随着时间序列数据的流行,它们的数量迅速增加。时间序列数据库是为这类数据设计的,它们以短片的形式处理数据,这意味着压缩机的压缩单元很小。如何在压缩浮点短片的同时保留高压缩比和高解压速度仍然是一个问题。为此,今天为大家带来 DCC 2024的论文《Machete: An Efficient Lossy
Floating-Point Compressor Designed for Time Series Databases》,它提出了Machete,它首先使用了一个有效的霍夫曼编码和优化的可变长度量化(VLQ)的混合编码器,其次利用自适应编码选择使其优于短片数据压缩比,最后整体简单的框架确保了快速解压缩。多年来每天需要收集数TB的时间序列数据并存储已经是普遍的情形。为了有效处理数据,时间序列数据库设计了方便的分析功能和高效的数据布局。随着TSDB的普及以及数据规模的不断扩大,TSDB压缩器受到越来越多的关注。通过对当前TSDB的研究,论文总结了TSDB压缩中三个显著的要点:(1)严格的误差界限使得损失压缩器在大多数情况下都是可行的。这是因为时间序列数据主要用于趋势分析和预测,而损失压缩器造成的小误差对趋势影响不大。此外,固定小数点数据的小误差可以通过四舍五入来修复。如果压缩误差小于±0.5×10−l,则带有l位小数的数据的损失压缩值可以通过四舍五入无损地恢复。因此,有损压缩器可用于普通情况,无误差允许且值具有不确定小数位数的极端情况则使用无损压缩器。(2)数据以短片段进行压缩。TSDB分别对数据进行短片段压缩,有助于减少读取放大(在解压缩中)和并行处理数据。(3)解压速度至关重要。这是因为解压速度直接影响查询吞吐量和延迟。压缩速度不那么重要,因为数据压缩与写响应异步进行,对写延迟和吞吐量影响不大。提出了一种新型的损失压缩器 Machete,它将损失压缩器的高压缩比与TSDB压缩器的短片段友好和高解压速度结合起来。Machete遵循LFZip和SZ3使用的预测-校正框架。但与LFZip和SZ3专注于高精度预测器不同,它使用简单的预测器,并通过高效的编码器实现上述显著要点。LFZip和SZ3都采用了预测-校正框架。该框架在压缩中有两个阶段:预测和编码。在预测阶段,一个预测器为每个数据生成一个预测值,然后输出预测值与实际值之间的量化差异。在编码阶段,一个熵编码器对量化差异进行编码。预测阶段将浮点数转换为围绕零点聚集的整数,使它们更容易编码。在解压缩中,量化差异被解码后,使用相同的预测进行校正。采用这样的框架的压缩器在时间序列数据库(TSDB)中遇到几个困难。一方面,复杂的预测器通常会影响压缩/解压速度,这对于TSDB来说是不可接受的。另一方面,纯熵编码器不适合短片段压缩。熵编码器面临的困难如下:(1)冗余减少。图1b中的频率远低于图1a中的频率,这是数据分片的必然结果。冗余减少可能不会影响数据的熵,但它增加了熵记录的时间和空间成本(例如,Huffman编码的Huffman树或算术编码的概率表)。同时,利用跨片段的冗余是不允许的,因为它会引入序列处理和读放大,这与TSDB执行的数据分片的意图相矛盾。(2)分布变化。如图1b所示,分布可能在不同的片段之间差异很大。这种差异影响了数据的熵,在一些极端情况下(例如图1b中的最后一个图),频率甚至被平均化。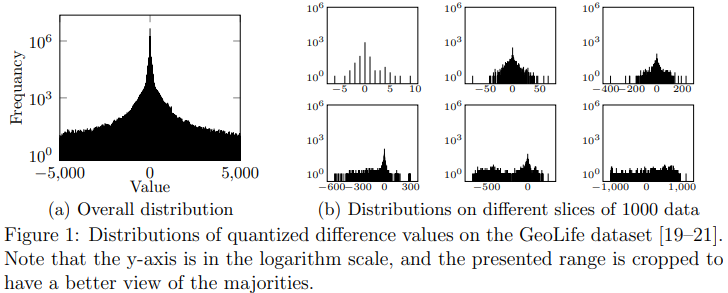
图 1
为了解决这些困难,论文提出了Machete压缩器。与以往专注于预测器设计的损失压缩器不同,更关注编码器阶段。在简化预测器以提高速度的同时,提出了一种混合编码器,自适应地应用两种高速编码:Huffman编码和可变长度量化(VLQ)。编码器以高效的方式将低冗余部分与高冗余部分分离,然后分别用VLQ和Huffman编码进行编码。此外,提出了最佳的VLQ,以最大化VLQ的压缩比,解除了由于单值编码而带来的限制,并进行了其他次要改进,包括Huffman树结构压缩和Huffman解码表。
3. 设计与实施
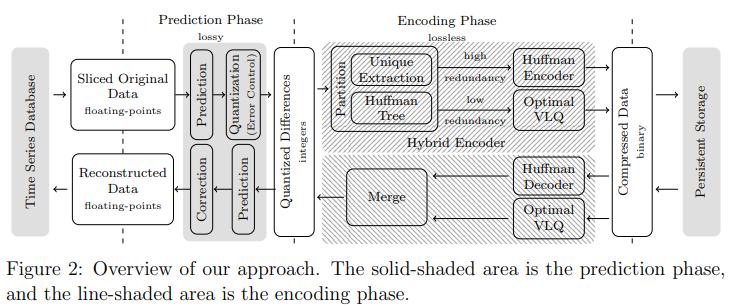
图2
图2说明了设计概述。一个时间序列数据库将一系列浮点数作为Machete压缩器的输入。作为第一步,Machete对每个值进行预测,计算预测值与实际值之间的差异,并将差异量化为整数。在量化过程中会丢失一些信息,但保证损失在用户指定的范围内。在获取所有量化差异后,Machete使用无损编码器对它们进行压缩。在解压缩过程中,解压缩器解码量化差异,进行相同的预测,然后用量化差异校正预测以重构浮点数据。
3.1 预测、量化和误差控制
真实值xi、预测值pi间的量化差值如下所示:

将浮点转换为量化差值后,使用混合编码器对其进行压缩。它结合了霍夫曼编码和可变长度量化(VLQ)来处理各种数据分布。霍夫曼编码为高频值分配更少的位,而VLQ为接近零的值分配更少的字节。从图1可知,量化的差异一般很可能接近于零,这就是为什么选择VLQ来压缩霍夫曼编码不擅长的低冗余数据。选择了底层编码器后,剩下的问题是正确地将输入进行分区并将其分配给编码器。实际上,Huffman 编码已经完成了部分工作。如果使用 Huffman 编码器对所有数据进行编码,那么低冗余数据就位于 Huffman 树内:所有呈现的值都恰好在树叶中记录了一次。所以,并不直接使用 VLQ对 Huffman 树中记录的值进行压缩,而是添加了一个额外的步骤来从 Huffman 编码器中提取唯一值(仅出现一次的值)。图3说明了如何提取唯一值。在统计了每个值的频率作为 Huffman 编码所需的编码之后,学习到了唯一符号,并将它们记录在另一个数组中,并用相同的特殊值(图3中的'$')替换它们。在提取了唯一值并完成了 Huffman 编码部分后,使用 VLQ 将 Huffman 树的值与唯一值一起压缩。在解码时,每次遇到特殊值时,从唯一值数组中加载一个唯一值。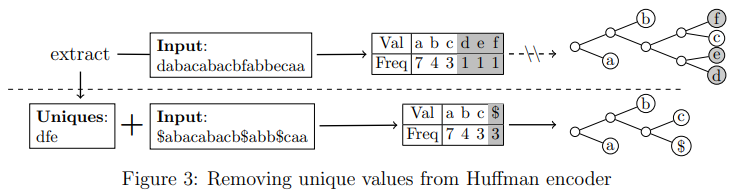
可变长度数量化(VLQ,也称为可变长度整数)是一种编码方法,它使用可变长度的字节来编码整数。它去除整数的头部零(或者如果是负数则为头部的1)(但至少保留一个头部零/一位作为符号位),这样当整数接近零时可以节省空间。VLQ 使用每个字节的最高位作为一个标志位,指示是否有更多的字节需要读取,并将数据存储在其余的位中。如果将每个字节中分散的标志位放在一起,会发现 VLQ 实际上使用了一个前缀码来记录字节数,如表1所示。
因为 VLQ 设计用于编码单个整数,所以每个编码的整数需要字节对齐,即具有8位的倍数。然而,Machete 使用 VLQ 来编码数组,因此字节对齐的限制被移除,并且标志-长度映射可以被重新定义以提高压缩比。显然,对于不同的数组,有不同的最优映射可以最大化压缩比。首先形式化寻找最优映射的问题,然后介绍如何解决它。因为标志位要么是单个的'0',要么是形如'11...10'的形式,给定一个标志位的位数,有且只有一个与之匹配的标志位。设L(flag) 为给定标志位的长度,f(L(flag)) = 数据位长度为一种映射。设 L(δ) 为量化差异 δ 的长度,使得L(δ) = l(l > 0) 当且仅当 δ ∈ [−2^l−1, 2^l−1)且 δ ∉ −[−2^l−2, 2^l−2)。特别地,当 δ = 0 时,设 L(δ) = 1。给定一个映射 f,可以构造一个函数 g(L(δ)) = L(flag),使得 f(g(L(δ))) ≥ L(δ) > f(g(L(δ))−1)。这意味着使用映射 f,δ 被编码为 g(L(δ)) 位的标志和 f(g(L(δ))) 位的数据。然后,使用如下公式 计算使用映射 f 对 δ 数组(记为 Aδ)进行编码的位长度: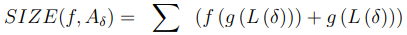
对于 Aδ 的最优映射是一种使 SIZE(f, Aδ)最小化的映射。为方便起见,将 f 表示为一个数组 [f(1),
f(2), · · · , f(n)],其中 n 是 f 域中的最大标志长度。最优映射可以通过动态规划找到。定义子问题如下:子问题 SP(l) 是在假设所有的 δ 长度不超过 l 的情况下找到最优的fl,这意味着使用 Ll(δ) = min(L(δ), l) 来替换 L(δ)。然后,证明最优子结构是为了证明如果 f = [f(1), f(2), · ·
· , f(n)] 是 SP(f(n)) 的最优映射,那么f' = [f(1), f(2), · · · , f(n − 1)] 就是 SP(f(n − 1)) 的最优映射。具体的证明用反证法可证,详情见论文。通过解决 SP(1), SP(2), · · · , SP(lmax)(其中 lmax =
max(L(δ)))来解决。对于 SP(1),只有一个可能的f,即 [f(1) = 1]。将 fl 作为 SP(l) 的最优映射,那么 fl 是以下之一:[l], f1 + [l], f2 + [l], · · · , fl−1+ [l],其中 fx + [l] 表示将 l 追加到 fx。然后,计算每个候选项的 SIZE,以找出最优的一个。此外,最优的 VLQ 也需要记录最优映射。由于量化差异是32位整数,所以 f 的范围是 [1,
32],因此可以通过设置 f(1)th,f(2)th,· · ·,f(n)th 位来使用 32 位来记录 f。
除了混合编码器和最优 VLQ 外,还有一些次要的改进技术。第一个是 Huffman 树结构压缩。Huffman 树是一棵完全二叉树,因此其结构可以通过记录从左到右的叶子高度来存储。将Huffman 树转换为规范树,使得每个叶子都不高于其右侧的任何叶子,从而对叶子高度数组进行排序。然后,记录树结构的叶子高度数组可以轻松地通过游程长度编码进行压缩。第二个是由 ZStandard 压缩器使用的 Huffman 解码表1。与逐位解码的 Huffman 树不同,解码表在 O(1) 时间内解码一个值,提高了解码速度。评估分为两个部分,均在一台装有 Xeon
Gold 6154 CPU、112.5 GiB DRAM 和7200 转/分钟磁盘的 Ubuntu 18.04 服务器上运行。在第一部分中,将 Machete 与其他压缩器进行比较;在第二部分中,将 Machete 和其他一些压缩器应用于 InfluxDB,这是一种流行的开源时间序列数据库(TSDB),以探究其影响。所有数据均以64位浮点数表示,REDD 和 Stock 具有固定的小数位数。表2还列出了在评估中使用的所有有损压缩器的默认误差界限。对于 GeoLife 和 System,误差界限足够小,适用于大多数应用。对于 REDD 和 Stock,误差界限足够小,可以通过将重建的数据舍入到相应的小数位数来检索原始数据。并非将整个数据集一次性压缩,而是首先将数据切分为不超过1000个数据点的片段(这是InfluxDB中使用的片段长度),然后对这些片段进行分别压缩。
表 2
4.3 直接评估
将 Machete 与其他压缩器进行比较,包括:(1)通用无损压缩器:Zlib2(也称为 GZip)和ZStandard(ZSTD),(2)TSDB 无损压缩器:Gorilla、Chimp128和 Elf,以及(3)有损压缩器:LFZip、SZ3。在这一部分,测量压缩比(原始数据大小与压缩大小的比率)、压缩速度和解压缩速度。相对而言,压缩比和解压缩速度更为重要。
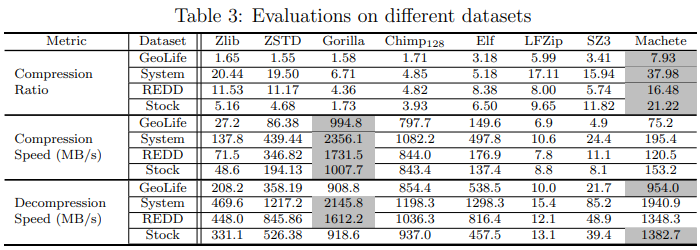
表3显示了突出显示了最佳记录的评估结果。Machete 在压缩比方面具有绝对优势,优于第二名32%−80%。同时,Machete 的解压缩速度也处于前列,接近于 Gorilla。就压缩速度而言,Machete 并无优势,但它对于时间序列数据库是足够的。在评估中,LFZip 和 SZ3 的表现远低于预期,这是短片段压缩的结果。对片段长度设置为216进行了另一次类似的评估,并发现 LFZip 和 SZ3 的压缩比接近于 Machete,而且运行速度快了几倍。同时,Machete 的性能仅略微提高。换句话说,与 LFZip 和 SZ3 相比,Machete 随着片段变短,性能下降较少。将 Chimp128、Elf 和 Machete 应用到InfluxDB 中,以查看使用不同压缩器对磁盘使用情况、写入吞吐量以及查询延迟/吞吐量的影响。分别将数据库命名为 DB-Chimp、DB-Elf 和DB-Mach。除此之外,还有一个名为 DB-Void 的数据库,它会丢弃所有浮点数据,并在查询时返回0,而 DB-Gorilla(Gorilla是 InfluxDB 的原始压缩器)。DB-Void 用于显示压缩器对数据库可以带来的改进的上限。实验结果如下图所示: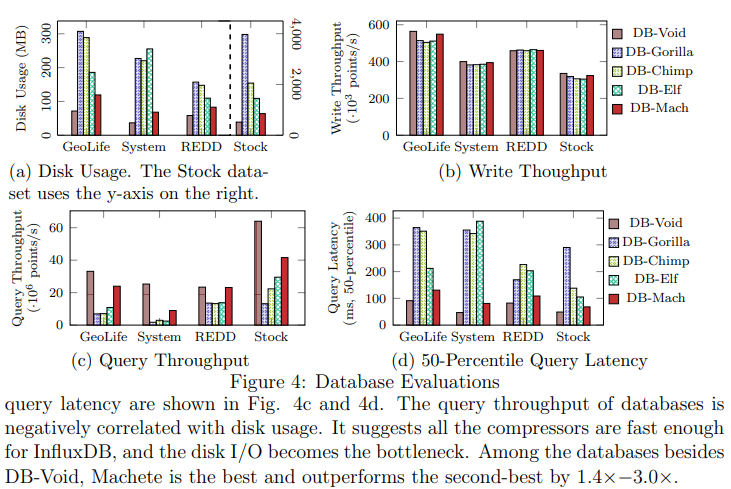
提出了一种损失浮点数压缩器 Machete。它旨在实现高压缩比,同时满足时间序列数据库(TSDB)的要求。与其提高预测器的准确性,可能会导致高计算开销不同,Machete 使用了简单的预测器,并专注于高效的编码器设计。它使用的混合编码器结合了Huffman编码和可变长度量(VLQ),旨在快速处理短片段数据。此外,还提出了最佳VLQ的概念,进一步提高了压缩比。评估结果显示,Machete在时间序列数据库场景中的压缩比方面优于最先进的压缩器,提高了32%−80%,同时解压速度与TSDB压缩器相似。当应用于InfluxDB时,它可以节省高达79%的磁盘空间,并且由于节省了I/O,显著提高了查询性能。
鲁茹芸 重庆大学计算机科学与技术专业本科在读学生,重庆大学Start Lab成员。主要研究方向:时序数据压缩 | 
|
重庆大学时空实验室(Spatio-Temporal Art Lab,简称Start Lab),旨在发挥企业和高校的优势,深入探索时空数据收集、存储、管理、挖掘、可视化相关技术,并积极推进学术成果在产业界的落地!年度有2~3名研究生名额,欢迎计算机、GIS等相关专业的学生报考!






