







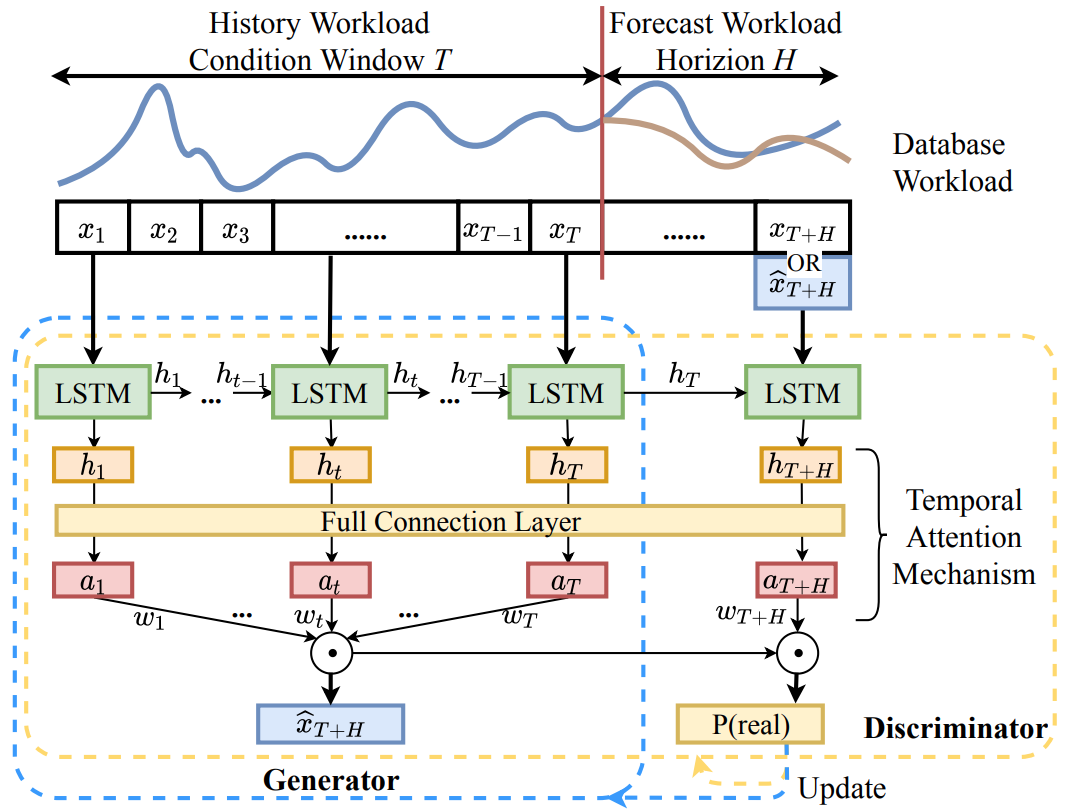
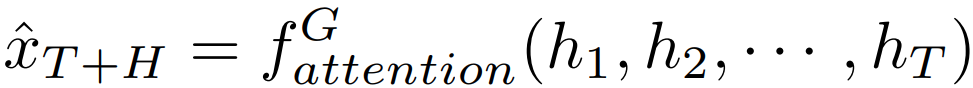

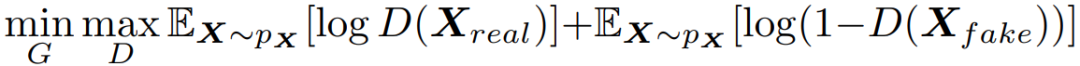

 是时刻t的预测工作负载,i=1,2,3分别表示三种模型。对于第i个预测模型,使用
是时刻t的预测工作负载,i=1,2,3分别表示三种模型。对于第i个预测模型,使用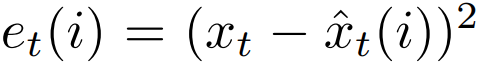 表示预测误差,根据误差分配各个模型的权重。但静态的et(i)无法对时间高敏感。对于这个问题,文章引入了一个带有衰减因子δ的时变预测距离。设e(i)=(e1(i),e2(i),...,et(i)),预测距离为
表示预测误差,根据误差分配各个模型的权重。但静态的et(i)无法对时间高敏感。对于这个问题,文章引入了一个带有衰减因子δ的时变预测距离。设e(i)=(e1(i),e2(i),...,et(i)),预测距离为 ,它具有时间敏感性与鲁棒性。对预测距离进行归一化,可得到每个模型随时间t的时变权重。
,它具有时间敏感性与鲁棒性。对预测距离进行归一化,可得到每个模型随时间t的时变权重。
|

文章转载自时空实验室,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
