时间序列数据广泛应用于物联网(IoT)、云服务器监控、股市价格等领域,支持许多重要任务,如预测、趋势分析、实时监控和异常检测。时间序列数据的爆炸式增长对高效存储和查询处理提出了巨大挑战。本文带来的是发表在SIGMOD 2024上的文章《MOST: Model-Based
Compression with Outlier Storage for Time Series Data》,提出了一种高效的时间序列数据压缩算法。
一、背景
随着物联网(IoT)、云服务器监控、金融市场等领域的快速发展,时间序列数据的生成量呈现出爆炸式增长。根据IDC的一份报告,从2015年到2025年,新数据的生成量以大约26%的复合年增长率增长,其中约65%的数据是在终端设备(如IoT设备)生成的。如此庞大的数据量对高效的数据存储和查询处理提出了巨大的挑战。
现有的时间序列数据压缩技术通常存在两大类问题:一类技术仅在时间序列数据上显示出低到中等的压缩比;另一类技术虽然可以实现较高的压缩比,但在查询处理过程中会产生显著的解压缩开销。这些问题限制了时间序列数据库系统(TSDB)在高效存储和快速查询处理方面的应用。
为了解决上述问题,论文提出了一种新的压缩技术——MOST(基于模型的异常存储压缩,Model-based compression with Outlier
STorage)。MOST利用时间序列数据在一段时间内通常平滑变化的特性,将时间序列划分为多个平滑变化的段,然后为每个段计算线性模型。为了在分析任务中容忍微小的误差,MOST忽略那些预测误差在预设阈值范围内的数据点,从而有效地减少数据大小。同时,MOST显式存储那些超出误差阈值的异常值,确保数据的准确性。
此外,作者还设计了一种分段-异常双模查询引擎,能够在处理MOST压缩数据时尽可能整体计算段,以减少查询处理开销。文章还构建了原型系统MostDB,并在真实世界的数据集上进行了广泛的实验评估。实验结果表明,MOST在压缩比和查询处理性能方面均优于现有技术,展示了其在时间序列数据存储与查询中的应用潜力。
二、MOST压缩
模型驱动的压缩通过捕捉时间序列的特征来表示数据,这些数据在一段时间内通常变化平滑。在一个极端情况下,模型仅压缩不存储任何预测误差,这虽然能实现高压缩比,但牺牲了数据的准确性。另一极端情况下,模型基于压缩存储所有的预测误差,保留了良好的数据准确性,但压缩比不理想。提出的MOST(基于模型的异常存储压缩,Model-based compression with Outlier
STorage)算法通过仅存储稀有的异常值来平衡压缩比和数据准确性,即预测误差超出预设误差阈值的数据点。通过这种方式,MOST可以同时实现高压缩比和良好的数据准确性。
MOST压缩算法由三个步骤组成:1)异常检测,2)分段,3)模型和异常编码。需要注意的是,在分段之前进行异常检测非常重要。图1a展示了一个时间序列的分段和异常情况。在分段之前进行异常检测,可以防止平滑段被零散的异常点分割。
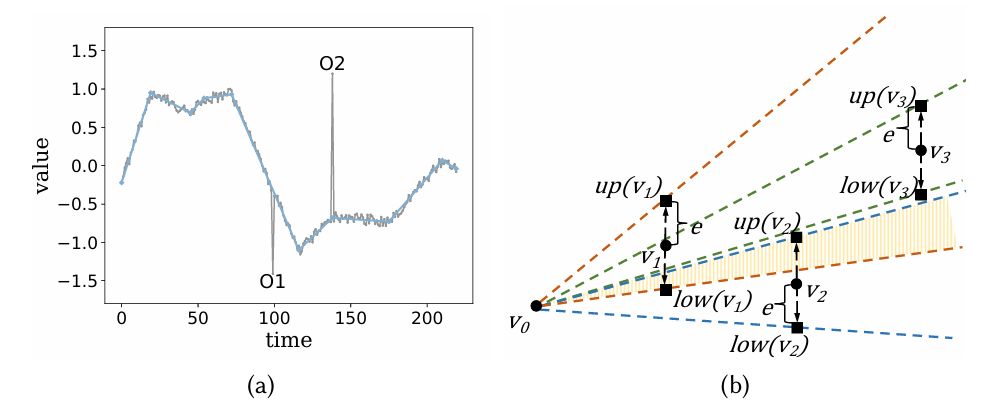
图1 (a)一个时间序列的分段和异常情况;(b)收缩锥的分割过程异常值。作者构造线性模型来压缩数据,如果预测值的误差超过误差界限的数据点称为异常点。作者总结了现有的异常值检测方法:(1)基于密度检测:在滑动窗口中检查每个点,计算其邻居(即值接近的点)的数量。如果某个点在任何窗口中都没有足够的邻居,则该点被视为异常值。(2)基于直方图的异常值检测:基于最优直方图(vopt),给定固定数量的桶。如果移除某个点能够减少直方图的估计误差,则该点被认为是异常。动态规划算法可以计算出最优的异常点集合。(3)基于模型的异常值检测:ML模型如LSTM和循环自编码器集合虽然精度高,但计算成本高,不适用于物联网场景下的快速数据摄取。收缩锥(Shrinking Cone)是一种源于可行空间窗口的方法,通过计算每个数据点的斜率范围来检测异常。当斜率范围变为空时,段的增长停止。如图1b所示,给定一个误差界𝑒,锥形的可行斜率范围随着点的增加而缩小。V0是该分段的起点。添加𝑉1后,可行的斜率范围为[𝑙𝑜𝑤(𝑉1),𝑢𝑝(𝑉1)]。添加𝑉2后,范围缩小到[𝑙𝑜𝑤(𝑉1),𝑢𝑝(𝑉2)]。如果添加了𝑉3,则∩3i=1[𝑙𝑜𝑤(𝑉𝑖),𝑢𝑝(𝑉𝑖)]=∅,则该范围变为空。因此,该段停止在𝑉2。
文章修改了收缩锥来检测异常值,由于一个异常值(例如,𝑂1)经常会形成一个非常短的段,因此文章在两种情况下将一个点标记为异常值: a)它停止一个段,但该点的移除会继续该段的增长;b)它开始一个包含小于min_seg_len(例如,5)点的短段。自上而下法(Top-down Method):递归地将时间序列划分为段,直到满足某个停止准则。这种方法适用于处理具有显著变化点的数据。自下而上法(Bottom-up Method):从短段开始,逐步合并相邻的短段直到满足某个停止准则。这种方法能够生成较为平滑的段,但需要多次遍历数据。极值点法(Extreme/Trend Point Method):这种方法在极值点或趋势点处分割序列,适合处理具有明显极值或趋势的数据。滑动窗口法(Sliding Window Method):通过增加数据点使段的增长直到其总误差超过用户定义的阈值。滑动窗口和自下而上法(SWAB)结合了滑动窗口和自下而上方法的思想,在滑动窗口中使用自下而上的方法对数据点进行分段,直到剩下5到6个段为止。然后,滑动窗口将第一个段弹出,并添加新数据点,再次执行自下而上计算。收缩锥法(Shrinking Cone Method):通过计算每个新点加入时的斜率范围来进行分段。当斜率范围变为空时,当前段停止增长,下一个点开始新的段。作者使用三个数据集对不同方案组合进行分析,结果如图2所示,其中SC+SC(收缩锥方法)是最佳的异常检测和分段策略。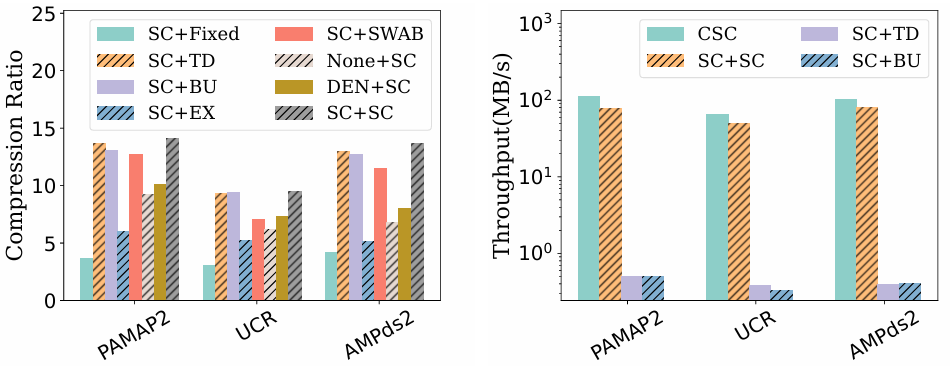
图2 不同组合的效果 (a)压缩率; (b)吞吐量
为了提高效率,文章提出了组合收缩锥算法(CSC),该算法将异常检测和分段结合在一起,进行一次性计算。算法步骤如下:如果斜率范围变为空,标记当前点为分割点并继续检查下一个点。如果下一个点成功扩展当前段,则记录分割点为异常并继续增长段。如果分割点继续分割段,则尝试开始新段,确保当前段的长度至少为最小段长度。
CSC算法的时间复杂度为𝑂(𝑛)。如图2b所示,CSC算法将SC+SC的压缩吞吐量提高1.27–1.40x倍。为了进一步减少存储空间,MOST算法在模型参数和异常值的编码方面进行了优化,包括量化和尾数截断。对离群值编码的量化。为了减少异常值的存储空间,文章采用量化的方法对异常值进行处理。将每个异常值𝑣与其所在的段关联,或者如果异常值位于两个段之间,则将其与前一个段关联。接着使用段的模型计算异常值的预测值𝑣𝑝。对异常值进行量化,量化结果𝑞和解压缩后的重建值𝑣′的计算如下: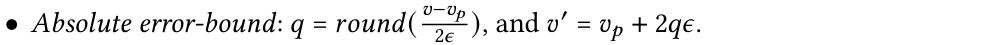
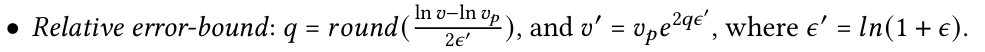
通过这种量化方法,可以确保异常值的存储满足误差界限约束,同时显著减少存储空间。量化后的 q 值使用Zigzag编码和变长整数编码进行存储。斜率编码的尾数截断。由于浮点数的长尾数会影响压缩算法(如Gorilla)的压缩比,MOST算法对斜率参数的尾数进行截断。首先使用BFLOAT16格式:BFLOAT16是一种在深度学习中广泛使用的浮点数格式,具有1位符号位、8位指数位和7位尾数位(而IEEE 754 32位浮点数格式有23位尾数位)之后采用尾数截断的方式进一步提高压缩率通过对尾数位进行操作获得截断后的斜率参数。在算法实现中,MOST确保截断后的当前斜率范围下限 truncated cur𝑙𝑜 >= cur𝑙o且truncated curhi <= curhi。错误界限保证。通过组合收缩锥算法,普通点保证落在段的收缩锥斜率范围内,因此满足误差界限。在量化过程中,通过对异常值的重建保证其满足误差界限。作者设计了MostDB,一个用于存储和处理MOST压缩时间序列数据的原型时间序列数据库(TSDB)。MostDB的设计包括存储引擎和查询处理引擎,MOST架构如图3所示,以下详细描述其组件和工作流程。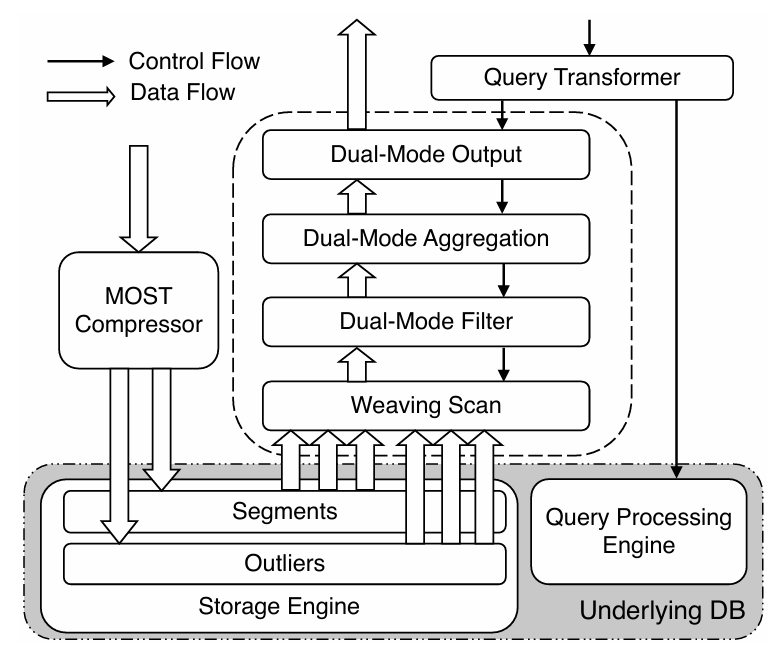
作者将大多数压缩数据存储在底层数据库中。时间序列表可以表示为:
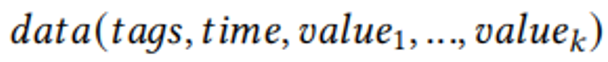
段表(Segment Table):存储段的模型参数文章要求底层数据库支持基于tags和时间范围的高效数据检索。具体而言,作者使用了InfluxDB作为底层数据库。由于InfluxDB不支持BFLOAT16格式,MOST将斜率列声明为32位浮点类型,并清除低16位尾数位。MOST利用InfluxDB默认的压缩方法(即Gorilla用于intercept和slope,Simple8b用于q)来压缩列。对于规则时间序列,不需要存储时间戳;对于不规则时间序列,MOST将时间戳作为测量值的一列进行存储,并使用自增ID作为规则时间戳。实际的时间戳列使用Delta-of-Delta编码进行压缩。MostDB的查询处理引擎支持常见的IoT查询类型,通过在底层数据库中检索数据并在查询操作符中处理段和异常,实现高效的查询处理。查询操作分析。根据IoTDB Benchmark,在物联网应用程序中有10种常见的查询类型,如表1所示。IoT应用中常见的查询类型包括:- 时间操作:查询数据在某个时间点(Q1, Q9)或时间范围(Q2, Q4-6, Q8, Q10)内的数据。MostDB在检索数据时,指定适当的时间条件。
- 标签操作:根据标签条件(Q1, Q2, Q4, Q5, Q9, Q10)检索数据或以标签为分组键(Q6-8)进行分组。MostDB在检索数据时指定标签条件。
- 值操作:包括选择子句中的值(Q1-5, Q9)、值的过滤(Q4, Q5, Q7, Q8)和值的聚合(Q6-8, Q10)。
- 限制子句:查询限制返回记录的数量(Q3, Q5)。MostDB在检索数据时指定限制子句。
为了支持这些操作,MostDB在底层数据库中检索数据,并通过查询处理引擎进行段和异常的双模处理。查询操作符具有段模式和异常模式,通过双模式扫描、过滤、聚合和输出操作符来实现高效的查询处理。
双模查询引擎的设计:MostDB提出了一种双模查询引擎,用于处理MOST压缩数据的关系查询。双模指的是主要的查询操作符有两种模式:段模式(segment mode)和异常模式(outlier mode)。段模式处理整个段的数据,而异常模式逐个处理异常记录。引擎采用了火山模型的查询执行方式,主要区别在于双模操作符的next()函数返回的是一个段和与该段关联的一组异常列表。结果样式。MostDB提供了几种生成查询结果的样式:默认样式:查询引擎基于模型预测的值计算结果。这种样式具有最佳的查询性能,但预测值不一定是原始测量值。Style-EB:生成期望值和聚合结果的确定性边界。Style-EBS:计算标准差以及Style-EB的输出。这些样式主要用于评估聚合操作,帮助处理不确定性因素,提高查询结果的准确性。双模编织扫描操作符是MostDB查询处理引擎中的一个关键组件,用于从段表和异常表中检索数据。它有两种工作模式:段模式和异常模式。如图4所示:
在段模式下,扫描操作符处理每个段的线性模型。操作符将整个段作为一个整体进行处理。例如,在过滤操作中,段模式可以根据段的线性模型快速决定是否接受或拒绝整个段,或者接受段的一部分。在异常模式下,扫描操作符逐个处理异常记录,类似于传统的关系数据库操作符。这种模式逐个读取和处理异常值,以确保所有数据点,包括异常点,都能被准确处理和查询。对于每个段,在评估过滤谓词时考虑三种情况。图 5 展示了一个示例,其中过滤条件为 value > const。在情况 (a) 中,段完全满足过滤条件,则将结果设置为真。在情况 (b) 中,段完全不满足过滤条件,则将结果设置为假。在情况 (c) 中,段部分满足过滤条件,因此将段划分为最多三个较小的段,如图 5(c) 所示。MOST相应地设置真和假的部分结果。对于未知部分,则需要考虑每个点。这里简单地将未知部分的所有点插入异常值列表,并与其他异常值一起处理。未知段变为空段,其结果设置为假。对于每个异常值,生成一个概率 p 用于过滤评估。首先根据预测值和误差边界约束计算 [valuelo, valuehi]。然后将值范围与过滤谓词进行比较,也有三种情况。首先,整个范围满足过滤条件,将p设置为1。其次,整个范围不满足过滤条件,则将p设置为0。第三,范围与过滤条件相交,根据均匀分布计算 p。对于示例过滤条件 value > const,如果 const 在[valuelo, valuehi]范围内,则p= (valuehi - const) (valuehi- valuelo)。逻辑操作(即 AND, OR, NOT)的过滤谓词可以轻松支持。请回忆,所有值列的段在编织扫描时已对齐。如果在任何过滤评估中发生情况 (c),则意味着可以进一步将段划分为更小的段。在给定段上评估单个过滤器后得到真/假结果。因此,对于一个段来说,计算 AND/OR/NOT 过滤谓词是很容易的。对于异常值,MOST假设不同列上的过滤结果是独立的。假设两个过滤谓词的概率分别为 p(pred1) = p1和p(pred2) = p2。则 p(pred1 ANDpred2) = p1 * p2,p(pred1 OR pred2) = 1 - (1 - p1)(1 - p2),p(NOT pred1) = 1-p1。过滤操作符通常输出所有输入段和异常值,并增强每个段的真/假结果和每个异常值的概率。只有当段的结果为假,并且它没有任何异常值或所有相关异常值的概率为 0 时,段才可以安全地丢弃。只有当异常值的概率为0并且其关联段的结果为假时,异常值才可以丢弃。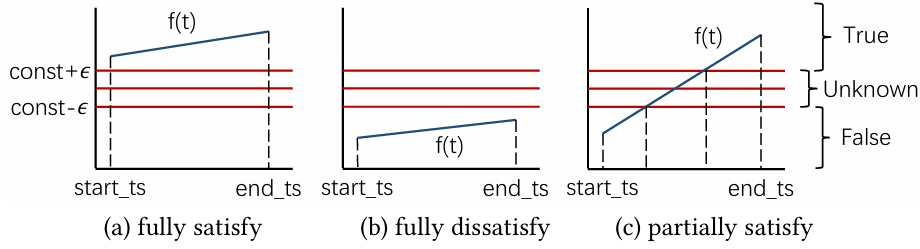
图5 一个段上评估过滤条件(value > const)聚合操作符在每次child.next()调用中获取一个段及其关联的异常值。返回的段具有真/假结果,每个异常值具有概率。如果子操作符是编织扫描(即没有值过滤器),则段结果默认为真,异常值概率为1。作者在文章中给出了如何在每次child.next()后逐步计算聚合。双模式输出操作符支持查询中 select 子句的测量值。在每次child.next()
调用中,它获取一个段及其关联的异常值。对于每个点j,它从段模型中计算重建值 f(j),除非它是一个异常值。对于异常值u,它计算重建值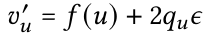 。输出操作符返回一组元组作为查询结果。通过这种方式将模型和异常值的细节隐藏起来,不向用户暴露。
。输出操作符返回一组元组作为查询结果。通过这种方式将模型和异常值的细节隐藏起来,不向用户暴露。
四、实验
4.1 实验设置
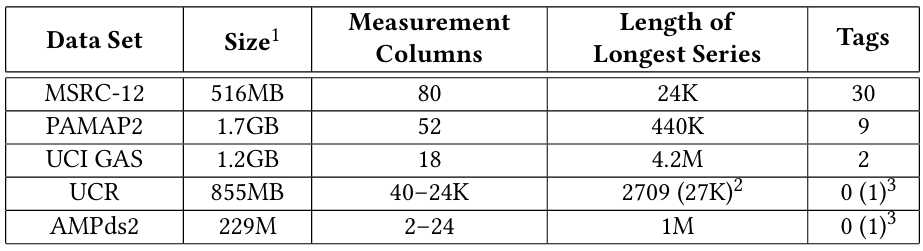
数据集:见表2
表2 实验数据集
对比方法:MOST 与最先进的压缩技术进行比较,具体包括通用方法(如 Snappy、LZ4、Gzip)、记录导向方法(如 BUFF、SplitDouble、Gorilla、RLE、TS-2DIFF)、模型导向方法(如 sprintzFIRE+Huff、SZ3)以及最先进的时间序列数据库(如 InfluxDB、IoTDB、ModelarDB)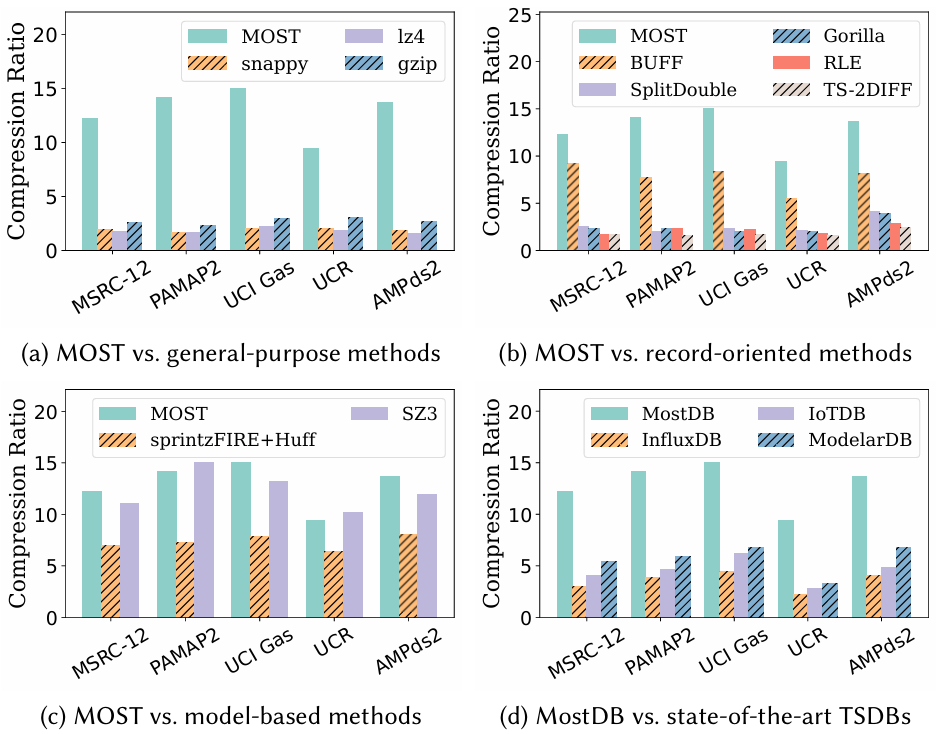
压缩率对比:图 6 显示了 MOST 与最先进的压缩技术的压缩率对比。压缩率计算为压缩前的大小除以压缩后的大小,因此值越高越好。图6(a)和6(b)显示,MOST 相较于通用和记录导向的无损压缩方法,取得了3.13到9.03倍的改善。相较于 BUFF,MOST 的压缩率提升了1.32到1.83倍。图6(c)显示,MOST 与最先进的基于模型的压缩技术(如 sprintzFIRE+Huff 和 SZ3)的比较结果。MOST 相较于 sprintzFIRE+Huff 的压缩率提升了1.48到1.94倍与最先进的时间序列数据库的比较:图6(d)显示了MostDB与InfluxDB、IoTDB和ModelarDB的比较结果。MostDB相较于InfluxDB、IoTDB和ModelarDB分别实现了2.36到4.24倍、2.42到3.37倍和2.02到2.84倍的压缩率提升。这表明 MOST 能够有效地提高时间序列数据库的压缩率。过滤查询性能:作者比较了 MostDB、SZ3 和 BUFF 的查询性能。由于没有时间序列数据库支持SZ3,文章在内存中完全运行查询。图7(a)显示了过滤查询的性能(TQ2),图 13b 报告了聚合查询的性能(不带 group by 的 TQ3)。从图中可以看出,MOST 的查询性能显著优于 SZ3,这是因为 SZ3 在计算之前需要解压缩数据块。BUFF 通过 SIMD 实现了良好的过滤查询性能,但在处理满足值谓词的分散记录子集的聚合时效率较低。相比之下,MostDB 的双模式处理能够以低成本处理数据段,从而实现更好的性能。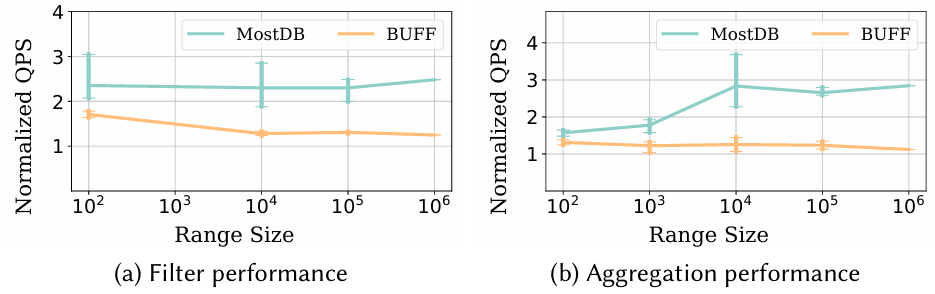
图7 比较MostDB、SZ3和BUFF的查询性能本文提出了MOST(基于模型的压缩与异常值存储),这是一种新的时间序列数据压缩技术。MOST通过利用线性模型来表示大部分平滑变化的数据,并仅存储那些超出预设误差阈值的异常值,从而在保持数据准确性的同时,实现了显著的高压缩比。基于MOST的压缩技术,本文还设计了一个名为MostDB的时间序列数据库原型。MostDB采用双模式查询引擎,结合段模式和异常值模式进行查询处理,能够在不解压数据的情况下高效执行查询操作,大大提高了查询效率。实验结果显示,MOST在多个实际数据集上实现了9.45到15.04倍的压缩比,并且MostDB在常见的物联网查询基准测试中,查询速度最高提升了11.68倍。相较于现有的压缩技术和时间序列数据库,MOST和MostDB在压缩率、插入性能和查询性能方面均表现优异,为处理和存储大规模时间序列数据提供了一个有效且高效的解决方案,特别适用于物联网等需要处理大量时间序列数据的应用场景。| 重庆大学计算机科学与技术专业2023级在读博士研究生,重庆大学Start Lab团队成员。 | 
|
重庆大学时空实验室(Spatio-Temporal Art Lab,简称Start Lab),旨在发挥企业和高校的优势,深入探索时空数据收集、存储、管理、挖掘、可视化相关技术,并积极推进学术成果在产业界的落地!年度有3~5名研究生名额,欢迎计算机、GIS等相关专业的学生报考!
图文|李政
编辑|徐小龙
审核|李瑞远
审核|杨广超






