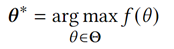现代数据库管理系统(DBMS)有数百个可配置旋钮来控制系统行为。确定这些旋钮的值以提高DBMS性能是数据库社区中长期存在的问题。目前现有基于机器学习的调优方法仍然会产生显著的调优成本,或者只产生次优性能。这是因为它们要么忽略了可用的广泛领域知识(例如 DBMS 手册和论坛讨论),并且仅依赖于基准评估的运行时反馈来指导优化,要么仅有限地利用领域知识。本次为大家带来数据库领域顶级期刊PVLDB 2024的文章《GPTuner:A Manual-Reading Database Tuning System via GPT-Guided Bayesian Optimization》。GPTuner是一个 GPT 引导的贝叶斯优化进行手册阅读的数据库调优系统,它广泛且自动地利用领域知识来优化搜索空间并增强基于运行时反馈的优化过程。

数据库旋钮选择合适的值对于提高DBMS的性能至关重要,这是数据库界长期面临的挑战。考虑到配置空间的高维性(例如,PostgreSQL v14.7有351个旋钮),以及这些旋钮固有的异构性(由于它们的连续和分类域),数据库管理员(DBA)在确定适合特定查询工作负载的配置时遇到了很大的困难。这一挑战在云环境中变得更加明显,在云环境中,底层的物理配置在不同的DBMS实例之间可能会有很大的不同。为了减少DBA手动调优的工作量,最先进的方法是通过机器学习(ML)技术自动进行旋钮调优,包括贝叶斯优化和强化学习。这些基于机器学习的调优系统遵循“试错”的主要概念,迭代地探索配置空间,在探索未知区域和利用已知空间之间取得平衡。虽然这些旋钮调优系统确实具有最终达到性能良好的旋钮配置的潜力,但它们仍然会产生显著的调优成本。因此,为了降低基于机器学习技术的高调优成本,需要设计一个利用领域知识的旋钮调优系统来增强优化过程。这个系统主要有以下两点挑战。挑战1:统一异构领域知识的结构化视图,同时平衡成本和质量是困难的。领域知识通常以DBMS手册和网络论坛讨论的形式出现,需要将其转换为统一的机器可读格式(即结构化数据)。挑战2:缺乏将结构化知识整合到优化过程中的方法。贝叶斯优化和强化学习等优化算法的内在设计并不直接支持外部领域知识的集成,需要对其标准工作流程进行大量修改。为了解决上述挑战,作者提出了GPTuner,这是一种手册读取数据库调优系统,它可以自动和广泛地利用领域知识来增强优化过程。对于挑战1,作者开发了一种基于大语言模型(LLM)的管道来收集和提炼异构知识,并提出了一种快速集成算法来统一提炼知识的结构化视图。对于挑战2,作者利用结构化知识(1)设计了一种工作负荷感知且无需训练的旋钮选择策略,(2)开发了一种考虑每个旋钮值范围的搜索空间优化技术,(3)提出了一种新的基于知识的优化框架来探索优化空间。
DB调优问题:对于一个数据库系统,数据库优化器需要在给定搜索空间θ和性能指标 f(如吞吐量或延迟)后,在搜索空间中找到一组最优参数θ*(假设目标是一个最大化问题),满足:由于有数百个可调节的旋钮且旋钮数值可能为连续或分类变量,旋钮调优是具有挑战性的。目前的研究提出了三种方法:基于启发式、基于贝叶斯优化(BO)和基于强化学习(RL)。进行实验比较后,发现基于贝叶斯优化的方法SMAC(Sequential Model-based Algorithm Configuration)产生了最好的性能,因为它使用随机森林作为代理,利用其在高维和异构配置空间建模方面的效率。该论文将SMAC视为当前最先进的不以文本作为输入的优化器,并旨在进一步改进它。鉴于GPT-4所展示的令人印象深刻的上下文学习能力,GPT-4为整个论文中的默认语言模型。(1) 用户提供要调整的DBMS(例如PostgreSQL或MySQL)、目标工作负载和优化目标(例如延迟或吞吐量)。(2) GPTuner从不同来源(如GPT-4、DBMS手册和网络论坛)收集和提炼异构知识,以构建Tuning Lake,这是一个DBMS调优知识的集合。(3) GPTuner将Tuning Lake中精炼的调优知识统一到机器可访问的结构化视图中(例如JSON)。(4) GPTuner通过选择要调整的重要旋钮来降低搜索空间的维度(即,要调整的旋钮越少,意味着维度越少)。(5) GPTuner根据结构化知识,根据每个旋钮的值范围优化搜索空间。(6) GPTuner通过一种新的粗到细贝叶斯优化框架探索优化的空间。(7) 在资源限制内(例如用户指定的最大优化时间或迭代次数)识别令人满意的旋钮配置。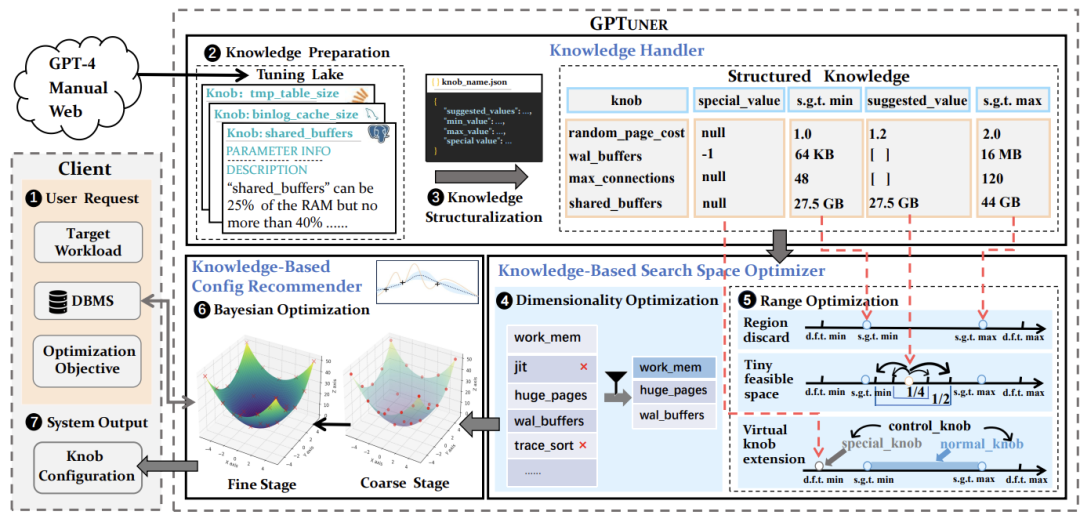
GPTuner由三个组件组成:知识处理器(Knowledge Handler)、基于知识的搜索空间优化器( Knowledge-Based Search Space Optimizer)和基于知识的配置推荐器(Knowledge-Based Configuration
Recommender)。该组件负责将来自不同来源的异构知识转换为机器可读的格式,以便后续优化过程使用。知识处理器的流程可以分为知识准备和知识转化两个步骤。知识准备又可以细化为数据摄取、数据清洗、数据集成和数据校正四个步骤。数据摄取包括LLM,DBMS手册和网络论坛的知识。数据清洗指过滤掉与系统视图冲突或质量低下的知识。LLM 会比较调优知识和官方系统视图(例如 PostgreSQL 的 pg_settings),并排除任何不一致的内容。数据集成是指将来自不同来源的知识进行汇总,处理可能存在的冲突。根据不同信息源的可靠性手动设置优先级,例如官方手册优先级最高,而 LLM 优先级最低。数据校正确保汇总后的知识与源内容保持事实一致性。LLM 会检查汇总结果是否存在与源内容不符的情况,并进行修正直到完全一致。知识转化包括属性确定和属性值确定两部分。属性确定是定义结构化知识中包含的属性,包括建议值、最大值、最小值和特殊值。属性值确定是从文本中提取特定属性值。由于 LLM 的易碎性,作者开发了提示集成算法来提高提取结果的可靠性。包括任务分解(将提取任务分解为多个子任务,例如提取建议值、最小值、最大值和特殊值),提示准备(为每个子任务准备多个提示,并包括示例来利用 LLM 的上下文学习能力),结果聚合(通过多数投票策略聚合来自不同提示的结果,选择出现频率最高的值作为最终结果)。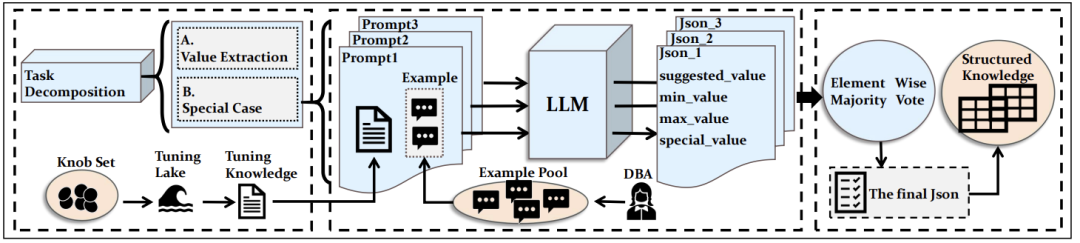
优化器从两个方面对搜索空间进行优化。首先,从维数上减小了搜索空间的大小,其次,关注每个旋钮的取值范围来优化搜索空间。作者提出区域丢弃(Region Discard、微小可行空间(Tiny viable Space)和虚拟旋钮扩展(Virtual Knob Extension)三种方法,分别用于丢弃无意义的区域、突出有希望的空间和处理特殊情况。对于维度优化,作者开发了基于LLM的旋钮选择算法(见图3)。它希望利用LLMF从旋钮集K中为特定工作负载w下的DBMS选择重要的旋钮T。该算法首先准备一个可配置的旋钮集C,其中不包括与调试、安全和路径设置相关的旋钮(第1行)。接下来,它从四个不同的级别选择旋钮:系统级别、工作负载级别、查询级别和旋钮级别。在系统级别选择中,识别极大地影响DBMS性能的旋钮,产生集C𝑠(第2行)。在工作负载级别选择期间,向LLM提供工作负载类型(例如,OLTP或OLAP)和优化目标(例如,吞吐量或延迟)来准备旋钮集C𝑤(第3行)。查询级别选择深入研究工作负载中的每个查询𝑞º(第4-9行)。具体而言,检索每个查询的执行平面,并通过诊断每个查询的性能瓶颈,识别与瓶颈相关的旋角,提取有影响的旋角集C𝑞。利用LLM F将相互依赖的旋钮补充到C𝑠,C𝑤和C𝑞的联合中,从而产生最终的目标旋钮集T(第10行)。
区域丢弃是指利用结构化知识中的最小值和最大值限制,丢弃不可能产生良好性能或可能导致系统崩溃的区域。微小可行空间利用结构化知识中的推荐值,为每个参数定义一个离散空间,并通过乘数动态调整推荐值,扩展搜索范围。乘数的公式为: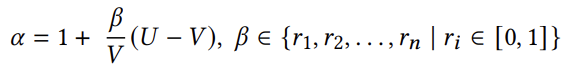
其中,𝑉是参数的建议值,𝑈是参数的最大值,𝛽缩放系数,取值范围为 [0, 1],由用户定义。在实验中,𝛽∈{0,0.25,0.5},作者对所有数值旋钮进行这种偏差处理,得到的离散空间就是微小可行空间。虚拟扩展旋钮指每个具有特殊值的配置参数都会被扩展为三个虚拟参数,分别为control_knob(值为 0 或 1,用于控制是否使用特殊值),normal_knob(表示原始参数的正常值范围)和special_knob(表示原始参数的特殊值)。通过这种方式,优化算法可以探索特殊值的所有可能值,包括特殊值 0(以lock_timeout为例,见图4)。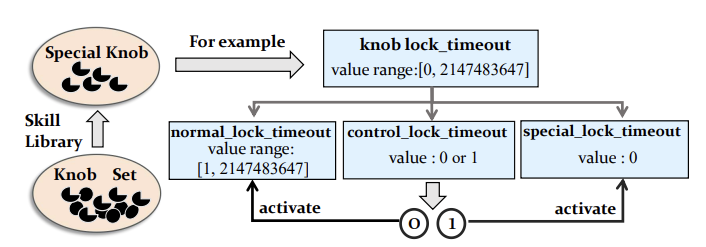
传统的贝叶斯优化(BO)算法需要大量的迭代才能收敛到最佳配置。这是因为 BO 算法需要通过运行工作负载来收集数据,并根据这些数据来构建代理模型,从而预测不同配置的性能。在配置空间较大时,这个过程会非常耗时。如果将领域知识集成到优化过程中,这种迭代成本可以显着降低,这激发了新的优化框架(粗到精贝叶斯优化框架)。粗粒度阶段:利用结构化知识构建一个细粒度的搜索空间,称为 Tiny Feasible Space。在 Tiny Feasible Space 中使用 Latin Hypercube Sampling (LHS)方法生成初始样本。使用 BO 算法在细粒度的搜索空间中进行搜索,直到达到预设的迭代次数或达到粗粒度阈值。细粒度阶段:使用粗粒度阶段的样本初始化代理模型。对整个配置空间进行区域丢弃处理,删除一些明显不会产生良好性能的区域。对具有特殊值的配置参数进行虚拟参数扩展,确保优化算法可以探索这些参数的特殊值。使用 BO 算法在整个配置空间中进行搜索,直到达到预设的资源限制或达到预期的性能提升。
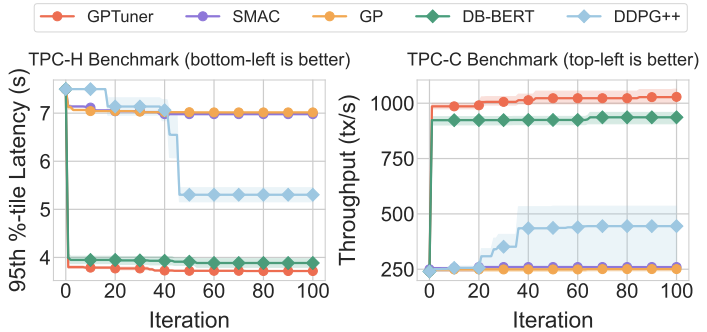
数据库管理系统:PostgreSQL 和 MySQL工作负载:TPC-H(OLAP)和TPC-C(OLTP)硬件环境:云服务器,配置 24 核 CPU、110GB 内存和 931GB SSD基线方法:DDPG++、GP、SMAC 和 DB-BERT实验结论:在 PostgreSQL 和 MySQL 上,GPTuner 都比基线方法更快地收敛到最佳配置,并且性能提升幅度更大。与 DDPG++、GP 和 SMAC 等不使用领域知识的方法相比,GPTuner 的收敛速度提高了 12.6 倍以上,性能提升幅度达到了 30%。与 DB-BERT 相比,GPTuner 的收敛速度更快,性能提升幅度也更大。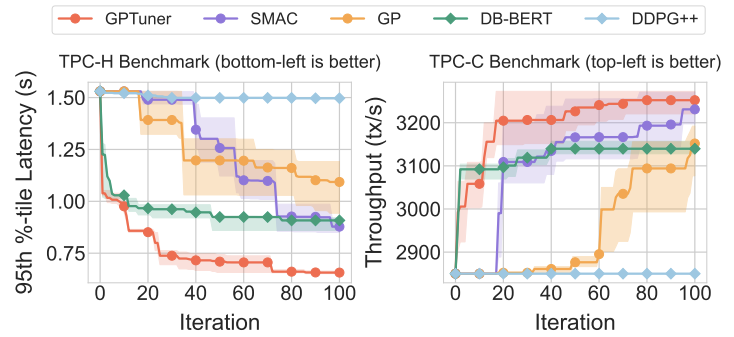
进行消融实验,分析 GPTuner 各个模块的贡献。消融实验结果表明,GPTuner 的各个模块都对性能提升做出了贡献。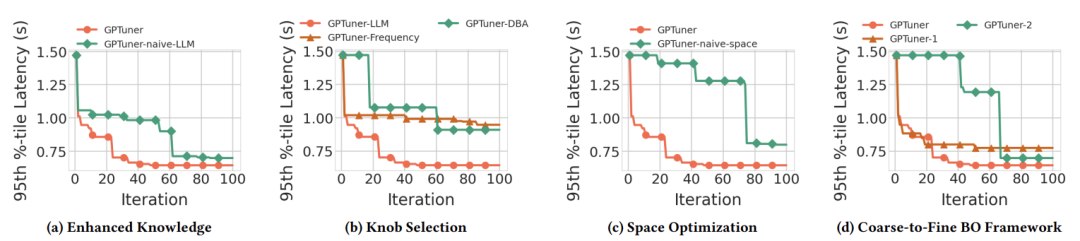
分析不同语言模型对 GPTuner 性能的影响。实验结果表明,GPTuner 可以有效地利用更复杂的语言模型,从而进一步提高性能。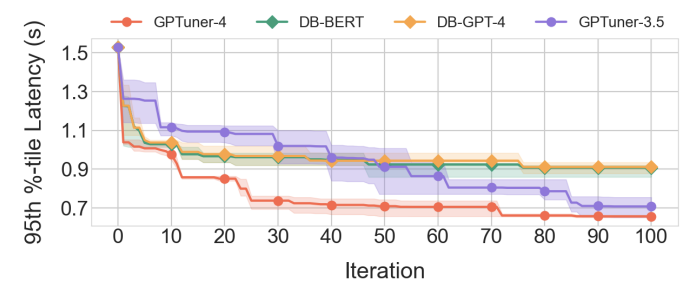
分析构建 Tuning Lake 和结构化知识的成本。每个旋钮的平均成本为LLM处理的令牌数量以及模型“gpt-3.5-turbo”和“gpt4”的相应资金。从总成本来看,准备60个PostgreSQL旋钮需要88万个token和29.5美元。考虑到令人印象深刻的性能和构建知识的可重用性,基于LLM的方法在成本和质量之间取得了很好的平衡。本文介绍了GPTuner,一个利用领域知识来提高旋钮调优过程的自动手册读取数据库调优系统。大量的实验证明了GPTuner的有效性,它优于现有的最先进的方法。| 重庆大学计算机技术专业2024级硕士生,重庆大学Start Lab团队成员。
| 
|
重庆大学时空实验室(Spatio-Temporal Art Lab,简称Start Lab),旨在发挥企业和高校的优势,深入探索时空数据收集、存储、管理、挖掘、可视化相关技术,并积极推进学术成果在产业界的落地!年度有3~5名研究生名额,欢迎计算机、GIS等相关专业的学生报考!
图文|苏赛男
编辑|徐小龙
审核|李瑞远
审核|杨广超