时间序列中存在着大量的脏数据,现有的时间序列清洗方面存在不小的缺陷。从脏数据识别的角度来看,大多数方法都存在较多的遗漏或错误;从清洗决策的角度来看,大多数方法得到的结果与真实值相去甚远。这些问题给时间序列数据清洗增添了许多挑战。本次为大家带来SIGMOD2024论文《Akane:
Perplexity-Guided Time Series Data Cleaning》。该文提出了基于困惑度的时间序列数据清洗算法Akane,以此来更敏感的甄别脏数据,并通过上下文给出更准确的清洗决策以确保框架的可行性。
一、背景
时间序列数据很少没有脏值,例如来自不可靠设备的传感器数据,由故障计量系统测量的能耗数据。而在数据分析领域,如分类、聚类、预测等任务中,使用脏数据分影响分析质量并使其不再可靠,对此常见的解决方案就是使用异常检测算法来识别和丢弃异常。然而,针对单一单变量时间序列,该方法会破坏分析质量。因此,人们提出并采用时间序列数据清洗算法以对脏数据进行校正。
传统的时间序列数据清理算法主要集中在平滑技术上,如移动平均(MA)、自回归(AR)。其中MA通过计算相邻点的加权平均值来确定特定数据点的清理结果,但其修改了几乎所有的数据点,倾向于过度清理。AR通过拟合给定时间序列的模型,同时生成对应的预测,对明显偏离预测的数据点,则用预测结果进行清洗,但脏数据会对拟合过程造成不利的影响。
近年来,也有一系列的算法被开发出来。如基于约束的SCREEN算法识别和纠正超过单速度约束的点。基于统计的算法SpeedChange结合了关系数据清洗的可能性清洗概念。包括一系列时间序列异常检测方法的拓展,例如NumentaHTM和FFT可以直接使用预测或重建序列进行清洗,GrammarViz或Sub-LOF可以参考挖掘的语法规则或用于异常检测的最近干净邻居进行清洗。
目前,时间序列数据清洗存在几大问题。从脏数据识别的角度来看,大多数方法存在遗漏或错误(SCREEN、SpeedChange),而Sub-LOF又将所有显示的数据点视为脏数据。从清洁决策的角度来看,大多数方法与事实偏差很大。同时,现有的时间序列数据清洗算法在清洗过程中对时间序列信息的利用是相当有限的。
基于此本文做出了如下主要贡献:
形式化了使用循环模式清理时间序列数据的问题,并引入了一个全面的四阶段算法框架,包括具体方法和参数选择策略,用于计算和优化时间序列数据中的困惑度。
减轻了对脏数据不利影响的担忧,并设计了一种自动预算选择策略,该策略依赖于估计从典型清洁案例中获得的收益,以确保框架的可行性。
对框架进行了改进,提出了一种新的基于同态模式聚合的概率计算方法,提高了框架的适用性;提出了一种基于贪婪的启发式优化算法,降低了框架的资源利用率,使框架更具通用性。
比较了12个真实数据集上的11个基线,其中包括6个真实脏数据集,以证明其工作的有效性。此外,其详细分析了每个参数对框架的影响。验证了方法和参数选择策略。
二、问题概述
时间序列:按时间排序的时间点序列。对数据点x[1],x[2],…,x[n]中的任一第i个数据点x[i],有时间戳t[i]与之相对应。困惑度:困惑度是衡量概率分布或模型对特定样本的预测能力的度量标准。本文借用NLP领域困惑定义,在时间序列下重新定义。对时间序列X以及选定的象征形式Xw下的困惑度公式如下: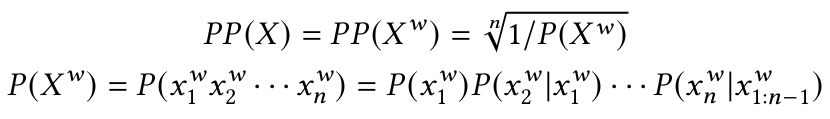
似然:由于原始时间序列范围连续,直接计算概率不可行,因此使用符号化时间序列代替。而不同的符号化策略结果差异较大。因此在使用困惑度前预先确定符号化策略。本文使用似然代替计算。时间序列的似然L(X)为: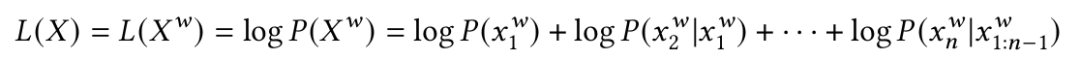
通过最大化该函数,可以方便的实现时间序列最小困惑度。
在数据清理任务中,通常需要找到一个与原始序列X相比具有更低困惑度的时间序列X'。其次,通常需要坚持最小变化原则以防止过度清洗。基于此,本文考虑清洗成本如下式所示: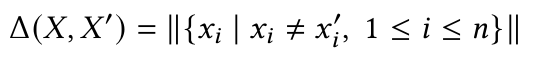
由于最小化困惑等于最大化可能性,因此本文问题具体描述为:给定长度为n的时间序列X,排序后的断点列表Breakpoints用于符号化,清理预算𝛿。找到时间序列X’,满足Δ(𝑋,𝑋’)≤𝛿同时最大化𝐿(𝑋’)。三、算法框架
3.1 框架总述
如图1所示,该算法框架共分为四个阶段:时间符号序列化、概率计算、似然优化、时间序列重建。时间序列符号化将每个连续的数值数据点转换为有限集合的符号,便于正确捕获循环模式并使后续概率计算成为可能。概率计算阶段指定了基于统计确定符号化时间序列概率的方法。似然优化采用基于动态规划的递归算法实现似然最大化,通过回调得到经过清洗的符号化时间序列。然后在时间序列重建阶段将其中的符号转换回数值,从而产生最终的清理结果。
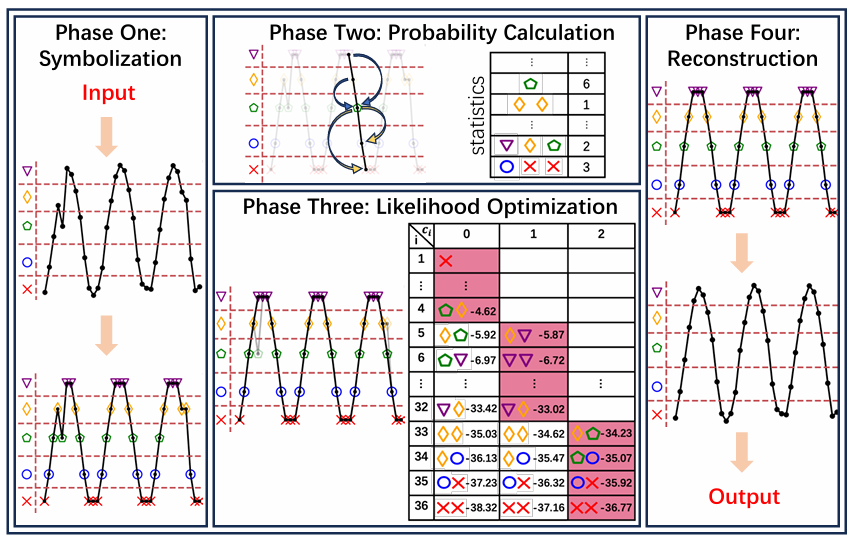
图1 算法框架
使用统一的符号,将每个连续的数值数据点转换为有限集合的符号。首先对时间序列计算Davies-Bouldin指数以得到最优聚类数,然后使用k-means算法对时间序列进行聚类得到质心以及断点。针对断点,文章计算两个相邻断点之间的距离d = (Xmax-Xmin)/r,令断点𝛽𝑎 = Xmin + a*b。通过断点,符号化时间序列。为了捕获时间序列固有的短期依赖关系和局部模式并降低计算复杂性,文章引入k-order马尔科夫链,即一个符号在时间序列中出现的概率可以认为仅仅由最后k个符号确定。概率值使用从原始时间序列中收集的统计信息来计算,同时使用加性平滑来处理零概率,公式如下:
其中r为总共的可用符号数量,C为在符号化时间序列Xw下对应子序列的概率。文章采用基于动态规划的伪多项式时间算法解决该问题,其目的是寻找具有最大似然的符号化时间序列。具体的算法实现伪代码如下:
对于一个清洗后的符号化时间序列,基于下述公式计算最大似然: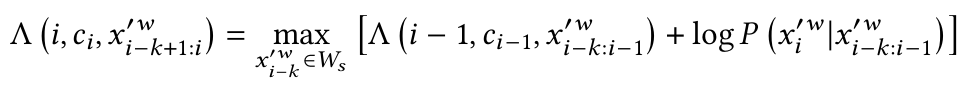
其中ci为清洗花费。如果xi'w不等于xiw,则ci-1 = ci – 1;否则ci-1= ci。初始化时,对任意符号化清洗数据点,如果ck大于前k项清洗损失和,则最大似然公式为:
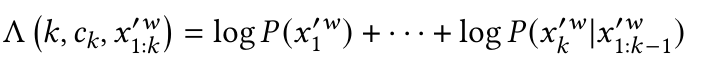
如图2所示,文章目标是降低困惑度,提高似然结果。随着预算的增加,似然值不断增加,RMS均方根误差不断降低,在预算140时,RMS误差最小,后续稳步上升,但似然依旧不断增长。这其中存在过度清洗的可能性。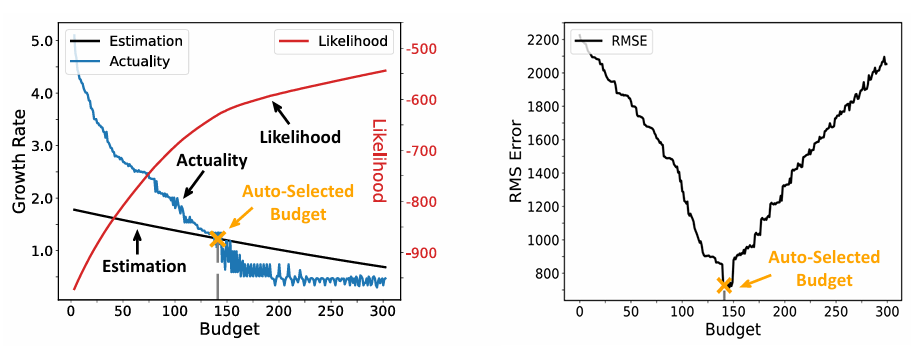
自动预算选择的伪代码如算法2所示,在逐步增加预算的过程中,若实际增长率接近并持续匹配理论下限,就停止清洗过程并输出最终结果。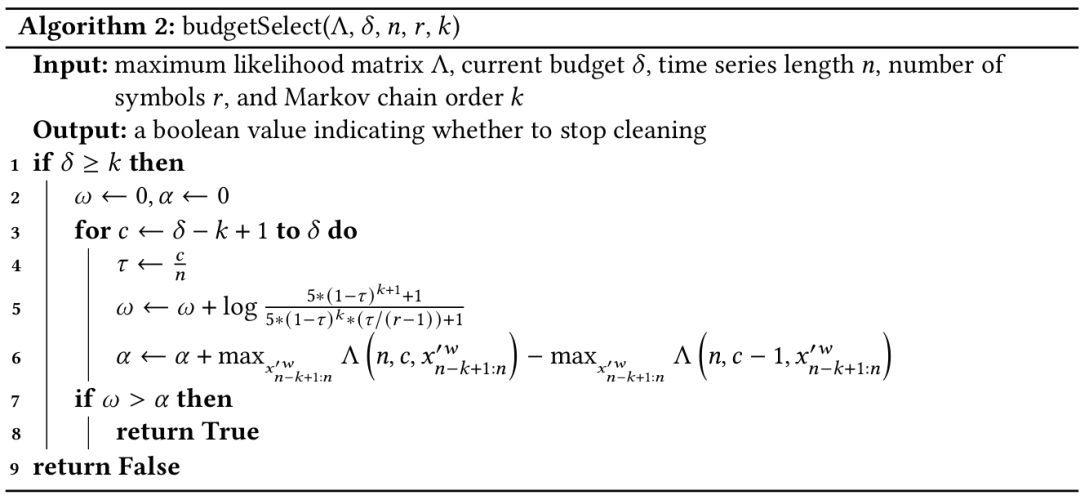
经历前三阶段,获得了一个具有最大似然和最小困惑的符号化时间序列,接下来便是将符号重建到数值的时间序列以完成清洗过程。文章设计了一个基于线性回归(LR)的策略。对于一个清洗过的数据点,首先选择它所属最频繁的模式拟合,对于时间序列中所有相同的模式,将其中与清洗数据点位置相同的数据点的值设置为模型目标,将真实数据点对应的值设置为模型输入,然后利用这些拟合LR模型并得到参数。之后便计算清洗后数据点的重建结果。如果没有合适的模式或足够的初始干净数据点用于拟合,也可以直接选择质心作为结果。如图3所示,尽管变化方式表现相似,并且可能是反复出现的模式,但由于不同的基础值使他们的值变化很大。在这种情况下,概率计算阶段会将这样的模式单独计算。这些模式被称为同态模式,对行为相似的模式属于同一个同态集合。这种情况通常导致模式稀疏,文章通过引入同态模式聚合解决该问题。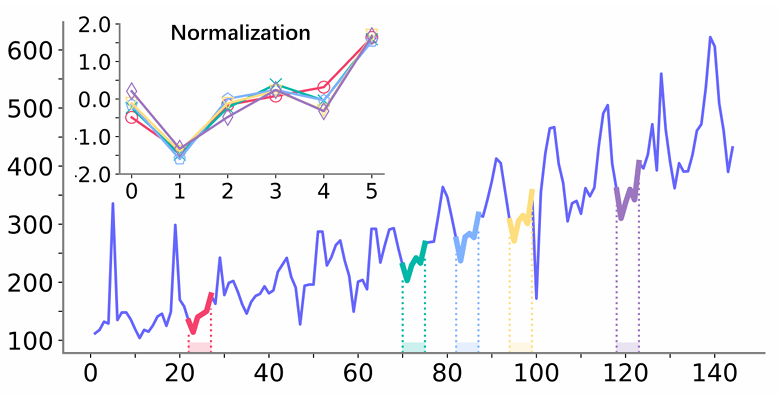
在符号化时间序列的基础上,使用符号化数据点的质心值进行时间序列归一化来消除模式间尺度差异。此外,使用RMS误差来衡量归一化符号模式间的同态性: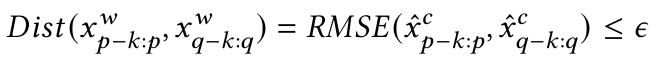
其中ϵ为距离阈值。在对特定模式进行概率计算时,将属于其对应同态集的所有模式聚合起来进行计算。在似然优化阶段,由于是全局优化,产生了时间和空间上显著的资源利用率。文章采用一种简单的逼近策略,即贪心算法。然后设计了一种启发式算法去捕捉似然增长。由于全局优化问题的目标是最大化似然,因此可以每次贪婪地清理一个点,以达到最大似然增量,直到达到自动选择的预算。该算法在关注效率时优先考虑。当逐步增加更多点的最大似然增量时,退化为全局优化。从本文自身的算法框架中选择三种方法评估其整体性能,Akane (K-Means符码化+全局优化,无模式聚合),AkaneH
(K-Means符码化+启发式算法,无模式聚合)和AkaneH+(均匀符码化+启发式算法,有模式聚合)。实验选择12个真实数据集。11个方法为基线,包括EMWA、AR-Linear、AR-LSTM、SCREEN、SpeedChange、Torsk、NumentaHTM、TripleES、FFT、GrammarViz、Sub-LOF。以均方误差作为评价时间序列数据清理算法质量标准。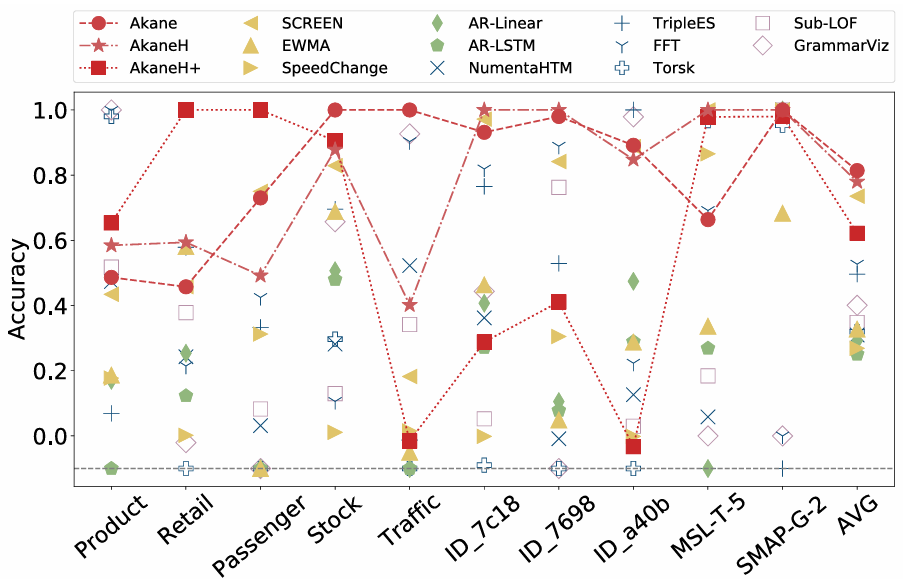
EWMA的有效性有限,而AR算法通常进行不准确的拟合,并错误地修改许多最初干净的数据点。6种基于异常检测的方法的性能也一般,FFT、TripleES和GrammarViz在其中表现出相对较强的性能,SCREEN通过利用地面真实值来识别大的峰值而表现良好。SpeedChange可以识别和纠正一些脏点,但由于其速度变化假设,可能会将它们与干净数据混淆,从而导致性能欠佳。本文的方法总体上比现有的方法表现得更好(除SCREEN)。对于Traffic, ID_7c18, ID_7698和ID_a40b数据集,AkaneH+表现不佳,因为数据中许多微小且不显著的变化使得难以捕获有意义的循环模式并选择精确的预算。对于产品、零售和客运数据集,AkaneH+优于Akane和AkaneH,因为这些数据集中存在单一趋势,证明了采用同态模式聚合来检测和解决隐蔽偏差的有效性。综合来看,Akane和AkaneH使用K-Means符号化,更适合具有特定非均匀分布特征的真实数据集。Akane优先考虑高效率,而AkaneH则利用贪婪的思想,在保留大部分功效的同时强调效率。AkaneH+使用万无一失的统一符号和同态模式聚合,适合于没有这种分布或太多先验知识的数据。文章具体评估了符号数r、马尔科夫链阶k、同态模式距离阈值对性能的影响。图5显示了使用K-Means进行符号化的算法性能,以及对应的DBI在𝑟变化时的性能。对脏CA和罗马尼亚时间序列使用𝑟= 6,对ID_7698使用𝑟= 3,对ID_7c18使用𝑟= 2,产生最小DBI,一致地为Akane和AkaneH产生几乎最佳的清洁结果,验证了文章提出的在K-Means中选择符号数𝑟的方法的有效性。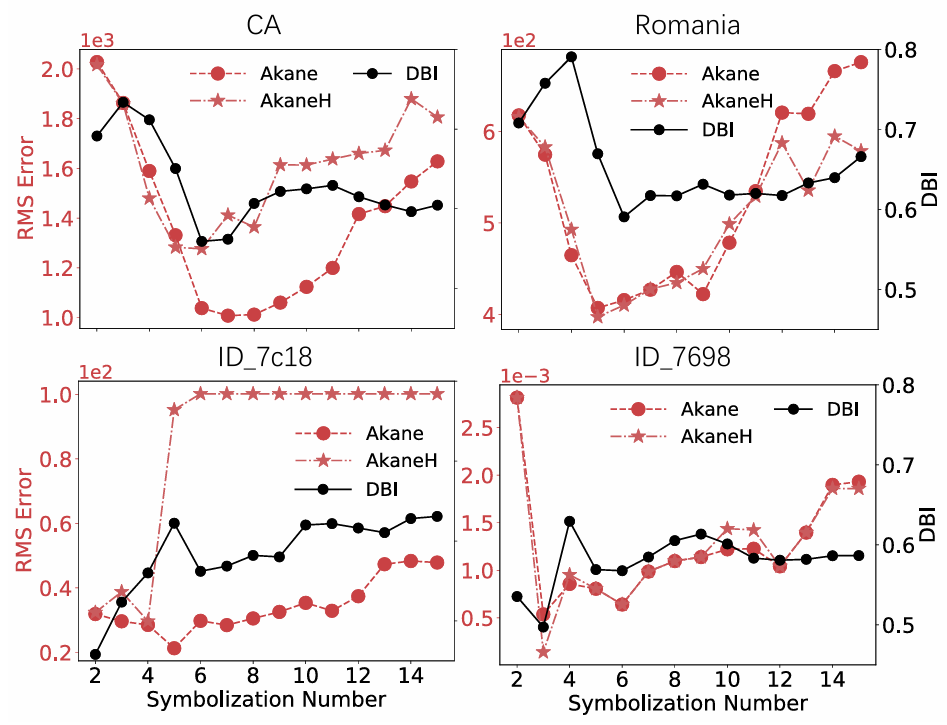
图5 符号数r值在四个数据集上的影响
图6展示了AkaneH+的性能如何随着变化的影响而变化。当设置为0时,表示没有模式聚集,算法通常表现出较差的清洗效果,从而证实了均匀符号化下的模式稀疏性。实验表明,在0.01 ~ 0.08的范围内,AkaneH+在所有4个数据集上的表现都很好,证实了由于归一化和均方运算,最优的预测结果受数据集的影响很小。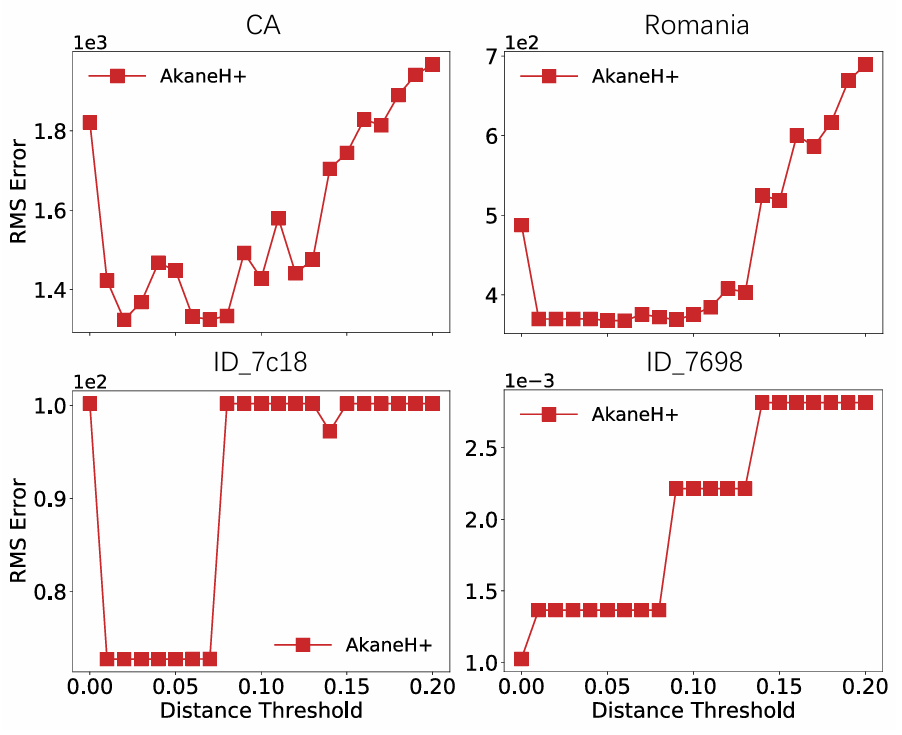
图6 距离阈值变化影响
表1展示了自动预算选择策略在2个变量和10个固定数据集上的准确性。表明了该策略的性能与数据集的属性、数据长度和脏率密切相关。且其在大多数情况下都表现良好,平均精度为0.915。即使在最坏的情况下,该策略也能达到0.811的精度,而且精度通常在0.9以上。
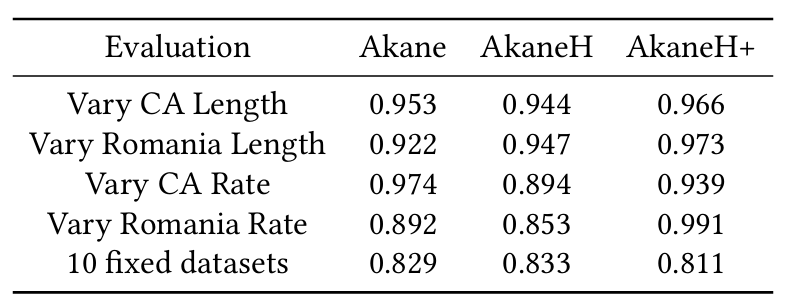
表1 自动预算选择策略的准确性
六、总结
本文解决了清理时间序列数据中的脏值的问题。通过将将困惑度引入时间序列数据清洗中,定义了一条时间序列的困惑度,并将清洗问题转化为在给定预算下最小化时间序列的困惑度这一最优化问题。设计了一个四阶段的算法框架来解决这个问题,包含时间序列符号化,概率计算,可能性最优化,以及时间序列重建。为了确保框架的可行性,对脏数据的影响进行了分析,并设计了自动预算选择策略。此外,通过引入了基于同态模式聚合的改进概率计算方法和基于贪心的启发式算法来增强算法的适用性和易用性。
王旭博 重庆大学计算机科学与技术(卓越)专业2022级本科生,重庆大学Start Lab成员。主要研究方向:时空数据压缩 | 
|
重庆大学时空实验室(Spatio-Temporal Art Lab,简称Start Lab),旨在发挥企业和高校的优势,深入探索时空数据收集、存储、管理、挖掘、可视化相关技术,并积极推进学术成果在产业界的落地!年度有3~5名研究生名额,欢迎计算机、GIS等相关专业的学生报考!
图文|王旭博
编辑|徐小龙
审核|李瑞远
审核|杨广超






