




Hello 大家好,我是猿java。
在 大厂实例分享:每日 3000万订单,如何分库分表? 文章分享道:目前分库分表比较常用的切分算法是 hash,因此有小伙伴私信我,hash算法在扩容和缩容时,需要迁移大量数据,如果是万亿级的数据库,那数据迁移将是一个偌大的工程,因此,今天特输出此文章予以解释,另外,本文把和 hash算法存在歧义的一致性 hash算法也一同比较分析。
在开始今天的分享之前,先说明一个概念的问题:在Java中,取模运算通常也叫取余运算,即 x mod y 等同于 x % y,唯一的区别在于:当 x 和 y 的正负号一样,两个函数结果相同;当 x 和 y 的符号不同时,取余结果的符号和 x 的一样,而取余结果的符号和 y 一样。
一、hash算法
hash,一般翻译为“散列或者哈希”,就是把任意长度的输入通过 hash算法,变换成固定长度的输出,该输出就是散列值。
假设有 A、B、C 三个节点组成的 KV 服务,每个节点存放不同的数据,当用户的请求过来时,可以对某个设定的 key 进行 hash 计算,然后用 hash(key)对节点总数做取模操作,这样相同 key 的请求总是能路由到相同的节点上,如下图:
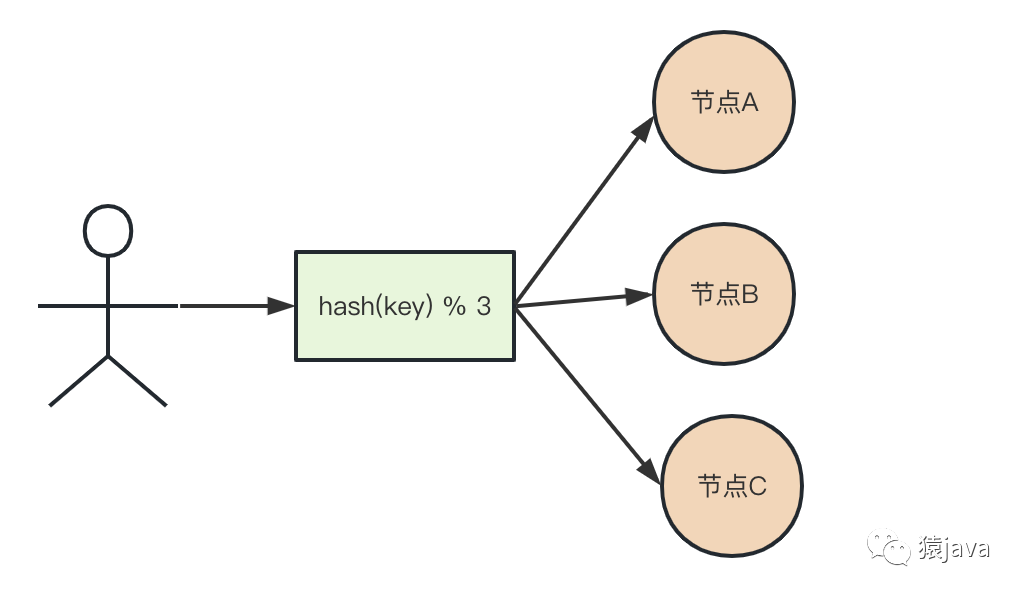
使用 hash算法最大的优点就是简单,最大的问题在于当 hash(key) % n 中的 n(即服务器节点数)发生变化时,同一个 key 经过 hash(key) % n 算法的结果值就发生了改变,因此,数据与节点间的映射关系自然而然发生了变化。n 的具体改变包括扩容和缩容,详细说明如下:
扩容
假如,随着业务的发展,用户量越来越大,原来的 A,B,C 3 个节点无法承受用户端的流量压力,这时需要增加一个节点D,如下图:
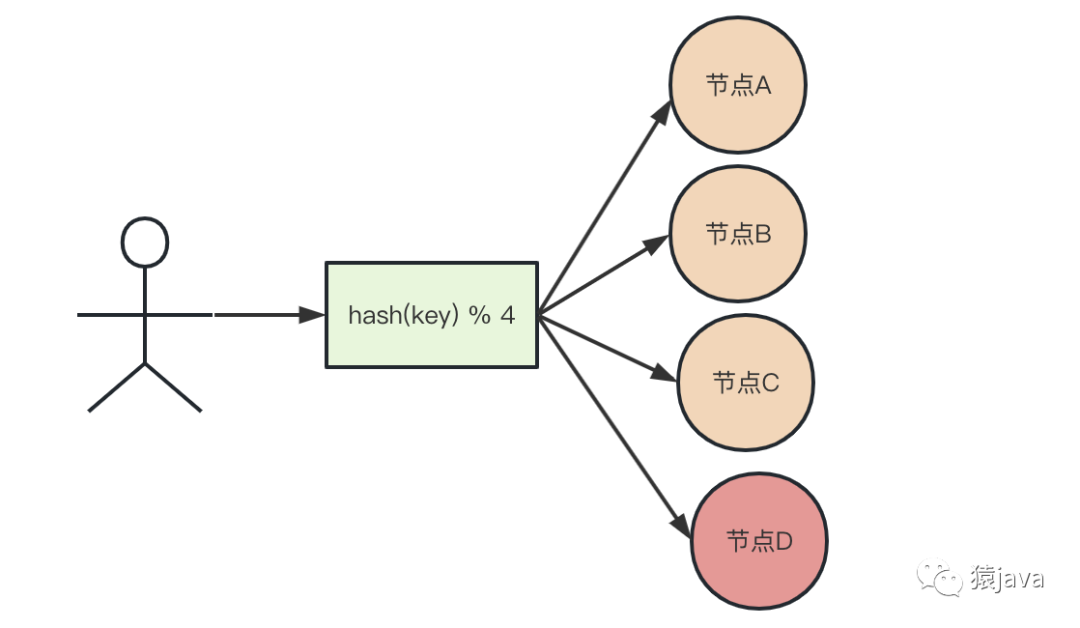
从上图我们可以看出,当增加一个节点 D 时,原来的路由算法需要从 hash(key) % 3 变成 hash(key) % 4,那么会出现什么问题?
假如 hash(key) = 100,hash(key) % 3 = 1, hash(key) % 4 = 0,此时计算的结果值发生了变化,对于同一个请求,扩容前路由到序号 1 节点(节点 B),扩容后路由到序号 0 节点(节点A ),寻址发生变化,但是,数据依然存放在节点B,而请求却到了节点A ,因此该扩容方式会导致请求获取数据失败。
缩容
同理:比如因为疫情,用户量越来越少,原本需要 3 个节点,现在 2 个节点就能满足需求,需要进行缩容,如下图:
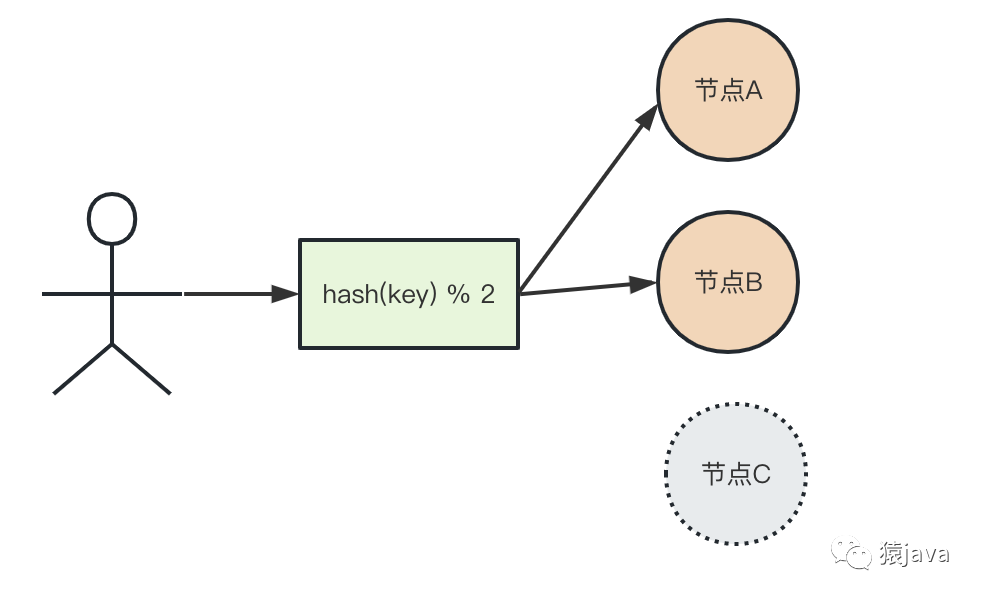
缩容,同样会出现扩容时寻址失败的问题。
对于扩容和缩容等服务器节点数发生变化,导致寻址失败的问题,该如何解决呢?
答案:迁移数据
比如:扩容操作,扩容前路由到 A 节点,扩容后路由到 B 节点,可以把数据从 A 节点迁移到 B 节点,满足新的路由方式;
缩容操作,同理。
但是当数据量比较大的时候迁移数据的也是需要代价的,有没有更好的方式来降低这种数据迁移?
答案:一致性 hash
二、一致性 hash算法
一致性 hash 算法也是采用取模运算,但与 hash 不同的是,哈希算法是对节点的总数进行取模运算,当节点的数量发生变化时,取模的结果会发生变化,而一致哈希算法是对 2^32 这个固定的数值进行取模运算,所以,如果 hash(key)算法结果不变,取模的结果就不变。
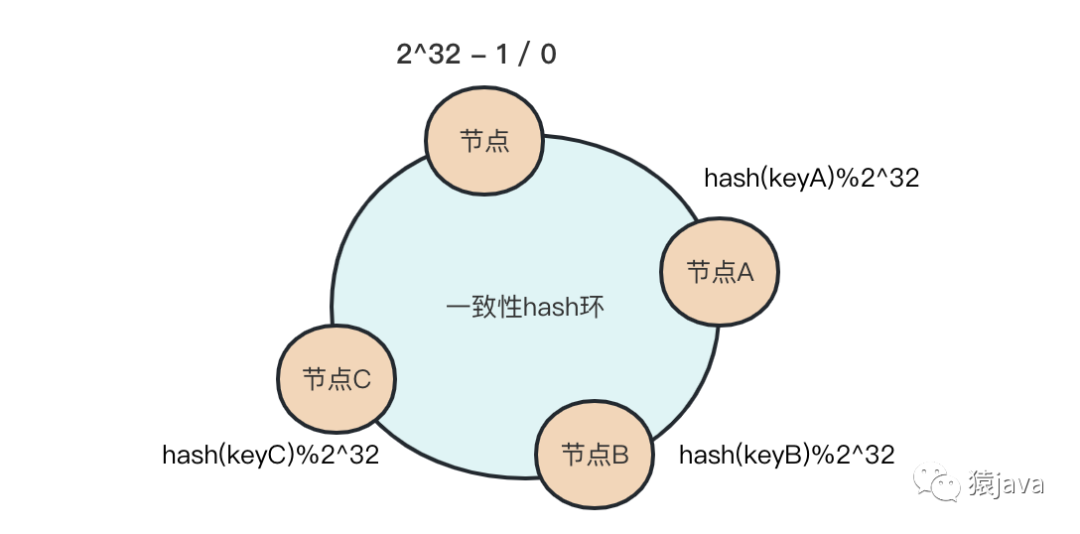
实际上,一致性 hash 是将整个哈希值空间组织成一个虚拟的圆环,也就是哈希环,如下图:
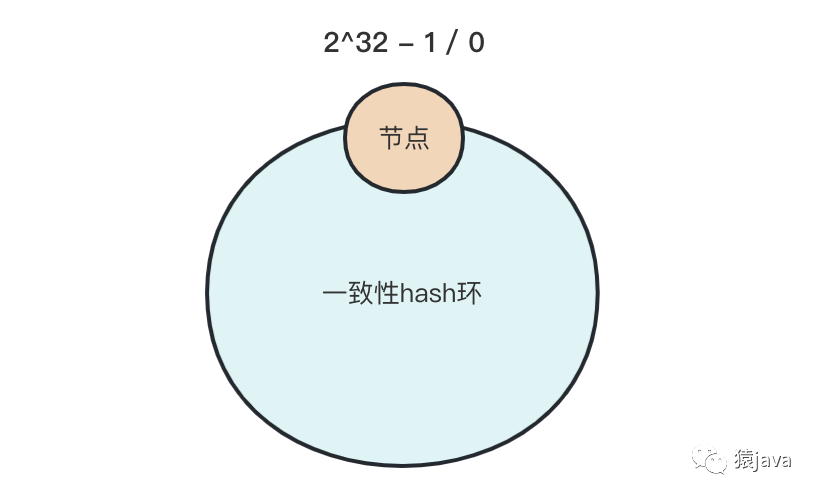
假如有 A,B,C 3 个节点,当需要对 key 的值进行读写操作时,可以按照下面 2 步进行寻址:
对 key 进行 hash() 计算,并确定此 key 在环上的位置;
从 key 所在的这个位置沿着哈希环顺时针"行走",遇到的第一节点就是 key 对应的节点;
如下图:hash(keyA)%2^32 寻址到节点 A,hash(keyB)%2^32 寻址到节点 B,hash(keyC)%2^32 寻址到节点 C
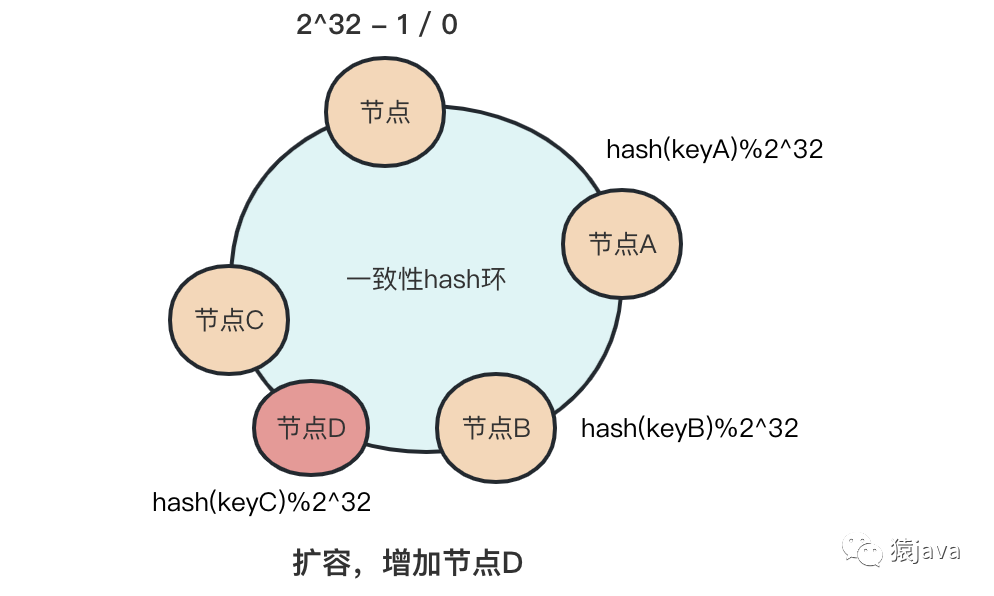
扩容
当增加一个集群 D,keyC 原本是寻址路由到节点 C,现在寻址路由到节点 D,因此受影响的 key 是节点 B 到节点 D 之间的所有请求,其他的 key 不受影响。
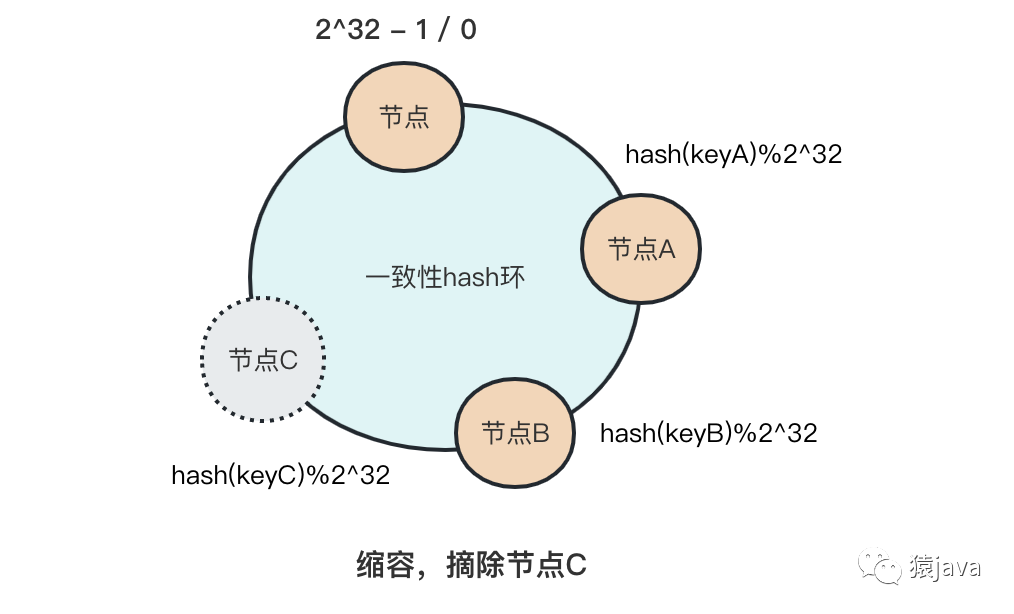
缩容
当缩容节点 C 时,keyC 原本寻址路由到节点 C,按照一致性 hash 的原理,顺时针寻找到最近的一个节点 A,所以节点 B 到节点 C 之间的 key 将受到影响,寻址路由到新的节点 A。
通过上面对一致性 hash 扩缩容的分析可以知道,当对节点进行扩缩容时,受影响的 key 是局部的,需要迁移的数据也可控,而且随着节点的增多,受影响的 key 会成反比下降。
公平性
如下图,当 hash 环上的节点分布不均匀时,节点 A 承受了 70%的流量,而节点 B,C 只承受了 30% 的流量,这样就会导致数据访问的冷热不均,造成不公平,如何解决?
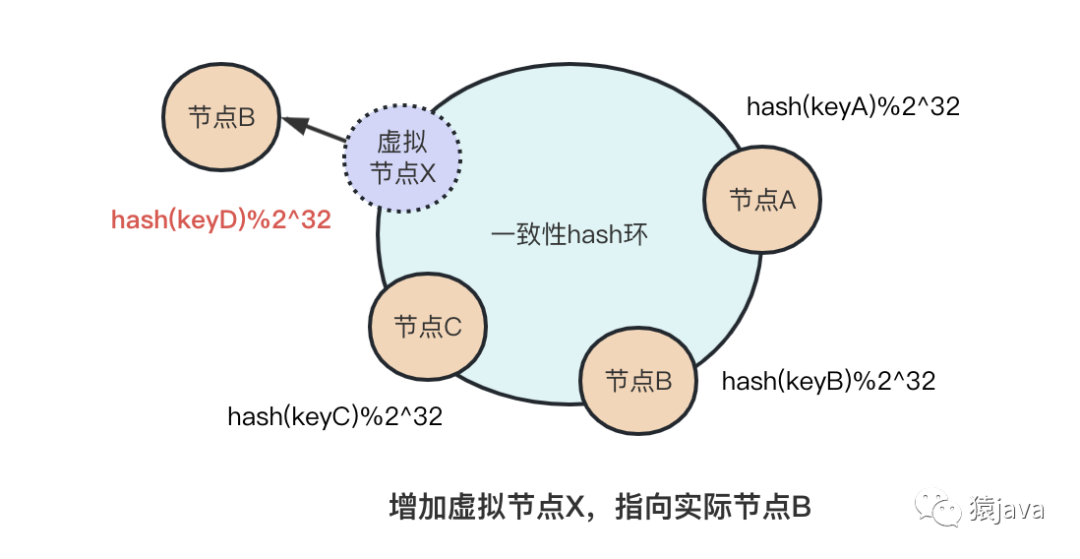
答案:虚拟节点
如下图:在节点 C 和节点 A 中增加了一个虚拟节点 X,真实指向节点 B,这样 keyD 原本路由到节点 A,现在会通过虚拟节点X间接路由到节点 B,这样就解决了数据访问的冷热不均造成的不公平问题。
三、如何选择?
hash(key) % n 尽管在服务器节点n发生变更时需要迁移数据,但是只要扩容和缩容时合理设置 n,就能很好的控制需要迁移的数据量,一般业内做法是:n = 2^x,比如2, 4, 6,要扩容的时候,一般扩容是以倍数的形式增加。比如原来是 4个表,扩容时,增加到 8个表,再次扩容就增加到 16个表。
为什么要以倍数的形式设置?主要是一个数对 n=2^x 取余和对 2n=2*2^x=2^(n+1) 取余,大大增加了 hash(key) % n 结果值相同的概率,因此迁移的数据量就减少了,可以参考 Java源码中 hashMap扩容机制。
一致性hash尽管在扩容,缩容时能够有效的控制迁移数据量,但是实现的复杂度比较高。
所以在一般业务中 hash使用的比较多,比如数据库的分库分表,一致性 hash在分布式一致性中使用的比较多,比如分布式缓存,Facebook 的 NoSQL数据库Cassandra,AWS的 NoSQL数据库DynamoDB 使用了一致性哈希算法,将 Key 对应的数据存储在多个节点中。
最后,具体怎么选,得充分考虑两者的优缺点以及业务需求。
四、总结
hash 算法是对节点总数取模后进行寻址路由,因此,对于扩缩容频繁导致大量数据迁移的场景不太适用;
一致性 hash 是一种特殊的 hash 算法,节点增减变化只影响到部分数据的路由寻址,因此只需要迁移部分数据,就能实现集群的稳定;
一致性 hash 算法,当节点数较少时,可能会出现节点在哈希环上分布不均匀的情况,最终导致业务对节点的访问冷热不均,可以通过引入更多的虚拟节点来解决;
一致性 hash 算法具有较好的容错性和可扩展性;
一致性 hash通过增多虚拟节点提升均衡性,但也会消耗更多的内存与计算力;
关键字到节点位置的映射,hash 算法的时间复杂度是O(1) ,一致性 hash 的时间复杂度是O(logN);
五、学习交流
文章总结不易,看到这里的小伙伴,感谢帮忙点赞,在读,或者转发给更多的好友,我们将为你呈现更多的干货, 欢迎关注公众号:猿 java
