




传统过滤器在准确性和空间开销之间做权衡,有时会产生假阳性错误,但它们在遇到假阳性时无法自动调整,导致只能保证单次查询的假阳率。自适应过滤器在检测到假阳性后会更新,避免重复错误,但现有的自适应过滤器存在适应性较弱和辅助结构开销大的问题。那么如何在保证较高适应性的同时不带来过大的额外空间开销呢?本次为大家带来数据库领域顶级会议SIGMOD的论文:《Adaptive Quotient Filters》。
一.引言
过滤器:过滤器使用紧凑的方式来表示一个集合,通过允许一定的假阳率(即本来不在集合中的元素过滤器可能认为它在集合中)来节省空间开销。目前,过滤器已经广泛应用于许多领域之中,比如网络,存储系统,机器学习等等。
过滤器解决/待解决的问题:1) 静态Yes/No判定问题:给定从域𝑈中选择的集合𝑌和𝑁,构建一个数据结构,该结构对𝑌中任意元素查询回答Yes,对𝑁中的任意元素查询回答No,并且对𝑈中的任何其他项回答No的概率至少为1-𝜀;2)动态Yes/No判定问题:与静态Yes/No问题类似,不同点在于Y和N可能会动态更新;3)倾斜查询分布:在某些情况下,查询的分布可能高度倾斜。在这种情况下,过滤器的实际假阳率可能与预期𝜀相差甚远。例如,如果所有查询都是针对单个元素的,则实际的假阳率将为0或1,但不介于两者之间。避免重复错误可以降低过滤器的假阳率,或者等效地减少实现某个目标假阳率所需的过滤器大小;4)对抗性查询:在这个问题中,目标是设计一个过滤器,保证来自攻击者的查询中误报的比例最多为𝜀,即使这些查询是由试图使过滤器返回尽可能多的误报的攻击者选择的。在这里,原文假设攻击者可以检测到查询何时导致误报,并且可以任意重复查询。这是倾斜查询分布的更一般情况。
先前的工作为以上几种问题分别提供了不同的方案,然而,原文作者指出,以上的所有问题都可以通过他们提出的单调自适应过滤器(一种永远不会忘记假阳性的过滤器)自然解决,并且空间相当,性能优于以前的专用解决方案。
自适应过滤器需要两件事:关于其假阳性的反馈以及用于纠正它们的辅助结构。例如,如果用自适应过滤器来避免数据库中的无效查询,后续数据库查询返回数据库中不存在𝑥时,应用程序需要通知过滤器对𝑥的查询是假阳。自适应过滤器还需要一个辅助结构来存储信息以支持自适应。Bender等人表明,这种辅助信息是必要的,而且必须非常大 [1]。大致做法是将过滤器分成两部分,一个小的内存组件在每次查询时都会访问,而一个大的辅助结构只在自适应期间访问,因此可以驻留在较慢的存储如磁盘中。单调自适应过滤器的特殊之处在于,当它们自适应时,它们的假阳性集只会缩小。之前提出的自适应过滤器不是单调的:修复一个假阳性可能会导致其他元素成为假阳。
指纹过滤器(例如商过滤器 [2])是构建单调自适应过滤器的良好候选者,它们通过紧凑地存储集合h(𝑆)={h(𝑥)|𝑥∈𝑆}来存储集合𝑆,其中h是哈希函数,h(x)称为x的指纹。其假阳率的唯一来源是指纹的碰撞,因此,要使指纹过滤器自适应,只需要消除这些指纹的碰撞即可。一个基本的方式是如果发现了假阳性,就不断增加指纹的长度,直到假阳性消失。事实上,这个操作不仅自然而且必要 [3]。挑战在于在较低的空间和时间开销下有效地存储和更新这些可变长度的指纹。因此,作者提出了构建在商过滤器上的单调自适应过滤器:AdaptiveQF(自适应商过滤器),其通过简单的机制来管理可变长度指纹。
二.方法
2.1 高层设计
AdaptiveQF建立在指纹过滤器的理念之上,通过存储指纹集h(S) = {h(x) | x∈S}来存储集合S。背后的基本理念是,最初,只存储每个指纹的足够位数,以确保假阳率为𝜀,即存储一组指纹F,其中每个指纹实际上是h(x)的前缀,其中𝑥∈𝑆。如果𝐹中的某个指纹是h(y)的前缀,则对y的查询返回Yes。当发现假阳性时,即某个数据𝑦∉𝑆使得某个指纹f∈𝐹是h(y)的前缀,则增加𝑓的长度,直到它不再是h(y)的前缀。该方案的主要问题是:在不知道指纹𝑓的完整哈希h(x)的情况下,应该如何在过滤器中扩展指纹f?为了解决这个问题,所有自适应过滤器都维护一个反向映射,将𝐹中的指纹映射回其完整哈希(甚至是原始数据)。然而,存储完整哈希意味着此映射将比过滤器大得多,可能大到无法放入内存中。因此,需要尽量减少更新和查询此反向映射的频率。AdaptiveQF在一般查询中保持其快速性能。理想情况下,不会在除了进行调整之外的情况下访问反向映射。在以下章节中,本文将描述如何有效地存储和更新可变长度指纹,以及如何以很少的开销维护反向映射。
2.2 商过滤器
前面提到,AdaptiveQF建立在商过滤器(QF)之上,如图 1所示,商过滤器由一个包含2q个槽的数组Q和一个哈希函数h组成。假设指纹长度为p(p>=q),则将元素x存储在槽h(x) 2p-q的位置,存储的值为h(x) % 2p-q,即以商为存储位置,存储的值为余数。当两个不同的指纹映射到同一个槽时,则将槽中已有的值向右移动。存储在相同槽的元素相当于存储在了数组中的一个连续位置,称之为run。多个连续的run则成为一个cluster。此外,在数组之外,QF还为每个槽维护了两个元数据:is_occupied和is_runend,表示这个槽是否被占以及这个槽是否是一个run的终点,主要用于发生冲突时的移动。
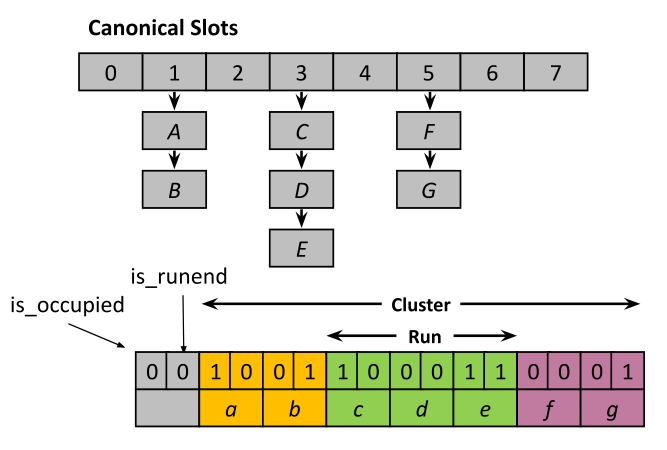
图 1 商过滤器
2.3 AdaptiveQF
前面说到,AdaptiveQF通过增长指纹的方式来消除假阳。具体来说,当出现假阳时,记最初的指纹长度为r,那么其会增长r位,增长的部分会插到原来指纹的相邻处。如图 2(b)所示,查询X时出现了假阳,这是因为它与D的指纹冲突了,d会扩展成dd’,d’则插入到d之后。此时,为了区分指纹是扩展而来的还是原始的,AdaptiveQF还需要维护一个新的元数据is_extension。要扩展指纹,还需要知道原始的hash值,因此,AdaptiveQF在磁盘中维护了从指纹到hash值的反向映射。由于AdaptiveQF通过增长指纹而不是像其它自适应过滤器那样重新散列来进行适应,因此适应之前存在的指纹位保持不变,即,插入数据时原指纹的移动过程无需访问该反向映射。假设两条数据𝑥和𝑦的商和余数相同。由于QF按run排序,而run内的指纹按余数排序,因此𝑥、𝑦和任何其他具有相同商和余数的指纹在AdaptiveQF中连续存储。这组指纹称为一个minirun,并将其共享的商余数对称为其minirun ID。假如某条数据不与任何其他数据共享商余数对,则认为其指纹包含在长度为1的minirun中。反向映射将minirun ID映射到具有该minirun ID的所有数据的列表,同一个minirun中数据通过其在AdaptiveQF中的顺序排序。如图 2(c)所示,A和Y的minirun ID均为001a,A的排序是0,而Y的排序是1,CEDB的排序均为0。该排序主要用于查找真实数据库中存储的数据。
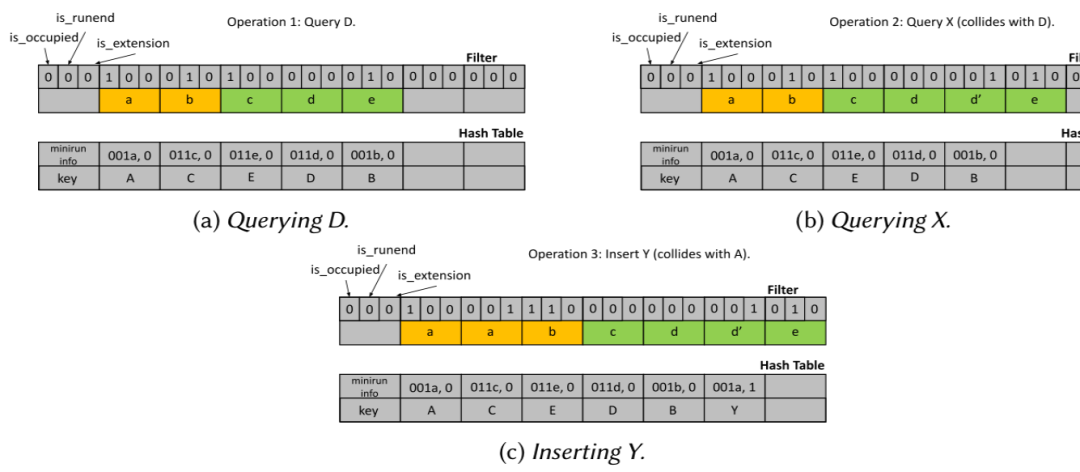
图 2 AdaptiveQF结构
由于AdaptiveQF建立在QF之上,因此很容易扩展到动态的数据上(QF天生支持自适应扩展以适应更大的数据集以及删除数据)。AdaptiveQF是单调自适应的,即它永远不会重复误报。永远不会忘记误报的代价是,随着时间的推移,AdaptiveQF 需要越来越多的插槽来保存自适应信息。因此,随着AdaptiveQF的适应,插入性能可能会急剧下降。但是,对于倾斜和对抗性工作负载,可以恢复自适应使用的空间,确保过滤器使用的总空间随时间保持不变。这会损害单调性,但仍可确保任何k个查询序列的误报数量非常接近𝜀𝑘。基本思想是定期使用新的哈希函数重建过滤器。重建过滤器将使攻击者重新处于攻击他一无所知的过滤器的位置。因此,可以在重建后删除任何自适应信息。
三.实验
实验平台:CPU:Intel(R) Xeon(R) Gold 6338 CPU @ 2.00GHz;内存:1TB;磁盘:4TB SSD。编程语言:C++。实验限制在单核上运行。
3.1 系统表现
作者评估了各种过滤器用于加速B树查询的效果,结果如图 3所示(AQF即AdaptiveQF)。使用 AQF时,系统的性能与使用非自适应QF和CF过滤器时相似。这表明,使用自适应过滤器对系统插入性能的影响几乎可以忽略不计。由于插入操作是B树的主要瓶颈,所有五个过滤器在开始时的插入吞吐量大致相同。然而,ACF和TQF随着时间的推移表现出吞吐量下降,这是由于维护反向映射的成本所致,AdaptiveQF由于需要更少的反向映射访问次数展现了巨大的优势。作者还衡量了对抗查询对系统吞吐量的影响,假设攻击者能够检测负查询和正查询(包含假阳性)之间的延迟差异,甚至在不了解实际插入集的情况下,记录一份正查询列表。然后,他们可以重复这些查询,故意引发 I/O 操作。即使在有缓存的系统中,攻击者也只需要收集足够的假阳性来使缓存过载,然后在这些查询之间循环,导致缓存失效。当提供更大的缓存时,非自适应过滤器的性能略有提高。然而,即使缓存能够容纳25%的数据集,一个占总查询不到1.5%的攻击者也可以使整个系统的查询吞吐量降低2倍。直觉上会认为,较大的缓存应该能够抵消攻击者的影响,然而,这些实验表明,增加缓存大小对对抗性攻击的影响的效果不成比例地降低。此外,由于缓存是页面缓存,对抗者只需从每个页面收集一个假阳性,就能有效地进行攻击。总之,任何合理大小的缓存对于这种特定类型的对抗查询来说基本上都是无效的。而AdaptiveQF无论对抗性查询的频率如何,都能提供高且一致的查询性能。即使没有对抗性查询,AQF 的查询性能也与非自适应过滤器相当。但是,在存在对抗性查询时,它的查询性能可以高出一个数量级。

图 3 插入/查询效率
3.2 真实数据集表现
图 4展示了在查询过程中自适应过滤器的假阳率和空间使用的变化速率。三种自适应过滤器的假阳率都随着查询的增加而下降。这是因为自适应过滤器在查询序列的初期就适应了热点项。随后,过滤器逐渐适应不频繁出现的项,每个不频繁项带来的假阳率下降较小。
在Caida和Shalla数据集上,三个自适应过滤器的假阳率随时间下降的速率相似。这两个数据集的分布不是特别倾斜,因此在这些数据集上,AdaptiveQF相比于TQF和ACF的强适应性优势不太明显。
在Zipfian查询中,所有三个过滤器的假阳率都等量下降。然而,随着时间的推移,AdaptiveQF 的假阳率降到低于TQF和ACF。这表明,AdaptiveQF的强适应性保证了随着时间推移更低的假阳率。TQF和ACF在首次遇到假阳性时未能完全适应,这可能导致它们与已经适应的键发生冲突,从而导致后续的假阳性结果。
在空间开销方面,AdaptiveQF 的空间开销(比特/项)随时间略有增加,因为适应过程需要为某些指纹占用额外的槽位。然而,由于假阳性非常稀少,这些额外的空间开销可以忽略不计,并且随着时间的推移,假阳性会变得更加稀少。

图 4 真实数据集表现
四.总结
本文介绍了强自适应的过滤器AdaptiveQF,能够在动态工作负载下始终保持较低的假阳率。通过在系统中使用AdaptiveQF,可以避免对后端存储(如数据库)的重复不必要访问,从而显著提高整体系统吞吐量。
五.参考文献
[1] Michael A. Bender, Martin Farach-Colton, Mayank Goswami, Rob Johnson, Samuel McCauley, and Shikha Singh. 2018. Bloom Filters, Adaptivity, and the Dictionary Problem. In Proc. 59th Annual IEEE Symposium on Foundations of Computer Science (FOCS). Paris, France, 182–193.
[2]Bender, Michael A., et al. "Don't thrash: How to cache your hash on flash." 3rd Workshop on Hot Topics in Storage and File Systems (HotStorage 11). 2011.
[3] Tsvi Kopelowitz, Samuel McCauley, and Ely Porat. 2021. Support optimality and adaptive cuckoo filters. In Workshop on Algorithms and Data Structures. Springer, 556–570.
 |
重庆大学时空实验室(Spatio-Temporal Art Lab,简称Start Lab),旨在发挥企业和高校的优势,深入探索时空数据收集、存储、管理、挖掘、可视化相关技术,并积极推进学术成果在产业界的落地!年度有3~5名研究生名额,欢迎计算机、GIS等相关专业的学生报考!

图文|何 翔
校稿|朱明辉
编辑|李佳俊
审核|李瑞远
审核|杨广超
