




本文由中国科技大学脑启发智能感知与认知教育部重点实验室发布。
标题: SAC-KG: Exploiting Large Language Models as Skilled Automatic Constructors for Domain Knowledge Graphs

论文地址:https://arxiv.org/pdf/2410.02811

01
摘要
在当今信息爆炸的时代,知识图谱(KG)已成为各专业领域中不可或缺的知识管理工具,它们在处理知识密集型任务时扮演着核心角色。然而,传统的知识图谱构建方法往往需要大量的人工参与,这不仅效率低下,而且难以保证 KG 的实时更新和准确性,限制了其在实际应用中的广泛部署。
为了突破这一瓶颈,本文推出了SAC-KG 框架 —— 一个创新的、基于大语言模型(LLM)的自动化知识图谱构建解决方案。SAC-KG框架能够将 LLM 的强大能力转化为领域专家的智慧,自动生成既专业又准确的多层次知识图谱。通过这一框架,不仅提高了 KG 构建的效率,还确保了其在各种现实场景中的适用性和可靠性,为知识图谱的应用开辟了新的可能性。
02
核心内容
SAC-KG 框架,由三个核心组件构成:生成器、验证器和修剪器。当给定一个实体时,生成器从庞大的原始语料库中挖掘出关系和尾部实体,迅速构建起一个单层的知识图谱。紧接着,由验证器和修剪器共同确保图谱的准确性。它们通过精准纠正生成过程中的错误,并决定新生成的尾部实体是否需要进一步迭代,以完善下一层级的知识图谱。
在实验中,SAC-KG 展现出其卓越的能力,能够构建起规模超过百万节点的领域知识图谱。与目前市场上的知识图谱构建方法相比,SAC-KG 在准确率上实现了超过20%的显著提升,这一成就标志着知识图谱构建技术的一大飞跃。其总体框架如下图所示:
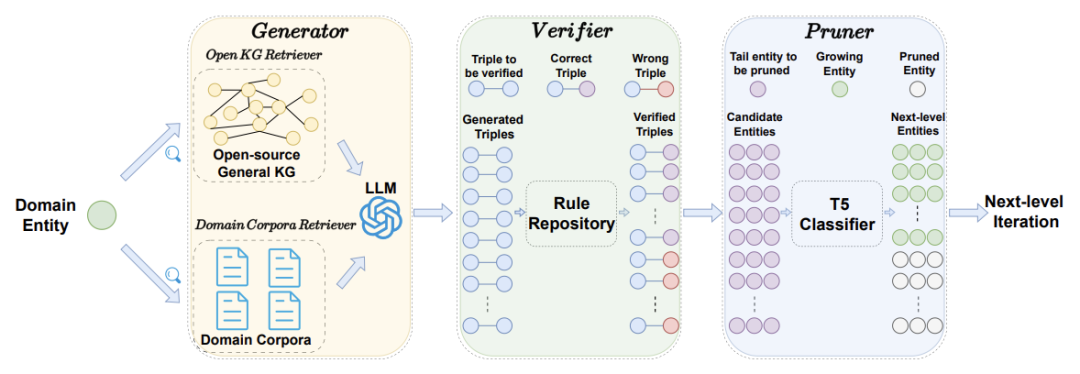
2.1 生成器
生成器配备了先进的领域语料检索器,它能够在庞大的原始语料库中精准挖掘出最相关的上下文信息。同时,它还搭载了开放知识检索器,能够从开源百科全书中提取与主题最为贴切的三元组知识。这一过程完全自动化,无需人工干预,也无需任何参数调整,实现了真正的无监督学习。
为了解决 LLM 中常见的幻觉问题,本文特别设计了一个领域语料库检索器。该检索器的工作流程如下:
首先,它将领域语料库中的内容分割成单独的句子;
接着,根据实体出现的频率对这些句子进行智能排序;
最后,依据与特定实体的相关性,将它们降序排列并串联成一个固定长度的文本,作为 LLM 的输入数据。
然而,当输入数据仅包含领域特定语料时,LLM 的输出可能会变得难以驾驭,甚至导致三元组格式出现错误。为了应对这一挑战,本文引入了开放知识图谱检索器。它利用上下文学习技术,从 DBpedia 中检索出与实体最相关的三元组作为参考示例,从而引导模型输出正确的内容格式。
在下图中,展示了领域知识图谱(KG)在同一领域语料库上的性能评估,包括准确率、召回率以及领域特异性指标,以证明该方法的有效性。
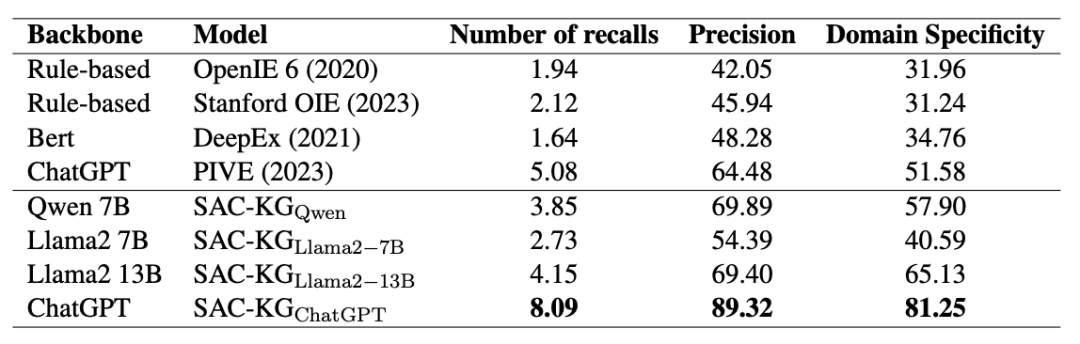
2.2 验证器
验证器分为两个核心步骤:错误识别和错误修正。
错误识别阶段: 利用 RuleHub 中的开放知识图谱挖掘技术,依据既定标准来检测并标记错误类型。这一过程涵盖了三个关键环节:数量验证、格式验证和冲突验证。数量验证确保三元组的数量不低于设定的阈值,避免因数量不足而导致的问题;格式验证则检查头实体是否与预定义实体匹配,以及头实体与尾实体是否相同;冲突验证则关注事实层面的矛盾,例如防止出现一个人年龄为负数的荒谬情况。 错误修正阶段: 首先通过错误识别步骤确定错误的具体类型,并提供针对性的提示。随后,会引导 LLM 根据这些提示,重新生成经过修正的、更加准确的输出结果,从而确保知识图谱的质量和可靠性。
2.3 修剪器
通过验证器的筛选,能够精准地识别出所有有效的三元组,进而为生成更深层次的三元组打下基础。然而,并非每个三元组都需要经历这一迭代过程。以三元组(大米,最佳生长温度,20~25摄氏度)为例,它本身就是一个准确的信息单元,无需进一步衍生出新的三元组。
为了提升这一过程的精准控制,本文引入了修剪器 —— 一个经过精细调整的二分类模型。该模型的任务是接收每个正三元组的尾实体作为输入,并输出 “growing” 或 “pruned” 的决策,以此指导是继续生成新的三元组还是就此打住。
下图展示了在首个三层结构的知识图谱(KG)中,SAC-KG 框架的剪枝效果。每一次迭代都代表着知识图谱层次的扩展,而 “-” 符号则表示在第一次迭代时,修剪器尚未被应用。
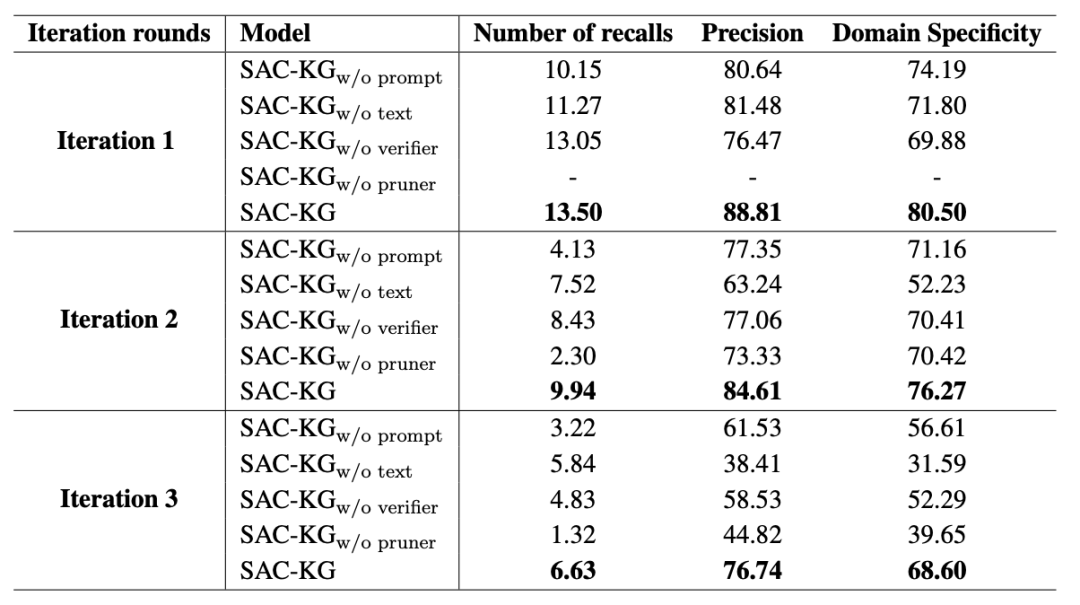
在构建修剪器模型时,作者从 DBpedia 这个知识库中精心挑选训练数据。特别关注那些代表 ‘增长’ 概念的头部实体,并从中挑选出一部分作为训练样本。为了确保分类的精准性,作者还搜集了一组尾部实体,这些实体与头部实体互不重叠,形成了 ‘修剪’ 类别。在微调阶段,作者将这些实体的文本作为输入数据,并将它们对应的标签 —— ‘增长’ 或 ‘修剪’ 作为目标输出。
03
总结
本研究的核心成就体现在以下几个方面:
开创性地构建了一个专业级的、自动化的通用框架,旨在生成高水准的知识图谱(KG),这一框架的提出,标志着知识图谱构建技术的一大飞跃; 生成器技术有效地排除了在知识图谱构建过程中可能干扰 LLM 的上下文噪声,确保了构建过程的准确性和可靠性; 通过验证器和修改器的协同工作,成功地消除了 LLM 在知识图谱构建中常见的幻觉现象,进一步提升了知识图谱的质量和可信度。
