





1、背景
2.1 框架总览
图一展示了Grep的体系结构,其中包括三个主要模块,即Column2Graph、Partitioning Model、Evaluation Model。
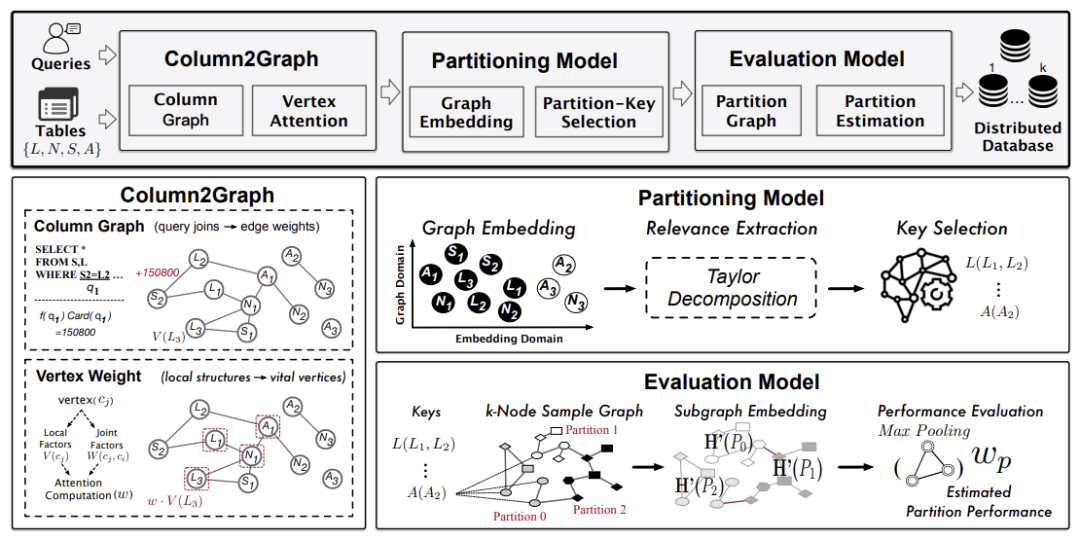
对于一个给定的数据库,Grep首先训练一个Evaluation模型,该模型预测分区策略的性能。其次,Grep基于数据和查询特征构建Column2Graph模型。通过构建出的Column2Graph模型,Grep训练一个Partitioning模型,该模型用于选择分区键。最后,Grep使用Evaluation模型对选中的键值进行评估,并反馈给Column2Graph模型(更新顶点权重)和Partitioning模型(更新GNN权重)。重复更新与评估直到收敛。
2.2 列图模型
 ,查询
,查询 ,将表列及其相关性建模为一个图模型。顶点是查询中使用的列,如果两个列在查询中连接或具有外键关系,则它们之间有一条边。
,将表列及其相关性建模为一个图模型。顶点是查询中使用的列,如果两个列在查询中连接或具有外键关系,则它们之间有一条边。 的总成本,c代表由列名转换成的点。点权由每个顶点的局部图结构(例如,读/写频率,连接成本)来计算,用顶点权重识别重要顶点,并将重要顶点作为分区键进行优先级排序。
的总成本,c代表由列名转换成的点。点权由每个顶点的局部图结构(例如,读/写频率,连接成本)来计算,用顶点权重识别重要顶点,并将重要顶点作为分区键进行优先级排序。2.2.1 基于谓词的边权
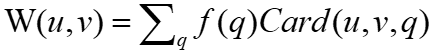 ,其中q是u,v两个点中间的任何连接谓词,
,其中q是u,v两个点中间的任何连接谓词,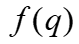 是频率,
是频率,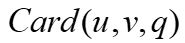 是基数。
是基数。2.2.2 基于注意力的点权
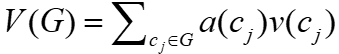 ,
,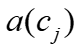 是分配的注意力,
是分配的注意力,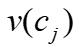 是顶点特征向量。对于每个列
是顶点特征向量。对于每个列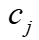 ,基于两种图特征计算其关注值。第一是顶点特征描述列字符,包括数据特征和查询特征,并使用Sigmoid激活函数来规范化这些特征,记为
,基于两种图特征计算其关注值。第一是顶点特征描述列字符,包括数据特征和查询特征,并使用Sigmoid激活函数来规范化这些特征,记为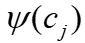 。第二是边特征,通过聚合每个顶点的连接边来计算边特征。计算公式为
。第二是边特征,通过聚合每个顶点的连接边来计算边特征。计算公式为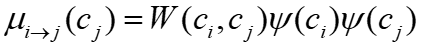 ,
,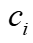 是
是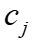 的任意相邻顶点,
的任意相邻顶点,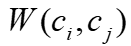 为边权。任意顶点通过下式进行编码:
为边权。任意顶点通过下式进行编码: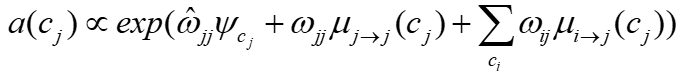
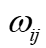 是网络权重,
是网络权重,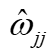 是的单位向量。注意力模型迭代计算至收敛。
是的单位向量。注意力模型迭代计算至收敛。2.3 分区键选择
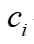 在t+1次迭代时的嵌入向量
在t+1次迭代时的嵌入向量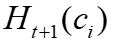 ,它基于
,它基于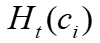 ,邻居和边权来得出。GNN迭代更新网络权值
,邻居和边权来得出。GNN迭代更新网络权值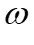 ,以学习具有最大分区效益的嵌入顶点向量。第二是分区键选择,嵌入向量是高维的,模型通过泰勒分解来估计每列的总体划分收益,该分解反过来计算嵌入向量中列的比例。之后通过二进制分类器,它输入列相关性并输出选中的列。
,以学习具有最大分区效益的嵌入顶点向量。第二是分区键选择,嵌入向量是高维的,模型通过泰勒分解来估计每列的总体划分收益,该分解反过来计算嵌入向量中列的比例。之后通过二进制分类器,它输入列相关性并输出选中的列。2.3.1 图嵌入算法
获得局部图结构,并利用图神经网络将图结构和的顶点向量嵌入到嵌入向量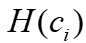 中,方法是将输入的顶点特征与GNN权重相乘,并基于性能目标迭代更新GNN权重。该过程可表示为下式,E为边矩阵:
中,方法是将输入的顶点特征与GNN权重相乘,并基于性能目标迭代更新GNN权重。该过程可表示为下式,E为边矩阵: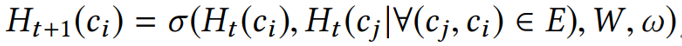
的结构信息表示为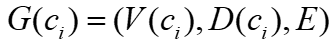 ,
,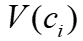 为顶点向量,
为顶点向量,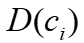 为的邻域矩阵。(2)用图卷积在
为的邻域矩阵。(2)用图卷积在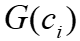 中嵌入特征,先将自连接关系添加到边矩阵E中并于单位矩阵求和,然后将连接特征嵌入到顶点向量中,再在图神经网络上传播嵌入的顶点,它为顶点分配网络权重,并输出嵌入向量。(3)应用激活函数将嵌入的特征转换为定长向量。
中嵌入特征,先将自连接关系添加到边矩阵E中并于单位矩阵求和,然后将连接特征嵌入到顶点向量中,再在图神经网络上传播嵌入的顶点,它为顶点分配网络权重,并输出嵌入向量。(3)应用激活函数将嵌入的特征转换为定长向量。2.3.2 分区键选择算法
与所有嵌入向量的相关性,并将它们聚合为总体分区效益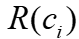 。嵌入向量取
。嵌入向量取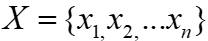 ,它们的总相关性为
,它们的总相关性为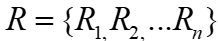 ,基于分层传播规则反向计算GNN中每个神经单元的相关性, 在最后一层L中每个神经单元的关联性表示为1。相关性的计算由下式表示,
,基于分层传播规则反向计算GNN中每个神经单元的相关性, 在最后一层L中每个神经单元的关联性表示为1。相关性的计算由下式表示,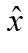 表示不影响分区的特征,
表示不影响分区的特征,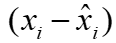 表示神经单元(l,
j)前后嵌入的变化:
表示神经单元(l,
j)前后嵌入的变化: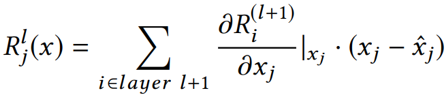
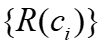 后,使用二元分类方法多项式逻辑回归来预测被选为分区键的概率。
后,使用二元分类方法多项式逻辑回归来预测被选为分区键的概率。2.3.3 模型训练
训练模型使用的数据为一个四元组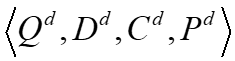 ,
,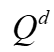 是查询的集合,
是查询的集合,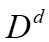 是表的集合,
是表的集合,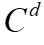 是列的集合,
是列的集合,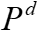 是性能指标。在训练过程中使用不同的查询和数据组合迭代地训练GNN模型,根据上述的方式构建列图,评估性能,更新网络权值。权值更新表示为
是性能指标。在训练过程中使用不同的查询和数据组合迭代地训练GNN模型,根据上述的方式构建列图,评估性能,更新网络权值。权值更新表示为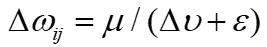 ,其中
,其中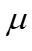 控制更新速率,
控制更新速率,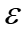 为10-6。当性能收敛或达到最大迭代次数时终止训练,并采用批量梯度下降来提高效率。
为10-6。当性能收敛或达到最大迭代次数时终止训练,并采用批量梯度下降来提高效率。
2.4 性能评估模型
2.4.1 模型介绍
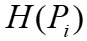 中。(2)生成一个k顶点图,由复合顶点矩阵
中。(2)生成一个k顶点图,由复合顶点矩阵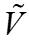 和边权
和边权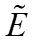 表示。对和进行卷积,将远程连接关系纳入划分向量,再将分区向量池化为图向量。(3)图向量会对k节点样本图中的特征进行编码,样本图中包含与整个数据集相似的数据和查询分布。使用全连接层,以ReLU作为激活函数,将采样元组上的图向量映射到整个数据集上的分区性能。
表示。对和进行卷积,将远程连接关系纳入划分向量,再将分区向量池化为图向量。(3)图向量会对k节点样本图中的特征进行编码,样本图中包含与整个数据集相似的数据和查询分布。使用全连接层,以ReLU作为激活函数,将采样元组上的图向量映射到整个数据集上的分区性能。2.4.2 模型训练
3、实验
3.1 实验设置
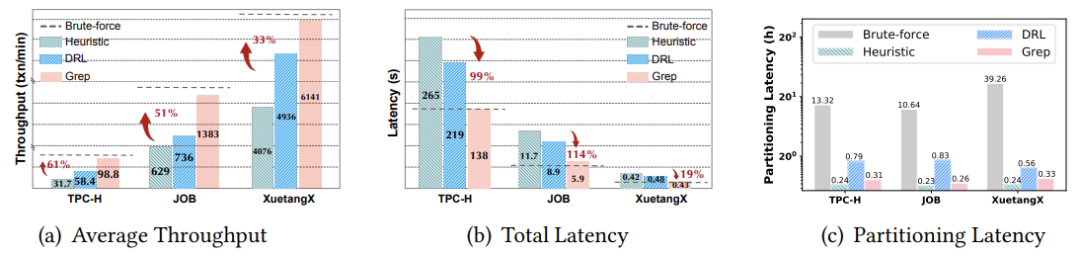
3.2 性能比较
3.3 模型评估
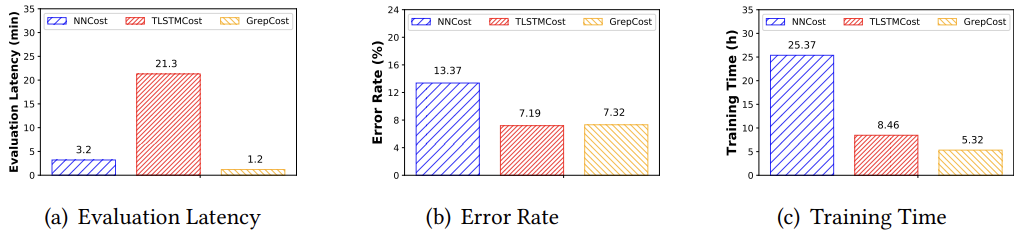
图三
模型评估
可以看出GrepCost在延迟和训练时间上分别比现有性能评估方法高出62.5% ~ 99.0%和37.1% ~ 79.0%,错误率与先分区后评估方法TLSTMCost相似。
在超参数的评估实验中,文章发现当层数小于3时,随着隐藏层的增加,性能会提高,而当层数大于3时,新的嵌入特征贡献较小,但开销较高。同时,更高的采样率会带来更好的效果,但过高的采样会使得速度降低。
3.4 适应性

4、总结
 |

图文|周敏欣
编辑|徐小龙
审核|李瑞远
