开源项目FastLanes旨在通过多种方式改进Parquet、ORC和列式数据库格式等大数据格式。本次为大家带来已发表在VLDB上的论文《The FastLanes Compression Layout: Decoding >100 Billion Integers per Second with Scalar Code》。在文章中,作者加快了常见轻量级压缩(LWC)方案DICT、FOR、DELTA 和RLE的解码速度。
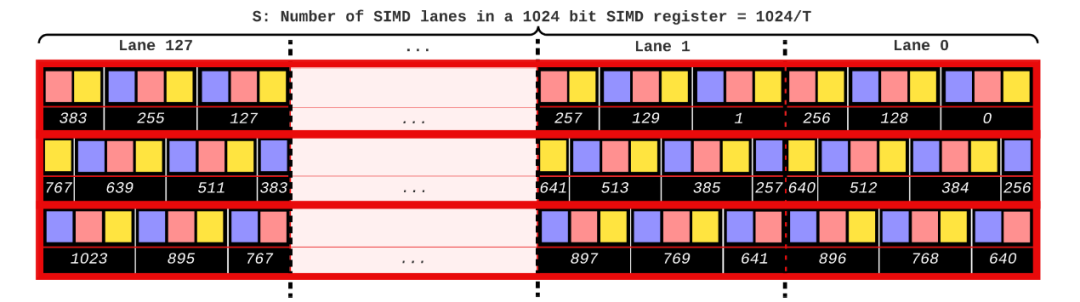
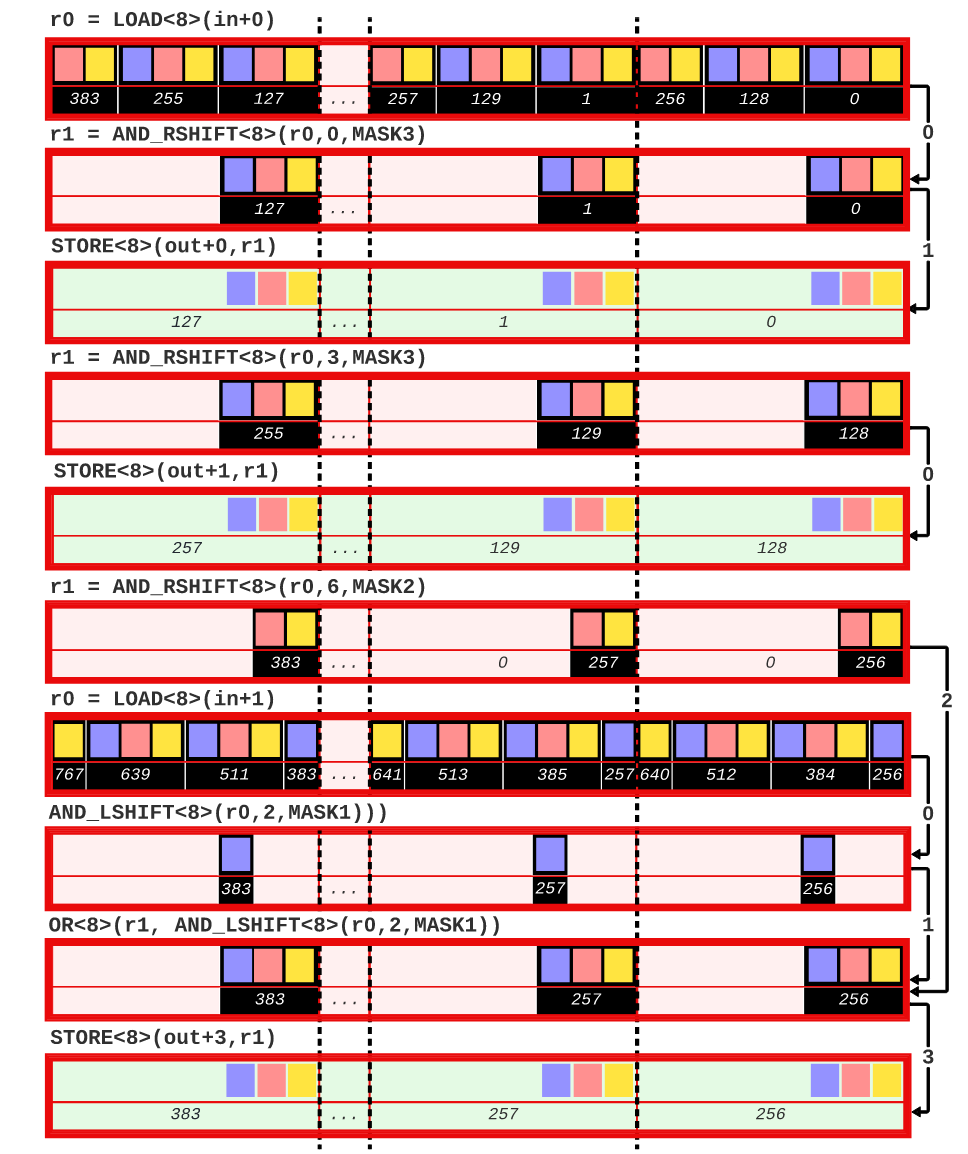
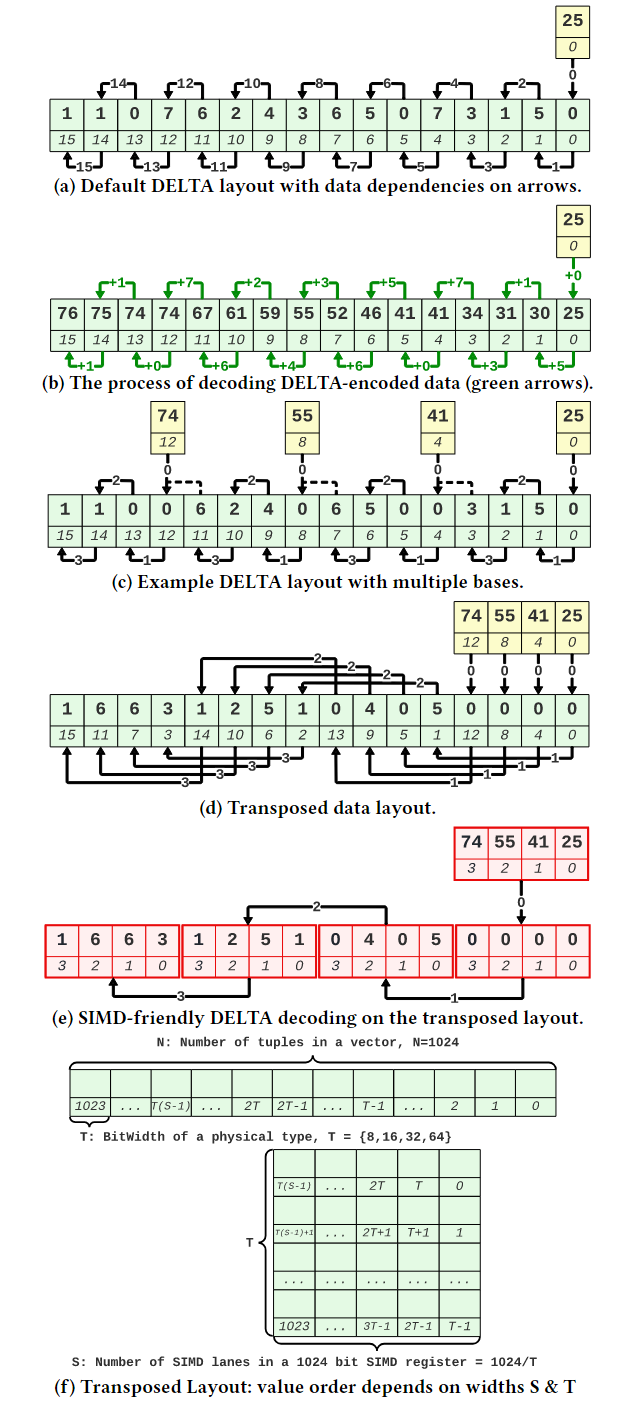
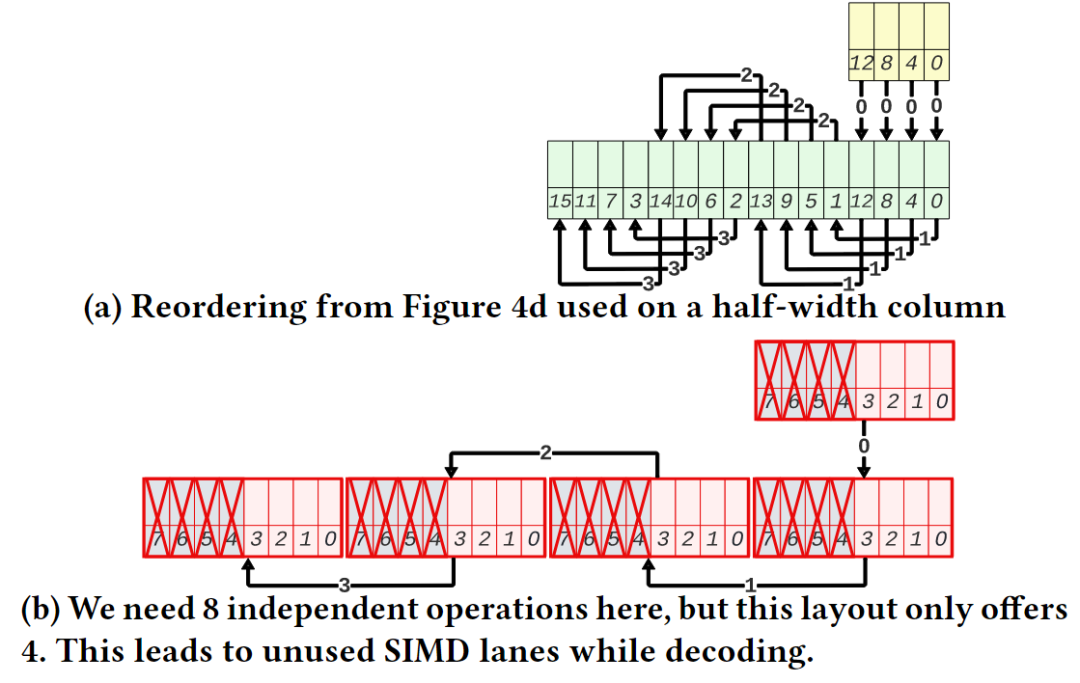
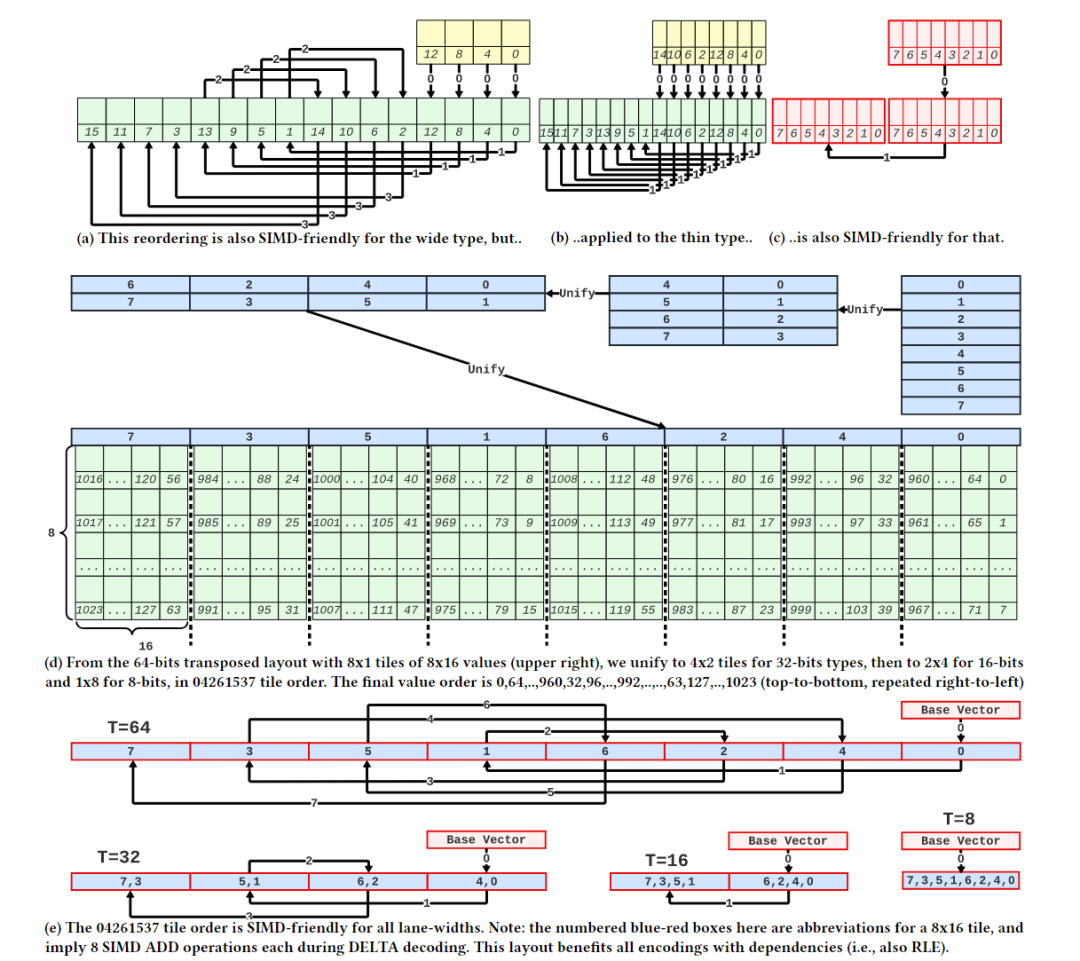
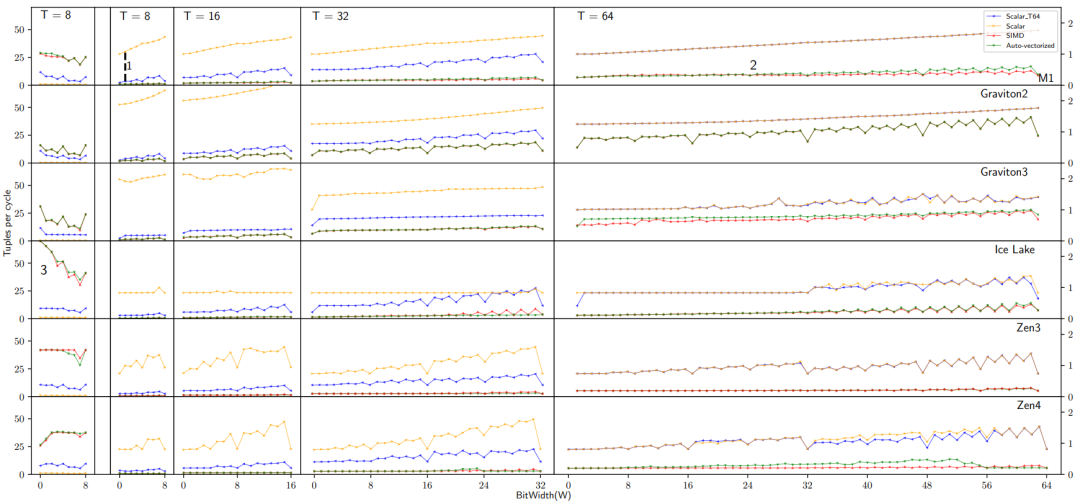
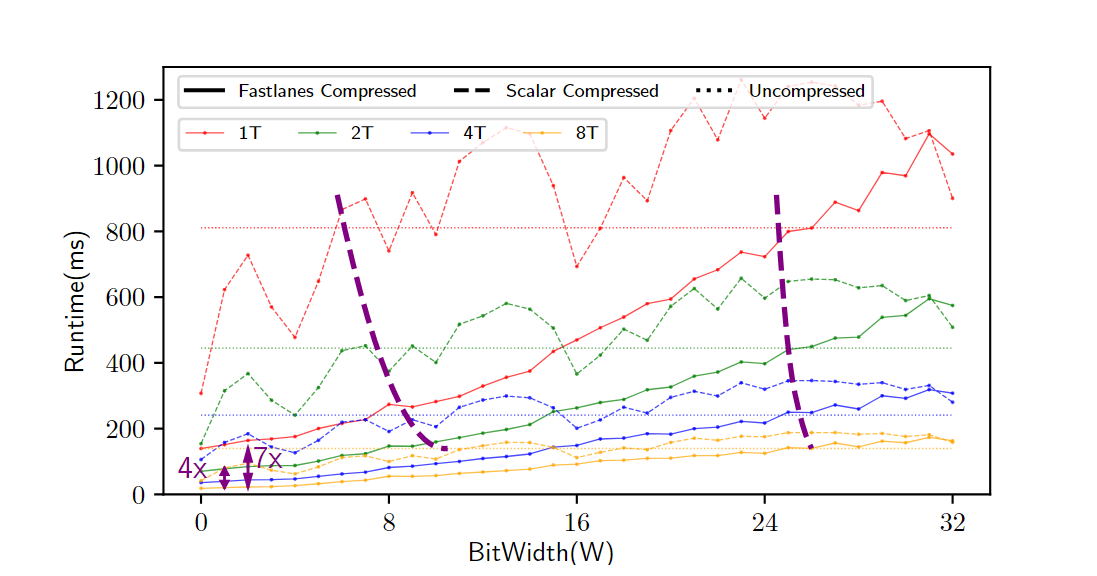
分析数据系统通常使用列存储来存储数据,这样可以使查询跳过不需要的列,从而节省网络、磁盘和内存带宽。列存储通常比行存储更紧凑,因为使用了压缩技术。矢量化执行是一种广泛采用的查询执行设计,其中查询表达式中的计算工作是在大小为1024的“向量”数据块上执行的。这些数据块通过预编译函数在循环中执行简单操作,从而分摊了函数调用开销,并且允许编译器使用技术(如循环流水线、代码移动和自动矢量化)来优化这些函数。下一代数据库系统中的扫描操作不应该直接地将列解压缩为对应的SQL类型,而是解压缩为能够由查询运算符处理的最小类型。现代系统支持压缩向量,其中数据部分压缩但仍支持随机访问。FastLanes是由CWI发起的一个项目,旨在为下一代大数据格式打下基础。它引入了一种新的压缩列存储数据布局,增加了数据并行解码的机会,通过这种方式提高了性能。在FastLanes项目中,作者重新设计列式存储,以在数据解码中暴露更多的独立性,使未来的查询引擎更好地利用现代硬件中的数据并行性。如表1所示,文章为六个挑战提供了解决方案。表一: FastLanes如何解决大数据格式中有效数据并行解压缩所面临的挑战 然而,由于FastLanes解码比以前的LWC方案快得多,因此解码功能可以成为STORE绑定,即使只存储到L1缓存中。文章展示了将位解包内核与FOR DELTA/RLE/DICT的解码内核融合在一起可以提高性能,因为这节省了中间的STORE+LOAD。现有的SIMD解码算法及其数据布局通常以特定的寄存器宽度为目标,考虑到 4 路交错布局,它在 4 个SIMD通道之间分配位打包的元组。这种布局避免了跨通道PERMUTE或BITSHUFFLE指令,如果比特连续打包,则需要这些指令。这种布局虽然对 128 位SIMD寄存器上的 4 个 32位值 CPU的解包效率高,但对于 256 位或 512 位寄存器而言并行性不够。为此,有人提出了 8 路和 16 路交错格式。为了在某些 ISA 开始支持更宽的 SIMD 寄存器时抢先改变数据格式,FastLanes 瞄准了仍未出现的寄存器宽度,即1024 位。图 1 显示了在整数可由3比特编码的示例情况下的交错比特分组布局(𝑆 =3)。为了最大限度地提高解码性能,文章使用了与之相适应的最小通道宽度,即 8 位(𝑇 =8),因此FLMM1024字中有128个(𝑆=1024/𝑇 =128)通道。当引入新的 SIMD ISA 时,通常会出现两种类型的不对称性:(i) 引入了在较窄的 ISA 中不存在的新运算符, (ii) 引入了更宽的寄存器,但并不是所有在较窄寄存器上存在的运算符都被 (最初) 支持在更宽的寄存器上。依赖这些运算符的数据布局在大部分硬件平台上的高效性就成为了一个问题,特别是对于作为二进制文件(预编译)分发的数据系统来说。随着ISA的异构性显著增加,为了支持异构 ISA,FastLanes 只使用简单的运算符,如加载/存储、左/右移位、与/或/异或、加法和设置指令;这些指令适用于所有的轨道宽度,如列表 1 所示。列表2显示了将3位(𝑇 =3)代码解包为8位(𝑇 =8)整数的实现过程。文章没有手动编写这样的代码,而是对所有 1 ≤W ≤ 64、T∈{8,16,32,64},其中W<𝑇的代码进行静态生成。 列表2:FLMM1024 SIMD中用于𝑇=8和𝑊=3的交错位解包内核。图 3 显示了算法的运行情况:在 10 条指令中,解包了384个值。在这个解包内核上,英特尔 AVX512 CPU 的速度达到了惊人的每周期70个值,即在一个2GHz 内核上每秒解包1400亿个值。鉴于每个值为3位,这需要52GB/s的速度,接近 RAM带宽极限。但实际上,查询流水线在运算时,每个值至少要花费几个周期,因此流水线运行速度要慢100倍;但在这种解包速度下,解压扫描时间可以忽略。 相邻值之间的依赖关系不适合于SIMD操作,因为相邻值最终会位于相邻的处理单元中。图4a显示的默认布局存在这个问题。DELTA解码所需的加法操作是跨处理单元的:假设图4b中的值是32位的,那么将位置0和位置1处的值相加对应于不同的处理单元。在这些图中,黄色框表示基准值。这些基准提供了开始DELTA解码的入口点。在FastLanes中,允许以1024元组的粒度开始解码。基准值将被找到在压缩的列式块的头部。但是,图4c显示了四个基准的概念,而不是为每个向量定一个基准。这允许从位置0、4、8和12开始解码。然而,这仍然没有解决跨处理单元的问题。图4d显示了“转置”布局,它以无序方式存储值。这里的前16个值的顺序是0、4、8、12、1、5、9、13、2、6、10、14、3、7、11、15。图4e显示了形成最佳的128位SIMD处理:只需要4个加法操作。 作者称这种重新排序为换位,因为主要思想是将值列切成 SIMD 寄存器大小的块,并将这些块垂直放置在彼此下方,如图 4f 所示。在FLMM1024寄存器的情况下,这意味着该矩阵恰好有𝑇行𝑆列;其中𝑇是值的位宽度,𝑆是寄存器中值的数量。作者认为,可以在数据库扫描的上下文中改变元组顺序。关系代数是基于集合的,查询操作的语义不依赖于顺序,因此如果元组的顺序与插入顺序不同,它们通常可以以它们到达的任何顺序进行处理。 在转置布局中,元组的顺序取决于𝑇。这在数据库扫描中会有问题:关系表由多列组成,不同列的宽度可能不同。然而,当重新排序元组时,应该对所有列使用相同的顺序,因为扫描需要创建一致的元组流。如图5所示,将图4d中的重新排序应用于宽度减半的数据类型时,较薄类型的独立工作量不足。文章示例中,宽数据类型是32位,因此4个值适合一个128位的SIMD寄存器。然而,当按照这种顺序放置16位整数列时,作者发现只能利用四个处理单元,而不是8个。这种情况下,可以通过使用与两种宽度列都能很好配合的不同排序方式来解决问题,如图6a-c所示。统一转置布局为所有处理单元宽度提供了通用解决方案,以8x16的转置块为基本构建块,每个1024元组向量有八个这样的块。对于不同宽度的数据类型,布局采用了不同的处理方式,以确保每个处理单元都得到了充分利用。这种布局的优势在于能够适应不同宽度的数据类型,提供了灵活性和效率。图5:针对一种数据类型设计的转置布局和结果值重排序对较少的数据类型不合适 FastLanes-RLE采用经典的RLE对值序列进行编码,编码结果是(value, length)元组。解码需要两个嵌套循环:一个循环迭代元组,内部循环迭代长度。循环在定义上是标量的,内部循环将受到短长度时分支错误预测的影响。到目前为止,对RLE的最佳SIMD加速是当运行长度很大时,即未压缩的运行远远大于SIMD寄存器时。在这种情况下,可以将SIMD寄存器的所有处理单元设置为常量值,并通过处理单元数量减少存储指令的数量。文章提出了一种新方案Fastlanes-RLE,将RLE映射到DELTA,并支持使用统一转置布局重新排序存储,针对的是像Velox和DuckDB这样的系统,这些系统更喜欢将解码后的RLE表示为紧凑的在途字典向量,而不是完整地解压缩向量。索引向量在每次新的运行开始时单调递增。对于具有许多短运行的向量,FastLanes-RLE使用16位索引,否则使用8位索引。这些索引向量仅使用1位来进行DELTA编码。对于8位索引,基本存储可以使用3位填充,每个值增加0.375位的存储空间,使得压缩比优于经典的RLE,达到平均运行长度为12。对于更长的平均运行长度,使用0位DELTA编码,将索引向量设置为0,并通过异常机制插入1。 文章以四种不同的方式实现了位解压和解码到𝑇 = {8, 16, 32, 64}的结果列中:标量(Scalar)、标量_T64(Scalar_T64)、SIMD和自动向量化。SIMD实现使用显式的SIMD指令。需要注意的是,对于ARM64架构,所有的SIMD实现都基于NEON指令。这是因为在Graviton3上的实验表明,SVE比NEON慢。最后,自动向量化的实现与标量实现相同,唯一的区别是没有禁用自动向量化。这些微基准测试旨在表征纯CPU成本,并对一个单独的向量进行30M次解压缩。位解压缩。在图7中可以看到1024位交错的打包数据对标量解码甚至没有任何影响,性能与朴素的“水平”位打包布局相同。但是,只有交错布局提供了标量_T64并行解码多个通道的机会,使其在8位值上比标量快8倍。图8显示了FastLanes解码的高速度:多亏了SIMD,它在所有平台上的性能明显优于标量:对于8位数据类型,提高了40倍至70倍,对于64位数据类型提高了3倍至4倍。可以看出Gravitons具有较弱的SIMD;这在64位数据类型中尤为明显。苹果M1也只有128位的NEON,但显然具有更多的指令级并行性。更宽的SIMD并不总是意味着更高的性能:尽管支持AVX512,Zen4并不比Zen3快。如果CPU使用两个AVX2(256位)单元执行一个AVX512指令,则这是可以预期的。FastLanes代码暴露的缺乏依赖性和数据并行性机会,使其从总CPU执行能力中获益。图8突显了以下几点:(1)对于不同的𝑇值,Scalar_T64确实比Scalar快64𝑇倍;(2)clang++可以自动向量化我们的标量代码,与显式的指令性能相匹配,表示为SIMD;(3)FastLanes可以每周期解压70个8位类型的元组,其中SIMD并行性是最大的。统一的转置布局。图9显示,统一的转置布局的思想是重新排序元组以打破顺序依赖性,这也使Scalar_T64代码路径受益。就标量性能而言,M1在时钟对时钟方面领先于Ice Lake。值得注意的是,Graviton和Zen3在8位和16位数字上的标量加法性能要低于32位和64位数字。Gravitons再次显示出弱的SIMD性能。性能可以再次非常高,例如在更快的平台上,8位DELTA可以达到每周期>40个元组。大多数DELTA解码用于较大的数据类型,但FastLanes-RLE在16位通道中非常快地进行了1位解码。由于位解压缩和FastLanes解码使用无依赖性的指令,列内容根本没法影响性能。只有位宽才有影响,因此评估所有位宽。 图9:对于所有位宽和平台的FastLanes DELTA 解码融合位打包和解码。文章为所有位打包宽度𝑊和解包类型宽度𝑇 ≤ 𝑊生成的116个位解压缩核心可能会与DELTA、FOR、DICT和FastLanes-RLE的解码核心融合在一起,形成一个既进行解压缩又进行解码的单一核心。融合的好处在于可以节省位解压缩结束时的STORE指令和解码开始时的LOAD指令。图10显示,融合提高了解压缩速度。对于解码到压缩向量的情况,对于DICT和FOR,不需要融合对于将DELTA解码为压缩FOR向量,可以使用融合;然后需要的是保留每个向量的MinMax统计数据,并在解码之前从基数中减去Min值。图10:将1024位交错位打包与解码(FOR)融合可以提高性能文章还在实验性的矢量化查询处理器Tectorwise中集成了FastLanes,运行了一个完整的查询流程。作者创建了一个名为TAB的表,其中包含一个名为COL的单列,该列包含10×228个uint32整数值(10GB),并在IceLake平台上对查询SELECT SUM(COL) FROM TAB进行了基准测试。图11显示了该查询的性能,具体取决于列中值的域,该域是从范围[0-2𝑊⟩中均匀随机生成的。作者运行了这个未经修改的Tectorwise查询,从一个uint32数组中读取COL,并运行了两个修改过的版本(FastLanes和Scalar),这两个版本扫描了一个压缩的COL,该列在每个值中进行了𝑊位的位打包。在所有情况下,数据都存储在RAM中。可以看出,尽管需要解压缩,但从FastLanes读取通常会使查询更快,因为查询需要的RAM带宽更少。并行执行增加了RAM瓶颈:使用8个线程,可以看出与未压缩相比,端到端性能提高了多达7倍(与Scalar相比提高了4倍)。FastLanes将查询变得更快的临界点从具有大于4倍压缩比的数据(Scalar)转移到几乎任何数据。 图11:Ice Lake上各种COL位宽度和线程(T)的SELECT SUM(COL) FROM TAB运行时间。FastLanes的关键思想是消除顺序解码依赖关系,将元组重新排序为特殊的“04261357”8x16平铺顺序。FastLanes能够用简单的操作在一个虚拟(且具有未来可扩展性)的1024位寄存器上使用所有常见的LWC解码方法,这种方法可以高效地映射到现有的SIMD指令集。与孤立地看待数值解码不同,文章将其视为数据库系统中的一部分,其中解压缩是其中的一部分,应该与硬件资源限制保持平衡。在这种情况下,列不是孤立地完全解码的,而是增量地作为查询的源,进一步处理数据,并且扫描解码多个不同的列。FastLanes还具有一个标量代码路径,并且与朴素的按位打包的顺序存储数据相比,它在紧凑数据类型上的数据并行性,甚至加速了标量解码。现代编译器可以完全自动将这个标量代码路径向量化,与显式的SIMD指令相比没有性能损耗,这使得FastLanes非常易于移植。FastLanes的性能优势在于提供更快的解压缩:位解压缩,然后是FOR和DELTA解压缩,通常比朴素的顺序位打包布局提高一个数量级。实验显示了与直接在内存中数组扫描相比,基于FastLanes压缩数据的RAM驻留查询可以更快。
许熠 重庆大学计算机科学与技术(卓越)专业2022级本科生,重庆大学Start Lab成员。主要研究方向:时空数据压缩 | 
|
重庆大学时空实验室(Spatio-Temporal Art Lab,简称Start Lab),旨在发挥企业和高校的优势,深入探索时空数据收集、存储、管理、挖掘、可视化相关技术,并积极推进学术成果在产业界的落地!年度有2~3名研究生名额,欢迎计算机、GIS等相关专业的学生报考!