数据流处理系统通常通过滑动窗口来对流数据进行管理。对于流窗口而言,高效的索引结构是使滑动窗口能够支持如聚合和连接等操作的关键部分。然而,现有的学习索引大多依赖于树结构,内存开销较大。那么如何在降低内存占用的同时保证高效的查询效率以及动态调整以适应数据流的变化呢?本次为大家带来数据库领域顶级会议SIGMOD的论文:《SWIX: A Memory-efficient Sliding
Window Learned Index》。
一.引言
随着大规模在线服务的持续增长,数据流处理变得越来越重要。在流处理环境中,系统面临着巨大的数据量和高速的数据到达速度来的挑战。因此,大规模流处理系统需要高效的数据结构和算法来实时处理数据并做出及时决策。
流处理系统通过滑动窗口管理有限数量的最新数据。这就像一个队列,当新记录到达时捕获它们,并移除较旧的记录以避免内存溢出。例如,网络流量监控系统可以使用滑动窗口来跟踪最近的流量数据,以进行实时监控和分析。流处理系统需要能够高效地搜索滑动窗口中的记录,例如通过IP地址或数据包ID进行搜索。
管理滑动窗口是一个挑战,因为这要求系统能够处理频繁的更新和支持高效的查询。在非流式系统中,记录的插入、删除和搜索通常基于主键进行。然而,在基于滑动窗口的流处理系统中,数据基于时间戳到达和过期,并使用主键(通常是唯一标识符,如记录ID)进行搜索。因此,流式数据结构必须能够处理基于时间戳的频繁更新,并能快速地基于主键进行搜索。
现有工作已经提出了许多用于窗口处理的索引。他们的设计使用了为查询和更新性能而优化的多个数据结构。这些设计的缺点是由于存储多个数据结构,需要大量的内存开销,比如同时使用一个大的和一个小的B树来处理滑动窗口。另一种方法是使用学习索引,它利用数据分布中的模式来预测记录的位置。虽然一些学习索引支持更新并拥有比传统索引的更快的速度,但与传统索引相比,它们没有达到相同的紧凑水平。并且,这些现有的学习索引不能处理流更新,其中更新基于非索引的时间维度(在不存储额外的结构前提下)。FLIRT是唯一的流学习索引,但它仅支持基于时间维度的更新和查询,这就要求主键必须按时间顺序排序。
因此,论文开发了一种新的内存高效的可更新学习索引SWIX。其主要设计目标是创建比传统或学习索引更紧凑的数据结构,同时提供与现有方法类似或更好的查询性能。为了实现这一点,SWIX的设计基于两层数据结构,与基于树的结构相比,该结构降低了索引的高度,从而减少了索引中的冗余。同时,该结构支持并行化以提高性能。为了高效地处理更新,SWIX根据数据分布动态地调整结构,以实现快速查询性能,同时最小化内存开销。此外,SIWX在查询和更新索引时隐式地从索引中删除旧数据,以确保紧凑性。
图 1(a)展示了IBWP中的一个滑动窗口以及各种操作。系统从流中接收数据,并将最近的记录保留在滑动窗口中。由于内存限制,IBWP系统仅保存最新的W个时间单位内的最新数据,其中,W称为窗口帧(也有基于数据量的定义,本文主要介绍基于时间单位的)。滑动窗口是一个队列,其中新数据将进行入队操作,旧数据将被退出队列并删除。IBWP系统还支持使用主键在窗口中查找记录。现有的FLIRT要求主键必须是按时间排序的。相比之下,SWIX的目标是处理一个通用的IBWP工作负载,其中插入和删除发生在索引内的任何地方(其中索引是按主键排序的,而不是按时间排序的)。现有的索引IBWP工作负载的方法要么内存占用很高,要么没有很高的更新/查询效率。由于数据分布是未知的,当前的流式索引不会利用其来减少索引的大小。同样,那些利用数据分布来减少索引大小的学习索引,在支持IBWP工作负载中频繁执行的更新操作(如入队和出队)时效率不高。同时,为了支持更新,现有的可更新学习索引在设计中包含许多冗余以保证查询效率。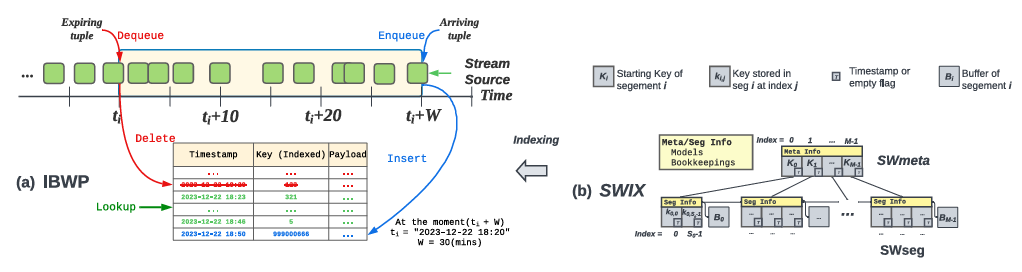
图 1 IBWP以及SWIX结构
2.2 延迟和内存之间的取舍
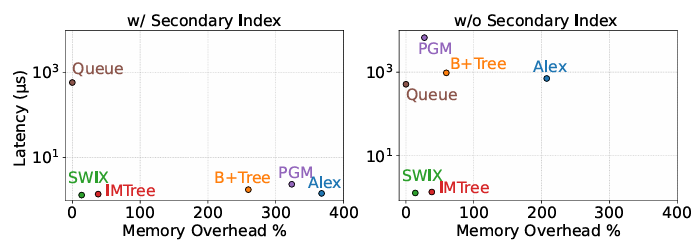
图 2展示了现有方法和SWIX的延迟和内存开销之间的取舍。可以看出:1)不是为数据流设计的索引,如B+树和学习索引(如PGM 和ALEX),需要一个二级索引来实现IBWP工作负载的低延迟。辅助索引提供了一个时间戳到键的映射,以标识要从主索引中删除哪些键。在没有辅助索引的情况下,这些索引在查找过期记录时具有很高的延迟(图2右)。然而,使用辅助索引会导致大量的内存开销,其大小约为数据量的3×(图2左)。因此,传统的和学习索引对于流式工作负载是不够的,因为它们在内存消耗或查询执行时间方面都表现不佳。2)队列是按时间排序的,因此,按主键进行搜索需要对所有记录进行线性搜索,因为主键是未排序的。在这方面,SWIX旨在提供内存消耗和速度之间的平衡。IMTree是SWIX的主要竞争对手。然而,IMTree是基于B+树的,这导致了比SWIX更高的内存开销。
SWIX是一个同时具有空间和时间优势的学习索引,可用于更新繁重的流工作负载。SWIX利用了几个关键的技术,包括两层结构、分段线性学习模型、用于优化搜索和更新性能的可扩展机制、用于适应不断变化的分布的在线自动调优器和用于可伸缩性的并行框架。SWIX的结构如图 1(b)所示,它使用了SWarray,一个结合了用于高效查询的线性预测模型以及轻量的支持快速更新的动态扩容/收缩机制。SWarray使用连续的内存布局来确保数据邻近性和查询性能。此外,SWarray隐式地丢弃过期的数据,而不需要使用辅助索引。SWarray包含以下两个部分:SWseg是SWarray的底层结构,由于SWseg会经常更新,需要扩展SWarray以生成插入的间隙。间隙的数量取决于当前的数据分布,并由自动调优器控制。SWarray使用现有的训练模型,根据模型预测空白空间的位置来分配间隙。对于相邻的键,其预测后的位置依然邻近。因此,在相邻键之间插入其他键的可能性更低,从而导致更少的间隙。相反,如果两个键彼此距离更远,在它俩之间插入键的可能性会高得多。作者认为,当分布发生变化时,预测间隙的位置是很困难的。SWIX没有增加间隙的数量(这增加了空间开销),而是选择减少间隙的数量,并使用高速缓存器作为“通用”间隙来吸收密集区域的更新。SWarray使用一个固定长度的简单排序数组来实现缓存。SWIX通过限制缓存大小以及从缓存删除过期数据以降低内存占用。相邻的SWSeg通过指针连接在一起,以提高范围扫描性能。SWmeta是SWarray的上层结构,其主要任务是管理SWsegs。它存储了每个SWseg的起始键。SWmeta中的更新并不常见,仅在对一个或多个SWseg进行再训练时发生。因此,SWmeta的主要目标是确保紧凑性的同时保持良好的查询性能(定位相应的SWsegs)。SWIX的查询包含如下两个过程:1)预测位置,2)错误修正。此过程首先在SWmeta中执行,以识别可能存储键的SWseg,然后继续在SWseg中执行相同的过程。如果在SWseg的SWarray中没有找到键,则利用二分搜索查询缓存。图 3给出了一个示例。SWIX采用限定搜索范围来进行错误修正以保证最差情况下的性能,因为插入优先放置在其预测位置附近。同时,在搜索过程中,SWIX会删除无效数据,如图 3中的63。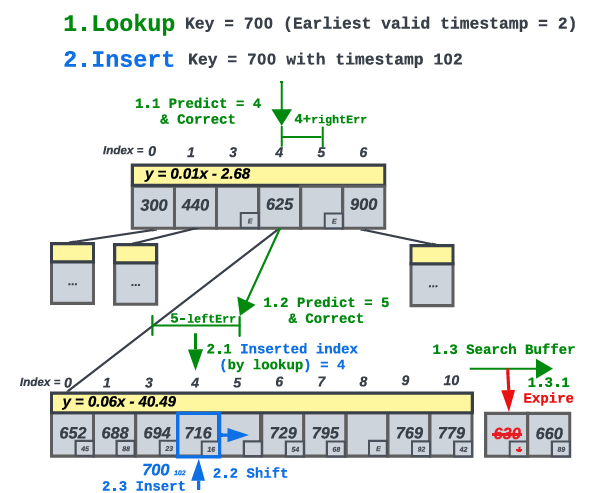
更新由数据的入队/出队操作引起,主要导致SWseg的变化。SWIX根据数据分布动态地改变SWseg的大小和间隙数。为了减少更新过程中数据移位产生的预测误差,SWIX利用缓存来降低由于数据分布变化引起的误差。插入:要插入数据,需要首先通过查询操作找到数据应该插入的地方。该过程如图 3中的蓝色线条所示,图4展示了SWIX中的不同插入策略。如果找到的位置是一个间隙,直接插入即可(图4a)。否则,通过将相邻的键移到最近的间隙位置来插入键,以使键尽可能接近预测位置(图4b)。SWIX将转移的次数限制在SWseg大小的30%(该大小是独立的),以防止精度下降。一旦超过了这个限制,数据就会被插入到缓存中(图4c)。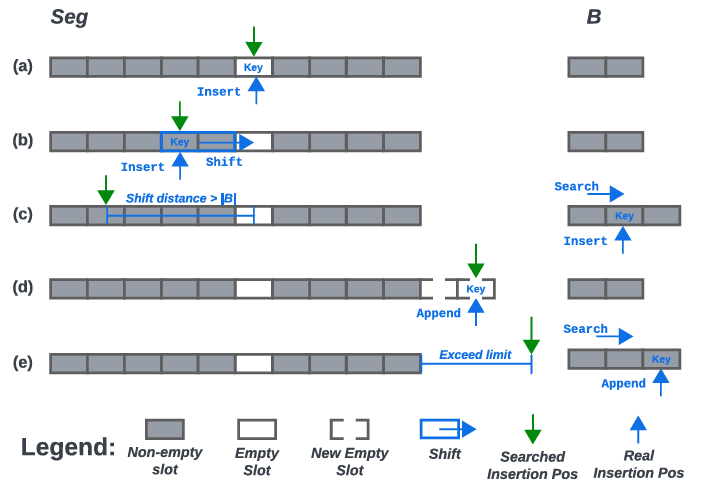
删除:在搜索、查询和插入期间,将隐式地删除无效的数据。SWIX使用一个时间戳阈值来确定数据是否已过期。在删除时,SWIX首先触发一次查询操作,之后将找到的数据从SWarray或从缓存中删除。如果一个SWseg过期,则从SWmeta中删去它。对于学习索引而言,再训练的目的是纠正由于分布变化而引起的预测误差。SWIX通过改变SWseg的大小来适应数据分布。当分布均匀时,SWarray中的数据会更密集,当分布变成非线性时,SWarray中的数据会更稀疏。如图 5所示,SWIX使用自下而上的方法进行再训练,相邻段一起再训练以降低每个段的平均误差。为保持一致性,SWseg再训练完成后需要对SWmeta进行再训练,这包括删除旧的SWseg和插入新的SWseg。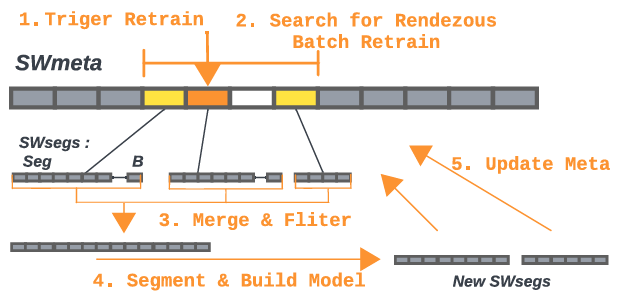
成本模型:SWIX从执行时间的角度设计成本模型,主要包括以下三方面:查询(CS),更新(CI)以及再训练(CR)。三者的计算公式如下: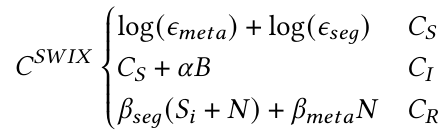
其中,查询成本结合了两个组成部分:查询SWmeta和查询相关的SWseg。论文假设这两个成本与预测错误率相关,于是用错误率来简单估计查询成本。更新成本除了包含查询成本外(找到要插入的位置),还包含没有间隙来放置数据时需要的最大移位距离。由于缓存会容纳需要移位距离过大的数据以降低预测错误率,假设缓存的长度为B,需要进入缓存的数据的比例为α,故插入成本为查询成本与插入缓存的成本之和。再训练成本包括SWseg和SWmeta再训练的成本。在SWseg再训练后,新形成的SWseg数据为S,SWseg再训练后需要更新SWmeta,N是最差情况下SWmeta需要更新的次数,βseg和βmeta分别是SWseg和SWmeta触发再训练的概率。论文发现,上述的参数均受tol(每个SWseg的可容忍误差,其控制每个SWseg中间隙的大小和数量)影响,因此,SWIX通过一个启发式的模型来使用tol来估计总成本,并通过执行时间进行调优。实验平台:CPU:Intel E5-2690@2.60GHz;内存:64GB;编程语言:C++;操作系统:Ubuntu
14.04。数据集:四个合成数据集以及来自SOSD的四个真实数据集。对比方案:一级索引(用于索引主键):B+Tree,Dynamic PGM-Index,ALEX以及FLIRT。二级索引:包括B+Tree,PGM-Index,ALEX,XIndex以及FINEdex以处理IBWP工作负载。评价指标:内存占用(MB),同时包含数据和索引大小;查询时间:延迟(us)以及吞吐量(ops/s)。图6展示了SWIX与不同基线的比较结果。图中,每个数据集上最快的索引用深绿色表示,而内存开销最低的索引用浅绿色表示。可以观察到:SWIX通常具有最低的内存开销,除了osm(所有学习索引都表现不佳)。一般来说,树的结构是内存密集型的,然而,IMTree通过限制树的高度达到了很低的内存占用率。相对于普通的树结构,学习模型往往具有较低的内存占用(比如ALEX),然而,如PGM的效果所示,使用许多子索引来降低树的高度会使得内存占用非常高。SWIX在没有多个子索引的情况下将树高截断为2,并利用学习到的模型来压缩顶层,从而大大减少了内存的使用。然而,学习模型压缩数据的能力取决于数据分布,因此在不同数据集上开销波动较大。在查询延迟上,学习模型在真实数据集上的表现不佳,比如osm和fb,因为它们的分布难以预测。ALEX使用一个成本模型来确定何时分割一个节点,然而,这对于内部节点是内存不友好的,因为它在不改变子节点数量的情况下增加了指针的数量。节点还被允许向下分裂,从而产生更多的内部节点,这增加了树的高度。相比之下,SWIX只有一个内部节点(SWmeta),并且最多只允许20%的SWmeta间隙(在再训练时压缩到5%)。此外,ALEX将一个完整的数据节点分成两半,这忽略了段中的分布,可能导致数据碎片化。SWIX选择将这些段一起重新训练,以避免数据碎片化并通过合并段以保证SWmeta节点的内存占用。因此,SWIX在真实数据和合成数据中具有最低的内存开销和非常有竞争力的查询性能。结果还表明,两层结构不会影响学习模型的速度。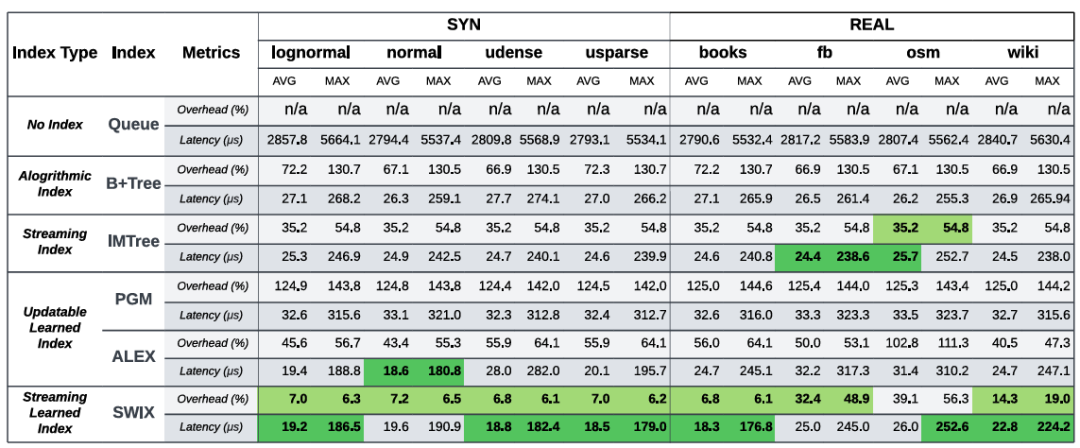
在图7a中,论文将时间窗口长度从100K变到100M(相当于改变数据大小),可以看出,SWIX达到了最低的内存占用,因为它位于图的左下角。并且,对于较大的窗口长度,SWIX的优势比其他学习索引更明显。对比方案不能随着数据大小的增加而很好地扩展。B+Tree、IMTree和PGM-Index不依赖于数据分布,而ALEX的性能受限于难以学习到的分布。对于osm,当窗口长度为100M时,ALEX生成657个内部节点,相比之下,B+树只有232个内部节点。论文还测试了在不同查询范围(10-10000)下各个方案的表现。可以看出,SWIX仍然是内存占用最低的。对于学习索引PGM-Index和ALEX,尽管它们内存不友好,但它们的查询性能是比较强的,这表明它们的设计倾向于查询速度。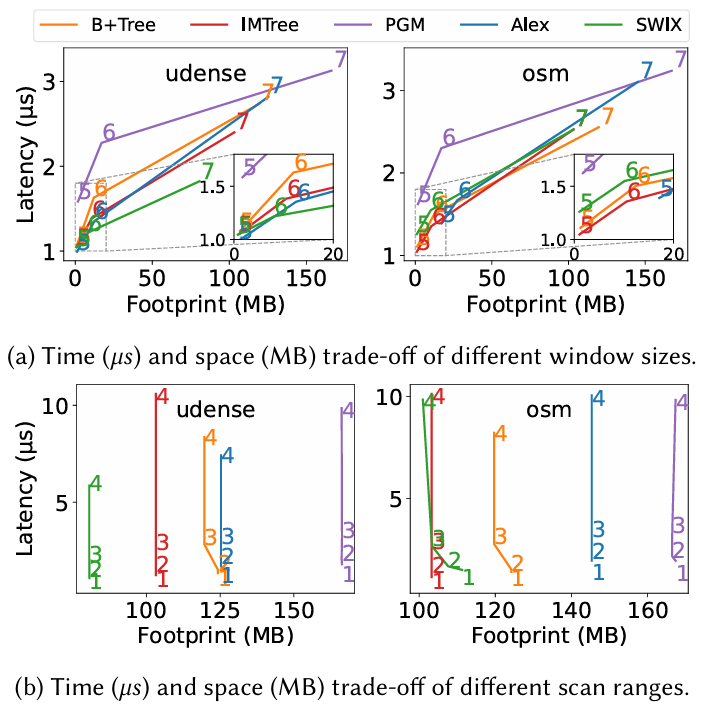
图8a展示了SWIX在不同读写比(RW比)下的查询性能。图中从左到右分别为1:10的重更新工作负载,1:1的平衡工作负载,以及10:1的重查询工作负载。其中,更新总量是一定的(400M)。因此,重查询工作负载将比平衡情况多10×的操作。可以看出,SWIX在整个工作负载中实现了平均最佳时间和内存性能,特别是在重查询工作负载下。其中,查询性能由学习模型保证,更新性能由动态SWarray保证。尽管SWIX是可更新的,但对于更新繁重的工作负载,它没有超过IMTree,因为树的设计没有再训练,插入非常方便。然而,IMTree的查询时间较慢,因为IMTree在此过程中需要搜索两棵树。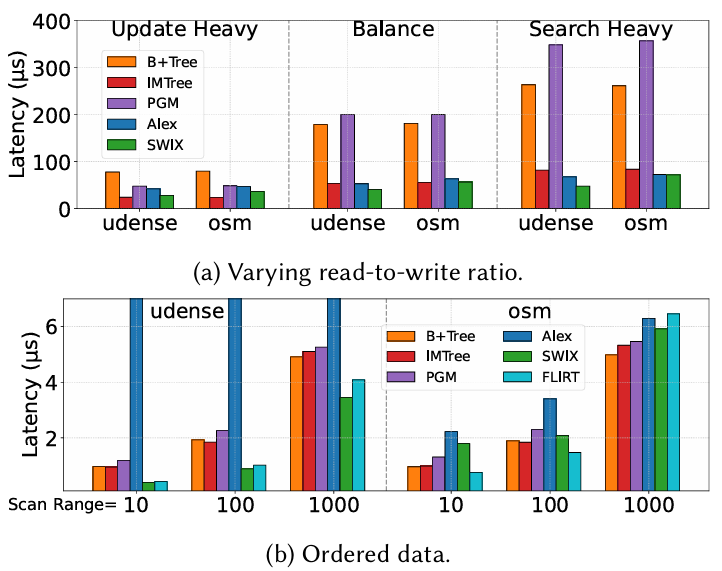
本文介绍了SWIX,一个内存友好的针对数据流的学习索引。SWIX是一个动态的、轻量级的、可并行化的学习索引,它建立在一个扁平的结构之上(一层SWmeta+一层SWseg),为数据流管理提供了一个有效的解决方案。实验结果表明,与现有的流索引和可更新的学习索引相比,SWIX在保证不同数据集和工作负载之间的查询性能的同时,实现了极高的内存节省。尽管SWIX被专门设计为IBWP工作负载,但它也可以用作通用的、内存友好的索引。[1] Andreas Kipf, Ryan Marcus, Alexander van
Renen, Mihail Stoian, Alfons Kemper, Tim Kraska, and Thomas Neumann. 2019.
SOSD: A Benchmark for Learned Indexes. NeurIPS Workshop on Machine Learning for
Systems (2019). | 重庆大学计算机科学与技术专业在读硕士二年级学生,重庆大学Start Lab团队成员。 | 
|
重庆大学时空实验室(Spatio-Temporal Art Lab,简称Start Lab),旨在发挥企业和高校的优势,深入探索时空数据收集、存储、管理、挖掘、可视化相关技术,并积极推进学术成果在产业界的落地!年度有3~5名研究生名额,欢迎计算机、GIS等相关专业的学生报考!
图文|何翔
编辑|徐小龙
审核|李瑞远
审核|杨广超






