数据流处理在流数据库中至关重要。现有的工作非常关注数据流中频繁出现的数据。为了更准确地找到这些数据,现有工作往往需要过滤掉非频繁出现的数据。虽然这些解决方案是有效的,但它们会跟踪所有不常见的数据,并需要多次哈希计算和内存访问,这就增加了内存和时间开销。那么如何减小这些开销呢?本次为大家带来数据库领域顶级会议SIGMOD的论文:《LadderFilter:
Filtering Infrequent Items with Small Memory and Time Overhead》
数据流处理在数据科学的各个领域都非常重要,如入侵检测、推荐系统等。数据流通常是高度倾斜的,也就是说,一些数据项是非常受欢迎的(称为频繁项),而绝大多数数据项是不受欢迎的(称为非频繁项)。许多重要的任务都关注于频繁项,比如寻找出现频率最高的k个数据项(top k问题)。在这些任务中,大量非频繁项消耗了太多的内存,从而降低了准确性。Sketch作为一种误差小的紧凑数据结构,在数据流处理中具有广阔的应用前景。它的速度是恒定的:每次插入都只需要进行几次哈希计算和内存访问。为了满足这些更依赖于频繁项的任务,一个被广泛认可的方法是利用Sketch来过滤掉非频繁项。理想情况下,我们会想要过滤掉所有非频繁项。然而,一开始,每一条数据都是非频繁的,在足够长的时间后可能会变得频繁。数据流的大容量和高吞吐量使得在内存和时间有限的情况下保持所有数据的频率是不现实的。因此,论文的目标是在保证低内存和时间开销下,大致剔除非频繁项。过滤非频繁项的现有工作包括ColdFilter[1]和LogLogFilter[2]。Cold Filter使用一个2层CU sketch(一种经典的计数sketch)来记录每条数据的频率,并设置一个阈值来分离频繁项和非频繁项。插入项目时,ColdFilter会将其插入CU sketch中并查询其频率,查询得到的频率超过预先设定的阈值的数据项将被认为频繁项。为了扩大ColdFilter的过滤范围,LogLogFilter用LogLog结构替换CU sketch。ColdFilter维护了所有不频繁项的频率,导致了不必要的内存开销。ColdFilter还需要多次散列计算和内存访问(6次或更多),从而导致相当大的时间开销。LogLogFilter继承了ColdFilter的限制。为了降低内存和时间开销,论文设计了一种新的概率算法称为LadderFilter。根据观察,有些数据项不太可能成为频繁项,LadderFilter的关键技术就是及时丢弃掉这些数据项。论文还提出了一种基于SIMD的方法来优化LadderFilter。为了更好地说明观察结果,作者首先定义了以下术语:active, inactive, promising以及unpromising items。如果某条数据未出现在最近的时间窗口中,我们称之为inactive item,否则称之为active item。当某个active item变得inactive时,1) 如果它的频率很低(比如小于5),则它被称为unpromising item,2) 它的频率适中(比如在5-30之间),则它被称为promising item。论文研究了多个真实数据集,发现当某一项长期保持unpromising时,它基本上很难成为频繁项。图 1是一个真实IP跟踪数据集的实验结果,可以看出,假如我们认为一个频率小于5的inactive item是unpromising item。当频繁项目的阈值为256,滑动窗口大小为10k(绿色折线)时,只有0.1%的unpromising item成为频繁项。当滑动窗口大小超过100k时,该数字将减小到0。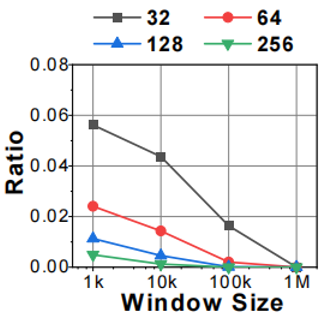
图1 unpromising
item变为频繁项的比率,不同颜色的曲线代表频繁项的不同阈值
基于以上观察,论文设计了LadderFilter,其关键技术是尽早丢弃LadderFilter中的unpromising item。LadderFilter的数据结构类似于由多个LRU队列组成的阶梯(见图 2)。对于队列i,它有一个低阈值Tilow当一个公共的高阈值Thigh。当某条数据项的频率高于Thigh时,它被视为频繁项,移出队列。当其频率小于Tilow时,被视为unpromising item,否则视为promising item。频繁项被发送到专门的Sketch记录下来,unpromising item被简单地丢弃。Promising item将被插入到上层队列,这样一来,promising item有了新的一次机会成为频繁项。如果该项在上层队列中增长得快并超过Thigh,它将成为一个频繁项;如果它增长得太慢(小于Tlow i+1),它将被认为是一个unpromising
item并被丢弃;否则,它仍然是一个promising item,并将进入队列i+2.
图 2 LadderFilter工作流
在本节中,本文将介绍LadderFilter的数据结构和操作。首先是LadderFilter的基础版,它实现了较高的内存效率。然后是一个优化版的LadderFilter,其时间效率得到了提高。最后介绍如何利用SIMD来加速LadderFilter。图 3是LadderFilter的基础版,LadderFilter包含λ个LRU队列,第i个队列包含li个格子。每个格子记录数据项的ID,频率和时间戳信息。每个队列对应一个低阈值Tilow以及一个统一的高阈值Thigh。低阈值是随着i递增的,即T1low<T2low<…<Tλ-1low< Tλlow =Thigh。情况1:e已经在某个队列中,LadderFilter将其频率增加1,并将对应的时间戳更新为当前的时间戳。如果其频率超过了Thigh,LadderFilter将其视为频繁项。情况2:如果e没有被记录过,我们将其插入第一个队列Q1。如果Q1没有满,LadderFilter将其频率置为1,并更新对应的时间戳。否则,LadderFilter将最近最少访问的数据项eLRU移出Q1,再将e插入Q1。如果eLRU的频率超过了Tilow,则其被视为promising item,LadderFilter会将其插入下个队列Q2。插入Q2的过程与Q1类似,以此递推,Qλ会直接丢弃对应的eLRU,而不是将其插入下一个队列。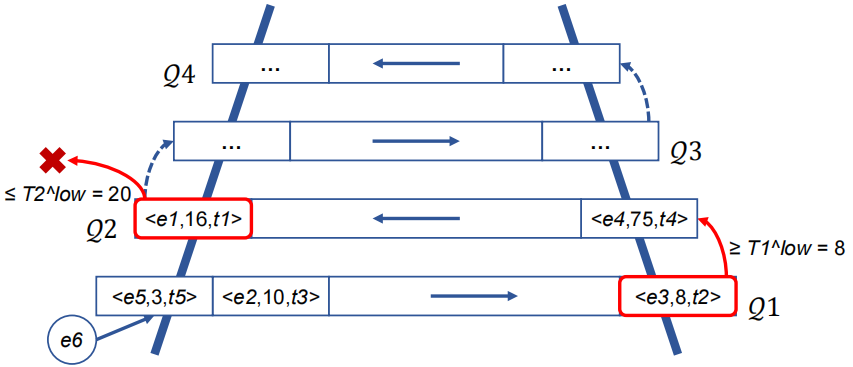
图3 基础版LadderFilter的一个例子
图 3是LadderFilter的基础版本的一个例子,它包含了4个LRU队列Q1,Q1,Q3,Q4。其中Q1,Q2的低阈值分别是8,20。假如在时间戳t7时插入e6,首先判断e6并未插入过LadderFilter,因此首先将其插入Q1,由于Q1已满,LadderFilter将最近最少访问的e3移出队列,并将e6记录进Q1。由于e3的频率=8>= T1low=8,因此e3被视为promising item,将其插入Q2。Q2同样已满,因此Q2中最近最少访问的e1会被移出队列,由于e1的频率=16< T2low=20,因此e1被直接丢弃。内存友好的方案:不使用额外的数据结构。在寻找某个数据项时,会扫描整个队列。但是,该方案时间复杂度较高。时间友好的方案:使用哈希表来定位传入的数据,并使用双向链表来维护数据的到达顺序。然而,这将消耗大量额外的内存。综上所述,上述两种方法要么很耗时,要么很耗用内存。相比之下,LadderFilter的设计目标是以一种同时优化内存和时间的方法来实现LRU队列。论文提出的方法是通过近似地实现LRU来达到这个设计目标。幸运的是,精确的LRU和近似的LRU对LadderFilter几乎没有性能差异。优化版本将基础版的LRU队列替换成一个LRU桶数组,每个数组包含wi个桶。记Qi[j]为第i个桶数组的第j个桶,每个桶包含了c个格子(c*wi=li)。每个桶数组同时关联了一个哈希函数hi(.)(0<=hi(.)<wi),该函数将数据映射到对应的桶。当要将数据e插入桶数组Qi时,LadderFilter会首先计算hi(e)定位到对应的桶Qi[hi(e)],插入过程与基本版本类似。如果该桶已满,LadderFilter会将该桶中最近最少使用的数据项踢出。具体流程为:LadderFilter会扫描整个桶,并找到最近最少使用的数据项,将其移出桶。如图 4所示,该LadderFilter包含了两个桶数组,其中Q1包含了10个桶,Q2包含了2个桶。当在时间戳t6插入数据e2时,首先计算两个hash函数h1(e2)=1,h2(e2)=1来找到e2在各个桶数组中对应的桶地址。可以发现e2已经被记录在了Q1中,因此,将它的频率加1变成11,并更新时间戳为t6。此时e2的频率已经超过Thigh=10,因此,它被视为频繁项。若在时间戳t7入数据e6,首先计算两个hash函数h1(e2)=10,h2(e2)=6。可以发现e6并没有被记录在任何桶数组内。因此,首先将e6插入Q1[10]。可以发现桶Q1[10]已满,因此将该桶内的最近最少项e3踢出。由于e3的频率高于Q1对应的低频率,因此接着将e3插入Q2。可以发现桶Q2[6]依然是满的,此时需要将Q2[6]中的最近最少项e1移出队列,由于Q2是LadderFilter中的最后一层,因此e1被直接丢弃。
图4 优化版本的一个例子
优化版本的LadderFilter已经有了良好的内存和时间效率,然而在操作过程中我们仍然需要存储和比较时间戳,导致时间和内存上的开销。基于此,论文使用SIMD指令加速桶的插入。对于每个桶,维护每个数据项的ID和频率,但是不维护时间戳信息。为了定位数据项,论文保证数据项是按时间顺序排序的。与基本版不同,当插入一个数据项到对应的桶时,在插入或者更新一个格子后,会进一步根据时间对桶中的项进行排序。假设e是该桶中的第j项,LadderFilter将第j+1个数据项移入第j个格子,第j+2个数据项移入第j+1个格子…第c个数据项移入第c-1个格子,并将e移入第c个格子(即最后一个格子),第1到第j-1个格子保持原顺序。这个版本似乎需要大量的操作,因此速度很慢。然而,它对于SIMD加速来说是理想的操作。为了更好地说明,我们假设每个桶由8个格子组成,每个格子由一个16bit的ID和一个16bit的频率组成。代码 1展示了对ID进行排序操作的具体C++代码(对频率进行排序是类似的)。其想法是利用_mm_shuffle_epi8函数来将ID数组中的每个字节重新排列到正确的位置。论文在重排操作中预先设定了每个字节的顺序。第2行给出了当到达的数据为桶中的第4项时的预设顺序示例。第3行将ID数组转换为一个_m128i指针。编译器把所有的ID加载到一个128位的SIMD寄存器中。第4行使用SIMD指令_mm_shuffle_epi8以适当的顺序重新排列寄存器中的字节。然后,这些ID将被存储到适当的单元格中(1个CPU周期)。总之,使用2个SIMD指令(1个针对ID,1个针对频率)即可进行排序,即2个CPU周期。
代码1 SIMD加速
论文介绍了如何在数据流处理中的四个重要任务中部署LadderFilter。这里我们简单介绍如何用LadderrFilter进行频率的估计。问题定义:给定数据流,返回每个ID对应的数据项的频率。现有方案:CU sketch[3],用于估计频率。一个CU sketch由d个计数器数组组成,并且每个数组都与一个哈希函数关联。当插入数据项e时,CU sketch首先计算d个哈希函数来定位到每个计数器数组中的对应位置。然后,CU sketch将其中最小的计数器增加1,这称为保守更新策略。当查询e的频率时,CU sketch同样通过d个哈希函数定位到对应的位置,然后将映射到的计数器之间的最小值报告为e的频率。应用LadderFilter:可以建立一个LadderFilter来配合CU sketch。LadderFilter将被用来防止非频繁项被插入到CU sketch中,因为作者认为频繁项的准确性更重要。插入:插入数据项e时,首先插入LadderFilter。如果LadderFilter将e视为一个频繁项,再进一步将其插入到CU sketch中。插入CU sketch的频率取决于e是否是第一次被LadderFilter视为频繁项。如果是第一次,以插入频率Thigh存到CU sketch;否则,以插入频率1发送至CU sketch。查询:查询包含两个步骤。1) 首先查询CU sketch中e的频率。如果其频率不是0,则必须超过阈值Thigh,因为只有频繁项被插入到CU sketch中,2)否则,e是一个非频繁项。然后我们检查e是否在LadderFilter中。如果它被记录在LadderFilter中,返回LadderFilter中对应的频率,否则返回0。实验平台:一台CPU服务器(Intel i9-10980XE)。CPU有三级缓存:64KB L1缓存,1MB L2缓存,24.75MB L3缓存。CPU频率为4.2GHZ,内存频率为3200MHZ。数据集:论文一共使用了3个数据集进行评估,1)IP跟踪数据集:IP跟踪数据集是收集的匿名IP跟踪流。srcIP作为ID。该数据集包含2700万条数据,共有25万条不同的数据。2)WebDocs数据集:WebDocs数据集是一个由web文档集合构建的事务性数据集。该数据集包含3200万条数据,共有95万条不同的数据。3)合成数据集:这两个合成数据集按照Zipf分布生成。两个数据集的偏度分别为0.5和1.0。每个数据集包含3200万条数据,共有100万条不同的数据。评价指标:论文主要包含3个评价指标,1) AAE,平均绝对误差,越低越好;2) F1 score,越高越好,3) 吞吐量(每秒百万操作次数),越高越好。队列数量和大小的影响(图 5(a)-(b)):可以发现,当使用多个队列来寻找top k时,准确性对不同的参数设置并不敏感。如图5(b)所示,在接近最优阈值(50)下,单队列和多队列都获得了较高的准确度;而在其他阈值下(>150)下,使用多个队列的准确性明显高于使用单个队列。如图5(a)所示,在估算数据频率时,趋势正好相反。每个桶的格子数量的影响(图 5(c)):可以发现,当每个桶的格子数超过8时,精度基本上停止增加。每个桶8个格子的F1 score平均比每个桶更多的格子仅低1.35%。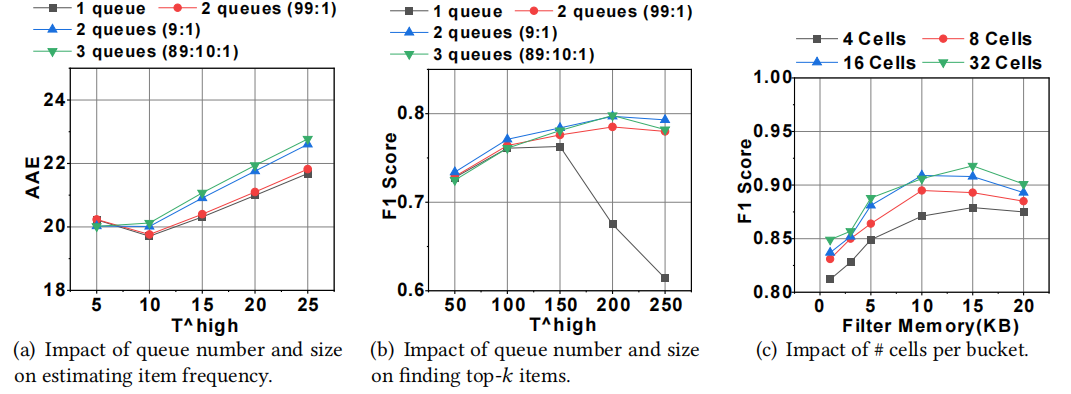
图5 参数实验
准确性(图 6):可以认为LadderFilter将CU sketch的误差减少了多达28.8倍。如图 6所示,LadderFilter的AAE平均分别比CU、CU+CF、CF和CU+LLF低7.43倍、15.2倍和7.29倍。并且LadderFilter在有限的内存下达到了很高的精度。例如,当内存为100KB时,LadderFilter的AAE平均比对比算法分别低7.08、5.95、93.0和49.5倍。原因是LadderFilter丢弃了不常见的数据项,而CF和LLF保留了所有不常见的数据项。因此,LadderFilter消耗更少的内存,并可以更有效地使用内存。吞吐量(图 7):与CF和LLF相比,LadderFilter实现了更高的吞吐量。如图 7所示,LadderFilter的吞吐量分别是CU+CF和CU+LLF的1.17和1.09倍。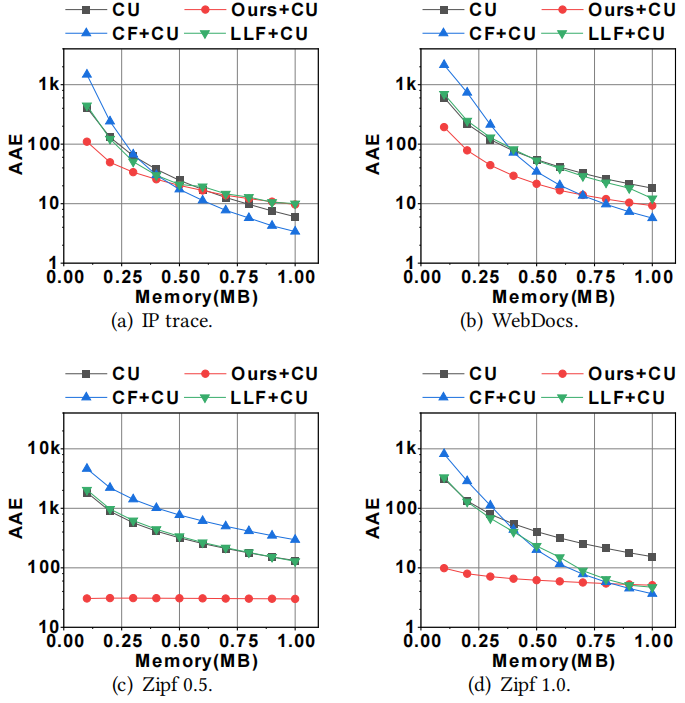
图 6 估计数据项频率的准确性

图 7 四个数据流任务上的吞吐量
本文介绍了LadderFilter,一个用于过滤数据流中不常见的数据项的数据结构。为了保证更高的空间效率,LadderFilter会及时抛弃掉不太可能变得频繁的数据项。为了实现更高的时间效率,论文提出了近似的LRU队列,并使用SIMD进行加速。LadderFilter可以应用在多种sketch上,并显著提高它们的精确度和吞吐量。一个可能的优化方向是使用其它的淘汰策略来替换LRU,比如LRFU。[1]Yang Zhou,
Tong Yang, Jie Jiang, Bin Cui, Minlan Yu, Xiaoming Li, and Steve Uhlig. 2018.
Cold flter: A meta-framework for faster and more accurate stream processing. In
Proceedings of the 2018 International Conference on Management of Data. 741–756.[2] Peng Jia, Pinghui Wang,
Junzhou Zhao, Ye Yuan, Jing Tao, and Xiaohong Guan. 2021. Loglog flter:
Filtering cold items within a large range over high speed data streams. In 2021
IEEE 37th International Conference on Data Engineering (ICDE). IEEE, 804–815.[3] Cristian Estan and George
Varghese. 2002. New directions in trafc measurement and accounting. In
Proceedings of the 2002 conference on Applications, technologies,
architectures, and protocols for computer communications. 323–336.| 重庆大学计算机科学与技术专业在读硕士一年级学生,重庆大学START团队成员,主要研究方向:时空数据管理 | 
|
时空艺术团队(START,Spatio-Temporal Art)来自重庆大学时空实验室,旨在发挥企业和高校的优势,深入探索时空数据收集、存储、管理、挖掘、可视化相关技术,并积极推进学术成果在产业界的落地!年度有2~3名研究生名额,欢迎计算机、GIS等相关专业的学生报考!





