对数据存储容量和高性能的需求的日益增长给并发索引结构带来了许多挑战。一个很有前途的解决方案是学习索引,它使用基于学习的方法来拟合数据的分布,通过预测的方式来定位数据,显著提高了查询性能。然而,现有的学习索引在多核数据存储上依然存在可伸缩性不足的问题。那么如何提高学习索引的可伸缩性呢?本次为大家带来数据库领域顶级会议SIGMOD的论文:《SALI: A Scalable Adaptive Learned
Index Framework based on Probability Models》

随着当今数据量的指数增长,高效的索引数据结构对于支持及时信息检索的大数据系统而言至关重要。为了提高传统基于树的索引的性能和内存效率,Kraska等人引入了一种称为递归模型索引(RMI)的学习索引,该索引使用机器学习模型来替换B+树的内部节点。原始RMI的一个缺陷在于它是静态的,因此在索引中插入或更新一个键需要重建数据结构的大部分,从而限制了学习索引的使用场景。先前的工作提出了两种策略来解决学习索引的可更新性问题。第一种方法(基于缓冲区的策略)是首先在单独的插入缓冲区中容纳新的条目,以均摊索引重建成本。另一种策略(基于模型的策略)是在节点内保留槽间隙,以就地插入处理新条目。在插入碰撞(即映射的槽已经被占用)时,ALEX[1]通过移动现有的条目来重新组织节点,而LIPP[2]利用链接方案,为相应的槽创建一个新的节点。然而,以上索引设计在高并发情况下都不具备良好的可伸缩性。论文进行了一个实验,将2亿个随机整数键插入到一个学习索引中,每次使用不同数量的线程。发现与使用基于模型的策略相比,使用基于缓冲区的策略的索引表现出更差的基础性能和更差的可伸缩性。这表明,更大的预测误差范围降低了索引的可伸缩性,因为基于缓冲区的策略的并发的“最后一英里”搜索迅速占满内存带宽,成为系统的瓶颈[3]。在LIPP+中,该问题得到解决,因为每个位置预测都是准确的(即没有“最后一英里”搜索)。然而,LIPP+需要在每个节点中维护统计信息,如访问计数和碰撞计数,通过重新训练节点以防止性能下降。然而,这些计数器导致线程之间产生高度争用。ALEX+中的基于模型的策略在插入冲突时需要移动现有条目。因此,ALEX+必须获取粗粒度写锁以执行此操作。随着线程数量的增加,越来越多的线程被阻塞,等待那些独占锁。因此,论文设计了SALI,旨在解决现有解决方案中存在的可伸缩性问题。为了解决维护每个节点统计信息的可伸缩性瓶颈,论文开发了轻量级的概率模型,可以在准确的时机触发SALI中的节点重新训练和其他结构演化操作。此外,论文还开发了一系列节点演化策略,包括扩展插入密集型节点以容纳更多的间隙、将频繁访问的节点的树结构扁平化,以及压缩很少被访问的节点以节省内存。SALI根据概率模型自适应地应用这些节点演化策略,因此可以在保持卓越的可伸缩性的同时,自我调整以适应不断变化的工作负载。学习索引的核心是使用一组学习模型来估计数据的累积分布函数(CDF),以预测数据的存储位置,如图1所示。每个节点,或只有叶节点,存储线性函数的斜率和截距。每个Segment对应于一个线性模型,它负责定位目标键的近似位置。该模式降低了传统的基于树的索引中需要多个间接搜索操作的开销,具有显著提高索引查找性能的潜力。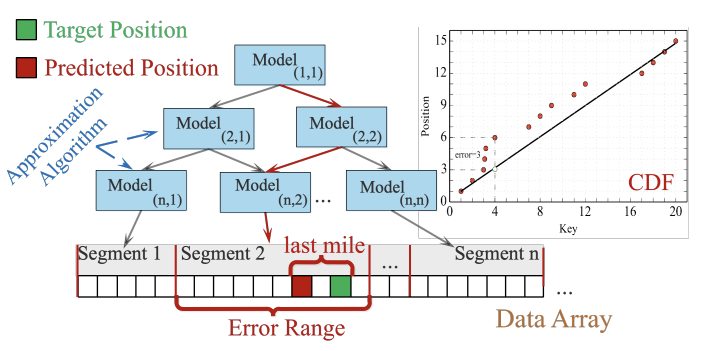
在并发场景中,索引操作的阻塞主要是由于插入了新的键。理解当前的插入策略对于增强索引的可伸缩性至关重要。论文总结了现有学习索引的插入策略如下:策略1:基于缓冲区的插入策略。如图2所示,基于缓冲区的策略的核心思想是为创建一个缓冲区结构。当缓冲区满时,其中的键与上个Segment中的键合并,并转换为一个新的线性模型,这导致预测可能会出现大量错误。策略2:基于模型的插入策略。如果线性模型预测插入的键的目标位置是空的,则直接插入。否则,有两种现有的冲突解决策略:- 移位:如图2所示,该方法将现有的冲突键及其相邻的键移到最近的一个槽,使得目标键插入目标位置。然而,键移动的过程可能会引入错误。
- 链:如图2所示,如果在新插入的键的目标位置已经存在一个键,则创建一个新节点以存放相互冲突的键。这种冲突解决方法不涉及移动任何数据,从而避免了潜在的查找错误(精确查找)。


表1总结了几个SOTA学习索引的潜在局限性,可以看出,没有任何一个现有的学习索引可以在同时保证基础性能与可伸缩性的同时(即在多线程下表现良好),还能保证不断演化的能力以适应新数据的插入。本部分将介绍SALI的结构,其中包括一种基于概率的轻量级统计维护方法和自适应演化策略。由于在现实环境中经常出现倾斜的工作负载,因此SALI对具有不同读写程度的节点应用不同的演化策略。这些策略可以作为传统再训练方法的替代品,因为它们是专门设计用来提高并发性能和减少索引空间的开销的。此外,SALI利用一种基于概率的轻量级方法来维护统计量,可以在保持节点再训练的精度的同时不阻止来自多个线程的插入操作。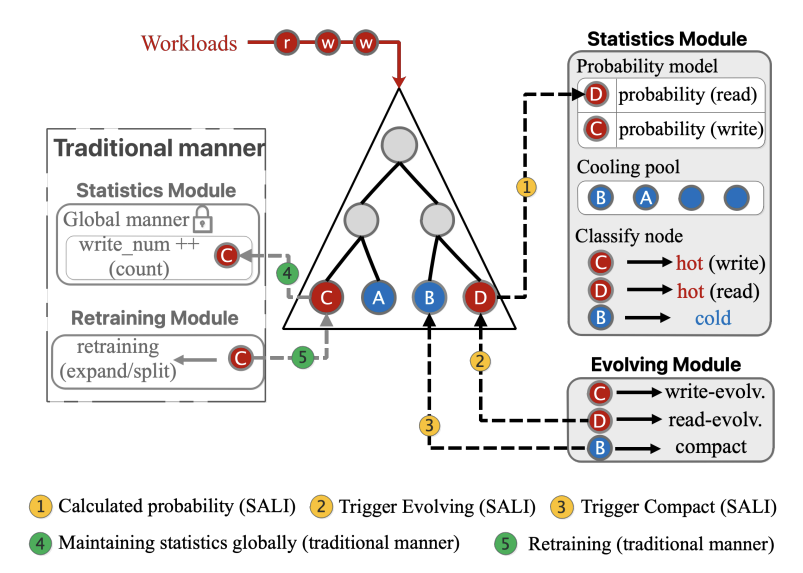
具体而言,如图3所示,SALI框架两个阶段。在第一阶段,计算每个节点在查找/插入操作过程中需要进行改进的概率,以提高性能。计算和维护概率的模型是轻量的,不会导致高争用和线程阻塞问题。在第二阶段,对被归类为热或冷的节点执行演化操作。SALI的结构建立在LIPP的结构之上,因为它在现有工作中表现出最高的可伸缩性。由于工作负载是多样的,因此,需要一个比再训练更全面的适应策略来调整学习索引结构。本部分介绍了一个不断发展的演化策略的设计,从3个方面提高了学习索引的并发性能。触发演变过程的条件和时间将在下节中讨论。再训练是一种被动的调整策略,用于可更新的学习索引,以保持其性能。其主要特点是:1)它是由索引结构的恶化驱动的,不能感知不同的工作负载;2)它只能通过专门为提高插入性能而优化的插入操作来触发;3)本质上不会改变索引结构。SALI提出的演化策略是学习索引中的一个新概念,它包含了再训练函数,改进了不同维度的索引调整机制。它的主要特点是:1)它是一种主动的调整策略,感知并受工作负载的驱动,以进一步提高索引性能;2)它可以被任何操作(如读取)触发;3)它可以“进化”成一种新的结构类型,适合当前的工作负载,以提高读取和插入性能。大多数再训练方法,包括SALI,都涉及到扩展目标节点或其子树。这种扩展创建了更多的间隙,可用于插入键,从而提高了整体插入性能。如图4(a)所示,数据节点内的间隙从1个增加到5个,以容纳更多的键。为了实现这一点,可以使用FMCD算法[4],输入扩展后空间大小即可扩展节点。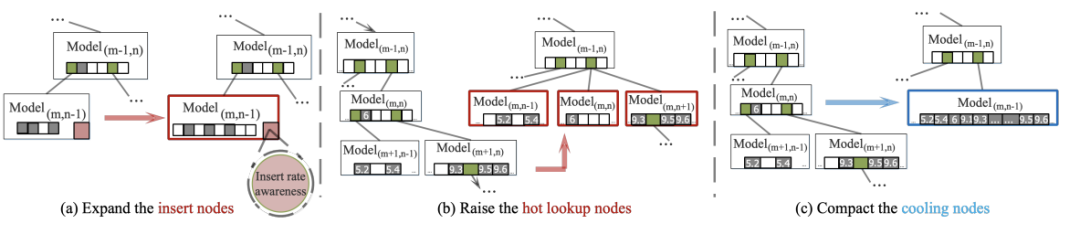
然而,如果固定扩展后的大小倍数可能不足以处理在倾斜的工作负载下插入迅猛增加的情况,这可能导致在并发场景中出现大量的插入冲突。为了解决这个问题,应该根据插入速率自适应地调整扩展因子,以确定最佳扩展大小。具体来说,当插入速率增加时,保留更多的间隙以提高插入性能。SALI采用的计算扩展因子的函数如下: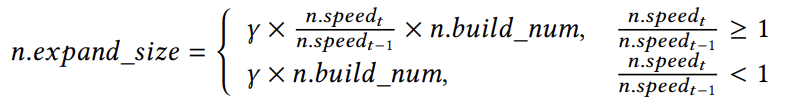
其中,𝑛表示一个特定的节点,𝑛.𝑏𝑢𝑖𝑙𝑑_𝑛𝑢𝑚表示当前节点的大小。𝑛.𝑠𝑝𝑒𝑒𝑑𝑡表示在𝑡时的积累速率,表示在特定时间新键插入节点的速率。该速率由一个概率模型决定。在式中,更高的速度会导致更显著的扩展率,这意味着与之前的扩展操作相比,将保留更多的间隙。扩展因子𝛾的定义如下: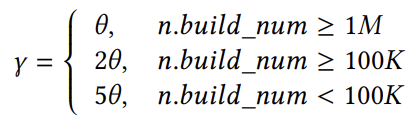
该式表明,不同大小的节点应该具有不同的扩展因子,较小的节点需要一个更大的扩展因子来实现足够的扩展。例如,如果两个节点上的槽数分别为4和8,且都需要扩展到32个槽,需要扩展因子分别为8和4。这个扩展基因子,用𝜃表示,可以根据不同的工作负载进行动态调整。SALI将𝜃设置的默认值为1。SALI为热读节点开发了一种不断演化的策略,以进一步提高在倾斜工作负载下的并发读性能。如果工作负载是统一的,那么SALI可以选择禁用这个演化函数,或者将每个节点视为一个热读节点。如图 4(b)所示,SALI为热读节点及其子树设计了一个扁平结构。这种结构使节点变平,并尽可能地提高它们的级别。在演化后,多个segment可以链接到同一个槽下。这种扁平化策略降低了局部热的树的高度。此外,SALI可以在查找过程中使用SIMD指令来快速查找目标键在某层中属于哪个节点。SALI开发了一种冷节点压缩演化策略,以优化SALI在倾斜工作负载下的空间占用。SALI添加了一个如图 5所示的冷却池空间。在SALI构建或演化操作期间,索引中的每个节点都有10%的概率被选择放置到冷却池中。当一个节点经历演化的操作时,该节点、它的子树和它上面的所有节点都被从冷却池中移除。在这个阶段,留在冷却池中的节点被认为是暂时冷的。当演化操作完成,SALI将检查是否超过了用户可接受的索引大小上限。如果超过了,SALI将选择冷却池中最早添加的节点进行压缩操作,并将其从冷却池中删除,直到满足用户可接受的索引大小。对于冷节点,空间压缩策略如图 4 (c)所示,即取消了保留的间隙,以为冷节点及其子树节省空间。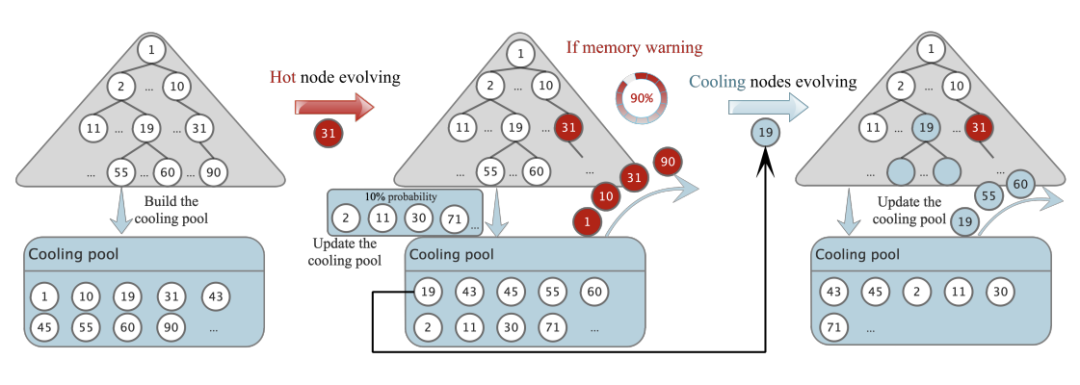
为了确保最佳性能,学习索引必须检测统计数据,以便在必要时进行调整。不幸的是,现有的高争用统计技术严重限制了学习索引的可伸缩性。此外,为了实施3.1节中提出的演化,还需要额外的统计数据,从而在并发场景中造成无法容忍的开销。为了解决这个问题,SALI提出了一种基于概率的策略,该策略使用一种轻量级的方法来维护SALI中的各种统计数据,从而以最小的成本触发演化操作。概率模型背后的基本是利用概率来模拟信息的积累。例如,当模拟指定时间内框架插入键的累积数量时,SALI设计了一个基于插入速率和插入时间的概率模型。此外,几何分布还可以用来模拟插入冲突等信息的积累。大多数再训练是由插入操作引起的学习索引的恶化所触发的。但是,从索引性能的总体角度来看,应该根据局部结构在调整后是否会继续面临新键的高频插入来考虑进行调整。这样的考虑可以使调整操作更加有利,从而获得较高的均摊性能效益。对于某个节点:条件(1):节点需要能够容纳足够数量的新插入的键。为了确定是否满足这个条件,需要满足以下公式: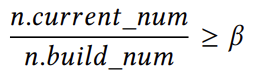 (1),其中,𝑛.𝑐𝑢𝑟𝑟𝑒𝑛𝑡_𝑛𝑢𝑚是指在当前插入操作结束时,节点中包含的键数。𝑛.𝑏𝑢𝑖𝑙𝑑_𝑛𝑢𝑚表示执行最后一次演化操作时节点中的键数。公差系数𝛽指定在需要调整节点之前可以插入节点的最大数据量。由于每个插入线程都必须维护累积变量𝑐𝑢𝑟𝑟𝑒𝑛𝑡_𝑛𝑢𝑚,因此可能会出现冲突。为了解决这个问题,论文提出了一个轻量级的概率模型。首先,将插入率乘以时间戳差,得到在此期间插入的新键的总量,并将其放入式中,得到:
(1),其中,𝑛.𝑐𝑢𝑟𝑟𝑒𝑛𝑡_𝑛𝑢𝑚是指在当前插入操作结束时,节点中包含的键数。𝑛.𝑏𝑢𝑖𝑙𝑑_𝑛𝑢𝑚表示执行最后一次演化操作时节点中的键数。公差系数𝛽指定在需要调整节点之前可以插入节点的最大数据量。由于每个插入线程都必须维护累积变量𝑐𝑢𝑟𝑟𝑒𝑛𝑡_𝑛𝑢𝑚,因此可能会出现冲突。为了解决这个问题,论文提出了一个轻量级的概率模型。首先,将插入率乘以时间戳差,得到在此期间插入的新键的总量,并将其放入式中,得到: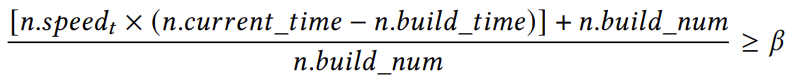 (2),变量𝑛.𝑏𝑢𝑖𝑙𝑑_𝑡𝑖𝑚𝑒表示与状态𝑛.𝑏𝑢𝑖𝑙𝑑_𝑛𝑢𝑚对应的时间戳,而𝑛.𝑐𝑢𝑟𝑟𝑒𝑛𝑡_𝑡𝑖𝑚𝑒表示当前的时间戳。估计的插入率,记为𝑛.𝑠𝑝𝑒𝑒𝑑𝑡,使用
(2),变量𝑛.𝑏𝑢𝑖𝑙𝑑_𝑡𝑖𝑚𝑒表示与状态𝑛.𝑏𝑢𝑖𝑙𝑑_𝑛𝑢𝑚对应的时间戳,而𝑛.𝑐𝑢𝑟𝑟𝑒𝑛𝑡_𝑡𝑖𝑚𝑒表示当前的时间戳。估计的插入率,记为𝑛.𝑠𝑝𝑒𝑒𝑑𝑡,使用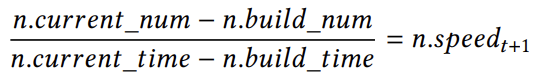 (3)计算,即上个时间段内插入数量和与时间戳的变化的商。因此,我们可以在时间𝑡时使用[𝑛.𝑠𝑝𝑒𝑒𝑑𝑡×(𝑛.𝑐𝑢𝑟𝑟𝑒𝑛𝑡_𝑡𝑖𝑚𝑒−𝑛.𝑏𝑢𝑖𝑙𝑑_𝑡𝑖𝑚𝑒)]+𝑛.𝑏𝑢𝑖𝑙𝑑_𝑛𝑢𝑚(4)来估计𝑛.𝑐𝑢𝑟𝑟𝑒𝑛𝑡_𝑛𝑢𝑚的值。此外,SALI将一个节点内的累积概率定义为𝑃𝑎𝑐𝑐,其中
(3)计算,即上个时间段内插入数量和与时间戳的变化的商。因此,我们可以在时间𝑡时使用[𝑛.𝑠𝑝𝑒𝑒𝑑𝑡×(𝑛.𝑐𝑢𝑟𝑟𝑒𝑛𝑡_𝑡𝑖𝑚𝑒−𝑛.𝑏𝑢𝑖𝑙𝑑_𝑡𝑖𝑚𝑒)]+𝑛.𝑏𝑢𝑖𝑙𝑑_𝑛𝑢𝑚(4)来估计𝑛.𝑐𝑢𝑟𝑟𝑒𝑛𝑡_𝑛𝑢𝑚的值。此外,SALI将一个节点内的累积概率定义为𝑃𝑎𝑐𝑐,其中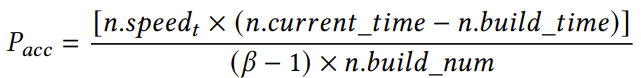 ,这是通过式(2)变换得来的。当𝑃𝑎𝑐𝑐=1时,满足条件,需要进行演化。当𝑃𝑎𝑐𝑐<1时,根据伯努利实验来确定是否需要演化调整。如果实验成功,则满足条件,否则不满足。条件(2):该节点可容纳足够数量的冲突。具体的概率模型请参考原论文,大致思想与条件(1)类似。实验平台:CPU:Intel Xeon Gold 6242 @2.80GHz CPUs (超线程到64线程);内存:384GB;编程语言:C++。数据集:五个真实数据集:1)COVID:带有COVID-19 标签的推特ID(均匀采样);2)FACE:Facebook用户ID;3)LIBIO:来自libraries.io的库ID;4)OSM:OpenStreetMap位置(均匀采样)。5)GENOME:人类染色体上的位置对。对比方案:六个对比方案:1)Masstree,B+树和Radix树的混合索引结构;2) ART-OLC,自适应Radix树的一个并发实现。3) ALEX+,ALE的一个并发实现;4) LIPP+,LIPP的并发实现;5) XIndex,第一个并发学习索引;6) FINEdex,一个细粒度更新的并发学习索引。图 6显示了在不同的数据集上执行只写工作负载时,对各种学习索引的并发性能评估。线程数用x轴上指定的数字表示。可以发现,除LIPP+之外,所有索引都受益于线程数量的增加,但当线程数超过逻辑核数时,性能就会下降。在简单的数据集中,即COVID、LIBIO和FACE,SALI在总体吞吐量方面表现更好。与学习索引ALEX+和传统的ART-OLC索引相比,SALI具有最好的可伸缩性。当线程数量超过60时,ALEX+和ART-OLC表现出性能急剧下降,而SALI保持高而稳定的性能。在COVID数据集中,SALI的性能分别比最好的两个基线即ALEX+和ART-OLC高出47%和73%,当线程数超过60后,该差距继续扩大。在复杂的数据集中,SALI的性能比其他学习索引高出2.5倍到10倍,因为SALI可以准确地匹配复杂的CDF,因此其性能可以与ART-OLC相当,并且当线程数超过了逻辑核数的时候,SALI可以保证性能,相比之下,ART-OLC的性能急剧下降。
,这是通过式(2)变换得来的。当𝑃𝑎𝑐𝑐=1时,满足条件,需要进行演化。当𝑃𝑎𝑐𝑐<1时,根据伯努利实验来确定是否需要演化调整。如果实验成功,则满足条件,否则不满足。条件(2):该节点可容纳足够数量的冲突。具体的概率模型请参考原论文,大致思想与条件(1)类似。实验平台:CPU:Intel Xeon Gold 6242 @2.80GHz CPUs (超线程到64线程);内存:384GB;编程语言:C++。数据集:五个真实数据集:1)COVID:带有COVID-19 标签的推特ID(均匀采样);2)FACE:Facebook用户ID;3)LIBIO:来自libraries.io的库ID;4)OSM:OpenStreetMap位置(均匀采样)。5)GENOME:人类染色体上的位置对。对比方案:六个对比方案:1)Masstree,B+树和Radix树的混合索引结构;2) ART-OLC,自适应Radix树的一个并发实现。3) ALEX+,ALE的一个并发实现;4) LIPP+,LIPP的并发实现;5) XIndex,第一个并发学习索引;6) FINEdex,一个细粒度更新的并发学习索引。图 6显示了在不同的数据集上执行只写工作负载时,对各种学习索引的并发性能评估。线程数用x轴上指定的数字表示。可以发现,除LIPP+之外,所有索引都受益于线程数量的增加,但当线程数超过逻辑核数时,性能就会下降。在简单的数据集中,即COVID、LIBIO和FACE,SALI在总体吞吐量方面表现更好。与学习索引ALEX+和传统的ART-OLC索引相比,SALI具有最好的可伸缩性。当线程数量超过60时,ALEX+和ART-OLC表现出性能急剧下降,而SALI保持高而稳定的性能。在COVID数据集中,SALI的性能分别比最好的两个基线即ALEX+和ART-OLC高出47%和73%,当线程数超过60后,该差距继续扩大。在复杂的数据集中,SALI的性能比其他学习索引高出2.5倍到10倍,因为SALI可以准确地匹配复杂的CDF,因此其性能可以与ART-OLC相当,并且当线程数超过了逻辑核数的时候,SALI可以保证性能,相比之下,ART-OLC的性能急剧下降。
图 7显示了在不同的数据集上执行混合工作负载时,对各种学习索引的并发性能评估。图 7(a,b)显示,在读取密集型工作负载下,SALI的性能优于其他索引,特别是在简单的数据集中。与ART-OLC和ALEX+相比,SALI在60个线程下的性能分别提高了37%和55%。图 7(c、d)说明了平衡工作负载条件下的性能。SALI保持高可伸缩性。其他索引的性能也表现出类似于读取密集型的工作负载。图 7 (e)展示了平衡工作负载下的索引的尾部延迟。其中,ALEX+和LIPP+比其他索引表现出更高的尾部延迟。然而,随着读取比率的增加,两个索引的尾部延迟都会减小。值得注意的是,SALI在整个过程中始终保持着较低的尾部延迟。
图 7 混合工作负载
图 8展示了对只读工作负载的评估。SALI和LIPP+在简单数据集和复杂数据集上都优于其他索引,因为它们采用了基于模型的链结构,这可以实现精确的查找。在只读场景中,LIPP+不需要高争用地维护统计信息,而SALI需要识别热节点和冷节点,这增加了轻微的开销。因此,SALI的性能略低于LIPP+。由于频繁的“最后一英里”查找,ALEX+表现出较差的查询性能。XIndex和FINEdex由于预测错误率较高导致性能较差。ART-OLC由于与学习索引相比树的层数较多,在只读工作负载下没有很大的优势。图 8(d,e)描述了FACE和OSM数据集上的尾部延迟。由于严重的预测错误,XIndex和FINEdex的表现更差。相比之下,SALI和LIPP+的尾部延迟比ALEX+要低,因为它们不会出现任何查找错误。本文介绍了SALI,一个拥有高度可伸缩的学习索引框架。SALI设计了一个基于概率的框架,用于监控索引的“退化信号”,并以分散的方式识别热/冷节点,从而消除了线程阻塞,提高了并发场景中索引的可伸缩性。由于统计开销可以忽略不计,因此概率框架为索引分别根据热数据和冷数据演化提供了必要的条件。此外,SALI还设计了演化策略,允许SALI分别为冷热节点演化出性能更好的局部结构。实验结果表明,建立在𝑀𝑜𝑑.+𝐶结构上的SALI比最先进的学习索引提供了显著更好的可伸缩性,并且演化策略可以将读写性能分别提高至少25%和30%。[1] Jialin
Ding, Umar Farooq Minhas, Jia Yu, Chi Wang, Jaeyoung Do, Yinan Li, Hantian
Zhang, Badrish Chandramouli, Johannes Gehrke, Donald Kossmann, et al. 2020.
ALEX: an updatable adaptive learned index. In Proceedings of the 2020ACM SIGMOD
International Conference on Management of Data. 969–984.[2] Jiacheng
Wu, Yong Zhang, Shimin Chen, Jin Wang, Yu Chen, and Chunxiao Xing. 2021.
Updatable learned index with precise positions. Proceedings of the VLDB
Endowment 14, 8 (2021), 1276–1288.[3] Chaichon
Wongkham, Baotong Lu, Chris Liu, Zhicong Zhong, Eric Lo, and Tianzheng Wang.
2022. Are Updatable Learned Indexes Ready? Proceedings of the VLDB Endowment
(2022).[4] Jiacheng Wu, Yong Zhang, Shimin Chen, Jin
Wang, Yu Chen, and Chunxiao Xing. 2021. Updatable learned index with precise
positions. Proceedings of the VLDB Endowment 14, 8 (2021), 1276–1288.
| 重庆大学计算机科学与技术专业在读硕士二年级学生,重庆大学Start Lab成员。 | 
|
重庆大学时空实验室(Spatio-Temporal Art Lab,简称Start Lab),旨在发挥企业和高校的优势,深入探索时空数据收集、存储、管理、挖掘、可视化相关技术,并积极推进学术成果在产业界的落地!年度有2~3名研究生名额,欢迎计算机、GIS等相关专业的学生报考!







