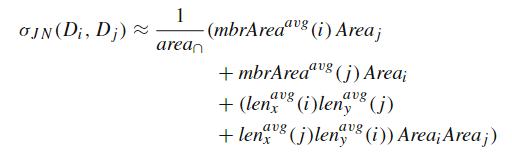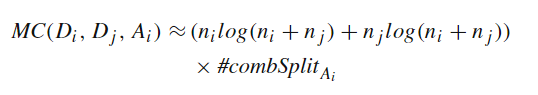空间连接是地理空间应用中的一种关键操作,常用于基于多个数据集的地理信息进行数据分析。由于空间数据处理的固有复杂性,优化空间连接操作对于确保有效查询执行和最小化计算开销至关重要。本次为大家带来数据库领域顶级期刊VLDBJ 2024的文章《A learning-based framework for spatial join processing: estimation, optimization and tuning》。
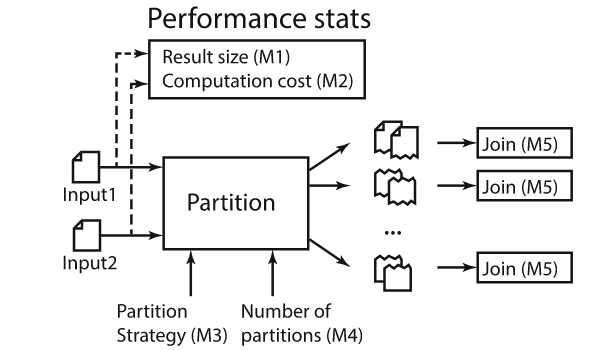
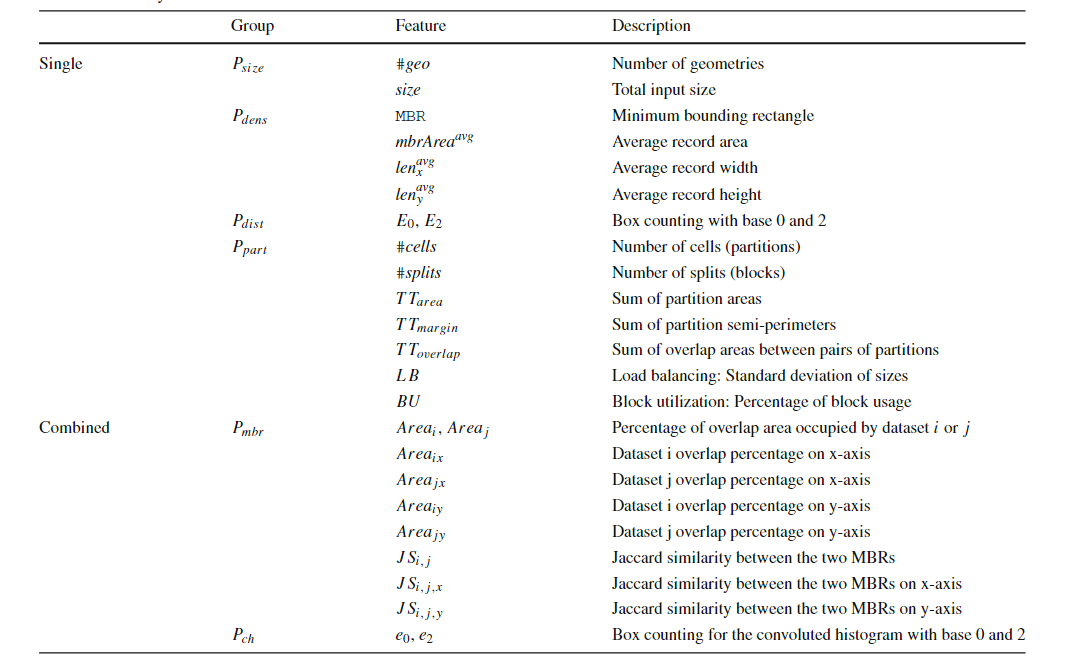
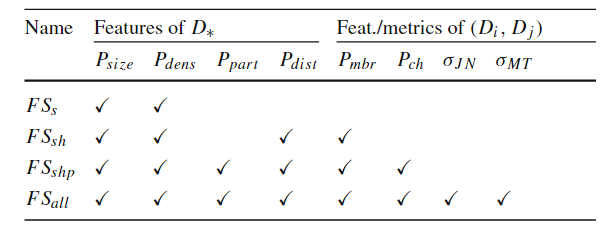
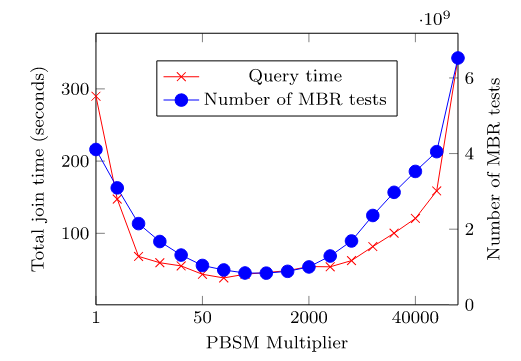
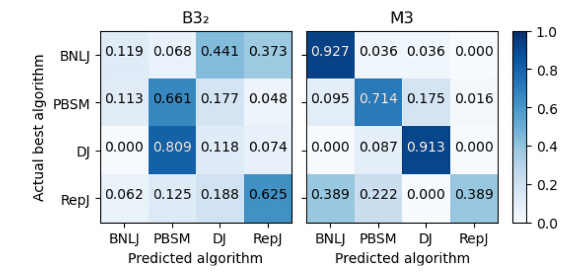
随着空间数据的快速积累,例如卫星图像、社交网络、智能手机和志愿者地理信息(VGI),传统的空间数据库管理系统(Spatial DBMS)技术难以处理这些数据量,促使出现了许多重要的空间数据管理系统,如SpatialHadoop、Hadoop-GIS等。随着空间数据的体量和复杂性的不断增长,有效的优化技术对于充分发挥空间连接的潜力和提高Apache Spark上分析工作流的整体性能至关重要。然而,选择合适的空间连接算法并非易事,这取决于多种因素,包括空间数据集的特性和不同算法的复杂性。因此,该论文提出了第一个基于机器学习的框架,用于空间连接查询优化,该框架可以适应空间数据集的特性和不同算法的复杂性。主要挑战在于如何开发可移植的成本模型,使这些模型一旦训练完成就可以应用于任何输入数据集对,因为它们能够提取重要的输入特征,例如数据分布和空间分区,空间连接算法的逻辑,以及两个输入数据集之间的关系。 文章基于四种基本空间连接算法(块嵌套循环连接(BNLJ)、基于分区的空间合并连接(PBSM)、基于分布式索引的连接(DJ)和重分区连接(RepJ))。并且用其他空间连接算法扩展模型很简单,类似于在分类模型中添加一个新类。由于算法原理不是本研究的重点,如有兴趣可阅读原文。表1 不同连接算法的优缺点 SJML框架包含多个机器学习模型,这些模型协同工作,以提高空间连接操作的性能。SJML包含5个机器学习模型(M1-M5),在开始实际的连接操作之前,SJML需提供一些关于查询性能的估计统计信息。M1估计结果大小,这是一个与算法无关的度量,可用于复杂查询的基数估计。M2根据矩形重叠测试的次数估计每个算法的计算成本。上述这些估计是在空间连接开始之前提供的。空间连接过程本身首先将数据划分为可以并行处理的较小分区。M3为给定的输入选择最有效的分区策略。对于某些分区策略,例如PBSM中使用的均匀网格分区,分区的数量也需要调优,M4用来调优该参数。最后,当涉及到并行处理分区的连接阶段时,SJML提供M5来确定处理每个单独分区的最有效顺序。在本研究中,使用平面扫描连接算法,M5决定是沿着x轴还是y轴扫描几何图形。特征提取是指将空间数据集转换为固定大小的特征向量,提取的特征包括单个数据集统计特征和组合数据集特征,其具体特征和其描述见表2,具体的计算过程可见原文。性能指标是用来评估模型或算法性能的标准。文章涉及到的性能指标有,连接选择性((σJN)用于估计连接操作的结果大小)、MBR测试选择性((σMT)用于估计每种算法的计算成本)、连接运行时间(用于衡量算法在实际执行时的效率)和最佳连接算法(用于衡量对于特定的空间连接查询,应选择哪种算法以获得最佳性能)。 文章的训练数据来源包括来自Spider数据生成器的合成数据与来自UCR-Star的公开真实数据。以表格的形式组织训练数据。训练数据的每一行都包含一个特征列表和输出度量。度量可以是连接选择性、MBR测试选择性、最佳算法或总运行时间(3.2提到的性能指标)。为了突出不同特征的影响,文章定义了四种可能的训练集,如表4所示。M1(连接选择性估计模型):建了一个随机森林回归模型,该模型将提取的特征作为输入,并预测查询的连接选择性。M2(MBR测试选择性模型): 由于每个连接算法都有特定的策略,因此MBR测试的数量是与算法相关的度量。文章建立了四个独立的模型来预测四种空间连接算法(BNLJ, PBSM, DJ, REPJ)的MBR测试选择性。每个模型都是一个随机森林回归器,以提取的特征作为输入,然后预测MBR测试的选择性。M3(算法选择模型):文章提出随机森林分类模型,该模型以特征集作为输入,从运行时间上预测最佳的空间连接算法。M4(调整模型:PBSM乘数):PBSM乘数决定了用于分区的网格(grid)的大小。通过调整PBSM乘数,可以改变每个分区中包含的数据量,从而可能影响算法的负载平衡和整体性能。图2显示总是存在一个PBSM 乘数值,对应的查询运行时间或MBR测试的数量最小。对于每个特定的连接输入,这个最优值是不同的。文章建立一个能够根据输入数据集的特征预测PBSM乘数α的机器学习模型。 图2 PBSM乘数、总运行时间和MBR试验次数之间的相关性M5(调整模型:局部连接操作中的平面扫描轴):平面扫描算法是空间连接操作中的一种常用技术,特别是在处理两个空间对象集合的交集时。在平面扫描算法中,可以选择沿x轴或y轴对空间对象进行排序和扫描。表5显示了在四个不同的连接输入合成对中按x轴和y轴对对象排序时空间连接的运行时间,选择x轴或y轴排序可以使运行时间比另一种方式快三倍。受此观察结果的启发,文章构建一个预测模型M5,它从输入分区中获取特征,然后提出排序标准,保证更好的本地连接运行时间。表5 平面扫描算法按x轴和y轴排序时空间连接的运行时间
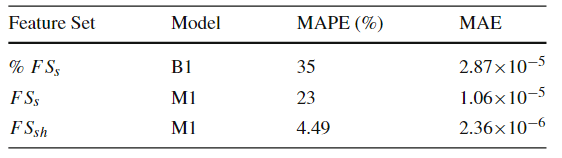
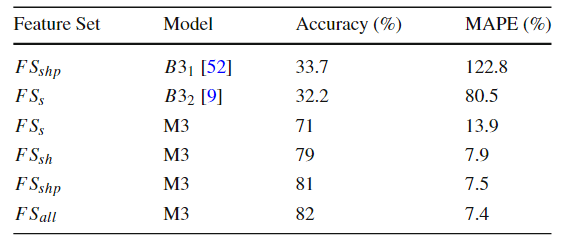
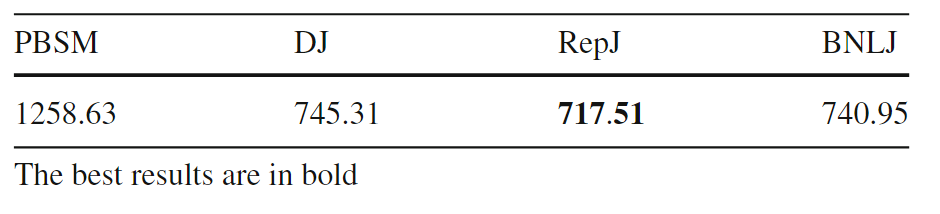
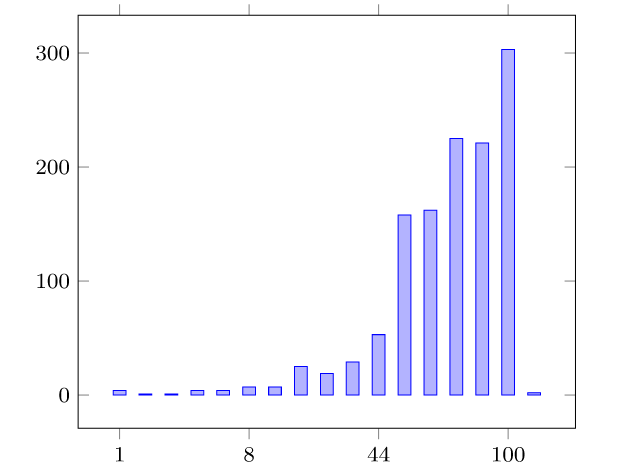
SJML框架包含多个机器学习模型,这些模型协同工作,以提高空间连接操作的性能。SJML包含5个机器学习模型(M1-M5),在开始实际的连接操作之前,SJML需提供一些关于查询性能的估计统计信息。M1估计结果大小,这是一个与算法无关的度量,可用于复杂查询的基数估计。M2根据矩形重叠测试的次数估计每个算法的计算成本。上述这些估计是在空间连接开始之前提供的。空间连接过程本身首先将数据划分为可以并行处理的较小分区。M3为给定的输入选择最有效的分区策略。对于某些分区策略,例如PBSM中使用的均匀网格分区,分区的数量也需要调优,M4用来调优该参数。最后,当涉及到并行处理分区的连接阶段时,SJML提供M5来确定处理每个单独分区的最有效顺序。在本研究中,使用平面扫描连接算法,M5决定是沿着x轴还是y轴扫描几何图形。特征提取是指将空间数据集转换为固定大小的特征向量,提取的特征包括单个数据集统计特征和组合数据集特征,其具体特征和其描述见表2,具体的计算过程可见原文。性能指标是用来评估模型或算法性能的标准。文章涉及到的性能指标有,连接选择性((σJN)用于估计连接操作的结果大小)、MBR测试选择性((σMT)用于估计每种算法的计算成本)、连接运行时间(用于衡量算法在实际执行时的效率)和最佳连接算法(用于衡量对于特定的空间连接查询,应选择哪种算法以获得最佳性能)。 文章的训练数据来源包括来自Spider数据生成器的合成数据与来自UCR-Star的公开真实数据。以表格的形式组织训练数据。训练数据的每一行都包含一个特征列表和输出度量。度量可以是连接选择性、MBR测试选择性、最佳算法或总运行时间(3.2提到的性能指标)。为了突出不同特征的影响,文章定义了四种可能的训练集,如表4所示。M1(连接选择性估计模型):建了一个随机森林回归模型,该模型将提取的特征作为输入,并预测查询的连接选择性。M2(MBR测试选择性模型): 由于每个连接算法都有特定的策略,因此MBR测试的数量是与算法相关的度量。文章建立了四个独立的模型来预测四种空间连接算法(BNLJ, PBSM, DJ, REPJ)的MBR测试选择性。每个模型都是一个随机森林回归器,以提取的特征作为输入,然后预测MBR测试的选择性。M3(算法选择模型):文章提出随机森林分类模型,该模型以特征集作为输入,从运行时间上预测最佳的空间连接算法。M4(调整模型:PBSM乘数):PBSM乘数决定了用于分区的网格(grid)的大小。通过调整PBSM乘数,可以改变每个分区中包含的数据量,从而可能影响算法的负载平衡和整体性能。图2显示总是存在一个PBSM 乘数值,对应的查询运行时间或MBR测试的数量最小。对于每个特定的连接输入,这个最优值是不同的。文章建立一个能够根据输入数据集的特征预测PBSM乘数α的机器学习模型。 图2 PBSM乘数、总运行时间和MBR试验次数之间的相关性M5(调整模型:局部连接操作中的平面扫描轴):平面扫描算法是空间连接操作中的一种常用技术,特别是在处理两个空间对象集合的交集时。在平面扫描算法中,可以选择沿x轴或y轴对空间对象进行排序和扫描。表5显示了在四个不同的连接输入合成对中按x轴和y轴对对象排序时空间连接的运行时间,选择x轴或y轴排序可以使运行时间比另一种方式快三倍。受此观察结果的启发,文章构建一个预测模型M5,它从输入分区中获取特征,然后提出排序标准,保证更好的本地连接运行时间。表5 平面扫描算法按x轴和y轴排序时空间连接的运行时间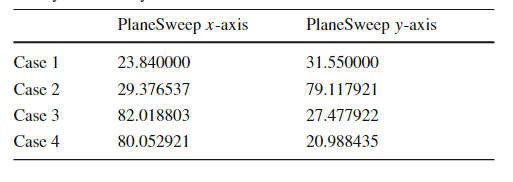 在基于Spark的大空间数据管理系统Beast上实现了四种原始设计的空间连接算法。合成数据使用开源的Spider生成器生成,实际数据从UCR-Star下载,选择了OSM建筑、湖泊和道路数据集,以及US Census线性水、边缘和面数据集。模型在合成数据上进行训练,测试数据包含合成数据和真实数据的混合。Baseline B3 for M3:使用基于规则的模型B31和基于成本的模型B32对于理论模型B1,实验结果如表6(MAPEJS(B1))所示,当应用于均匀分布的数据集,B1准确性较好但当应用于倾斜和非完全重叠的数据集时,性能会下降。对于非均匀数据集,B32在预测最佳或次优连接算法时的准确性会迅速下降(表6ACC(B32))。表6 连接选择性理论模型(B1)和最佳选择算法(B32)的精度一般来说,越复杂的特征将产生更准确的模型。在每个实验中,将特征集FS、FSsh和FSshp应用后续实验中。表7显示了使用特征集FS和FSsh时对连接选择性模型(M1)和基线(B1)的评估。(不使用FSshp是因为分区信息与连接选择性无关)。给定相同的特征集FS,随机森林回归模型M1在MAPE方面明显优于基线B1,提高了12%。对于模型M1,特征集FS、FSsh的不同结果表明具有信息特征的回归随机森林模型可以有效地预测连接查询的连接选择性。 表8显示了使用特征集FS、FSsh和FSshp时MBR选择性(M2)和基线(B2)的效率。由于四种算法中都有一个单独的模型,因此需分别测量它们的性能基线模型B2的MAPE和MAE值几乎是不可接受。相比之下,文章提出的随机森林回归模型M2在MAPE和MAE值上都能得到很好的值。当更多特征输入到模型中时,可以观察到指标的下降趋势(在DJ和REPJ模型有明显的改进)。这一观察结果进一步证实当给定足够的特征来描述输入数据集时,机器学习模型可以优于理论模型。表8 特征选择对MBR选择性估计模型B2和M2的影响表9给出了使用不同特征集时算法选择(M3)和基线(B31和B32)的准确率。结果表明,B31和B32的精度太低,MAPE值不合理时,不能很好地预测最佳算法。它们比完全随机选择略好(完全随机的准确率为25%),其原因是这些模型主要是为均匀分布的数据设计的,而没有考虑到复杂的空间分布。另一方面,所提出的随机森林分类器M3可以提供高达82%的准确率和7.4%的MAPE值。使用FSall特征集的模型产生的精度最高。 图3的混淆举证显示PBSM和REPJ算法的基线(B32)得到了不错的精度(约60%),但对两种算法BNLJ和DJ却效果不佳。为了证明该框架在大型现实世界数据集上的能力,提出“找到世界上所有的交叉道路的问题,可在OpenStreetMap的道路数据集OSM2015/roads上运行一个自连接操作来回答这个问题。使用M3模型表明,就运行时间而言,RepJ是最好的连接算法。之后,我们用给定的输入运行所有的空间连接算法。每种算法的运行时间如表10所示,验证了RepJ实际上是最快的连接算法。 表10不同空间连接算法在OSM2015/roads数据集上的自连接运行时间(秒)固定测试集,并逐渐将训练集从所有可用训练数据的40%增加到100%。图4显示,即使训练集很小,模型在特征集较小的情况下也会表现得更好。还表明添加的连接选择性和MBR选择性有助于提高模型(M3)性能。图4 随着训练集大小的增加,FSshp和FSall特征集在M3的性能PBSM乘数预测是一个回归问题,PBSM乘数的整数作为标签,简单地使用随机森林模型来训练PBSM乘数预测模型。选择基线值等于100,因为这是PBSM乘数最常见的最佳值(如图5)。表11表明,基于学习的模型可以更好地估计出最佳PBSM乘数值,从而缩短空间连接操作的运行时间。
在基于Spark的大空间数据管理系统Beast上实现了四种原始设计的空间连接算法。合成数据使用开源的Spider生成器生成,实际数据从UCR-Star下载,选择了OSM建筑、湖泊和道路数据集,以及US Census线性水、边缘和面数据集。模型在合成数据上进行训练,测试数据包含合成数据和真实数据的混合。Baseline B3 for M3:使用基于规则的模型B31和基于成本的模型B32对于理论模型B1,实验结果如表6(MAPEJS(B1))所示,当应用于均匀分布的数据集,B1准确性较好但当应用于倾斜和非完全重叠的数据集时,性能会下降。对于非均匀数据集,B32在预测最佳或次优连接算法时的准确性会迅速下降(表6ACC(B32))。表6 连接选择性理论模型(B1)和最佳选择算法(B32)的精度一般来说,越复杂的特征将产生更准确的模型。在每个实验中,将特征集FS、FSsh和FSshp应用后续实验中。表7显示了使用特征集FS和FSsh时对连接选择性模型(M1)和基线(B1)的评估。(不使用FSshp是因为分区信息与连接选择性无关)。给定相同的特征集FS,随机森林回归模型M1在MAPE方面明显优于基线B1,提高了12%。对于模型M1,特征集FS、FSsh的不同结果表明具有信息特征的回归随机森林模型可以有效地预测连接查询的连接选择性。 表8显示了使用特征集FS、FSsh和FSshp时MBR选择性(M2)和基线(B2)的效率。由于四种算法中都有一个单独的模型,因此需分别测量它们的性能基线模型B2的MAPE和MAE值几乎是不可接受。相比之下,文章提出的随机森林回归模型M2在MAPE和MAE值上都能得到很好的值。当更多特征输入到模型中时,可以观察到指标的下降趋势(在DJ和REPJ模型有明显的改进)。这一观察结果进一步证实当给定足够的特征来描述输入数据集时,机器学习模型可以优于理论模型。表8 特征选择对MBR选择性估计模型B2和M2的影响表9给出了使用不同特征集时算法选择(M3)和基线(B31和B32)的准确率。结果表明,B31和B32的精度太低,MAPE值不合理时,不能很好地预测最佳算法。它们比完全随机选择略好(完全随机的准确率为25%),其原因是这些模型主要是为均匀分布的数据设计的,而没有考虑到复杂的空间分布。另一方面,所提出的随机森林分类器M3可以提供高达82%的准确率和7.4%的MAPE值。使用FSall特征集的模型产生的精度最高。 图3的混淆举证显示PBSM和REPJ算法的基线(B32)得到了不错的精度(约60%),但对两种算法BNLJ和DJ却效果不佳。为了证明该框架在大型现实世界数据集上的能力,提出“找到世界上所有的交叉道路的问题,可在OpenStreetMap的道路数据集OSM2015/roads上运行一个自连接操作来回答这个问题。使用M3模型表明,就运行时间而言,RepJ是最好的连接算法。之后,我们用给定的输入运行所有的空间连接算法。每种算法的运行时间如表10所示,验证了RepJ实际上是最快的连接算法。 表10不同空间连接算法在OSM2015/roads数据集上的自连接运行时间(秒)固定测试集,并逐渐将训练集从所有可用训练数据的40%增加到100%。图4显示,即使训练集很小,模型在特征集较小的情况下也会表现得更好。还表明添加的连接选择性和MBR选择性有助于提高模型(M3)性能。图4 随着训练集大小的增加,FSshp和FSall特征集在M3的性能PBSM乘数预测是一个回归问题,PBSM乘数的整数作为标签,简单地使用随机森林模型来训练PBSM乘数预测模型。选择基线值等于100,因为这是PBSM乘数最常见的最佳值(如图5)。表11表明,基于学习的模型可以更好地估计出最佳PBSM乘数值,从而缩短空间连接操作的运行时间。 表11 PBSM-Multiplier模型比较
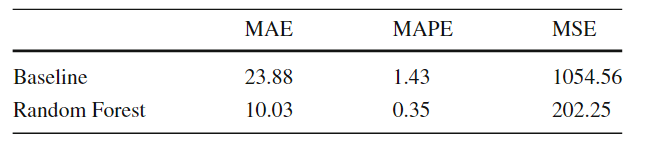
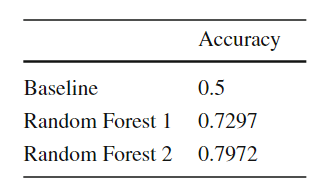
基于生成的训练数据建立两个随机森林分类模型。Random Forest1是基于FSsh特征构建的。第二个模型利用FSsh特征和两个分区在x轴或y轴上的相交百分比和Jaccard相似度特征构建。随机选择作为基线,显然其精度为0.5。从表12的实验结果可以看出,使用附加特征构建的第二个Random Forest模型的准确率最好。文章介绍了第一个基于机器学习的空间连接查询优化框架,该框架既能适应空间数据集的特点,又能适应不同算法的复杂性。主要的挑战是如何开发便携式的成本模型,一旦训练可以应用于任何一对输入数据集,因为它们能够提取重要的输入特征,如数据分布和空间划分,空间连接算法的逻辑,以及两个输入数据集之间的关系。该系统为数据定义了一组可以有效计算的特征,以捕捉空间连接的复杂方面。然后,它使用这些特征来训练五个机器学习模型,这些模型用于识别最佳的空间连接算法。前两个是回归模型,用于估计空间连接性能的两个重要度量,它们充当成本模型。第三个模型选择用于空间连接的最佳分区策略。第四和第五种模型进一步调整两个重要参数——分区数量和平面扫描方向,以获得最佳性能。在大规模合成数据和实际数据上的实验表明,该模型比基线方法更有效。
| 重庆大学计算机科学与技术专业2024级硕士生,重庆大学Start Lab团队成员。 | 
|
重庆大学时空实验室(Spatio-Temporal Art Lab,简称Start Lab),旨在发挥企业和高校的优势,深入探索时空数据收集、存储、管理、挖掘、可视化相关技术,并积极推进学术成果在产业界的落地!年度有3~5名研究生名额,欢迎计算机、GIS等相关专业的学生报考!
图文|苏赛男
编辑|李佳俊
审核|李瑞远
审核|杨广超