




陈宗志 (暴跳) 发布与:https://zhuanlan.zhihu.com/p/12796249884
AWS re:Invent2024 Aurora 发布了啥 -- DSQL 篇
这个是前年AWS re:Invent 2022 的内容, 有兴趣可以看这个链接: Aurora re:Invent 2022
这个是去年AWS re:Invent 2023 的内容, 有兴趣可以看这个链接: Aurora re:Invent 2023
AWS reInvent 2024 刚刚结束, 笔者作为数据库从业人员主要关注的是AWS Aurora 今年做了哪些改动, 今年最大的可能就是 Aurora DSQL 的发布了.
因此这个文章主要介绍 Aurora DSQL 的实现, 以及笔者的一些看法.
下面的内容主要分成 3 部分:
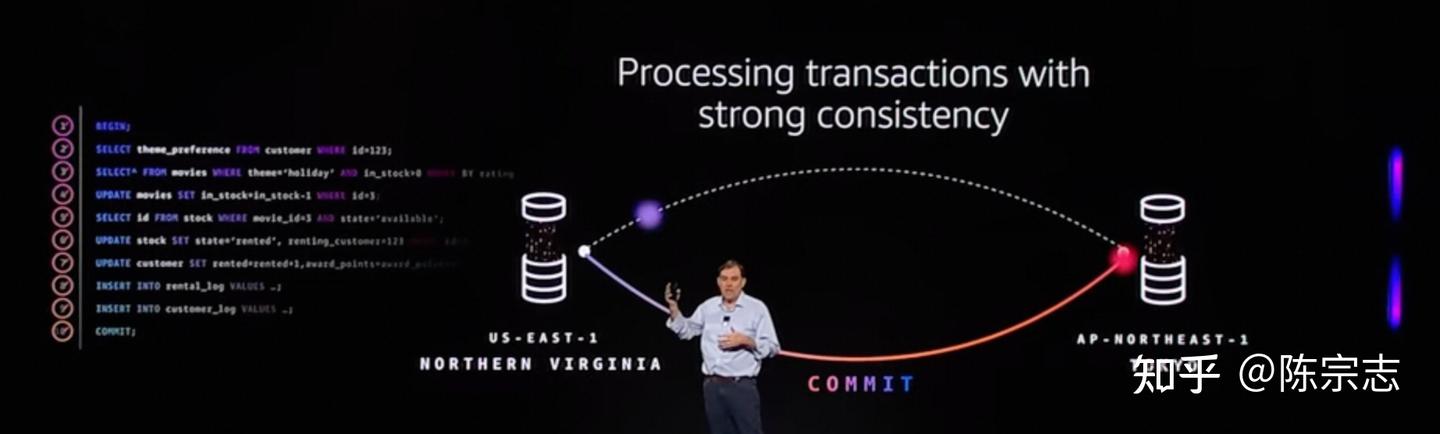
在发布会上, Matt 介绍 DSQL 将多次 commit 合并成一次 commit, 从而实现了 90% 的性能提高, 那么 DSQL 是如何实现的呢?
主要通过 snapshot isolation + EC2 TimeSync service + OCC 实现.
具体做法原先一个事务中包含 10 条 SQL, 每一条 SQL 都需要和数据库交互, 需要对某一些行就先 row lock, 避免事务执行过程中被其他事务修改. 那么如果在跨 region 场景, 延迟可能到了 100ms 以上, 一个事务包含 10 条 SQL 那么就至少需要 1s 才能 commit, 那么自然很容易出现性能问题.
DSQL 的做法通过 snapshot isolation + EC2 TimySync service 获取 t(start) 的版本信息, 然后在提交的时候通过 OCC(optimistic concurrency control) 进行冲突检测
因此这次只需要在 commit 的时候, 需要和数据库交互, 10 条 SQL 执行过程中, 都读取当前 AZ 的 snapshot 出来的版本就可以了, 这就是 Matt 讲的可以优化 90% 的实现方式.
但是真实的场景是这样的么?
其实 OCC 并没有想象的那么好, 其实很早就有讨论基于 OCC 的数据库的并发控制机制实现, "On Optimistic Methods for Concurrency Control" in 1979 by H.T. Kung and John T. Robinson 已经介绍了. 但是一直没有大规模被使用主要由于,
OCC适合于交互式或系统内部组件同步延时较大的场景, 之前大部分数据库都是一体化设计, 计算, 存储, 内存等等都在本地, 因此开销并不大, OCC 冲突导致事务中止浪费计算资源的开销远大于同步操作的开销, 所以没有大规模使用.
那么在跨 region 类似 DSQL 这样场景可以使用吗?
理论上在跨 region 场景 OCC 可以比之前一体化设计数据库有更多的收益, 而且工程实现会更加的简单.
但是可以理解这里把处理冲突的方式交给了用户, 比如目前 DSQL 的事务的大小是有限制的, 一个事务默认最多能够支持修改 10000 行, 事务最长时间为 5 分钟.
用户需要知道直接的业务场景是否有明显的冲突, 做过云数据库
从技术角度可以看为什么 DSQL 选择了 OCC.
可以猜测的原因更多是从工程的角度去考虑, 更易于实现, 减少维护成本, 减少了全局 lock service.
因为如果选择 PCC 的话, 那么需要为了一个全局锁
另外这里有一点没有提到, 就是如何处理多个 Region cache coherence 的问题?
下面这个图是 Aurora 和 Aurora DSQL 的对比.
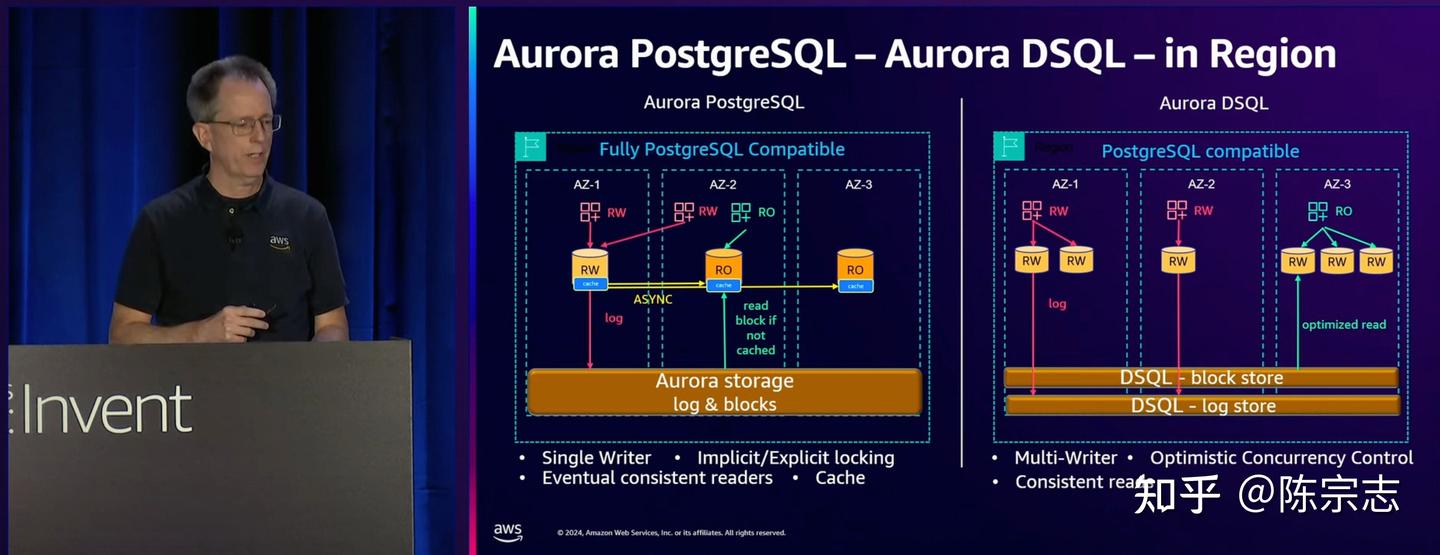
Aurora 里面 Log & blocks 是放在一起存储的, Aurora DSQL 里面将 log store 和 block store 分开存储, 因为 log 写入和 page 写入其实是两个非常不一样的 IO
其实早年在 PolarDB
比如需要考虑 log 和 page 快照一致性问题, 需要考虑维护两个存储池子, log store 使用的机型应该更好, 而 page store 使用的机型可以差一些等等, 一旦需要分池, 那么云计算最大的池化
除了这个差异, 其实这里两个架构最大的区别是, 在 Aurora DSQL 里面取消了每一个实例上面的cache
我们知道在一写多读架构下面, 多个节点之间 cache 一致性是一个比较大的问题.
比如在 rw 节点写入 a = 100 (old value = 99) 以后.
在 ro 节点去读取 a 的值, 这个时候有两种情况:
- a 不在 ro 节点的 cache 里面, 那么就需要从底下的 storage 去读取 a 的值, 这个时候会根据 ro 节点 lsn 信息, 应用到指定版本的 lsn 从而获得 a 的 value.
- 该 ro 节点的内存中已经有 old value a = 99, 那么这个时候需要判断当前 ro 节点的 apply_lsn 信息, 如果 apply_lsn 还没到 rw 节点写入(a = 100) 的位点信息, 那么此时可以直接返回, 如果 ro apply_lsn > rw (a=100) lsn, 那么就需要从底下 storage log 读取对应的 redo log
信息, 应用到指定的 lsn 然后再返回给客户.
从上面的例子可以看到, 在一写多读的架构下, 需要保证 cache 中的数据是一致的, 才可以避免 ro 节点读取到错误版本的数据, 从而导致读取出错.
那么其实在多节点写入的架构下面其实一样存在这样的问题, 而且这个问题会更加的严重, 因为同样要解决多个节点之间的 cache 一致性问题.
那么 DSQL 怎么解决?
非常的暴力, 直接取消了这个 cache, 也就是这个 buffer pool
那么带来的问题是, 这样 block store 的性能是否可以?
在一写多读下, 直接读取 cache 中的内容就可以返回, 那么在 DSQL 的架构下, 需要读取的都不是本地存储, 而是远端的 block store, 本地 内存读取的延迟差不多是百 ns 级别, 而远端存储访问, 即使是 RDMA
为了解决 DSQL 没有 cache 的问题, DSQL 实现了很多的计算下推操作, RW 节点和 block store 请求的不再是 Page, 而是具体的某一行, 这样可能尽可能减少需要请求的 page, 提高性能.
但是大部分线上 OLTP
还有一个比较差别的点可能跟Marc Brooker 有关, Marc Brooker 在 AWS 做了 10 年的 Lambda
DSQL 在 serverless 上比 Aurora 更彻底, DSQL 的实例在有请求的时候, 通过 Firecracker 启动一个实例, 在执行完请求以后, 直接就将实例释放, 由于没有 cache 的存在, 并且使用的是 OCC 计算节点几乎没有保留任何有状态的信息, 那么在连接关闭以后, 这个节点就可以直接关掉了, 所在这里可以做到秒级别的 serverless.
而传统 Aurora 差不多需要的时间是 5min 级别.
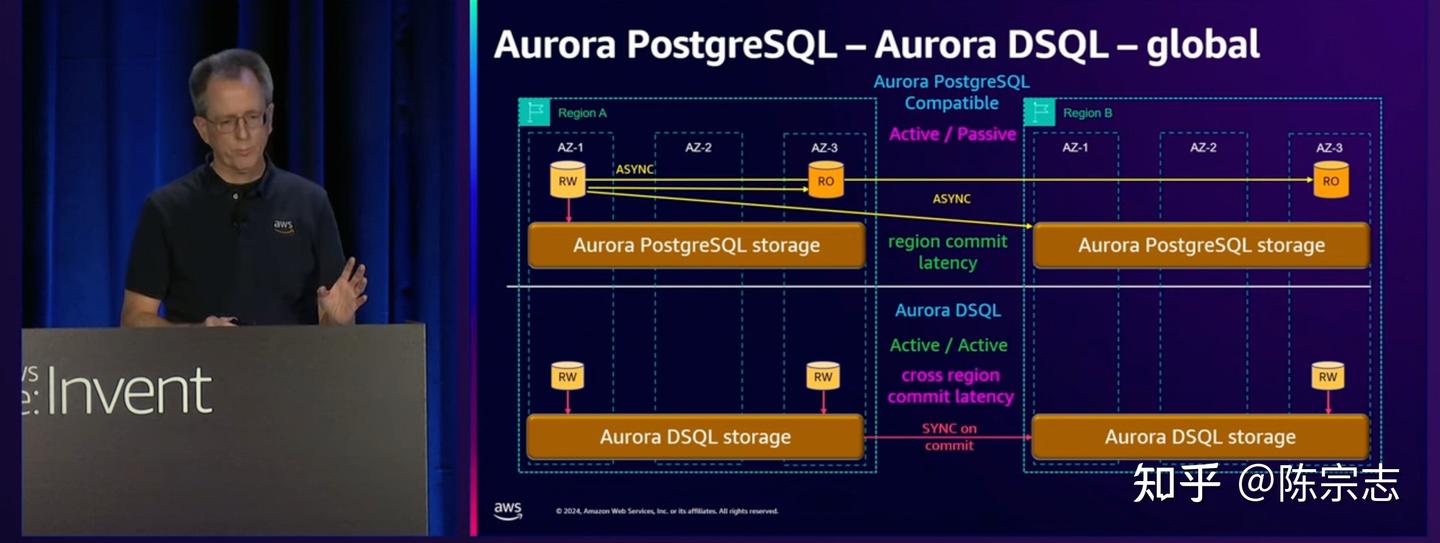
对于在 Global database 场景, Aurora DSQL 使用了和跨 AZ 场景, 几乎一样的能力. 由于跨 region 场景, 延迟更高因此 OCC 带来的性能收益也更加明显.
笔者观点:
从上面的原理介绍我们可以看到 Aurora DSQL 由于减少了 cache 层, 延迟会增加, 使用 OCC 那么用户使用的复杂度会增加. 因此笔者认为Aurora DSQL 的使用场景其实是有限, 需要对延迟不敏感, 业务上很少存在热点数据, 并且业务开发人员需要有较强的开发能力, 能够实现业务层的重试机制, 业务范围很大, 需要分布多个 region
Reference:
1: AWS re:Invent 2024 - CEO Keynote with Matt Garman
2: DSQL Vignette: Aurora DSQL, and A Personal Story
3: DSQL Vignette: Reads and Compute
4: DSQL Vignette: Transactions and Durability
5: DSQL Vignette: Wait! Isn’t That Impossible?
6: AWS re:Invent 2024 - Deep dive into Amazon Aurora and its innovations (DAT405)
