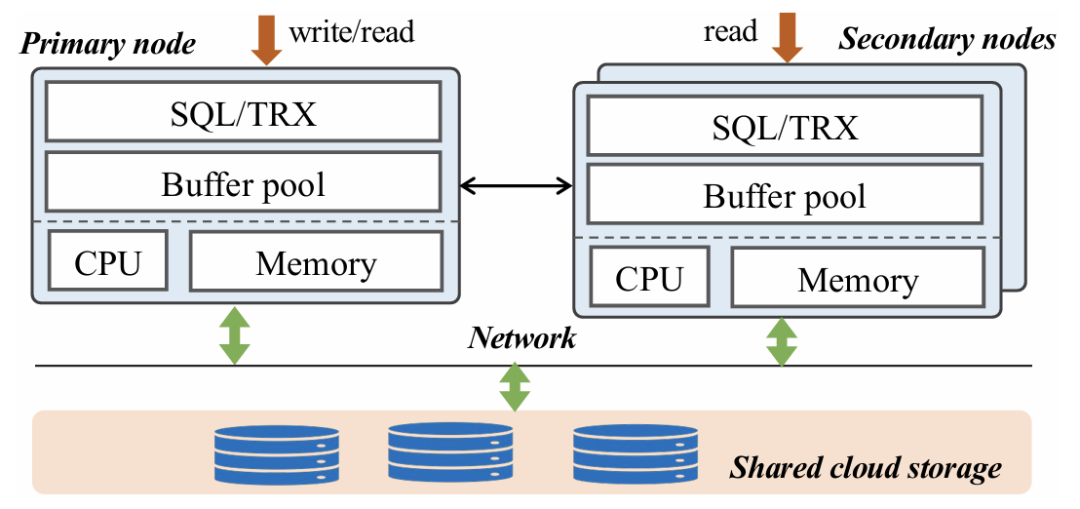
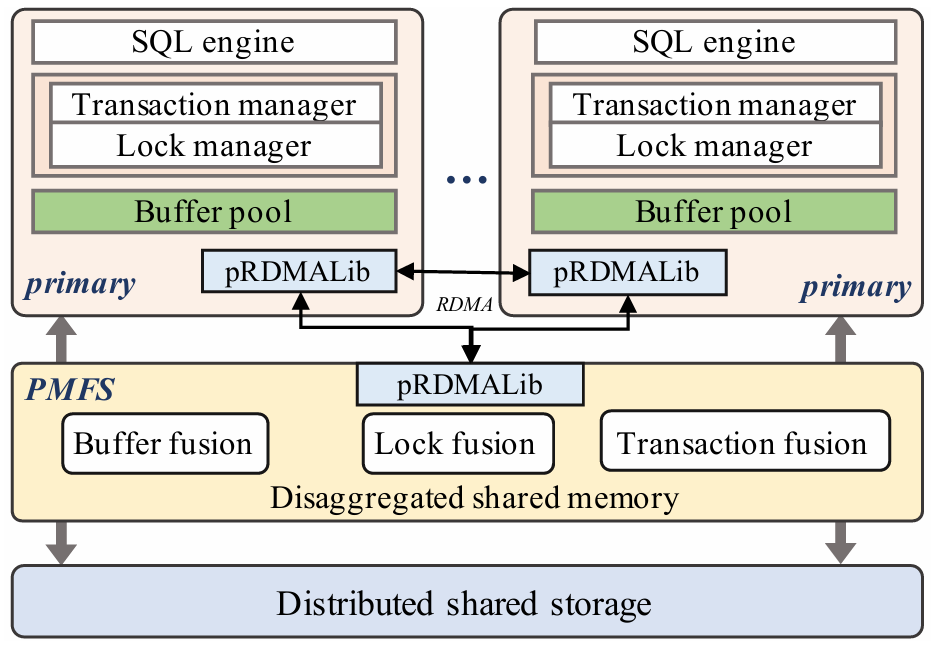
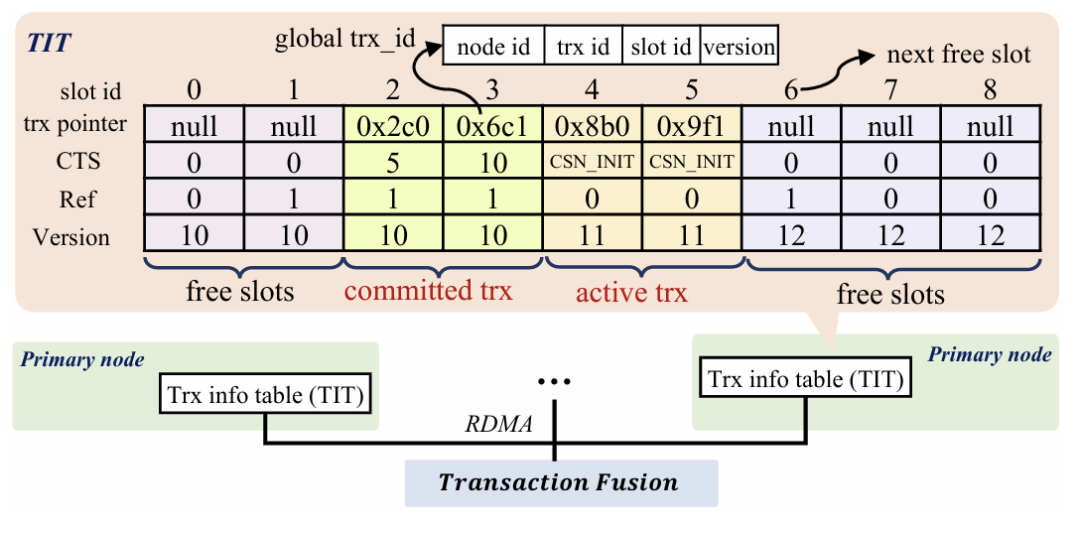
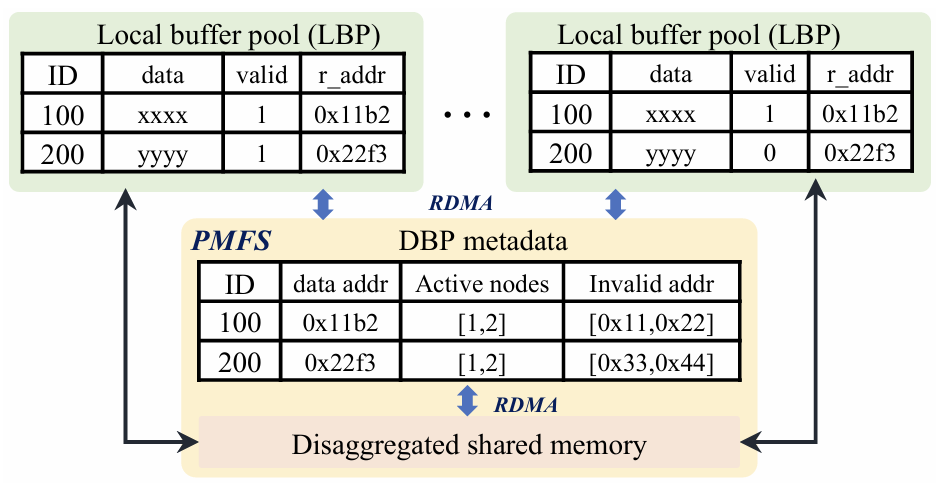
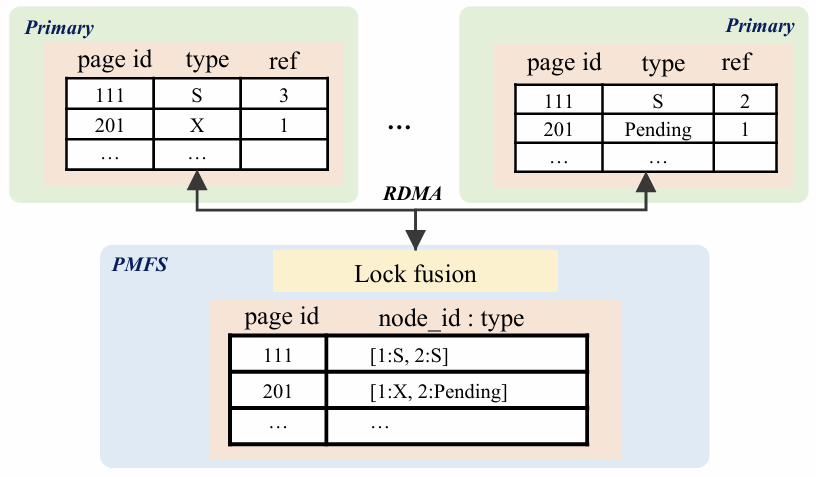
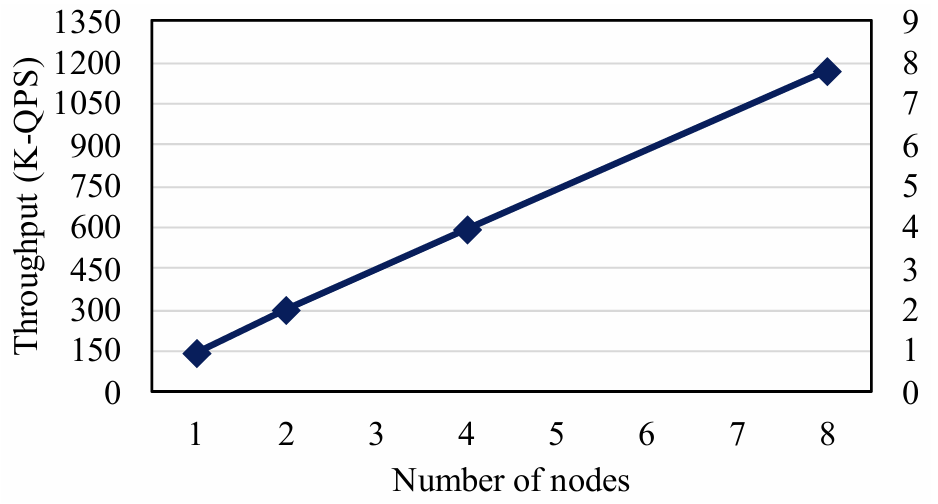
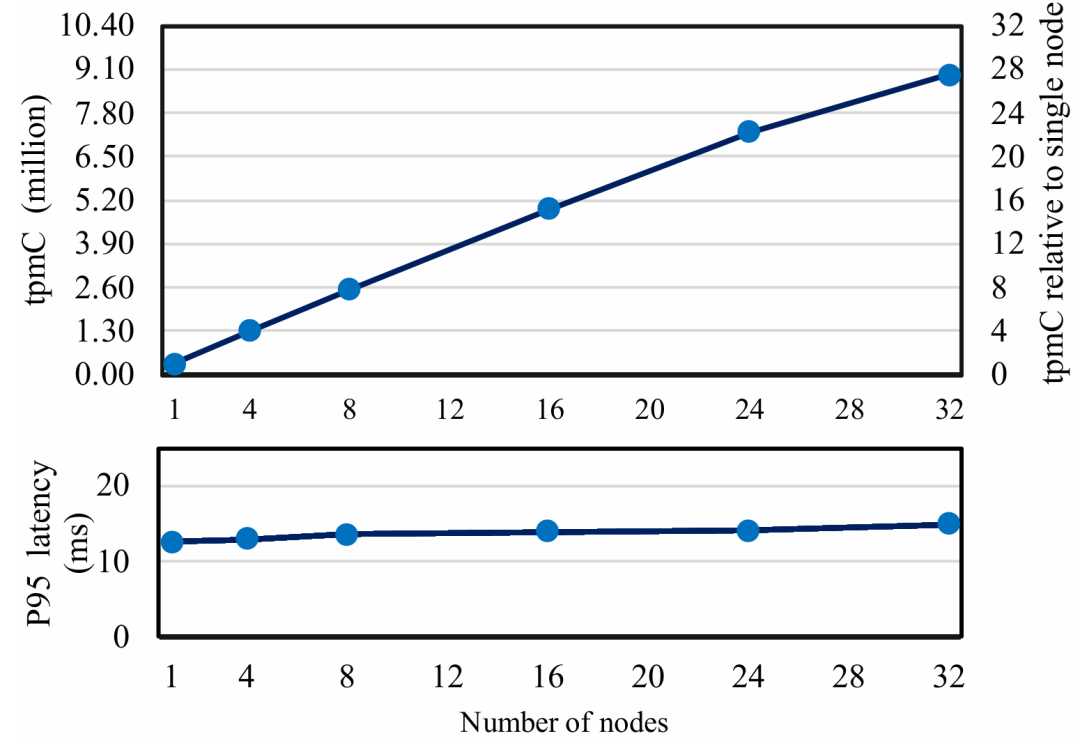
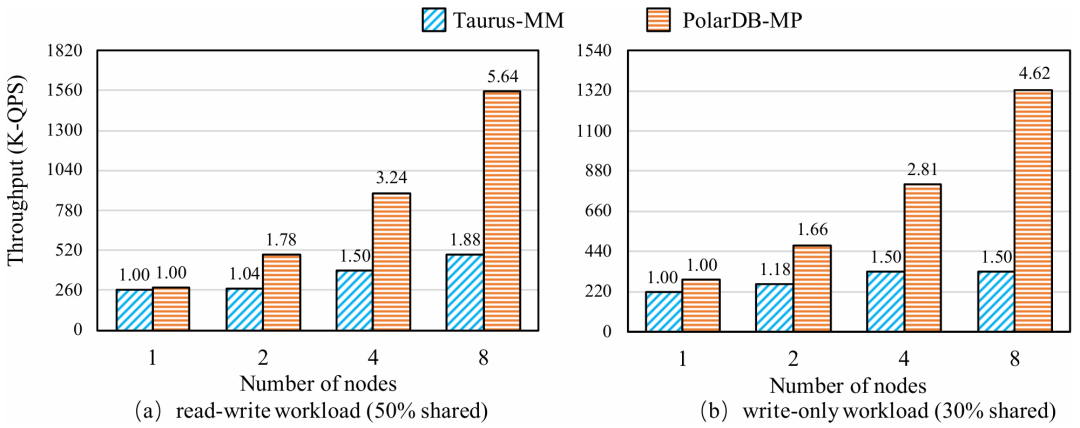
大数据时代巨大的数据量使得分布式数据库的需求越来越广泛。在分布式数据库中,主从架构的分布式数据库写入吞吐量较低,因此一些开发者提出了多主集群架构,例如无共享架构和共享磁盘架构,但这两种方案也有各自的缺点。本次为大家带来数据库领域顶级会议SIGMOD 2024的文章《PolarDB-MP: A Multi-Primary Cloud-Native Database via Disaggregated Shared Memory》。许多云原生数据库(如 AWS Aurora和PolarDB)都采用了基于分布式共享存储的主从架构,主从架构通常由一个主节点和一个或多个辅助节点组成,但是主从架构的写入只能由主节点完成,导致这种架构难以应对密集写入场景,另外在主节点故障或关闭时需要将其他节点提升为主节点,这种过渡会导致短暂的停机时间。因此,多主架构的云原生数据库变得必要,两种最流行的多主架构是无共享架构(如TiDB,Oceanbase)和共享存储架构(如Oracle RAC,Amazon Aurona-MM,Huawei Tauros-MM)。在无共享架构中,整个数据库被分区,节点之间相互独立,每个节点只能从指定分区访问数据,当一个事务跨越多个分区时,需要跨分区的分布式事务机制(如两阶段提交策略),导致了额外开销。 共享存储架构与之相反,每一个集群节点都可以访问全部数据,IBM pureScale和Oracle RAC基于复杂的分布式锁管理,成本远高于现代云原生数据库,一般部署在专用计算机上,不适配云环境;Aurona-MM和Tauros-MM的扩展性不高,Tauros-MM在50%共享存储的读写负载下,一个八节点集群的数据吞吐量仅仅比单节点提高了1.8倍。针对已有架构的上述问题,论文提出PolarDB-MP,一个使用分布式共享内存和共享存储的多主云原生数据库架构。PolarDB-MP继承了PolarDB的分布式共享存储模型,允许所有主节点平等访问存储,无需使用复杂的分布式事务。与其他依赖日志重放实现节点间数据一致性的云数据库不同,PolarDB-MP 使用分布式共享内存来实现高效的缓存和数据一致性,随着远程内存访问(RDMA)在云供应商数据中心的日益普及,PolarDB-MP充分利用了RDMA以提高性能。如今,有许多基于主从架构的云原生数据库,这类数据库通常包括一个处理读取和写入的主节点和一些仅处理读取的从节点,其中的每个节点都是一个完整的数据库实例。传统的主从架构数据库中,每个节点都需要维护自己的独立存储,但云原生的主从架构数据库的特点是使用了分布式共享存储,共享存储保证了容错性和一致性,并使得增加新的节点时无需增加新的存储设备。 单主云原生数据库的问题在于可扩展性不足,在这种架构下横向扩展难以提高性能,而纵向扩展会受到物理机可用资源的限制;另外,仅有单个主节点意味着主节点迁移过程中可能导致一定时间内的停机,因此为了实现高可用性和可扩展性,多主数据库变得必要。无共享架构是一种流行的横向扩展模型,在分布式计算和分布式数据库领域中得到广泛使用,在无共享架构中每个请求都由集群中的单个特定节点处理,这样做可以尽可能地避免节点之间的竞争。无共享架构允许系统在存在节点发生故障的情况下继续运行,也允许在保持系统正常运行的同时升级节点。基于无共享架构的数据库中通常将数据分区到多个节点,每个节点对其分区中的数据具有独占的访问权限(读取和写入),具有强大的可扩展性。但是如果事务跨越多个分区,则需要分布式事务处理来维护事务的ACID属性。在保持性能的同时保证事务属性是非常困难的,针对这个问题,目前已经提出了各种技术,比如位置感知分区、推测执行、一致性级别等,但是这些解决方案通常比较复杂,并且缺乏透明度。此外当系统需要横向扩展时,可能需要对数据进行重新分区,而数据移动的过程十分耗时。总体而言,虽然无共享架构在可扩展性上具有优势,但这些优势也带来了更多的复杂性。 共享存储架构和无共享架构最大的不同点是共享存储架构的数据库中的每个节点能够读取和写入整个数据库中的全部记录,因此需要一些额外的机制保证数据一致性,例如全局锁管理器和集中式时间戳服务(TSO)等。传统的基于共享存储的数据库(如Oracle RAC)是在云计算出现之前设计的,通常部署在企业的专用硬件上,并不适合现代云环境,导致它们与现代云原生数据库相比成本明显更高。Aurora-MM和Taurus-MM是将多主数据库引入云服务的两个最新产品,它们的具体机制各有不同,但可扩展性都不及预期,在横向扩展时性能并没有得到显著的提升。MVCC(多版本并发控制)是现代数据库最流行的事务管理方案,几乎所有的关系型数据库都在使用MVCC,和其他的传统方法不同的是,MVCC不对实际的数据进行更新,而是直接创建一个数据的新版本,多个版本的数据同时存在于数据库中,这些版本对事务的可见性由数据库的隔离级别决定,其中最常见的是快照隔离。在快照隔离下,每个事务只会看到在事务开始时数据库的快照,从而确保在整个持续时间内保持一致的数据视图。每个事务使用时间戳或事务ID来确认要读取的正确数据版本,从而提供一种有效地将读取和写入操作彼此隔离的机制,这种隔离是在不依赖锁的情况下实现的,大大提高了性能。然而在共享存储多主数据库中,确定MVCC下数据项的可见性是一项重大挑战。数据可能被多个事务同时更新,因此当事务读取节点上数据项的某个版本时无法简单地确定数据的可见性,为了确定当前版本在给定隔离级别下对事务的读取视图是否可见,节点必须能够访问全局事务信息。在不同节点之间同步全局事务信息通常会产生相当大的开销,这种信息同步的复杂性是一个关键问题,在现有系统中尚未得到彻底解决。PolarDB-MP使用了一种创新的PolarDB-MP融合服务(PMFS)解决这一问题,在PolarDB-MP中每个节点只维护自己的本地事务信息,其他节点可以通过RDMA访问该节点的事务信息,这使得事务能够准确地确定数据项在MVCC 下的可见性。 多主数据库集群不可避免地需要传递消息来实现不同节点的数据同步和并发控制,这使得网络成为提高性能的重要瓶颈,幸运的是随着网络技术的进步,网络瓶颈越来越不重要。网络技术的飞速进步使高性能的RDMA成为可能,例如NVIDIA的ConnectX-7 InfiniBand网卡能够为设备提供高达400Gbps的数据传输速率,将RDMA延迟降低到微秒级别。PolarDB-MP利用基于RDMA的分布式共享内存,在不同节点之间直接传输数据页,锁管理信息和事务协调消息。PolarDB-MP使用基于PolarStore和PolarFSD的共享存储,在分布式共享存储上层的是PolarDB-MP的核心PMFS,它使所有节点都能平等地访问内存中的共享数据并同时处理读写请求。PMFS的主要功能是管理不同节点之间的全局事务并发和缓存区一致性,它由三个核心组件组成:事务融合,缓存融合和锁融合。事务融合旨在管理全局事务处理,保证事务的ACID属性。它维护一个全局时间戳来管理事务提交,实现MVCC下的快照隔离。缓存融合使用分布式缓冲池(DBP)。DBP中利用分布的共享内存缓存大量的数据页,当节点对数据页进行更新时,它会在适当的时间将更新的页推送到DBP。随后如果另一个节点需要此页面,它可以直接从DBP检索最新版本。高速RDMA网络保证了主节点和DBP之间的快速沟通,从而确保数据页面在不同节点之间快速移动。锁融合负责实现两个锁协议:页面锁PLock和行锁Rlock,PLock协议保证了不同节点同时访问时页面的物理一致性。只有当节点持有相应的独占/共享PLock时,才能写入或读取页面;RLock 协议保证了用户数据的事务一致性,并且通常遵循两阶段锁定协议。为了减少RLock请求带来的消息开销,PolarDB-MP 将行锁信息直接嵌入到行数据本身中,在锁融合中维护等待关系。 PolarDB-MP使用TSO进行事务排序,当事务提交时,需要从TSO请求一个递增分配的提交时间戳(CTS),借助于RDMA操作,CTS的获取只需要几微秒。为了有效地管理集群中的所有事务信息,PolarDB-MP采用了一种分布化的方法,将事务信息分布在所有节点上。PolarDB-MP 中的每个节点都预留了一小部分内存,存储本地的事务信息,同时一个节点可以通过RDMA轻松地远程访问另一个节点的交易信息。如图3,每个节点都在事务信息表(TIT)中维护其本地事务的信息,TIT为每个事务维护四个关键字段:pointer、CTS、version 和 ref,pointer是事务对象的指针,CTS 标记事务的提交时间戳,version 用于同一个槽中的不同事务,ref用于指示是否有任何事务正在等待此事务释放行锁。当一个事务在某一个节点上开始时,PolarDB-MP为这个事务分配一个全局唯一的ID和一个空闲的TIT槽位,TIT槽位可以被重用,因此需要用一个递增的version字段区分不同时期占用同一槽位的事务。为了在集群维度识别一个事务,PolarDB-MP将node_id、trx_id、slot_id和version组合成了一个全局事务ID(g_trx_id)。有了这个g_trx_id,任何节点都可以通过RDMA远程访问其他节点事务的CTS,只需要维护节点本地的事务信息,大大降低了开销。 g_trx_id和CTS在MVCC的实现中至关重要,在PolarDB-MP中直接被存储在行的元数据中,在更新某个记录时,会将全局事务ID(g_trx_id)存储在该记录的元数据中。为了利用g_trx_id和CTS正确地保证数据对给定事务可见性,需要设定正确的机制以获取正确的CTS,PolarDB-MP设置了以下算法:当事务提交时,如果当前事务所修改的记录在缓存中,就将事务的CTS写入到记录的元数据,否则将CTS保持为默认值(CSN_INIT)不变。在判断记录的可见性时,如果该记录的CTS不是CSN_INIT,就可以直接从该记录的元数据中获取CTS。如果该记录的CTS为CSN_INIT,则需要从TIT获取该记录的CTS:首先需要从元数据中获取g_trx_id,然后使用g_trx_id获取相应的TIT槽位。如果TIT中的version和正在检查的g_trx_id的version不匹配,则表明TIT槽位已被新的事务重用,意味着原始的事务已经提交。在这种情况下,仅返回一个最小的CTS,表示这个事务应当全局可见,因为只有当一个TIT槽位的CTS小于所有活跃事务的CTS时,该TIT槽位才会被重用。反之,如果slot的version和当前g_trx_id的version匹配,就可以直接从TIT槽位中直接获取CTS,另外如果该事务处于活动状态,就返回最大的CTS值,表示数据对与除了自己以外的所有事务都不可见。整个算法流程的伪代码如下: 每个PolarDB-MP节点都可以更新任何数据页,使得不同节点之间的页面传输非常频繁,因此PolarDB-MP提出了缓存融合,节点将数据页推送到分布式缓存 (DBP),随后另一个节点可以从DBP访问页面。在这种情况下,页面可以在不同节点之间高效、低延迟地移动,DBP的设计如下图所示: 如图所示,每一个节点都有自己的本地缓存(LBP),当DBP中存储了页面的新版本,DBP会让其他节点上的本地副本失效,从而强制这些节点重新从DBP获取页面的最新版本。PolarDB-MP实现了PLock和RLock两种锁协议。PLock类似于传统单节点数据库中的页面锁,确保对页面的原子访问,并发访问时只有持有PLock的节点才能对数据库页面进行读写操作。PLock的设计如图所示:每个节点维护它持有或正在等待的PLock,并用一个引用计数来指示使用特定PLock的线程数。当节点需要一个PLock时,它会首先检查本地的PLock管理器,查看是否已经持有所需的锁或更高级别的锁。如果没有,它会通过基于RDMA的RPC从锁融合服务请求PLock。PolarDB-MP在每一行数据中直接嵌入RLock信息,也就是额外增加一个字段来表示持锁事务的ID。当事务尝试锁定一行时,只需将其全局事务ID写入此字段。如果该行的事务ID字段已经被另一个活跃事务占用,则当前事务必须等待。RLock遵循两阶段锁协议,这种设计减少了锁信息的管理复杂性和存储开销,另外,直接在行中嵌入锁信息可以快速检测和解决锁冲突,而不需要在一个中心节点统一地维护所有的锁状态信息,从而提高了数据库进行事务处理的效率。实验设备:每个物理机配备2个Intel Xeon Platinum 8369B CPU 和1TB 的DDR4 DRAM,通过100Gbps Mellanox ConnectX-6网络互相连接。系统配置:8个vCPUs和32G内存(8c32g),缓存大小为24g。评估基准:启用读提交隔离,在三个标准 OLTP 基准测试(SysBench、TPC-C 和 TATP)上评估 PolarDB-MP。对于SysBench基准测试,为每个实例配备8vCPU和32GB内存,配置SysBench为每组40个表,每个表包含100万条记录,评估不同工作负载(只读、读写和只写)和节点间不同共享数据量下的吞吐量,实验结果如图所示: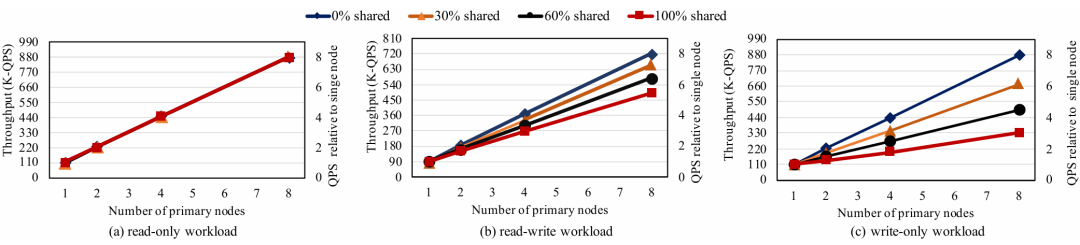 图7 SysBench结果对于只读工作负载,PolarDB-MP始终表现出线性可扩展性;在读写和只写工作负载中,PolarDB-MP在数据分区良好(0% 共享数据)的场景中观察到近线性可扩展性。但是,随着共享数据百分比的增加,由于数据同步和交易协调开销的增加,可扩展性开始下降。尽管如此可扩展性仍然相当可观。对于TATP基准测试,为TATP每个节点设置2000万订阅者,实验结果如图所示,展示了PolarDB-MP的高效的可扩展性和良好的性能:接下来使用TCPC对PolarDB-MP进行大规模集群的评估,在这次测试将 PolarDB MP扩展到32个节点,每个节点配备32个虚拟CPU(vCPU),最终总共有 1024 个 vCPU,TPC-C主要模拟与单个仓库相关的事务,只有大约11%的交易涉及跨仓库操作。在本次测试中主要关注记录每秒新事务(tpmC)以及事务95%的延迟(P95),如图所示:结果表明,PolarDB-MP 展示了近乎线性的可扩展性,在32个节点上,PolarDB-MP实现了910万 tpmC 的吞吐量,是单个节点吞吐量的28倍。P95延迟随节点数量增加而增加的幅度极小,这表明 PolarDB-MP保持了较低的延迟。AuroraMM和Taurus-MM代表着当今多主云原生数据库的最新进展。但是它们目前在在公有云中不可用,也不开源,因此论文基于Taurus-MM论文的性能数据进行比价,使用相同的节点和SysBench配置,在对比测试中配置了共享数据百分比为50%用于读写,30%用于只读工作负载,这反映了Taurus-MM评价标准中性能最高的共享数据场景,实验结果如图所示:实验结果表明,PolarDB-MP与Taurus-MMina的单节点性能相当,然而,PolarDB-MP的优势在多节点中变得十分明显,例如在只读和仅写工作负载中,PolarDB-MP 的吞吐量分别是Taurus-MM的3.17倍和4.02倍。值得注意的是,Taurus-MM将节点数量从4增加到8时,读写工作负载中吞吐量只提高了25%,仅写工作负载中甚至没有提高。相比之下,PolarDB-MP 的可扩展性比Taurus-MM高得多,这凸显了在节点数据竞争激烈的场景下PolarDB-MP 的高扩展性和高效率。论文介绍了PolarDB-MP,一个利用分布式共享内存框架的多主云原生数据库。在 PolarDB-MP 中,集群中的每个节点都可以平等地访问所有数据,这使得事务可以在单个节点上处理。PolarDB-MP 的核心组件是利用分布式共享内存实现的Polar多主融合服务(PMFS)。PMFS主要分为三个部分:用于事务排序和可见性的事务融合、用于全局共享缓存区的缓存融合、用于并发控制的锁融合,这些组件与现代RDMA网络技术无缝集成,大幅提高了性能。在多个基准测试中,PolarDB-MP与Taurus-MM 等解决方案相比具有显着优势。
图7 SysBench结果对于只读工作负载,PolarDB-MP始终表现出线性可扩展性;在读写和只写工作负载中,PolarDB-MP在数据分区良好(0% 共享数据)的场景中观察到近线性可扩展性。但是,随着共享数据百分比的增加,由于数据同步和交易协调开销的增加,可扩展性开始下降。尽管如此可扩展性仍然相当可观。对于TATP基准测试,为TATP每个节点设置2000万订阅者,实验结果如图所示,展示了PolarDB-MP的高效的可扩展性和良好的性能:接下来使用TCPC对PolarDB-MP进行大规模集群的评估,在这次测试将 PolarDB MP扩展到32个节点,每个节点配备32个虚拟CPU(vCPU),最终总共有 1024 个 vCPU,TPC-C主要模拟与单个仓库相关的事务,只有大约11%的交易涉及跨仓库操作。在本次测试中主要关注记录每秒新事务(tpmC)以及事务95%的延迟(P95),如图所示:结果表明,PolarDB-MP 展示了近乎线性的可扩展性,在32个节点上,PolarDB-MP实现了910万 tpmC 的吞吐量,是单个节点吞吐量的28倍。P95延迟随节点数量增加而增加的幅度极小,这表明 PolarDB-MP保持了较低的延迟。AuroraMM和Taurus-MM代表着当今多主云原生数据库的最新进展。但是它们目前在在公有云中不可用,也不开源,因此论文基于Taurus-MM论文的性能数据进行比价,使用相同的节点和SysBench配置,在对比测试中配置了共享数据百分比为50%用于读写,30%用于只读工作负载,这反映了Taurus-MM评价标准中性能最高的共享数据场景,实验结果如图所示:实验结果表明,PolarDB-MP与Taurus-MMina的单节点性能相当,然而,PolarDB-MP的优势在多节点中变得十分明显,例如在只读和仅写工作负载中,PolarDB-MP 的吞吐量分别是Taurus-MM的3.17倍和4.02倍。值得注意的是,Taurus-MM将节点数量从4增加到8时,读写工作负载中吞吐量只提高了25%,仅写工作负载中甚至没有提高。相比之下,PolarDB-MP 的可扩展性比Taurus-MM高得多,这凸显了在节点数据竞争激烈的场景下PolarDB-MP 的高扩展性和高效率。论文介绍了PolarDB-MP,一个利用分布式共享内存框架的多主云原生数据库。在 PolarDB-MP 中,集群中的每个节点都可以平等地访问所有数据,这使得事务可以在单个节点上处理。PolarDB-MP 的核心组件是利用分布式共享内存实现的Polar多主融合服务(PMFS)。PMFS主要分为三个部分:用于事务排序和可见性的事务融合、用于全局共享缓存区的缓存融合、用于并发控制的锁融合,这些组件与现代RDMA网络技术无缝集成,大幅提高了性能。在多个基准测试中,PolarDB-MP与Taurus-MM 等解决方案相比具有显着优势。| 重庆大学计算机科学与技术专业2022级本科生,重庆大学Start Lab团队成员。 | 
|
重庆大学时空实验室(Spatio-Temporal Art Lab,简称Start Lab),旨在发挥企业和高校的优势,深入探索时空数据收集、存储、管理、挖掘、可视化相关技术,并积极推进学术成果在产业界的落地!年度有3~5名研究生名额,欢迎计算机、GIS等相关专业的学生报考!
图文|高研盛
校稿|李 政
编辑|朱明辉
审核|李瑞远
审核|杨广超