





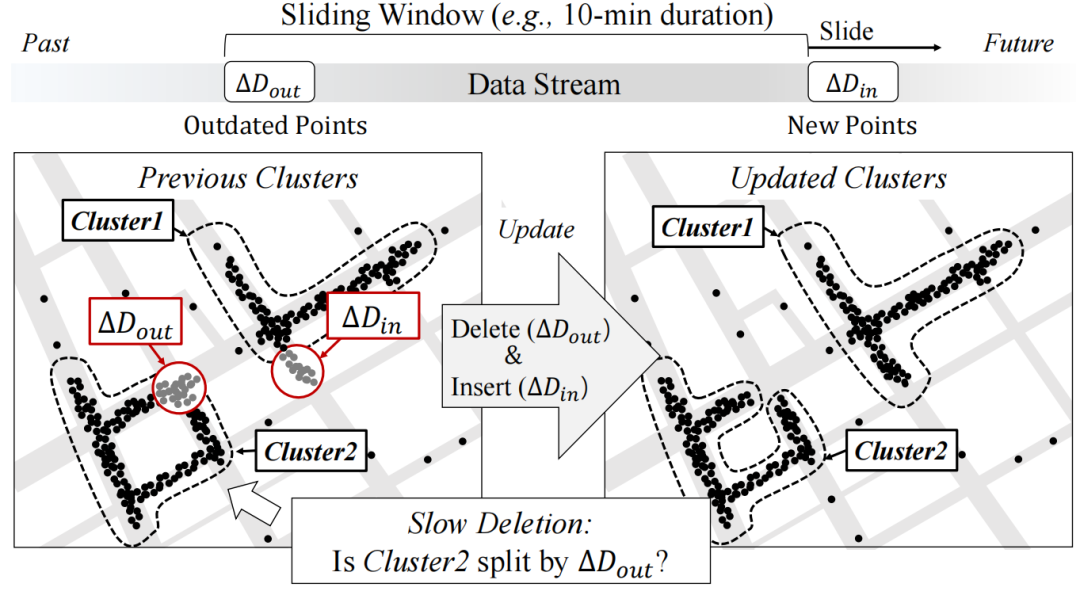
距离阈值ε:用于确定邻居点。点p的邻居点集合为所有与p距离小于ε的点,即Nε(p)={q∈D : d(p,q)≤ε},其中,D表示数据集。 密度阈值MinPts:用于确定核心点。若p的邻居点数量≥MinPts,则p为核心点。
核心点 边界点:不满足核心点的条件,但它是核心点的邻居。 噪声点:除以上两种点之外的点。
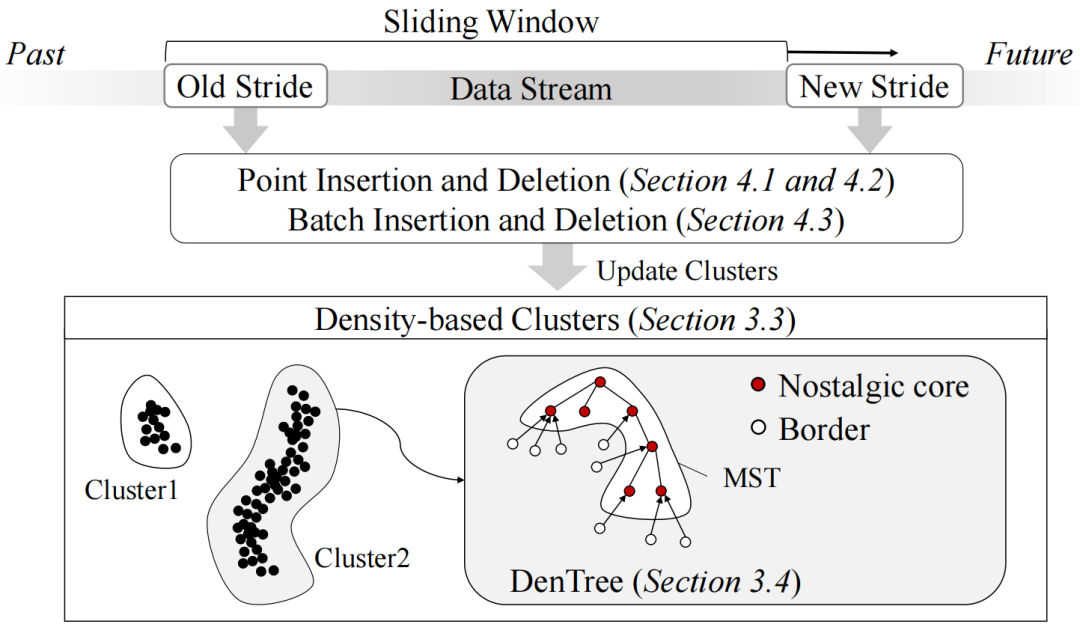
直接密度可达:满足| Nε(q) |≥MinPts且p∈Nε(q) ,称p可从q直接密度可达。 密度可达:存在一条点链p1,...,pn∈D,p1=q,pn=p,pi+1可从pi直接密度可达,则称p可从q密度可达。 密度相连:p,q都能从点o密度可达,则称p,q是密度连接的。

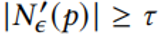 且
且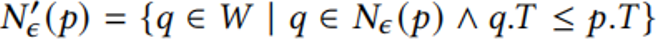 时,就称p为怀旧核心点。其中,Nε代表p的邻居点,T代表时间戳。简单来说,就是若满足p的邻居点且比p先进入窗口的点数量大于阈值τ,p就是怀旧核心点。
时,就称p为怀旧核心点。其中,Nε代表p的邻居点,T代表时间戳。简单来说,就是若满足p的邻居点且比p先进入窗口的点数量大于阈值τ,p就是怀旧核心点。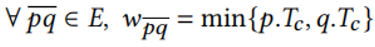 。
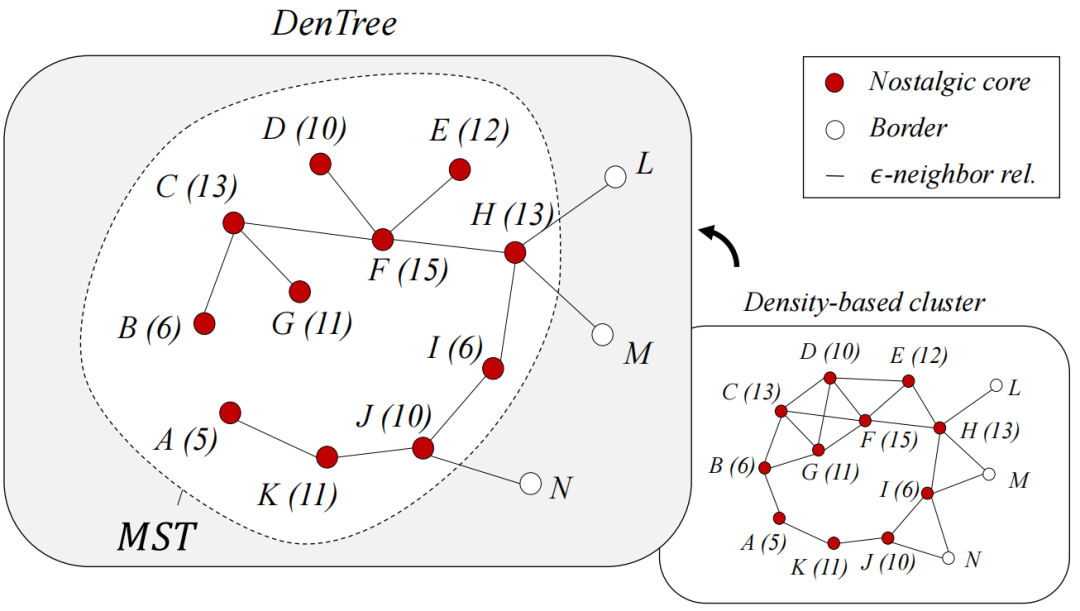
。


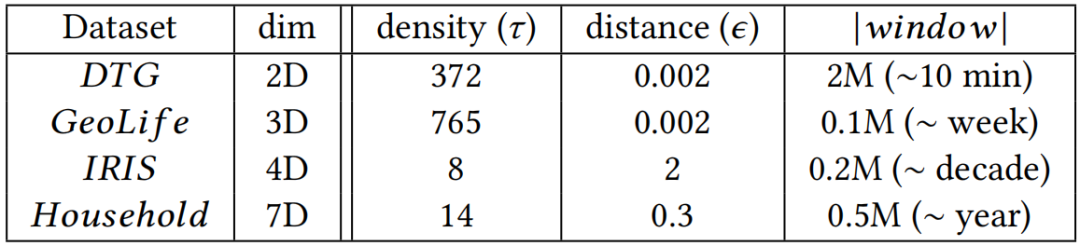
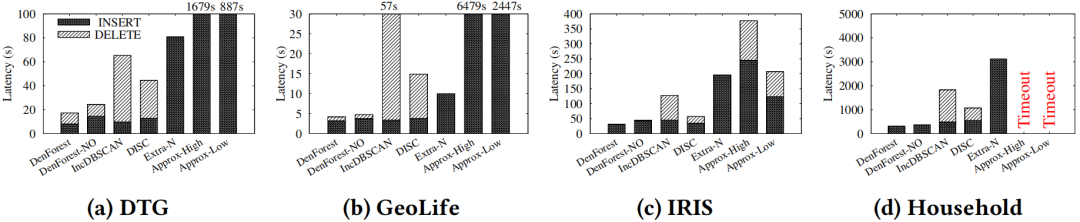
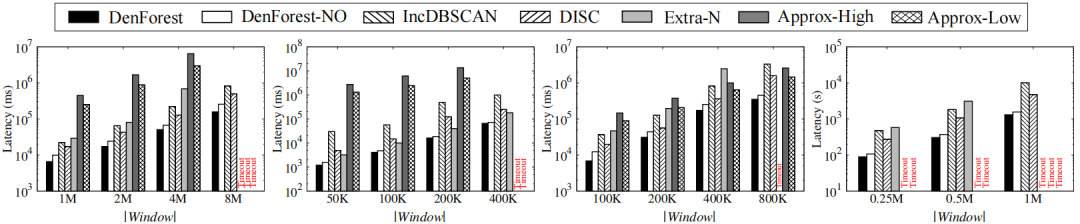

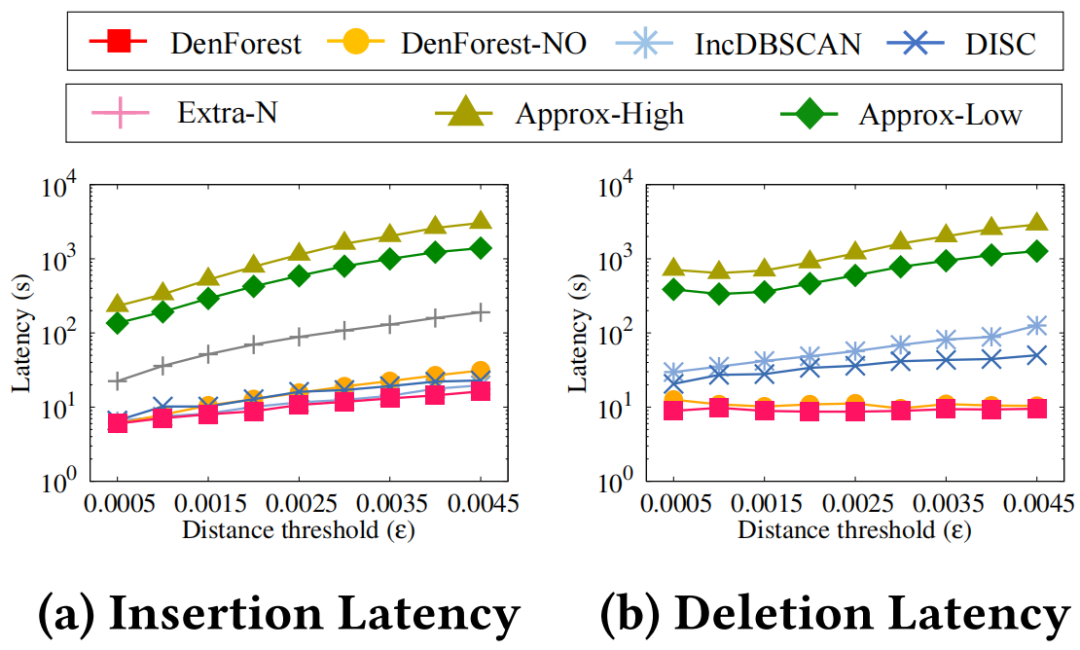

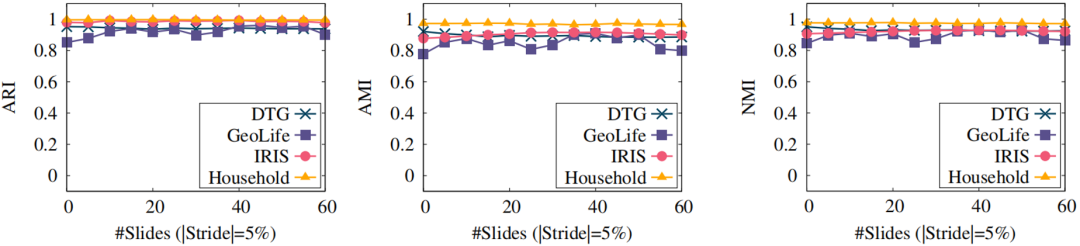
|

文章转载自时空实验室,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
