有损压缩是减小科学数据大小的最有效技术之一,然而传统的试错方法用于配置有损压缩器以找到重构数据质量和压缩比之间的最佳权衡代价高昂。本文是发表在数据库领域顶会ICDE 2022上的《Improving Prediction-Based Lossy Compression Dramatically via
Ratio-Quality Modeling》,文章开发了一个基于预测的有损压缩框架的通用分析比率-质量模型,它可以有效地预见减小的数据质量和压缩比,以及有损压缩数据对事后分析质量的影响。

在当今的科学和工程领域中,基于并行计算机的大规模科学模拟起着重要作用,这类模拟可以生成极大量的数据。尽管当今计算能力的不断增强可以用于运行这些模拟,但管理如此大量的数据仍然是一个挑战。科学数据的压缩被确定为解决这个问题的一种主要数据减少技术。在大规模计算机系统上进行的科学应用,通常使用并行I/O库如HDF5,来管理数据。要让HDF5充分利用有损压缩器,用户必须确定压缩比和压缩数据质量之间的最佳权衡。由于目前没有可用于准确预测/估计压缩质量的分析模型,因此科学应用中有界误差有损压缩器的配置设置依赖于基于领域科学家的试错实验的经验验证/研究。试错方法存在两个显著缺点,首先,这种方法的计算成本极高;其次,确定的配置设置依赖于特定条件和输入数据,由于缺乏理论上的压缩质量模型,无法在数据集之间通用地应用。本文基于预测的有界误差有损压缩框架方面理论上开发了一种新的分析模型,该模型可以有效且准确地估计任何给定数据集的压缩质量,包括压缩比和数据失真。模型具有三个关键特征:(1) 它是一个适用于大多数科学数据集和应用程序的通用模型,(2) 在估计压缩比和事后分析质量方面具有相当高的准确性,(3) 计算开销非常低。与所有现有解决方案相比,本文提出的模型可以通过显著提高压缩比和低计算的开销来提供有损压缩质量的原位优化。近年来,科学应用的数据管理已经成为一个相当棘手的挑战。研究人员必须开发高效的数据管理方法和软件来处理极大的数据规模和异常的数据移动特性。通常情况,HDF5、netCDF 和Adaptable IO System (ADIOS) 是在高性能计算机上运行的科学应用中广泛使用的数据管理软件库。然而,这些科学数据管理技术仍然受制于极大的数据集和随之而来的I/O瓶颈,因此它们通常采用压缩技术。由于HDF5已经成为科学界支持数据管理的系统,本文主要以HDF5为例进行性能评估。有损压缩通过在重构数据中丢失非关键信息,可以实现极高的压缩比。评估有损压缩性能的两个最重要的指标是压缩比与数据失真度量。近年来,针对科学数据提出并开发了一种新一代高准确度的有损压缩器,例如 SZ 和 ZFP。这些有损压缩器提供参数,允许用户精细控制由于有损压缩导致的信息丢失。本文主要关注基于预测的有损压缩的比率-质量建模。基于预测的有损压缩的工作流程包括三个主要阶段:预测、量化和编码。本文建立了一个用于基于预测的有损压缩的系统模型,支持准确且高效的比率-质量估计。
图1说明了比率-质量模型的工作流程,该模型具有高度模块化和可扩展性。比率-质量模型基于两个主要估计:压缩比率和后续分析质量。本文基于误差边界构建了一个比率-质量模型,并为不同的预测器和误差边界提供了优化。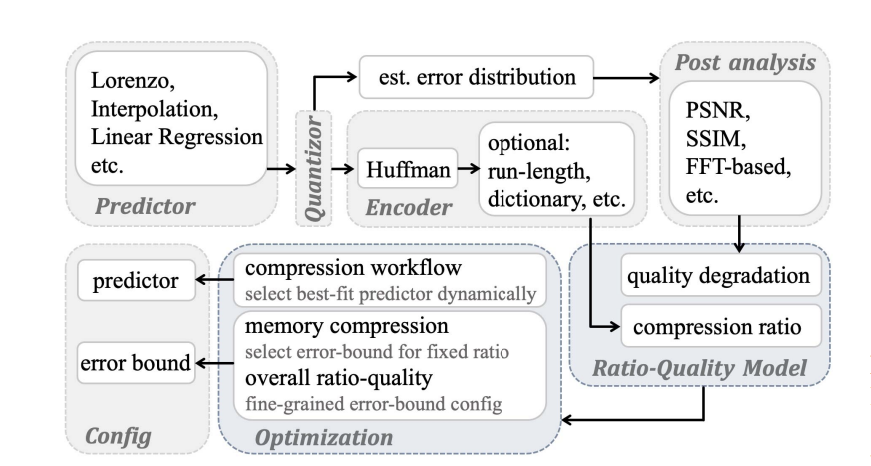
图1 基于预测的有损压缩和科学数据分析的比例质量建模工作流程概述为了建模压缩比率,首先检查由有损压缩器提供的现有误差边界模式。然后,主要的压缩比率估计包括三个模块:预测器、量化和编码器。文章首先对预测器进行建模,以提供预测误差的估计直方图。之后,对量化阶段进行建模,以估计误差分布和量化码直方图。最后,基于对Huffman编码效率和可选无损压缩效率的理论分析,估计压缩比率。为了对事后分析质量进行建模,本文首先从压缩器量化步骤确定误差分布。然后,通过一个基于假设错误注入数据集的错误传播理论推导,分析了对事后分析质量的影响。在编码量化代码时,首先应用Huffman编码器,然后是其他无损编码技术。实验结果显示,Huffman编码提供的编码效率与可选的无损编码器提供的编码效率存在明显差异,如图2所示。这意味着可选的无损编码器提供的编码效率只在达到一定极限(约每个符号1位)后才能补充Huffman编码。另一方面,在对Huffman编码的输出应用游程编码后,可以使压缩比非常接近使用整个无损压缩器进行Huffman编码后的压缩比。这是因为预测器始终尽最大努力准确预测数据点,使得大多数预测值都会在相应真实值周围误差边界内。在这种情况下,相应量化代码被标记为'零'。因此,在高误差边界下进行压缩时,零会始终占据Huffman编码的主导地位,特别是压缩率相对较高时。本文基于以下两种编码方法估计编码器的效率:(i)对频率信息进行编码的Huffman编码和(ii)对空间信息进行编码的游程编码(适用于较高的误差边界)。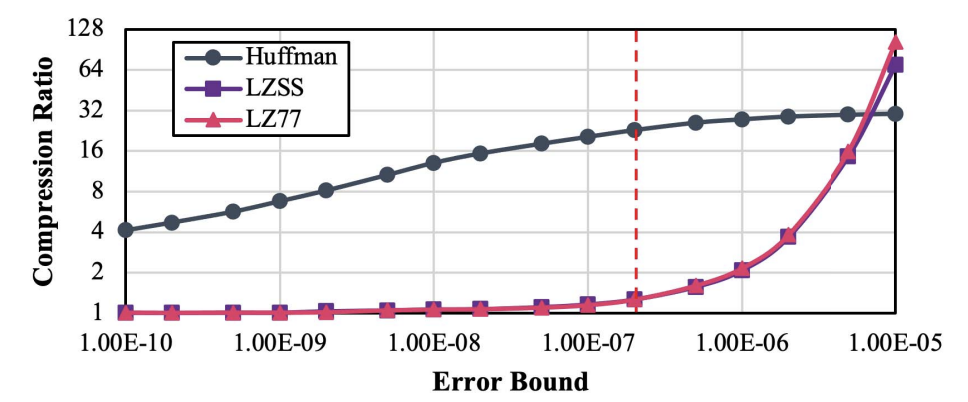
图2 量化代码上来自霍夫曼编码器和来自 Zstandard 和 Gzip 的可选无损编码器压缩比估计比特率: 文章根据预测和量化生成的量化代码,对Huffman编码(即每个数据点的平均比特长度)产生的比特率B进行建模,如下所示: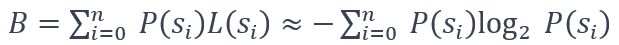 (1)
(1)
式中n为不同霍夫曼码的个数,P为给定码si 的概率(或频率),L为给定码si 的长度。文章进一步使用二进制的二进制系统表示基于其概率的Huffman编码长度。当处理具有最高频率的代码时,需要调整其比特率 -log2P(si) 以使其成为最小码长(即1位)。基于比特率的优化错误界: 基于现有比特率B的目标比特率B*的优化错误界e∗如下式所示:  (2)
(2)
其中e是位率为B的轮廓误差界,由式(1)得到。
注意:当量化箱的数量相当小时,上述估计方法不适用。
(ii) 游程编码(RLE)的建模
如前所述,无损编码器仅在霍夫曼编码器达到极限时才有助于压缩比,其中零支配量化代码。此外,由于去相关效率高,量化码在有效预测后是独立随机的,导致连续非零码的概率极低。因此,本文仅对零上的RLE进行建模。
估计压缩比: 文章用下式对RLE的压缩比Rrle进行建模:
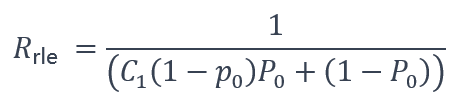 (3)
(3)
这里P0是代码零所占用的空间相对于完整的霍夫曼编码数据大小的百分比,其中P0是零个数的百分比。基于比特率的优化错误界: 通过由式(3)推导出的零的目标百分比p0,量化代码对优化的错误界e* 进行了分析: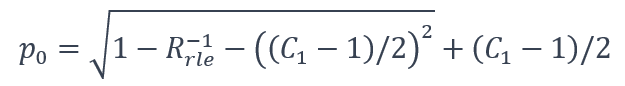 (4)
(4)
需要对量化的预测误差直方图进行建模,因为基于预测的有损压缩依赖于高效的预测器和量化器来集中输入数据信息以实现高编码效率。本文计算预测误差的分布,基于这个分布,将为编码器模块构建量化代码直方图。为了在低开销的情况下获得准确的预测误差分布,本文根据不同预测器的设计原则应用合适的采样策略。对于稀疏的科学数据,这一步还确定了稀疏性并删除了预测误差分布中相应的零,以获得高模型准确性。文章分析并设计了用于SZ中的三个预测器的所有三个预测器的采样策略:Lorenzo、线性插值和线性回归预测器。对于误差边界相当高的情况(由p0阈值确定),使用原始数据值估计的量化代码直方图可能会受到较大失真。因此,文章在估计中添加了一个校正层。在为编码器模块提供直方图时,文章添加了以下随机箱传输: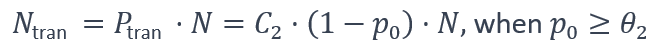 (5)
(5)
其中,Ntrans是从一个bin传输到相邻bin的代码数量,C2是基于本文实验的预测器经验参数,N是给定bin中值的数量。事后分析质量与用于特定科学应用的分析指标密切相关。文章介绍了两种分析指标:PSNR 和 SSIM。1. 误差分布:文章首先提供误差分布的平均值和方差,用于误差传播分析。重构数据的误差分布由用户定义的误差界方式和误差界值决定。在大多数情况下,基于预测的有损压缩器的误差分布呈均匀分布。在这种情况下,μ(E) = 0,有: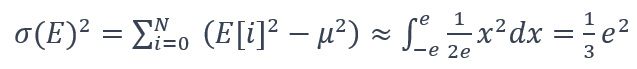 (6)
(6)
这里 e 是误差界。然而,在高误差范围内,观察到误差分布结合了均匀分布和集中分布。可以将中心仓内的值与其他仓内的值分开(μ(E) = 0):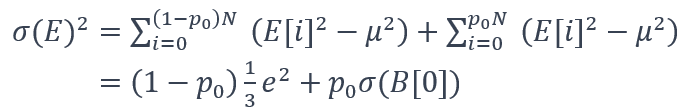 (7)
(7)
2. PSNR的建模:论文对重构原始数据的PSNR建模如下:
 (8)
(8)
其中D' 和 D分别是重构数据和原始数据,minmax是值范围。3. SSIM的建模:论文对重构原始数据的结构相似指数(SSIM)建模如下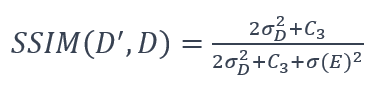 (9)
(9)
4. 特定数据事后分析:专门设计的分析指标也用于一些科学数据集,以前的研究在给定误差分布的情况下对基于FFT的Power Spectrum和Halo
Finder执行了误差传播分析。然而,在对分析质量建模时,它使用均匀误差分布,这在高误差范围下可能产生不同的结果。通过使用本文新提出的误差分布模型,可以进一步提高在基于FFT的分析的估计精度。本节主要介绍三个用例,利用比率-质量模型来显著提高基于预测的有损压缩器的性能。A.为任何数据集和误差边界自适应选择最佳预测器:使用比率-质量模型,可以为每个预测器提供比例质量估计,并选择适合给定误差边界或目标比例的最佳预测器。文章方法与现有方法相比可帮助显著减少优化开销,只需进行一次采样和高效估计。B.目标比内存压缩:对于将压缩数据存储在内存中并需要特定最大占用空间的应用,文章的模型估算了任何给定数据集的压缩比,可提供一种优化策略,以有效利用可用内存。C.原位压缩优化:为了在压缩比和重构数据质量之间取得平衡,对于被认为是多个分区组合的数据集,本文能够根据一些指标具体描述每个分区,然后用这些指标来决定应用哪种压缩配置。因此,本文可以以整体压缩比和整体分析质量为目标,对每个分区分别优化压缩性能。使用模块化的基于预测的有损压缩框SZ3进行评估,在Argonne的Bebop集群上进行实验,每个节点配备两个18核Intel Xeon E5-2695v4 cpu和128GB DDR4内存。同时在评估中使用了来自科学数据缩减基准的10个真实科学数据集。首先从预测器模块评估本文的采样预测误差的准确性。然后,使用两个编码器设置情况进行评估:(1)仅使用 Huffman 编码器对量化代码进行编码;(2)使用 Huffman 编码器和一个可选的无损编码器对量化代码进行编码。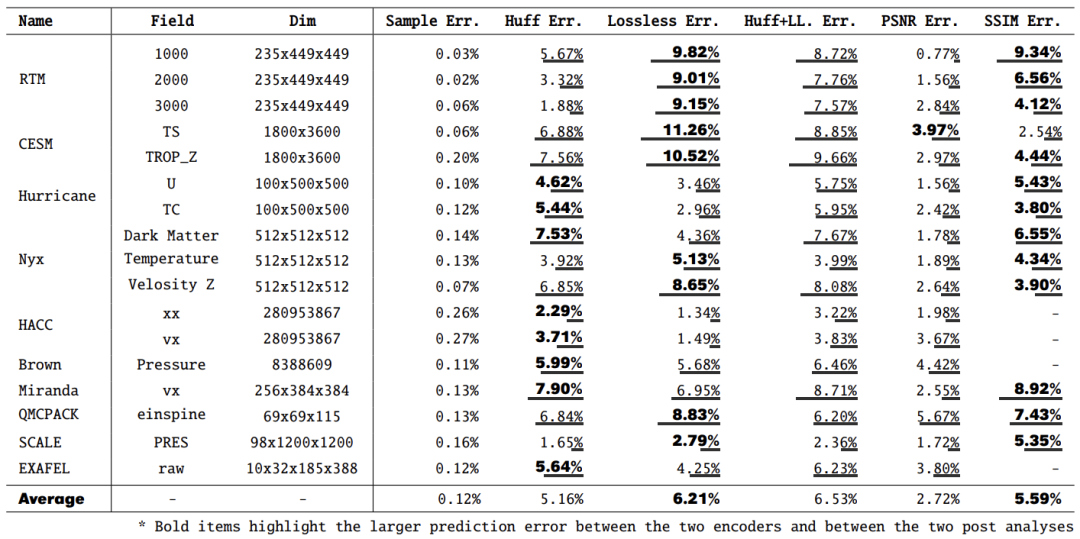
整体压缩比是霍夫曼编码效率和RLE效率的综合。图3中的红点和线分别表示编码器总体效率的测量比特率和估计比特率。可以观察到,本文的建模达到了很高的精度。所有数据集上总体压缩比估计的详细精度见表1。准确率高达97.6%,平均准确率为93.5%。结果表明,仅使用哈夫曼编码的压缩比估计几乎总是比同时使用哈夫曼编码和无损编码的估计更准确。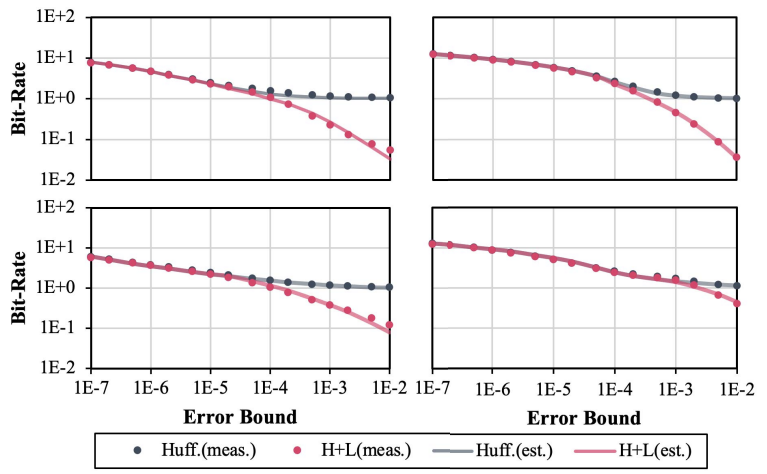
图3 与编码器测量相比的压缩比(比特率)估计准确性1.PSNR:图4显示了测量的PSNR与基于误差分布的估计PSNR的比较。总的来说,本文的模型在模拟PSNR方面达到了99.2%和97.3%的平均精度。
图4 PSNR估计精度(用线性插值预测器(左)和Lorenzo预测器(右)对Nyx暗物质密度场进行评估)2.SSIM:图5显示了测量的SSIM与基于误差分布的估计SSIM的比较。评估表明,本文的模型在SSIM上可以提供平均94.4%的准确率。与SSIM估计相比,本文提出的模型在PSNR估计上表现更好。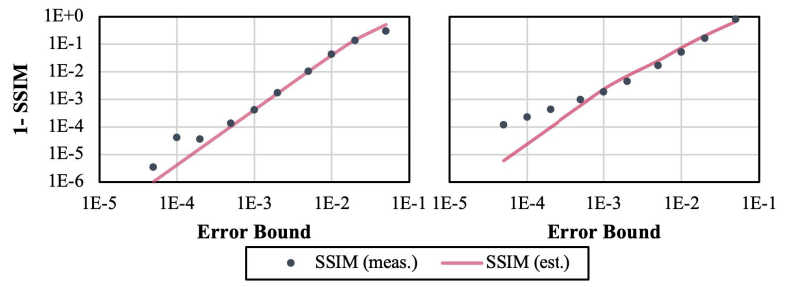
图5 SSIM估计精度(在CESM数据集(左)和Aramco RTM数据集(右)上进行评估)3.数据特异性事后分析:图6显示,考虑方程(6)和(7)的误差分布的建议估计优于之前只考虑均匀误差分布的解决方案。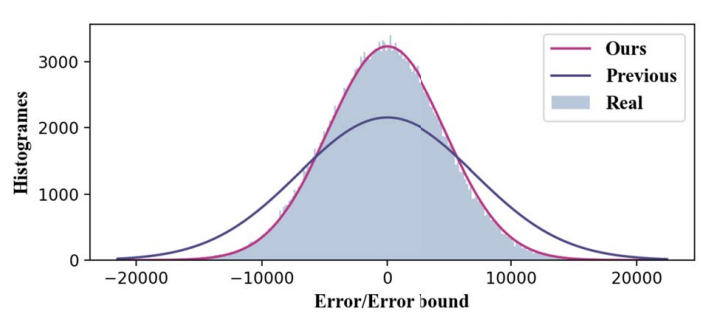
图6:FFT质量退化估计,在ABS 500下对Nyx温度场进行了评估文章将建模策略的性能与试错方法进行了比较。图7显示了本文的工作流与以前方法在3个反演时间迁移(RTM)数据集上平均性能的比较。相对于Lorenzo和插值预测器作为候选项估算的7个候选错误边界,本文的解决方案平均优于基于试错的解决方案18.7倍。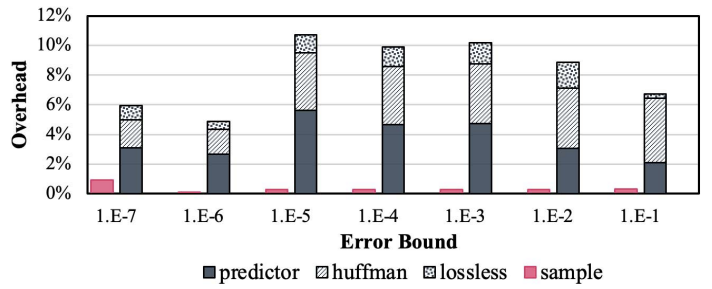
图8显示了传统静态、离线方法和自适应原位方法之间跨多个快照的 RTM 数据的比率质量比较。示例目标是确保所有快照的 PSNR 高于 56 dB,这保证了每个快照的重建数据质量以进行后阶段处理。可以看出,传统的解决方案只为所有快照选择一个误差界,导致多数快照PSNR远高于目标。对比可见,采用比值质量模型的原位方案在满足重构数据质量要求的同时,能够在所有快照中提供一致的低比特率。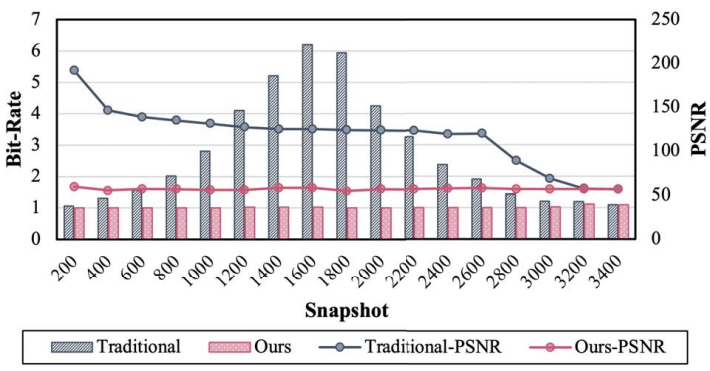
图8:目标PSNR为56 dB时,基于建模方法与离线优化方法在不同快照中的比特率和相应PSNR比较。图9显示了三种方法跨不同快照的总体数据转储时间:传统方法、原位TAE方法和我们使用比率质量模型的原位优化方法。与传统的原位TAE方法相比,本文的方法由于精确的误差界控制,提供了较高的压缩比,可以显著减少总体数据转储时间。当与原位TAE方法进行具体比较,论文提出的方法可以显著减少优化时间,同时提供更高的压缩比以减少I/O时间。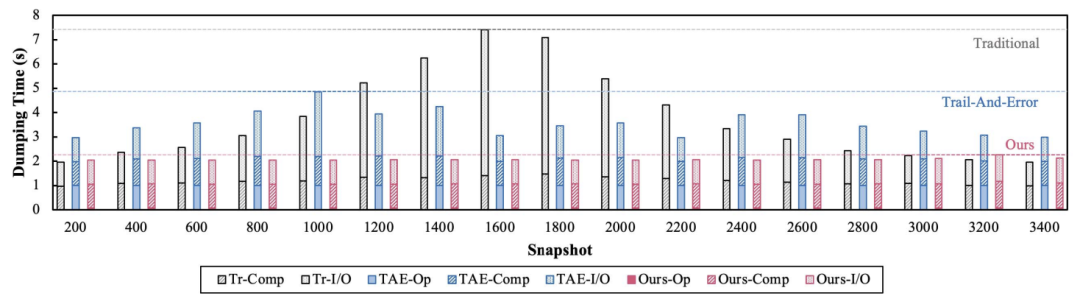
本文为基于预测的有损压缩器开发了一个通用的分析比率-质量模型,该模型可以有效地估计压缩比,以及有损压缩数据对事后分析质量的影响。文章的分析模型在三个用例中显著改善了基于预测的有损压缩:(1)通过自动选择最适合的预测器和模式来优化预测器和压缩模式;(2)通过选择固定或估计比特率的错误边界来优化内存压缩;(3)通过对各个数据分区进行细粒度的误差界调优,实现整体比例质量优化。作者在10个科学数据集上评估了文章的分析模型,证明了它在估计压缩比和有损压缩对事后分析质量的影响方面具有较高的准确性(平均准确率为93.47%)和较低的计算成本(比以前的方法低18.7倍),还通过在三个用例中使用不同的应用程序来验证比率质量模型的高效性。最后,文章证明,与传统的静态离线解决方案相比,基于建模的方法在128个CPU核上并行HDF5时,可将RTM仿真的数据管理时间减少3.4倍。许熠
重庆大学2022级计算机科学与技术(卓越)专业在读,重庆大学START团队成员。主要研究方向:数据压缩 | 
|
重庆大学时空实验室(Spatio-Temporal Art Lab,简称Start Lab),旨在发挥企业和高校的优势,深入探索时空数据收集、存储、管理、挖掘、可视化相关技术,并积极推进学术成果在产业界的落地!年度有2~3名研究生名额,欢迎计算机、GIS等相关专业的学生报考!






