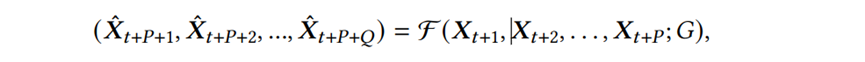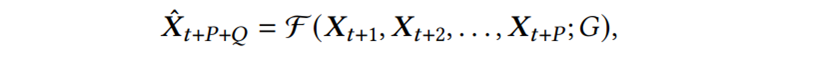物联网系统中的传感器能够捕获互连的过程,从而发出相关时间序列(CTS),其预测可实现重要的应用。CTS预测成功的关键是揭示时间序列的时间依赖性以及时间序列之间的空间相关性,基于深度学习的解决方案在这一方面表现出优越的性能,然而现有的自动化CTS解决方案仍处于起步阶段,只能为预定义的超参数找到最佳架构,并且很难扩展到大规模 CTS。本次为大家带来数据库领域顶级会议SIGMOD 2023的文章《AutoCTS+: Joint Neural Architecture and
Hyperparameter Search for Correlated Time Series Forecasting》。包括交通系统、电网系统和污水处理系统在内的许多系统都包含物联网组件,这些组件内部的传感器都会发出时间序列,从而产生通常相互关联的多个时间序列,从相关时间序列预测未来值通常具有重要的应用,例如通过准确预测交通流量可以预测道路拥堵和出行时间,从而实现更有效的车辆路线选择。成功的相关时间序列预测的关键是能够捕获每个时间序列的历史值之间的时间依赖性以及不同时间序列之间的空间相关性,利用深度学习模型强大的特征提取功能,人们提出了不同的神经架构(称为ST块)来捕获时空依赖性,以实现准确的预测。传统意义上,人类专家设计ST块并手动选择相应的的超参数设置,然而这是一项资源密集型工作,人类的专业知识并不适合。最近出现的一种方法是自动设计有效的ST块,图1(a)表示一个典型的自动化框架:图1 现有基于超网的框架与AutoCTS+框架(超参数𝐶表示ST块中节点数量,𝐻是潜在表示的大小。不同颜色的边代表不同的算子)尽管现有的自动化CTS预测方法实现了设计的自动化并且具有优于手动设计的模型性能,但它们仍然存在三个主要问题:缺乏对架构和超参数联合搜索的支持:在训练超网时,现有的自动化CTS预测方法依赖于预定义的超参数,对于不同超参数设置,相同的架构可能会产生明显不同的性能,而现有的解决方案依赖专家来选择适当的超参数设置,这很可能导致选择次优的架构,并使框架呈现半自动化。可扩展性差:现有的自动化CTS预测方法通常可扩展性较差,整个超网在训练期间必须全部加载到内存中,可能会导致内存溢出,并且组成超网的神经算子的内存成本随着时间序列𝑁 的数量和时间序列中历史时间戳𝑃 的数量而快速增加,限制了神经架构搜索的可扩展性。不可重复利用:现有的自动化CTS预测方法需要从头开始为每个特定数据集训练一个超网,成本高昂。不同CTS预测数据集之间可能存在相似性,重复利用之前在相关数据集上搜索中学到的知识可能会显着提高训练效率。针对上述三个问题,论文提出AutoCTS+框架,其核心是可扩展且高效的联合架构-超参数搜索策略。具体来说,论文做出以下贡献:(1)提出了一种用于相关时间序列预测的联合搜索空间,以进行架构和超参数设置的联合搜索。(2)提出了一种内存高效的架构-超参数比较器(AHC)来对所有候选arch-hyper进行排序,并使用代理度量提高搜索效率。(3)提出了一种能够将训练好的AHC转移到新数据集的方法,从而显著地提高新数据集上的AHC训练效率。对六个基准数据集的大量实验表明,与最先进的手动和自动方法相比,AutoCTS+能够有效地找到性能更好的CTS预测模型。相关时间序列预测:考虑多步和单步相关时间序列预测,给定X的过去𝑃时间步数内的特征向量,多步CTS预测的目标是预测未来𝑄 时间步数内的特征向量,其中𝑄 > 1,单步CTS预测的目标是预测第𝑄 个未来时间步的向量,其中𝑄 ≥ 1。因此将多步CTS预测定义如下:其中𝑿𝑡 表示时间戳𝑡 处所有时间序列的特征向量,𝑿ˆ 表示预测的特征向量,F表示CTS预测模型。问题定义:目标是从预定义的组合架构-超参数搜索空间S中自动构建最佳ST块F∗,从而最大限度地减少验证数据集 D𝑣𝑎𝑙 上的预测误差。在数学上目标函数可以表示为以下等式:

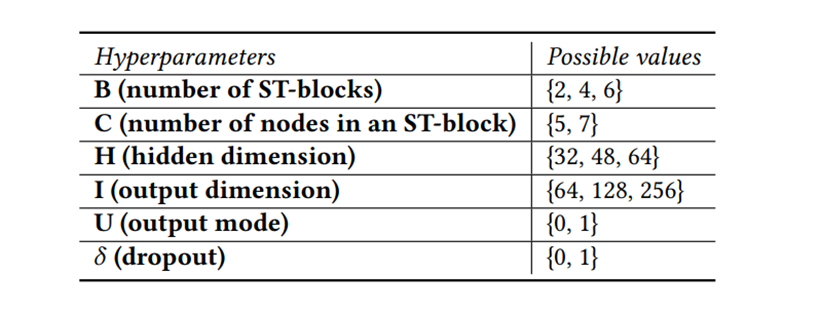
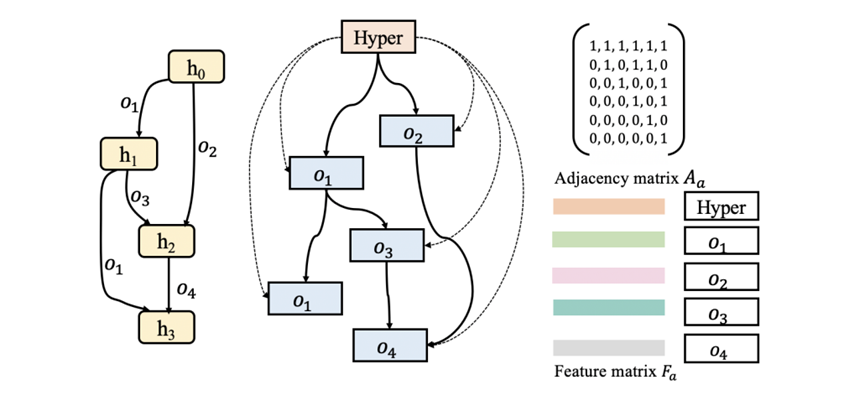
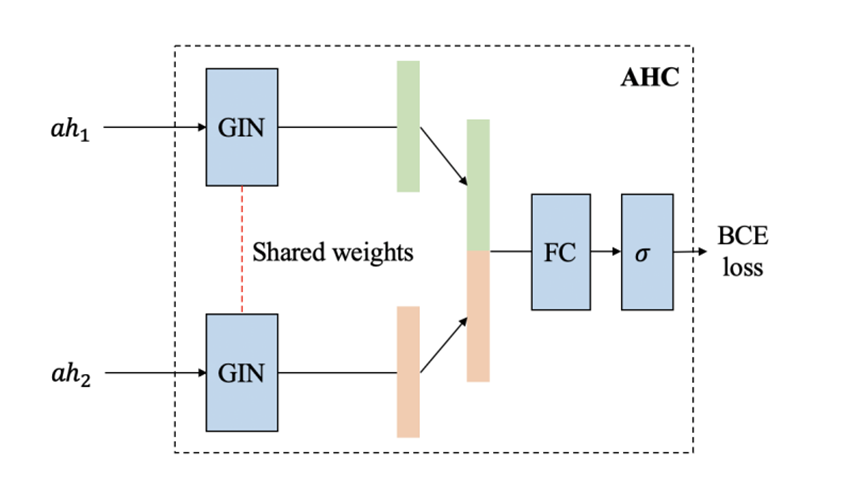
如图 2 所示,手动设计的神经CTS预测模型的通用框架包含三个组件:输入模块、ST骨架和输出模块。输入和输出模块通常由一个或两个全连接层组成,分别对输入时间序列进行编码,并将提取的时空特征解码为预测值。ST骨架是CTS预测模型的核心组件,它由多个ST块组成,可以使用不同的拓扑结构进行连接。ST块捕获时间序列之间的空间相关性和各个时间序列的时间依赖性,因此ST块中有两类算子,S算子(例如GCN)和T算子(例如Transformer),分别用于提取空间和时间特征。神经CTS预测模型的自动化框架设计中,通常首先设计一个包含各种 ST 块架构的搜索空间,搜索空间由有向无环图(DAG)表示(图 1(a) 左),称为超网,具有𝐶个节点和许多边,每个节点ℎ𝑖 表示一个潜在表示。每个节点对 (ℎ𝑖, ℎ𝑗) 间都有 |O| 条有向边,对应于 |O| 个候选S/T算子。自动化框架的目标是选择最小化验证错误的算子,以获得ST块和后续的CTS预测模型,为了实现这一点,引入边权向量来衡量每个节点对之间的边 (ℎ𝑖, ℎ𝑗),这些向量反映了算子的性能并在训练期间学习。从节点 ℎ𝑖 到节点 ℎ𝑗 的转换为所有边的加权和,也就是:其中𝛼𝑜 (𝑖,𝑗) 是算子𝑜的权重,𝑜 (·) 表示算子𝑜的转换函数,节点ℎ𝑗 的潜在表示是通过对其前驱节点的所有转换求和来获得的:接下来就可以可以使用梯度下降法在目标CTS预测数据集上训练超网。现有的自动化框架虽然优于手动模型,但仍然需要预定义超参数,且并不支持联合搜索架构和超参数,效率比较低下。候选算子:通过对已有的CTS预测框架的搜索空间进行实验分析,论文引入了两个候选T算子:门控膨胀因果卷积(GDCC)与Informer (INF-T),两个候选S算子:扩散图卷积网络 (DGCN)与Informer (INF-S)。另外加入一个身份算子来支持节点之间的跳跃连接,这样就得到了由上述5个算子组成的候选算子集合𝑂。该框架也可以轻松容纳额外的算子,要添加新的算子时,只需将该算子加入到在候选算子集合𝑂中,后续的训练过程基本相同。拓扑连接:选择候选算子后考虑ST块内算子之间可能的拓扑连接,ST 块可以表示为具有𝐶 个节点的有向无环图𝐺𝑑(例如图3左侧),其中每个节点 ℎ𝑖 代表一个特征表示(feature representation),每条边代表一个算子𝑂𝑖,论文提出以下拓扑连接规则来生成候选ST块:(1) 从节点ℎ𝑖 到节点 ℎ𝑗 最多有一条边,并且𝑖 < 𝑗 时从节点 ℎ𝑗 到节点 ℎ𝑖 不允许有边(这是为了形成神经网络的前向流)(2) 一条边上的算子是从选定的候选算子集合中选出的。考虑两种超参数:结构超参数和训练超参数,表1总结了超参数搜索空间中的超参数,并列出了它们的可能值。该框架可以轻松包含额外的超参数以及现有超参数的扩展值范围。结构超参数:结构超参数与ST块的具体结构相关,包括ST块的数量𝐵、ST块中节点的数量𝐶、S/T算子的隐藏维度𝐻、输出维度𝐼,以及ST块的输出模式𝑈,输出模式𝑈 是一个二进制值,指示 ST 块中的哪个节点产生输出。训练超参数:训练超参数包括𝛿,𝛿 的值可以是0或1,表示是否使用随机失活(dropout)以缓解过拟合。从超参数搜索空间中选择的一组超参数值可以表示为𝑟 维向量,例如在表1中,[2,5,32,64,0,0]是一个可能的超参数向量。设计了架构和超参数搜索空间后需要将它们结合起来构建一个联合搜索空间,以支持搜索最佳的arch-hyper,两个搜索空间具有不同类型的编码(DAG与向量)因而无法简单组合,将联合搜索空间设计为联合双DAG是一个较好的选择。图3 联合搜索空间的DAG和邻接矩阵(𝑜𝑖表示一种算子)论文首先将架构搜索空间中架构的原始DAG 𝐺𝑑(图3左)转换为其对偶图𝐺𝑑∗(图 3 中),其中节点代表算子,边代表信息流。得到对偶图后向联合双DAG添加一个新的Hyper节点,该节点代表架构的超参数设置(图3中),Hyper节点连接到所有其他节点,这样就可以使用单个DAG 𝐺𝑎 来表示包含候选架构和候选超参数的完整ST块(图3中)。论文接下来使用邻接矩阵(反映了𝐺𝑎 的拓扑信息)𝐴𝑎 和特征矩阵(反映每个节点的算子信息)𝐹𝑎 来编码DAG 𝐺𝑎,首先采用最小-最大归一化对Hyper节点的原始特征进行归一化,然后将归一化后的特征转换为𝐷维嵌入:𝐹ℎ = 𝑛𝑜𝑟𝑚(𝐻𝑜)𝑊𝑐,其中𝐻𝑜是Hyper节点的原始特征向量,𝑊𝑐 是可学习矩阵,𝐹ℎ 是Hyper节点的嵌入。对于其他𝑛 个算子节点,论文首先将每个算子嵌入一个独热编码,然后引入一个可学习矩阵,将所有算子节点的独热嵌入转换为嵌入矩阵。形式上,𝐹𝑒 = 𝐻𝑒𝑊𝑒,其中𝐻𝑒 和 𝐹𝑒 分别是节点的独热嵌入和变换后的嵌入矩阵,𝑊𝑒 是可学习矩阵,这样联合搜索空间中的每个arch-hyper都可以编码为邻接矩阵𝐴𝑎 和特征矩阵𝐹𝑎。为了找到最佳arch-hyper,论文设计了AHC,将两个arch-hyper作为输入,并输出一个二进制值值𝑦,表明哪个arch-hyper可能具有更高的验证精度。图4展示了AHC的结构,AHC的输入是一对arch-hyper (𝑎ℎ1, 𝑎ℎ2),每对arch-hyper 都由其联合图的邻接矩阵和特征矩阵进行编码。考虑到图同构网络(GIN)区分任意两个图的强大能力,论文使用GIN将arch-hyper编码为紧凑的连续嵌入。给定arch-hyper图的邻接矩阵𝐴𝑎 和特征矩阵𝐹𝑎,相应的GIN可以递归表示如下:其中𝐿 是GIN层数,𝐻(0) = 𝐹𝑎,𝜖 是可训练偏差,𝑀𝐿𝑃是多层感知器。使用相同的GIN将两个输入𝑎ℎ1 和𝑎ℎ2 分别编码为𝑙𝑎 和𝑙′𝑎 后在特征维度中将它们连接为𝐿𝑎,最后将𝐿𝑎 输入到由全连接层和Sigmoid函数𝜎(·) 组成的分类器中,分类器使用0.5作为阈值,从而得到𝑎ℎ1 和𝑎ℎ2 的比较结果。训练可靠的AHC需要大量 (𝑎ℎ1,𝑎ℎ2,𝑦) 形式的训练样本,其中𝑎ℎ1 和𝑎ℎ2 是两个arch-hyper,y是arch-hyper 𝑎ℎ在验证集上的预测精度。得到大量训练样本的成本很高,因此一个合理的替代方案是轻量级代理𝑅 ′ (·),当𝑅′(𝑎ℎ1) ≥ 𝑅′(𝑎ℎ2)成立时,𝑅(𝑎ℎ1)
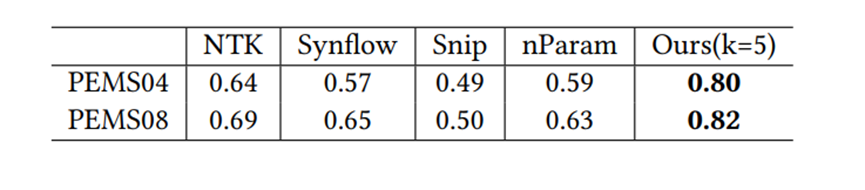
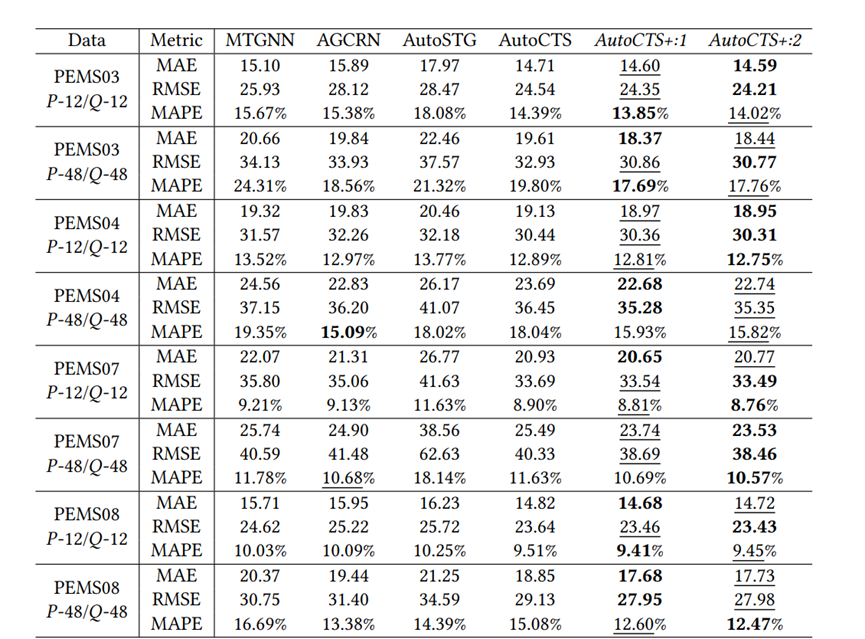
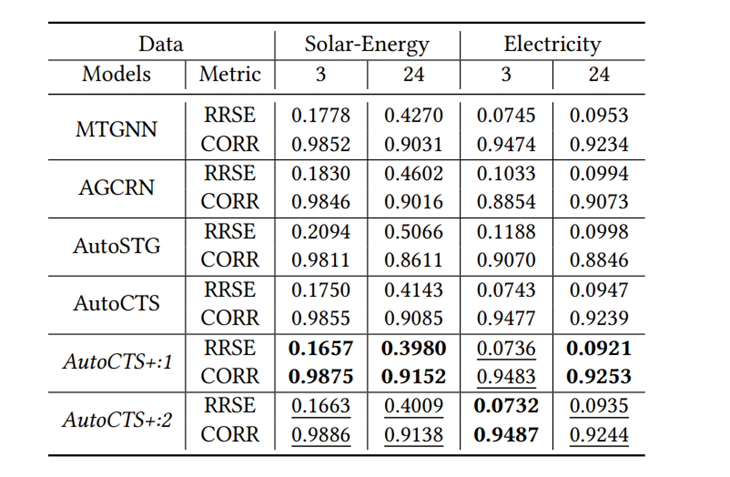
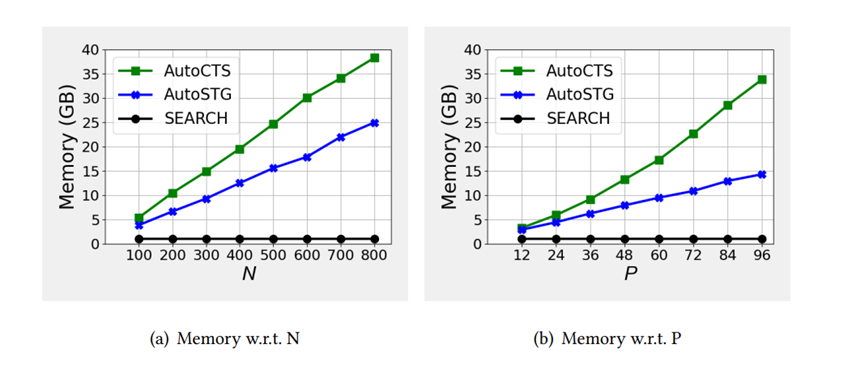
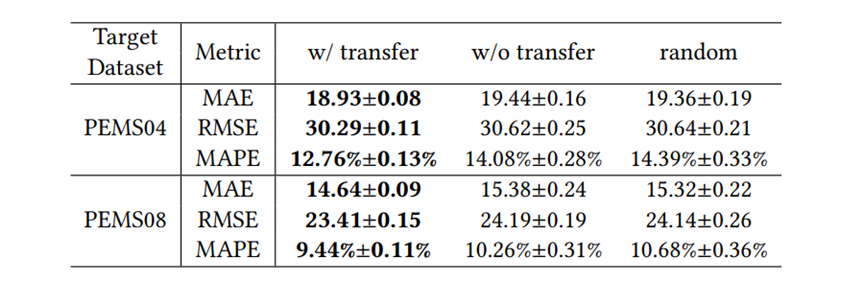
≥ 𝑅(𝑎ℎ2) 具有高置信度,使用这个代理可以生成伪标签𝑦 ′ = (𝑅′(𝑎ℎ1) ≥ 𝑅′(𝑎ℎ2))来近似 (𝑎ℎ1, 𝑎ℎ2) 的真实标签𝑦,这样就可以轻松获得大量有噪声的训练样本 (𝑎ℎ1,𝑎ℎ2,𝑦′),这些样本被称为噪声训练样本,因为𝑦′有可能被错误地标记。代理性能指标:在实验中注意到如果一个arch-hyper在前几个训练周期中的验证精度高于另一个,那么它的最终验证精度很可能也更高。基于这一现象,论文仅训练𝑘 (𝑘 ≤ 5)个周期的arch-hyper,并使用这个仅训练几个周期的验证精度作为代理,论文将提出的这种性能代理指标称为早期验证代理,如表2所示早期验证代理具有较高的准确性,适合为AHC生成噪声训练样本。去噪算法:为了最大限度地减少噪声样本训练的影响,实现更可靠的AHC,论文完全训练了一些额外的arch-hyper以获得形式为 (𝑎ℎ1, 𝑎ℎ2, 𝑦) 的干净训练样本,然后以去噪方式使用噪声和干净样本训练AHC。训练的具体过程是:首先从联合搜索空间中随机采样𝐿1个arch-hyper,并使用代理度量来获取每个arch-hyper 𝑎ℎ的代理分数𝑅 ′ (𝑎ℎ),然后将这些arch-hyper配对,生成𝐿1 (𝐿1 − 1) 个噪声样本,其形式为 (𝑎ℎ1, 𝑎ℎ2, 𝑦′),随机采样𝐿2 (𝐿2 << 𝐿1) 个arch-hyper并对其进行完全训练,以获得𝑎ℎ的验证准确性𝑅(𝑎ℎ),接下来将这些arch-hyper配对以生成 (𝑎ℎ1, 𝑎ℎ2, 𝑦) 形式的𝐿2 (𝐿2 − 1) 个干净样本。收集噪声和干净样本后,首先使用噪声样本将 AHC 预热𝑘𝑡个训练周期,然后使用干净样本对AHC进行微调直至收敛。搜索策略:论文使用进化算法在联合搜索空间中找到最佳的arch-hyper,首先对𝐾𝑠 个arch-hyper配对以产生𝐾𝑠 (𝐾𝑠 − 1)/2 个 (𝑎ℎ1, 𝑎ℎ2) 形式的比较对,然后从𝐾𝑠 个arch-hyper中按预测精度降序选择顶部𝑘𝑝 个arch-hyper作为初始种群,在每个进化步骤中生成新的后代时,每个arch-hyper分别具有交叉和变异概率𝑝1 和𝑝2。训练时将后代添加到种群中,并使用学习到的AHC来比较种群中的arch-hyper并删除劣质的 arch-hyper,以将种群规模保持在𝑘𝑝,最后从群体中选择预测精度排名中前K个arch-hyper来计算准确的预测精度,并选择精度最高的一个作为最终搜索到的ST块。复用已经训练好的AHC:尽管arch-hyper在不同的CTS预测数据集上表现不同,但已有的实验能够证明两个模型的相对性能不仅取决于数据,还取决于arch-hyper 本身,鉴于上述观察,论文提出将训练得到的的AHC迁移到未见过的数据集的方法:给定源数据集𝐷𝑠 上经过良好训练的AHC N𝑠和待训练的AHC Nt,可以将 N𝑠 转移到 Nt 上,通过微调来实现AHC的训练以提高训练效率。数据集:为了实现简单和公平的比较,论文使用六个广泛采用的基准数据集进行单步和多步预测实验评估指标:实验将提出的框架与两个性能最佳的手动设计的 CTS预测模型和两种最先进的自动化方法进行比较。为了比较不同 CTS 预测模型的性能,论文使用平均绝对误差 (MAE)、均方根误差 (RMSE) 和平均绝对百分比误差 (MAPE) 估计多步预测的准确性,并使用根相对平方误差(RRSE)和经验相关系数(CORR)估计单步预测的准确性。实验集群:多个Nvidia Quadro RTX 8000 GPU。预测性能:表4展示了AutoCTS+框架与四个多步CTS预测模型之间的性能比较,表5展示了AutoCTS+与两个单步CTS预测模型的性能比较。为了证明AutoCTS+框架对AHC的不同源数据集的鲁棒性,论文将框架分为AutoCTS+:1和AutoCTS+:2,它们分别使用PEMS08和PEMS04作为源数据集。为了便于观察,表格使用粗体和下划线来突出显示最佳结果和次佳结果。实验表明,论文提出的的框架(AutoCTS+:1 或 AutoCTS+:2)在几乎所有数据集上实现了一致的最先进的预测准确性,使用不同的源数据集得到的AutoCTS+:1和 AutoCTS+:2搜索的模型性能与现有模型相比均具有优越性,证明AutoCTS+对于不同的源数据集具有鲁棒性。可扩展性:论文比较了AutoCTS+框架和现有自动化框架的可扩展性,并将结果绘制在图5中。具体来说,首先将输入时间戳的数量𝑃 固定为12,并改变时间序列数量𝑁,然后将𝑁 固定为50,改变𝑃以观察可扩展性。图5表明AutoSTG 和AutoCTS的内存使用量随着𝑁 和 𝑃 增长而快速增长,而AutoCTS+框架的内存使用量变化很小,这证明了AutoCTS+框架比现有的自动化框架更具可扩展性。可转移性:论文构建了三个变体:(1)w/transfer:使用AHC转移方法并进行微调,使用少量的训练数据;(2) w/o transfer,直接在目标数据集上训练 AHC,不使用先前的AHC,使用少量的训练数据; (3) random,从联合搜索空间中随机选择3个 arch-hyper,并对它们进行完全训练以获得最好的一个。实验结果见表6,可以观察到对于这两个数据集,w/o transfer性能明显比 w/transfer更差,与random几乎相同。结果表明:如果不使用AHC转移,少量的训练数据远远不足以实现可靠的AHC;给定在源数据集上训练的AHC,可以通过仅使用少量训练数据对其进行微调,获得目标数据集上可靠的AHC配对,从而保证高训练效率。论文提出了相关时间序列架构-超参数搜索框架AutoCTS+,可以自动设计用于CTS 预测的高性能ST块,AutoCTS+框架包括arch-hyper联合搜索空间,AHC搜索策略以及含有代理度量的噪声训练。此外,论文还提出了一种转移方法来进一步提高框架的效率,能够将预训练的AHC转移到未见过的数据集,以减少训练AHC的样本需求。对六个常用相关时间序列预测数据集的综合实验证明了AutoCTS+框架的有效性、可扩展性和高训练效率。| 重庆大学计算机科学与技术(卓越)2022级本科生,重庆大学Start Lab团队成员。 | 
|
重庆大学时空实验室(Spatio-Temporal Art Lab,简称Start Lab),旨在发挥企业和高校的优势,深入探索时空数据收集、存储、管理、挖掘、可视化相关技术,并积极推进学术成果在产业界的落地!年度有3~5名研究生名额,欢迎计算机、GIS等相关专业的学生报考!
图文|高研盛
编辑|李佳俊
审核|李瑞远
审核|杨广超