




最近,我们收到了很多用户在论坛、博客上主动分享的基于 AI 助手 Demo 改造的趣味实践(戳此回顾 👉 体验 SQL+AI,用 OceanBase 搭建你的 AI 助手 ),非常感谢大家的热情支持!
自 OceanBase 4.3.3 版本发布以来,SQL +AI 的能力受到了广大用户的欢迎。OceanBase 基于一体化向量能力,实现 AI +多模的融合。有不少用户提出希望 OceanBase 继续拓展更多 AI 方向的应用和场景。今天咱主打一个听劝!这就为大家带来一个全新应用——
搭建一个 Text2SQL 应用!
通过大模型用自然语言生成对应的查询 SQL,不仅可以直接在 OceanBase 数据库中执行该 SQL 获取结果,还能够将得到的查询结果进行可视化展示(下文中会将这个应用称为 chat data)。这个应用能够在一定程度上提升 OceanBase 数据库的易用性,且步骤十分简单,欢迎大家都来尝试一下。
一、Text2SQL应用简介
这个 Text2SQL 的 chat data 应用是基于蚂蚁集团的 AI 原生数据智能应用开发框架——DB-GPT 进行。
DB-GPT 通过多模型管理(SMMF)、Text2SQL 效果优化、RAG 框架以及优化、Multi-Agents 框架协作、AWEL (智能体工作流编排)等多种技术能力,使围绕数据库构建大模型数智应用变得更加简单和便捷。目前已有超过 106 万用户学习和使用 DB-GPT ,并有 100+ 家企业已将其集成到生产系统中。
OceanBase 支持向量数据类型的存储和检索,并已适配作为 DB-GPT 的可选向量数据库,支持 DB-GPT 对结构化数据和向量数据的存取需求,从而支撑其上 LLM 应用的开发和落地。
我们可以快速看看应用的效果:让 chat data 写一条简单的 SQL,对 TPC-H 测试集的数据进行查询,并生成可视化的图表,效果如下:
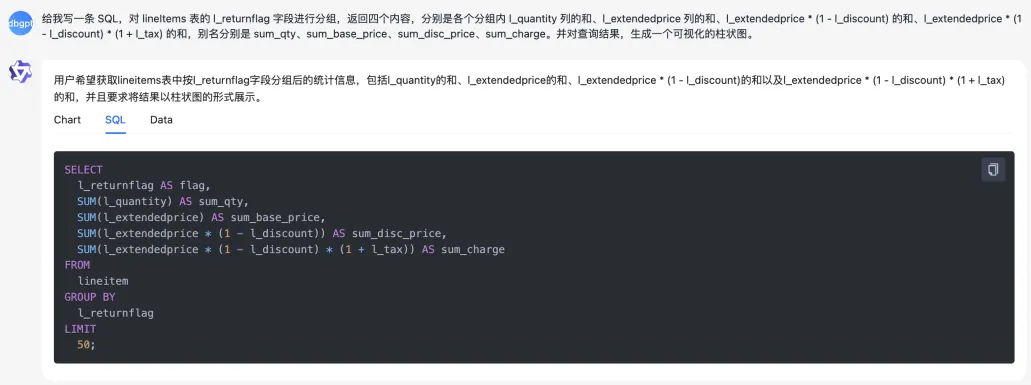
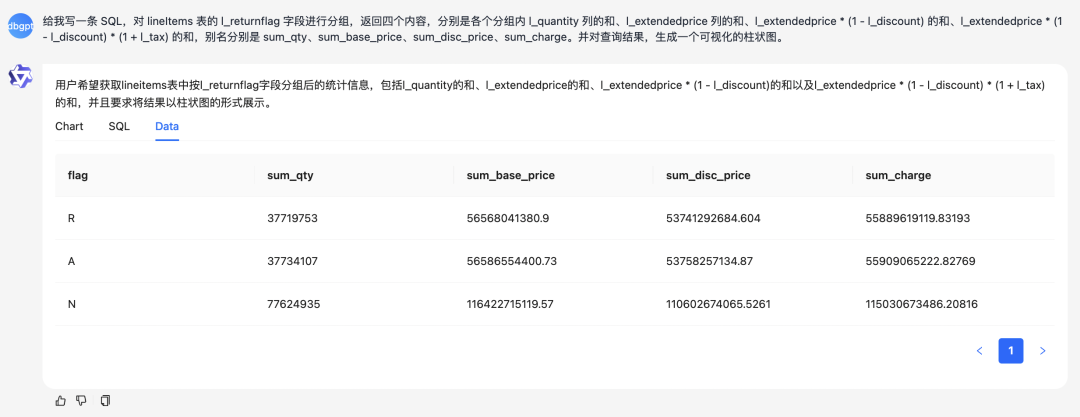
chat data 会自动拿着生成的 SQL 去数据库里执行,并返回查询结果。
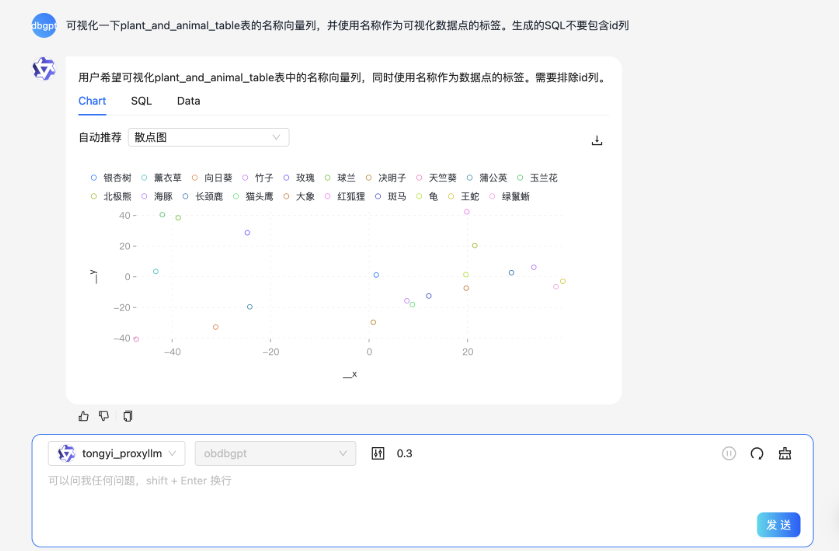
再看看另一个示例——输入提示词后,让 chat data 应用帮我们生产一个可视化的散点图。(需要注意的是 Text2SQL 对大模型的能力要求较高,如果执行结果出现错误提示,可以尝试重试和修改提示词。)
二、OceanBase如何支持TextSQL应用
我们可以通过下图去理解 OceanBase 数据库在 Text2SQL 应用中的作用。
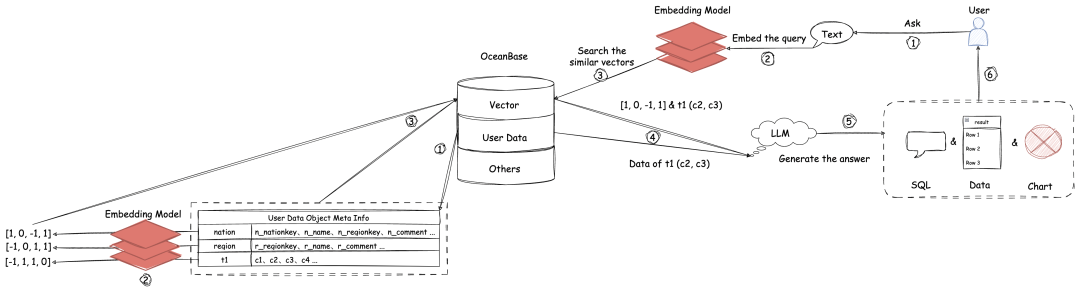
图中展示的这个 OceanBase 租户里有三类 database,分别为:
✅ 用于存储用户数据的库(图中的 User Data 库);
✅ 用于存向量数据的库(图中的 Vector 库);
✅ 以及其他库(图中的 Others 库)。
Text2SQL 应用的服务对象是数据库,这个被服务数据库在本实验中就是 OceanBase,对应图中的 User Data 库;同时,应用需要对用户输入的自然语言,将数据库对象的元数据拿出来,进行相似性检查,所以也需要一个服务于应用的向量数据库,这个数据库也由 OceanBase 支持,对应图中的 Vector 库。
也就是说,这次实验,不需要专门去另外搭建一个向量数据库,通过 DB-GPT,利用 OceanBase 的向量能力,对在 OceanBase 中存储的用户数据进行服务,完全实现了“自给自足”。
我们从上图的左侧部分,来看 DB-GPT 在搭建 Text2SQL 应用的过程中生产向量的过程。
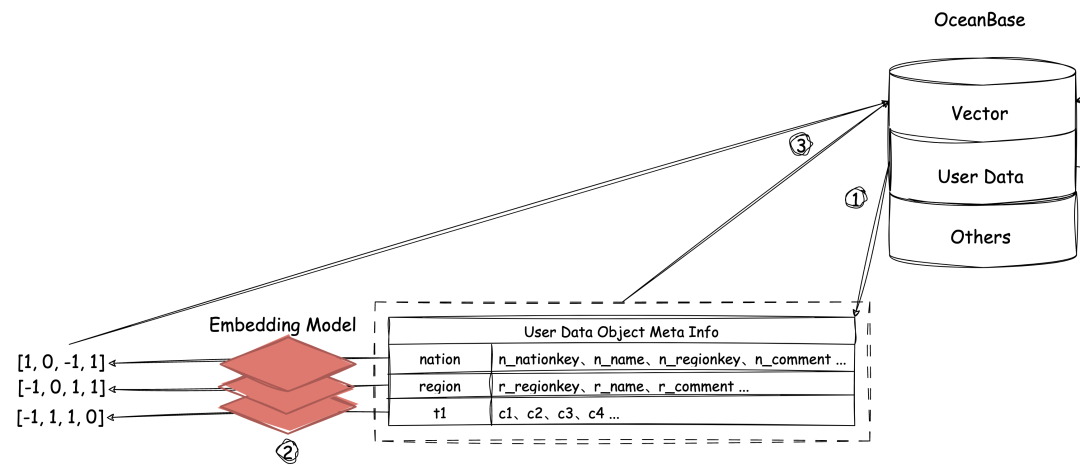
🚩 首先需要创建一个 User Data 库的连接,在创建这个连接的时候,就会把连接中对应库(例如这个库的真名叫 dbgpt_test_db)中用户数据的元信息(表名、列名等)拿出来;
🚩 然后把这些元信息转成向量的形式;
🚩 最后存入 Vector 库中的一张叫做 dbgpt_test_db_profile 的表内。
DB-GPT 每创建一个新的 User Data 库的连接,就会在 OceanBase 的 Vector 库内创建一张叫做<database_name>_profile 的表,(<database_name>替换为用户使用的数据库名),表中有一个 document 列,用于存储元数据的文本信息;还有一个 embedding 列,用于存储将 document 列转换成的 1024 维向量。
上图的右侧部分,则体现了 OceanBase 和用户交互,然后通过大模型消费向量数据,产生答案的过程。
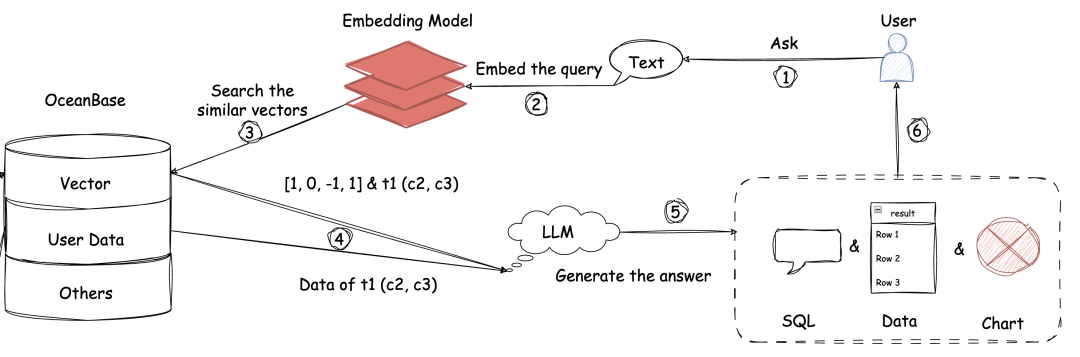
步骤 1 到 3 :首先会把用户的自然语言请求,通过模型转换为向量,并在 dbgpt_test_db_profile 表内查询相似度最高的向量。
步骤 4 到 5:大语言模型会基于 Vector 库返回的元数据信息,把自然语言转换为对应的 SQL,并在 User Data 库中执行 SQL 和收集结果数据。还可以根据用户需求将结果数据生成适合的图表。
三、四步搭建chat data应用
进行实验之前,我们需要先开通 OceanBase 数据库,方式有两种:使用 OB Cloud 实例或者使用 Docker 本地部署单机版 OceanBase 数据库。我们在此推荐 OB Cloud 实例,因为它部署和管理都更加简单,且不需要本地环境支持。
OB Cloud 目前已经支持 365 天免费试用,大家可以开通事务型共享实例(MySQL模式)。
开通完成后,只需要下面的 4 步就可以完成 chat data 应用的搭建了。这里不做详细描述,完整的实验步骤流程,可点击下面的链接查看:
https://gitee.com/oceanbase-devhub/DB-GPT/blob/main/docker/compose_examples/ob_dbgpt_tutorial.md
第一步,获取 OceanBase 数据库实例连接串
第二步,申请大模型 API KEY (可以选择阿里云百炼)
第三步,启动 Docker 容器,复制项目镜像
第四步,访问 DB-GPT 平台,创建应用
在 DB-GPT中,还支持知识库的 RAG 应用搭建,大家也可以参考文档中的步骤去搭建。
最后,如果大家想了解 OceanBase 的向量检索能力、向量数据库与 AI 大模型如何联动应用,以及如何去搭建一个检索增强生成(RAG)场景的 AI 助手 Demo,可以移步《体验 SQL+AI,用 OceanBase 搭建你的 AI 助手 》这篇文章继续阅读哦~
四、还有更多
为了让更多的用户更容易地基于 OceanBase 搭建 AI 应用,我们会陆续将不同场景的 AI 实验步骤录制为视频课程,方便大家随时学习。目前已经上线的有 RAG AI 助手 Demo,和如何结合低代码平台 Dify 去搭建 AI 应用,本文的应用和更多实验也将陆续上线。下图扫码可以直达课程。

