随着分析工作负载向云端迁移,数据也转为数据湖的形式。这些数据湖通常存储在对象存储服务(如S3)上,实现了无缝的数据共享和系统互操作性。为了支持这一趋势,许多系统选择建立在开放的存储格式上,例如Apache Parquet。然而,他们并没有针对远程访问的数据湖和当今高吞吐量网络进行优化。本文是已经发表在数据库领域顶会SIGMOD 2023上的《BtrBlocks: Efficient Columnar Compression for Data Lakes》,旨在提高远程访问数据湖以及在今天高吞吐量网络下的性能和效率。
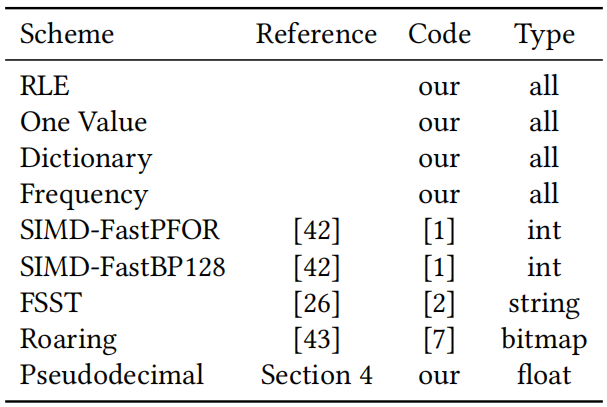
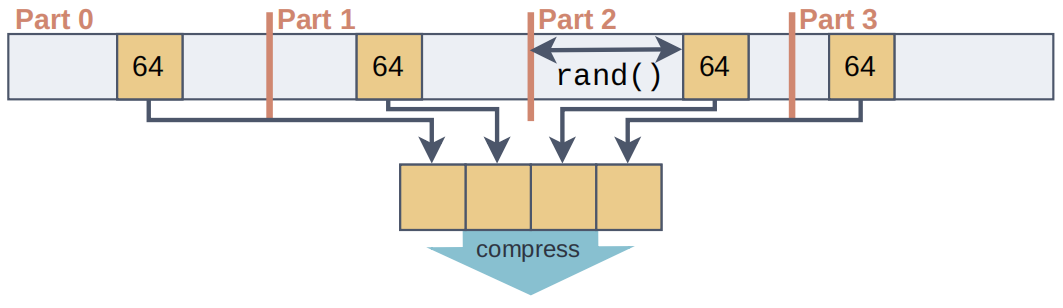
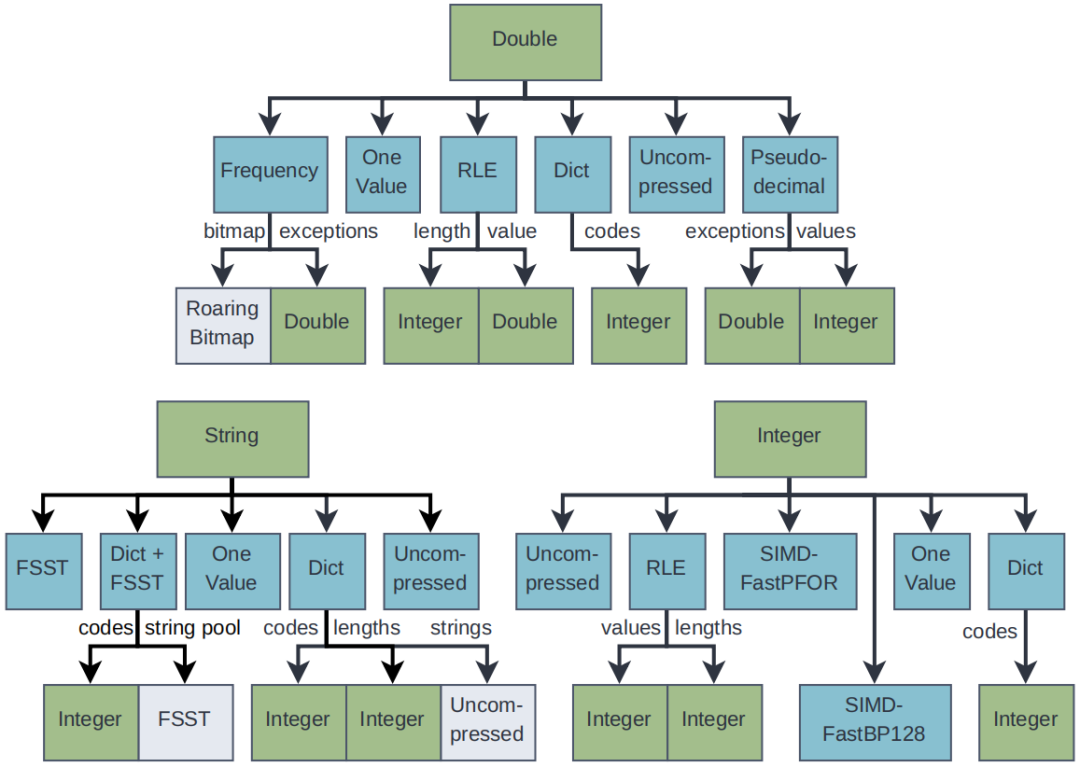
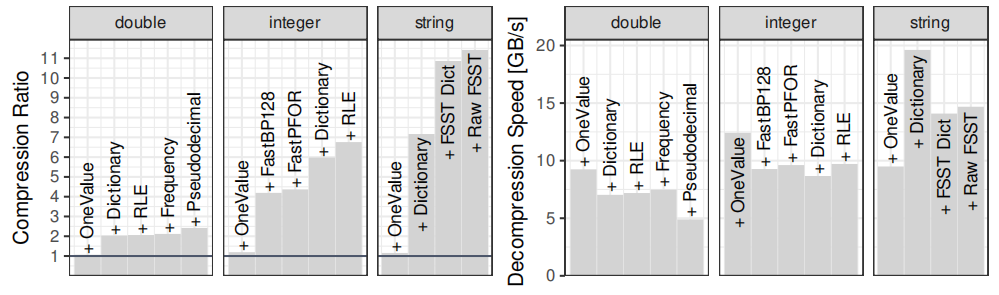
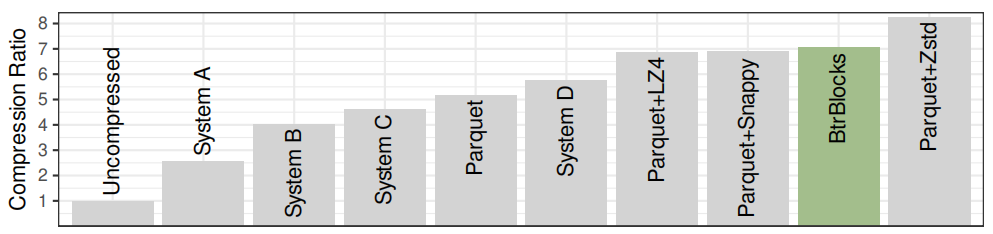
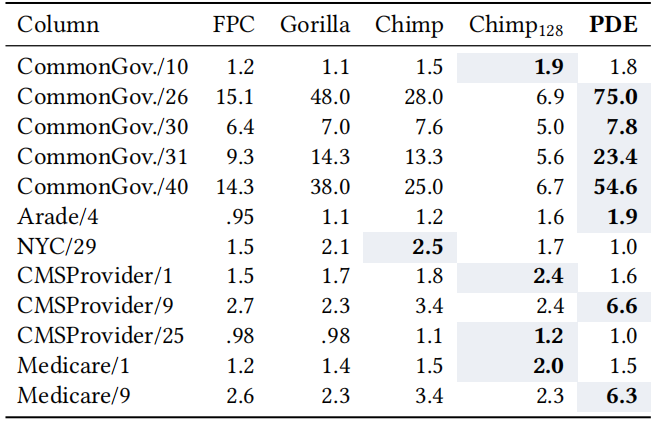
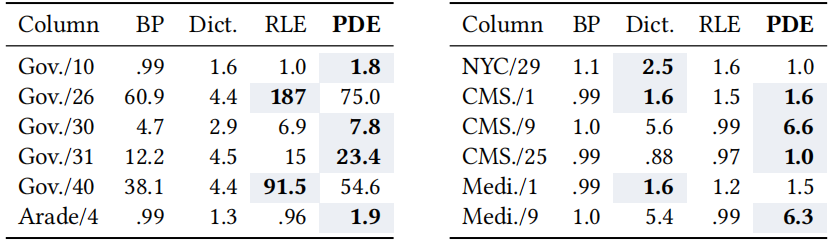
数据仓库正逐渐迁移到云端。许多组织正在收集和分析日益庞大的数据集,这些数据越来越多地存储在像亚马逊AWS、微软Azure和谷歌云这样的公共云中。为了分析这些数据集,客户使用云端数据仓库系统。其中数据存储在分布式云对象存储中,如S3,并且计算能力可以根据需要弹性生成。但是数据仓库可能成为数据陷阱。经过长时间的验证,数据仓库依赖压缩的列式存储。默认情况下,大多数系统使用专有的存储格式,其中一个显著缺点是,数据被困在一个系统或者生态中,不能被其他系统灵活地使用。因此提出采用数据湖的方式来解决数据仓库的问题。数据湖有着开放的存储结构,但存在以下问题:1)过去网速慢导致访问数据湖慢,现已解决;2)与专有的数据仓库相比欠有效、紧凑,需要进行压缩。BtrBlocks的设计目的是通过低存储成本和快速解压缩,将总体工作负载成本最小化。为了在真实数据上实现有效的压缩,文章结合了7种现有的编码方案和一种新颖的编码方案,提供快速解压缩性能,并可以级联使用(例如先RLE然后按位打包)。BtrBlocks还设计了一种算法用于确定对特定数据块使用哪种编码。 Parquet & ORC:Apache Parquet 和 Apache ORC是开源的面向列的格式,支持了很多分析系统,其中Parquet使用更加广泛。Parquet列编码:采用定长编码,支持RLE编码、字典、位打包,Delta编码。使用的编码方式可以由用户指定也可以由满足特定情况的规则确定。Parquet将结果打包成行组。多个行组被组合成一个Parquet文件,每个行组的元数据同样存在文件中。元数据和统计信息:每一个Parquet文件里面都包括元数据和统计数据以及一些轻量级索引,这些信息对查询处理十分重要,但是这些信息放在数据文件里是不太合适的。本文将数据和其他的信息分离开来,仅生成具有可配置大小的压缩数据块。元数据、统计信息和索引是完全独立的。额外的通用压缩。Parquet中可以选择的编码方案很少,因此在使用简单的列编码方案后实际压缩率并不高,因此会使用Snappy、Brotli、Gzip、Zstd、LZ4、LZO和BZip2等算法进行二次压缩,但是解压时间就会相应增加。一个更好的压缩方法。上面提到的压缩方案的解压时间很长,因此BtrBlocks扩展了Parquet提供的轻量级编码选择并且改进了编码方案选择算法。 BtrBlocks的理念是结合多种类型特定的高效编码方案,涵盖不同的数据分布,从而在保持解压缩速度的同时实现高压缩比。表1列出了BtrBlocks中使用的编码方案。BtrBlocks对类型化数据列(整数、双精度浮点数和可变长度字符串)进行压缩。BtrBlocks将每一列分成固定大小的块, 默认大小为64,000个条目。逐个压缩块使得BtrBlocks能够通过根据每个块中的数据调整压缩方案来应对不断变化的数据分布。块还有助于并行化压缩和解压缩过程。RLE & One Value。Run-length Encoding (RLE)是一种普遍的技术,它对相等值的连续序列进行压缩。例如,连续的序列{42, 42, 42},存储为(42, 3)。One Value是针对只有一个唯一值的列进行特殊优化。Dictionary。字典编码是另一种简单但有效的方案,它使用(较短的)编码替换输入中的不同值。一个查找结构(即字典)将每个编码映射到原始的不同值。用于实现字典的数据结构由编码类型确定,字典通常是压缩字符串的唯一方式。Frequency。在真实世界的数据集中,通常会有一些多次出现的值,形成了偏斜分布。DB2 BLU提出了一种基于数据频率的频率编码,使用多个代码长度。例如,一个一位编码可以表示两个最频繁的值,一个三位代码可以表示接下来的八个最频繁的值,依此类推。通常,一列只有一个主导的频繁值,其次频繁的值出现的频率呈指数下降。本文针对这种情况进行了优化,只存储:1)最频繁的值,2)标记哪些值是最频繁值的位图,3)不是最顶部值的异常值。 FOR & Bit-packing。对于整数,参考框架(Frame of Reference,FOR)将每个值编码为相对于选定基值的增量。例如,序列{105, 101, 113},我们可以选择基值为100,然后存储{5, 1, 13}。这在与Bit-packing结合使用时很有用,后者截断不必要的前导位,可以使用4位而不是8位对每个值进行Bit-packing。但是,基本的FOR方案在处理离群值时效果不佳。例如,向示例序列添加118,这种情况下每一个值都需要5位来表示。因此,Patched FOR (PFOR)将这些离群值存储为异常,并保留其余值的较小位宽。SIMD-FastPFOR和SIMD-FastBP128构建在这个想法上,并专门为SIMD(单指令多数据)优化了算法和布局。在BtrBlocks中使用这些现有的高性能实现。FSST。Fast Static Symbol Table (FSST)是一种用于字符串的轻量级压缩方案,因为真实世界中大部分的数据都以字符串形式存储。FSST通过将长度最多为8个字节的频繁出现的子字符串替换为1个字节的编码来实现压缩。这些编码在一个固定大小的255条目字典(符号表)中进行跟踪。符号表是不可变的,并且用于整个字符串块。解压缩是简单且快速的但是压缩时需要找到一个合适的符号表,所以较为复杂。NULL Storage Using Roaring Bitmaps。BtrBlocks使用Roaring Bitmap存储每列的NULL值。Roaring 的背后思想是根据位的局部密度使用不同的数据结构,这使得它对于许多数据分布非常高效。BtrBlocks使用一个针对现代硬件进行了优化的开源C++库来实现Roaring Bitmaps。除了追踪NULL值之外,BtrBlocks还使用Roaring Bitmaps来追踪内部编码方案(例如频率编码)的异常情况。 方案选择算法。针对不同数据类型本文提供了不同的编码方案,以适合各种不同的数据分布。但存在一些挑战:一种更好的编码方案选择是使用抽样。为了更好的压缩,样本必须捕获与压缩相关的数据集特征。例如,随机抽样可能不能很好地检测RLE是否有效。另一方面,简单地取第一个k个元组,就可能会得到一个有偏差的样本。方案选择算法的另一个挑战是要考虑级联,即它必须决定是否对已经编码的数据进行二次编码。解决方案。在BtrBlocks中将在每一个样本中测试每种编码方案并且选择性能最好的方案。给定一个要压缩的数据块,每个递归级别都执行以下步骤:(3)对于每个可行的方案,使用数据中的一个样本来估计压缩比。(4)选择观测压缩比最高的方案,并以此压缩整个块。(5)如果压缩的输出为可压缩格式,则重复步骤(1)。为了让每个数据块选择最佳方案,样本必须代表数据的特征。主要是需要保留空间局部性以及捕捉到唯一值的分布,而且开销尽可能要低。如图1所示,文章从数据的非重叠部分的随机位置选择多个小runs。对于64,000个值的块大小,文章使用每个包含64个值的10个runs,从而得到1%数据的样本大小。 估计压缩比。BtrBlocks首先通过一次遍历收集诸如𝑚𝑖𝑛、𝑚𝑎𝑥、唯一计数和平均运行长度等统计数据。基于这些统计数据,然后应用启发式方法来排除不可行的方案。然后,BtrBlocks使用每个可行的编码方案对样本进行压缩,以估计每个方案的压缩比。递归应用方案。在选择了一个压缩算法之后,压缩后的数据(或其中的一部分)可能会使用不同的方案进行压缩。如图所示,递归点表示额外的可能压缩步骤。用于额外步骤的方案再次使用我们的压缩比估算算法进行选择。递归的最大次数默认为3。一旦达到这个递归深度,BtrBlocks 将不再进行压缩。 编码方案池。结果是一个通用的、可扩展的级联压缩框架,它从任意编码方案的池中进行选择。方案池显著影响BtrBlocks的整体效果:有了更多的方案,压缩速度变慢,因为需要评估更多的样本,但压缩比增加。添加更多的重型方案可能也会提高压缩比,但减慢解压缩速度。过去对关系型数据库中浮点压缩的研究非常少。这有一个历史原因:关系系统通常将实数表示为小数或数值,可以物理地存储为整数。然而,随着数据湖的转移以及随后与非关系系统的集成,这种情况正在改变,例如,Tableau的内部分析DBMS将所有实数编码为浮点数,而机器学习系统几乎完全依赖浮点数。文章设计了一种专门为二进制浮点数设计的压缩方案,即伪十进制编码(Pseudodecimal Encoding)。挑战:1)物理上的IEEE 754表示,导致许多压缩方法不适合;2)一些十进制数,不能用二进制精确表示,如0.99实际存储的值是0.98999...。浮点数表示为整数元组。伪十进制编码使用十进制表示法对双精度浮点数进行编码。它使用两个整数进行表示:带符号的有效数字和指数。例如,3.25变为(+325, 2),就像325 × 10^(-2)一样;对于0.99只需要存(99, 2)而不用存(98999...,17)。算法细节。伪十进制编码算法通过测试所有10的幂并检查它们是否正确地将双精度浮点数乘以一个整数值来确定紧凑的十进制表示。首先在一个静态表中存储10的幂的倒数,以避免为每个数字重新计算它们。其次为解决-0、lnf和NaN问题,算法将其作为补丁存储。同时将数字和指数的位数限制为32和5。这些属性确保编码比特位相同。级联到整数编码方案。伪十进制编码将一个浮点数列转换为两个整数列和一个小的异常列。BtrBlocks可能会再次使用级联压缩对这些列进行编码:图中所示的级联压缩选择只是示例,而不是固定的;BtrBlocks使用其先前描述的采样算法来选择方案。何时使用伪十进制编码。有些数据不适合使用伪十进制编码,比如包含许多异常值的列:伪十进制编码略微提高了压缩比,但由于存在许多异常值,解压缩速度较慢。因此,BtrBlocks对那些具有超过50%不可编码异常值的列禁用该方案。同样,具有很少唯一值的列通常使用字典几乎可以实现同样好的压缩效果,而字典具有更高的解压缩速度。因此,在BtrBlocks的上下文中,选择在具有少于10%唯一值的列中排除伪十进制编码。 实验设置。实验在c5n.18xlarge AWS EC2实例上执行,运行着Intel Xen Platinum 8000系列(Skylake-SP)CPU,并配备了192 GiB的内存。代码在Amazon Linux 2上使用GCC 10.3.1进行编译,内核版本为5.10。本文使用TBB库进行并行化,并禁用超线程。数据集。1)合成数据。像TPC-H和TPC-DS的数据生成算法未必能产生真实的数据分布,为了能反映典型的现实世界数据,不使用合成数据集进行评估;2)Public BI Benchmark。其包含了从创建时的46个最大的Tableau Public工作簿中派生的数据集,内容更具代表性,更符合今天大型数据湖中可能找到的情况:数据倾斜、非规范化表、错误使用的数据类型(例如,字符串的泛滥)以及由异构数据源的各种形式导致的非统一的NULL表示。测量每个压缩方案。如图4所示,对于双精度浮点数,字典编码和伪十进制编码对压缩比的影响最大,分别提高了95%和20%。然而,正如预期的那样,双精度浮点数本质上比整数和字符串更难以压缩。One Value 在双精度浮点数和整数的解压缩速度方面也是最快的,分别提供了平均吞吐量为 8.9 GB/s 和 11.8 GB/s。对于字符串解压缩,字典编码将吞吐量从 9.4 GB/s 提高到 19.6 GB/s。 图4 当依次增加压缩方案时,根据数据类型,压缩比和解压缩吞吐量的变化图5显示了不同采样策略在一直对640个元组进行采样(64k块的1%)的情况下,正确选择方案的百分比。它包括一些极端情况,比如随机采样个别元组或选择单个元组范围,这两者的性能最差。主要的观点是,对整个块进行多次小块采样相对于其他策略而言可以提高准确性,尽管在选择包含≥ 16个元组的块的策略之间几乎没有差异。这证实了样本需要捕捉整个块的数据局部性和数据分布的直觉。本文设计BtrBlocks时考虑了关系型数据,例如存储构成元组的对齐列。因此,本文将其压缩比与四个关系型列存储在Public BI数据集上进行了比较。这些系统基于内部专有格式进行压缩。论文还将最流行的开源格式Apache Parquet添加到比较中。Parquet提供了不同的内置高级压缩选项。图6显示了综合结果,显示BtrBlocks在除了Parquet上的重量级Zstd压缩之外的每种格式上都表现更好。 图6 Public BI Benchmark中专有列存储(A-D)、Parquet和BtrBlocks的压缩比。与现有的双精度浮点数方案进行比较。首先将伪十进制编码与众所周知的现有双精度浮点数压缩方案FPC 、Gorilla 以及最近提出的Chimp和Chimp128 进行比较。表2显示了这些方案在最大的非平凡(例如,超过一个值)公共BI双精度浮点数列上的压缩比。伪十进制编码(PDE)在高精度值的列上效果不好,比如纽约市的经度坐标值NYC/29。然而,在精度较低的列上通常优于其他方案。表2. 伪十进制编码(PDE)和其他双精度浮点数方案的压缩率 同样的伪十进制编码与BtrBlocks方案池中的算法进行比较,伪十进制编码在性能上也必须优于诸如字典编码和RLE之类的通用方案。文章通过再次应用一个固定的两级级联来比较这些方案,其中每个方案的输出总是使用FastBP128进行压缩。还包括非级联的FastBP128,以检查论文的推断,即Bit-packing(BP)在IEEE 754浮点数值上不够有效,如表3所示。本文提出了BtrBlocks,一种面向数据湖的开放式列压缩格式。可以针对不同的数据情形选择合适的算法进行压缩,并且提出了针对浮点类型数据的伪十进制编码算法。通过对数据集Public BI Benchmark一个包含真实世界数据集的集合进行实验,并使用基于样本的压缩方案选择算法和级联压缩的通用框架,展示了与现有数据湖格式相比,BtrBlocks实现了更高的压缩率、更卓越的解压性能。 | 重庆大学计算机科学与技术专业2023级博士研究生,重庆大学 START团队成员。主要研究方向:时空数据管理,数据压缩 | 
|
重庆大学时空实验室(Spatio-Temporal Art Lab,简称Start Lab),旨在发挥企业和高校的优势,深入探索时空数据收集、存储、管理、挖掘、可视化相关技术,并积极推进学术成果在产业界的落地!年度有2~3名研究生名额,欢迎计算机、GIS等相关专业的学生报考!