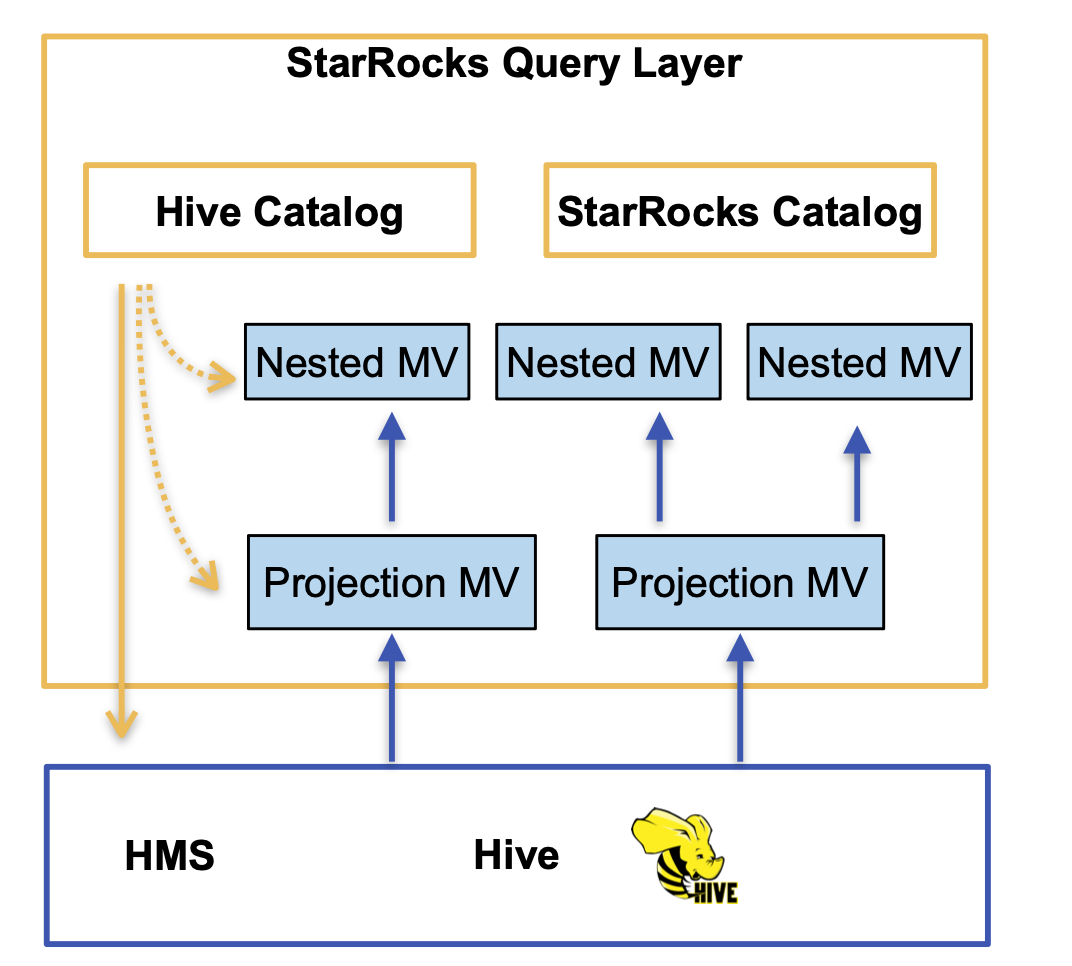
Projection MV:在 Hive Table 基础上创建 Projection MV,发挥 StarRocks 内表和存储引擎的性能,使得关键报表能够获得几倍的性能加速。由于 StarRocks MV 能够支持 Hive Table 的自动刷新,一次创建后几乎不需要后续的维护,从而大幅降低 ETL 的维护成本 嵌套视图:在 MV 的基础上,对复杂查询创建嵌套视图,以进一步加速关键报表查询。这些查询通常涉及 BI 场景中的典型操作,如 Join、Aggregation、多层聚合等复杂查询。 AutoMV:利用 AutoMV 能力,分析慢查询自动推荐出合适的物化视图,从而进一步减少了人工维护成本。
Join Rewrite
StarRocks 支持 join 查询改写,支持的 join 类型包括:Inner join/cross join/left outer join/full outer join/right outer join/semi join/anti join。
CREATE TABLE `customer` (
`c_custkey` int(11) NOT NULL COMMENT "",
`c_name` varchar(26) NOT NULL COMMENT "",
`c_address` varchar(41) NOT NULL COMMENT "",
`c_city` varchar(11) NOT NULL COMMENT "",
`c_nation` varchar(16) NOT NULL COMMENT "",
`c_region` varchar(13) NOT NULL COMMENT "",
`c_phone` varchar(16) NOT NULL COMMENT "",
`c_mktsegment` varchar(11) NOT NULL COMMENT ""
) ENGINE=OLAP
DUPLICATE KEY(`c_custkey`)
COMMENT "OLAP"
DISTRIBUTED BY HASH(`c_custkey`) BUCKETS 12
PROPERTIES (
"replication_num" = "1"
);
CREATE TABLE `lineorder` (
`lo_orderkey` int(11) NOT NULL COMMENT "",
`lo_linenumber` int(11) NOT NULL COMMENT "",
`lo_custkey` int(11) NOT NULL COMMENT "",
`lo_partkey` int(11) NOT NULL COMMENT "",
`lo_suppkey` int(11) NOT NULL COMMENT "",
`lo_orderdate` int(11) NOT NULL COMMENT "",
`lo_orderpriority` varchar(16) NOT NULL COMMENT "",
`lo_shippriority` int(11) NOT NULL COMMENT "",
`lo_quantity` int(11) NOT NULL COMMENT "",
`lo_extendedprice` int(11) NOT NULL COMMENT "",
`lo_ordtotalprice` int(11) NOT NULL COMMENT "",
`lo_discount` int(11) NOT NULL COMMENT "",
`lo_revenue` int(11) NOT NULL COMMENT "",
`lo_supplycost` int(11) NOT NULL COMMENT "",
`lo_tax` int(11) NOT NULL COMMENT "",
`lo_commitdate` int(11) NOT NULL COMMENT "",
`lo_shipmode` varchar(11) NOT NULL COMMENT ""
) ENGINE=OLAP
DUPLICATE KEY(`lo_orderkey`)
COMMENT "OLAP"
DISTRIBUTED BY HASH(`lo_orderkey`) BUCKETS 48
PROPERTIES (
"replication_num" = "1"
);
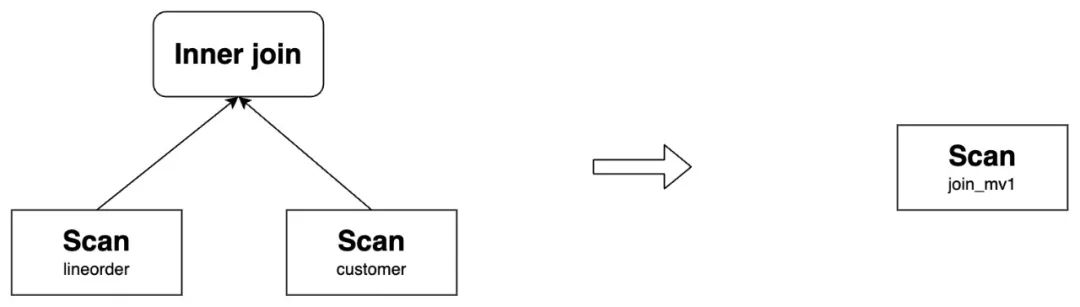
基于上述的表,构建物化视图-- MV
create materialized view join_mv1
distributed by hash(`lo_orderkey`)
as
select lo_orderkey, lo_linenumber, lo_revenue, lo_partkey, c_name, c_address
from lineorder inner join customer
on lo_custkey = c_custkey;则如下的查询可以被改写为查询 join_mv1
-- Query
select lo_orderkey, lo_linenumber, lo_revenue, c_name, c_address
from lineorder inner join customer
on lo_custkey = c_custkey;
select lo_orderkey, lo_linenumber, (2 * lo_revenue + 1) * lo_linenumber, upper(c_name), substr(c_address, 3)
from lineorder inner join customer
on lo_custkey = c_custkey;
上述的 join 改写场景是 Query 的 join 类型和表集合同 MV 相同的场景,StarRocks 中还扩展支持了以下几种 join 场景的改写。
select lo_orderkey, lo_linenumber, lo_revenue, c_name, c_address, p_name
from
lineorder inner join customer on lo_custkey = c_custkey
inner join part on lo_partkey = p_partkey
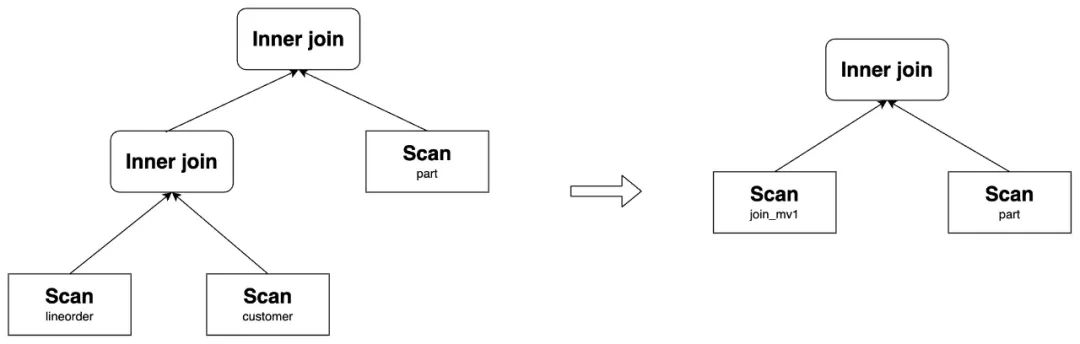
1.2 View delta join rewrite
View delta join 指的是在查询中,涉及的 join 表是物化视图中 join 表的子集。这种场景的改写能力通常适用于大宽表查询。例如,在 SSB 场景中,可以构建一个包含所有表的物化视图,将多个表 join 成一个大宽表。这样,所有 SSB 查询都可以通过物化视图的透明改写来提升查询性能。测试结果表明,通过物化视图改写后的多表 join 查询,其性能可达到直接查询大宽表的水平。
为了实现 view delta join 的改写,要求物化视图中的 join 必须与查询中的 join 具有1:1的 cardinality preservation(基数保持)关系。以下是 SSB 改写的示例。在满足下列的 join 条件时,都可以进行 cardinality preservation join 改写。任何满足其中一种条件的 join,都能够进行 view delta join 的改写。
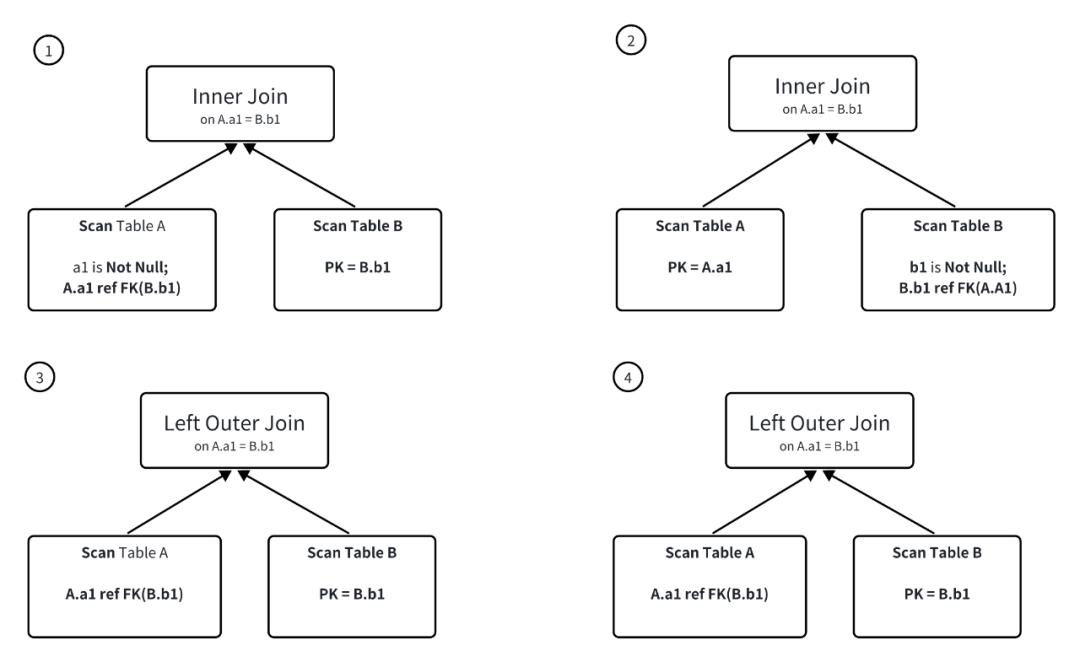
在 StarRocks 中, 可以用以下语法指定主外键关系:
CREATE TABLE `customer` (...)
PROPERTIES (
"unique_constraints" = "c_custkey" #指定唯一键
);
CREATE TABLE `lineorder` (...)
PROPERTIES (
"foreign_key_constraints" = "(lo_custkey) REFERENCES customer(c_custkey);(lo_partkey) REFERENCES part(p_partkey);(lo_suppkey) REFERENCES supplier(s_suppkey)" #指定外键约束
);
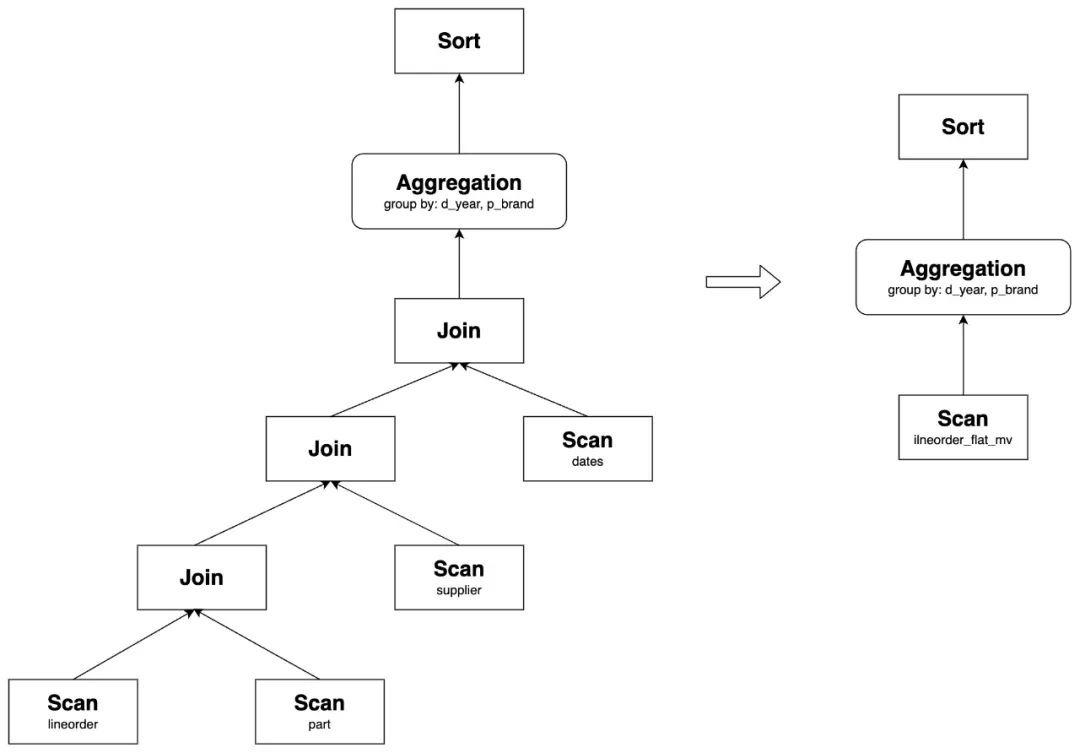
对于 SSB 中的 Query,往往不会查询 MV 的所有表,但是通过指定了主外键关系,仍然能够利用物化视图改写加速,以其中一个查询为例:
--MV
CREATE MATERIALIZED VIEW lineorder_flat_mv
DISTRIBUTED BY HASH(LO_ORDERDATE, LO_ORDERKEY) BUCKETS 48
partition by LO_ORDERDATE
REFRESH manual
PROPERTIES (
"replication_num" = "1"
)
AS SELECT
*
FROM lineorder AS l
INNER JOIN customer AS c ON c.C_CUSTKEY = l.LO_CUSTKEY
INNER JOIN supplier AS s ON s.S_SUPPKEY = l.LO_SUPPKEY
INNER JOIN part AS p ON p.P_PARTKEY = l.LO_PARTKEY
INNER JOIN dates AS d ON l.LO_ORDERDATE = d.D_DATEKEY;
-- Query
select sum(lo_revenue) as lo_revenue, d_year, p_brand
from lineorder
join dates on lo_orderdate = d_datekey
join part on lo_partkey = p_partkey
join supplier on lo_suppkey = s_suppkey
where p_category = 'MFGR#12' and s_region = 'AMERICA'
group by d_year, p_brand
order by d_year, p_brand;
1.3 Join derivability rewrite
Join 派生改写是在物化视图(MV)的 JOIN 类型与查询(query)不一致,但 MV 的结果包含查询的结果时,进行的改写,例如 MV 使用了 OUTER JOIN,而查询是 INNER JOIN。目前分为以下两种情况:
两表 join 的情况:此时会枚举所有 JOIN 顺序和多种 JOIN 方式,检查 INNER/SEMI/ANTI/OUTER 之间是否兼容,在兼容的情况下仍然能够进行改写 三表或三表以上的 join:多表时无法枚举所有可能性,因此只做相对严格的兼容性检查
IS NOT NULL去保证结果的正确性。
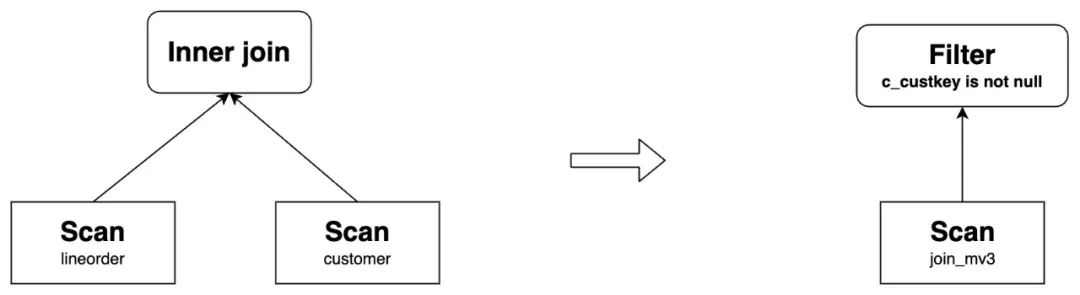
-- MV
create materialized view join_mv3
distributed by hash(`lo_orderkey`)
as
select lo_orderkey, lo_linenumber, c_name, sum(lo_revenue) as total_revenue, max(lo_discount) as max_discount
from lineorder
left join customer
on lo_custkey = c_custkey
group by lo_orderkey, lo_linenumber, c_name;
-- Query
select lo_orderkey, lo_linenumber, c_name, sum(lo_revenue) as total_revenue, max(lo_discount) as max_discount
from lineorder
join customer
on lo_custkey = c_custkey
group by lo_orderkey, lo_linenumber, c_name;
Aggregation Rewrite
支持多表聚合查询的改写,并且支持所有的聚合函数,其中包括 bitmap_union/hll_union/percentile_union 等。
-- MV
create materialized view agg_mv1
distributed by hash(`lo_orderkey`)
as
select lo_orderkey, lo_linenumber, c_name, sum(lo_revenue) as total_revenue, max(lo_discount) as max_discount
from lineorder inner join customer
on lo_custkey = c_custkey
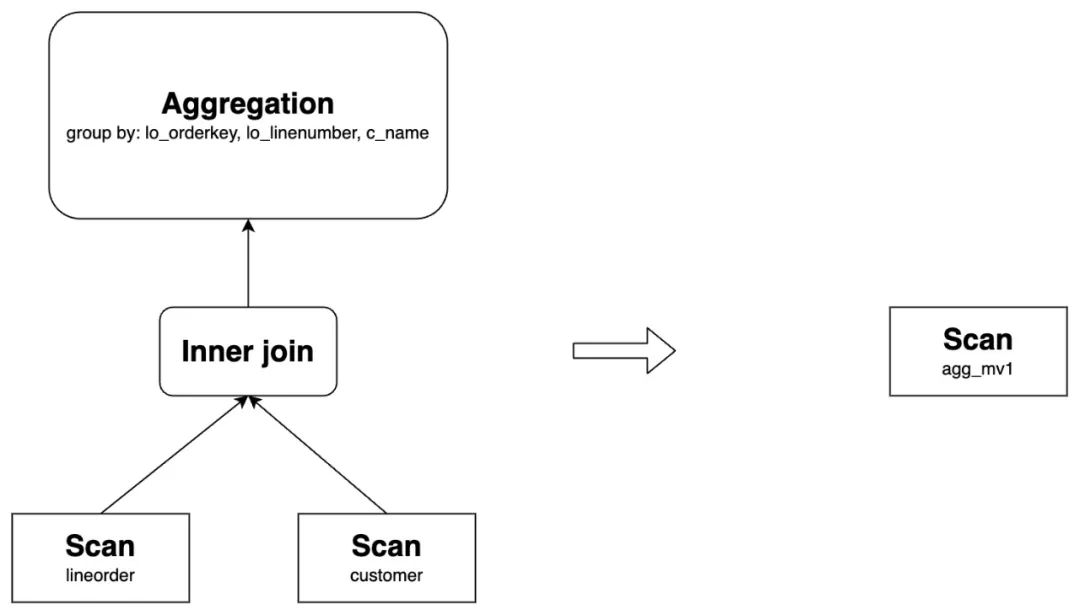
group by lo_orderkey, lo_linenumber, c_name;
-- Query
select lo_orderkey, lo_linenumber, c_name, sum(lo_revenue) as total_revenue, max(lo_discount) as max_discount
from lineorder inner join customer
on lo_custkey = c_custkey
group by lo_orderkey, lo_linenumber, c_name;
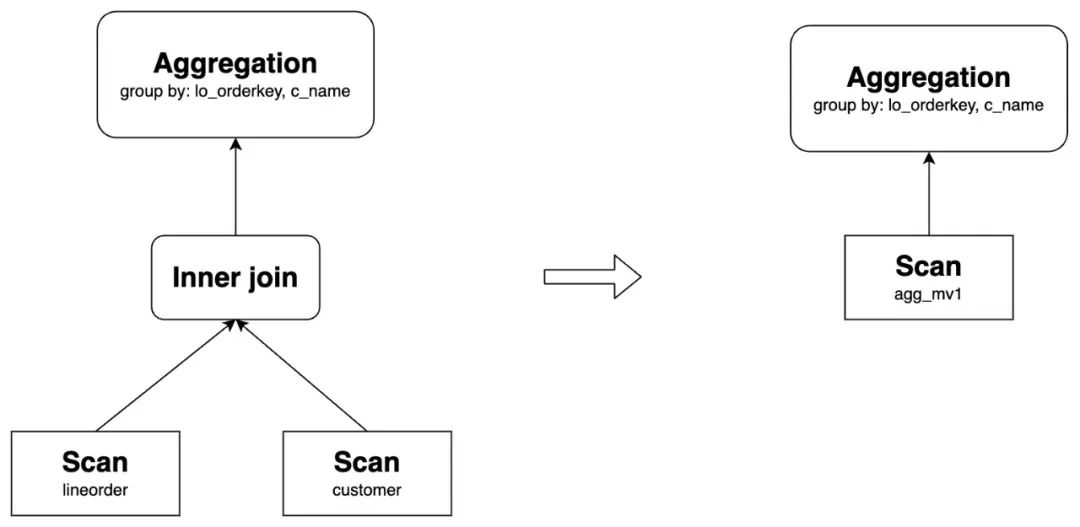
除此最基础的场景之外, 还有一些扩展的场景。
2.1 Rollup
同时,支持聚合物化视图的上卷改写,例如当查询中的 GROUP BY 比 MV 的 GROUP BY 更少时,能够一定程度上服用 MV 的结果,但是仍然需要做二次聚合,才能得到最终结果:
创建物化视图时,使用
bitmap_union(to_bitmap(lo_custkey))查询时,仍然使用普通的
count(distinct lo_custkey)
即可
-- MV
create materialized view distinct_mv
distributed by hash(`lo_orderkey`)
as
select lo_orderkey, bitmap_union(to_bitmap(lo_custkey)) as distinct_customer
from lineorder
group by lo_orderkey;
-- Query
select lo_orderkey, count(distinct lo_custkey) from lineorder group by lo_orderkey;
Nested mv rewrite
Nested mv rewrite
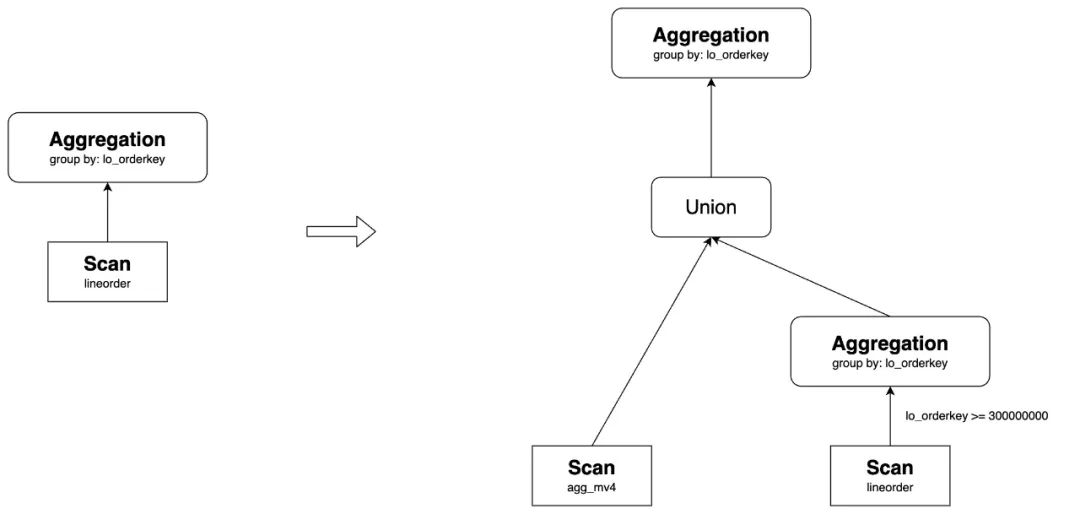
Union rewrite
Partial Predicate:MV 谓词范围是查询的子集,此时会将差集回原表查询,再 UNION 起来 Partial Partition:MV 只物化了部分 Partition,此时其余的 Partition 回原表查询
例如 MV 中有谓词 where lo_orderkey < 300000000
-- MV
create materialized view agg_mv4
distributed by hash(`lo_orderkey`)
as
select lo_orderkey, sum(lo_revenue) as total_revenue, max(lo_discount) as max_discount
from lineorder
where lo_orderkey < 300000000
group by lo_orderkey;
-- Query
select lo_orderkey, sum(lo_revenue) as total_revenue, max(lo_discount) as max_discount
from lineorder
group by lo_orderkey;
比如,有如下的物化视图, base 表 lineorder 的目前包含 p1-p7 分区,物化视图目前也包括 p1-p7 分区。
-- MV
create materialized view agg_mv5
distributed by hash(`lo_orderkey`)
partition by range(`lo_orderdate`)
refresh manual
as
select lo_orderdate, lo_orderkey, sum(lo_revenue) as total_revenue, max(lo_discount) as max_discount
from lineorder
group by lo_orderkey;
如果 lineorder 新增一个 p8 分区,分区范围是[("19990101"), ("20000101")),则下面的查询会被改写为 union:
-- Query
select lo_orderdate, lo_orderkey, sum(lo_revenue) as total_revenue, max(lo_discount) as max_discount
from lineorder
group by lo_orderkey;
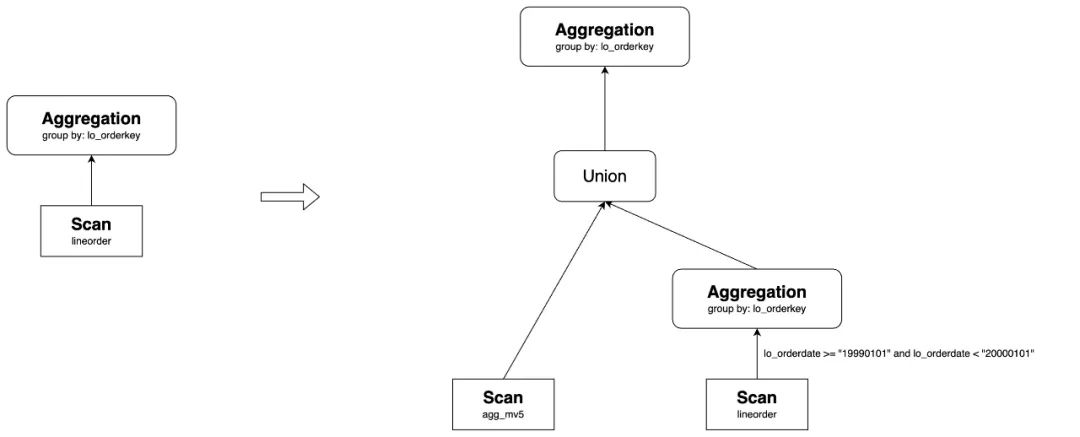
其中,agg_mv5 包含 p1-p7 分区的数据,p8 分区的数据通过直接读取 lineorder 表进行计算,最终通过 union 之后再聚合,获取最终结果。
MV on views
MV on views
支持从 view 上创建 MV,并且查询 view 的时候能够实现透明改写。在查询改写时会有两种方式:
VIEW 展开:内联整个 VIEW,当做普通的 QUERY 改写 VIEW 独立:将 VIEW 作为独立的算子,不考虑内容,再进行改写
-- View
create view customer_view1 as
select c_custkey, c_name, c_address
from customer;
-- View
create view lineorder_view1 as
select lo_orderkey, lo_linenumber, lo_custkey, lo_revenue
from lineorder;
-- MV
create materialized view join_mv1
distributed by hash(`lo_orderkey`)
as
select lo_orderkey, lo_linenumber, lo_revenue, c_name
from lineorder_view1 inner join customer_view1
on lo_custkey = c_custkey;
MV on External catalog
MV on External catalog
StarRocks 支持在 Hive/Hudi/Iceberg/Paimon/DeltaLake/JDBC 外表上构建物化视图,并且能够进行透明改写。上述所有的改写能力大部分在外表物化视图中都支持,具体支持程度可参考使用文档。
不支持非确定性函数的改写,包括RAND/RANDOM/UUID/SLEEP等 在SPJG改写模式下,不支持窗口分析函数的改写;基于文本的改写,不受这个限制 在SPJG改写模式下,如果mv定义语句中包含limit/order by/union/except/intersect/minus/grouping sets/with cube/with rollup,则无法用于改写;基于文本的改写,不受这个限制 部分外表(Hudi/DeltaLake)上还不支持查询结果的强一致
以下列出主流大数据产品在物化视图上的改写能力:
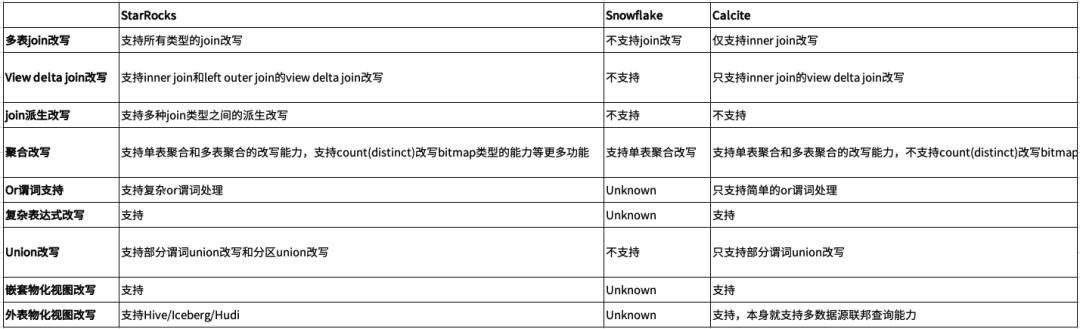
本文主要介绍了 StarRocks 中物化视图查询改写的技术原理,从优化器的执行流程,到对不同查询的处理 Join、Aggregation、View、Union 等,以及内部视角的反省和外部视角的对比。希望本文能够对关心技术原理的读者有所帮助,对 StarRocks 的用户带来更多的技术洞察和业务启发
Optimizing Queries Using Materialized Views: A Practical, Scalable Solution
Materialized view in Apache calcite: https://calcite.apache.org/docs/materialized_views.html
Oracle:https://docs.oracle.com/en/database/oracle/oracle-database/12.2/dwhsg/advanced-query-rewrite-materialized-views.html#GUID-0906CA6B-7EE3-42E1-A598-C6541BCD9B36
延伸阅读:
QPS 提升 10 倍!滴滴借助 StarRocks 物化视图实现低成本精确去重
关于 StarRocks

行业优秀实践案例
泛金融:平安银行|南京银行|中原银行|中信建投|苏商银行|申万宏源|中欧财富|西南证券
互联网:微信|小红书|滴滴|B站|携程|同程旅行|芒果TV|得物|贝壳|汽车之家|腾讯音乐|饿了么|七猫|金山办公|Pinterest|欢聚集团|美团餐饮|58同城|网易邮箱|360|腾讯游戏|波克城市|37手游|游族网络|喜马拉雅|Shopee
新经济:蔚来汽车|理想汽车|吉利汽车|顺丰|京东物流|跨越速运|中通速运|大润发|华润万家|TCL |万物新生|百草味|多点 DMALL|酷开科技|vivo|聚水潭
