




自然语言数据库接口(NLIDB)旨在使用户能够使用自然语言与数据库进行交互和查询。目前最先进的方法是构建语言翻译模型,将NL查询转换为SQL查询。虽然这些模型在NLIDB基准测试中表现出良好的性能,但翻译精度似乎停滞在70%-75%之间,并且对于需要理解特定于数据库的结构和语义的复杂查询表现不好。本次为大家带来数据库领域顶级会议ICDE上的论文:《GAR: A Generate-and-Rank Approach for Natural Language to SQL Translation》。

一.背景
随着数据库查询接口的设计变得越来越注重用户友好性,用自然语言与数据库进行交互和查询的方法逐渐崭露头角。近年来,随着语言翻译技术的成熟,一些数据库查询接口已经采用了将自然语言查询(下文简称NL查询)翻译为SQL查询的方式,这种翻译过程利用了机器学习方法。其主要思想是将自然语言数据库接口(NLIDB)问题看作是一项语言翻译任务,并采用通用的序列到序列(Seq2Seq)模型进行训练。尽管在翻译的准确性方面取得了显著的进展,但在总体上的改进方面停滞不前。在这篇论文撰写时,SPIDER排行榜上位于首位的模型在测试集上仅达到了72.1%的翻译准确率。
翻译难点主要出现在复杂的查询中,例如,考虑两个最先进的模型GAP和SMBOP,在SPIDER基准测试中,面对不同"难度级别"的SQL查询的翻译准确性如图1所示。

图1 SPIDER基准测试中各SQL难度级别的翻译准确性
可以观察到,这些翻译方法在处理更复杂的查询时准确性有明显的下降。这一现象可能的原因是更难的查询需要比一般查询更多的目标数据库的训练数据,而其他数据库上的训练数据几乎没有帮助。实际上,每个数据库都具有其独特的结构和语义,就像构成了一个独立的"宇宙",具有自己独特的思想表达方式。
如果没有充分考虑目标数据库的特殊语义和结构,NL查询到SQL查询的翻译任务就可能会失败。
在这篇论文中,作者提出了一种名为GAR的方法。其假设给出一组样本SQL查询来表示用户可能的对数据库的查询,GAR从样本集中提取基本组件,形成基本构建块,以生成通用的SQL查询集合。然后利用简单的基于规则的SQL到NL技术,获得一种不太自然的NL表达式,称为方言表达式(dialects)。最后,对给定的NL查询,使用学习排序的方法来检索出最佳方言表达式,从而得到结果SQL查询。虽然改进了现有的技术,但GAR仍然可能发生错误,尤其是对于那些涉及连接操作的查询,因为连接操作通常会提高语义上的抽象级别,而GAR很难仅从表/列名中推断出来。针对这个问题,论文通过在SQL到NL的连接操作中添加注释来辅助翻译过程,从而将GAR扩展为GAR- J,提升了处理连接操作查询的能力。
接下来的部分将详细介绍GAR方法的工作原理和实验结果。
二.方法介绍
2.1 总体框架
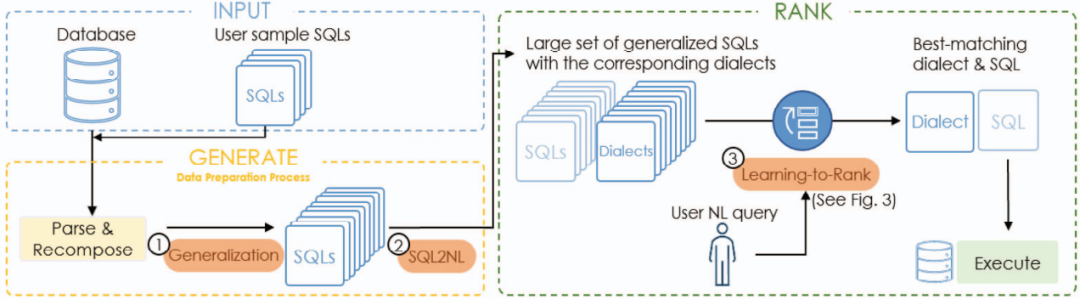
图2 GAR框架概览
图2所展示的是GAR的总体框架,在一开始的数据准备过程,GAR首先使用给定的一组样本SQL查询,经过泛化和SQL2NL(SQL查询to NL查询)两个阶段生成大量的泛化SQL以及相应的方言表达式。在数据准备过程之后,对于用户输入的NL查询,使用LTR(Learning-to-Rank)技术对生成的方言表达式进行排序,返回最相似的查询语句。
2.2 泛化
定义1:SQL的基本组件
根据观察,每一句SQL查询都可以看作是由一些基本组件构成的,文章对这些组件进行了定义以及分类,如图3所示,一共分为select,from,where,group,order,join,compound七种类型。
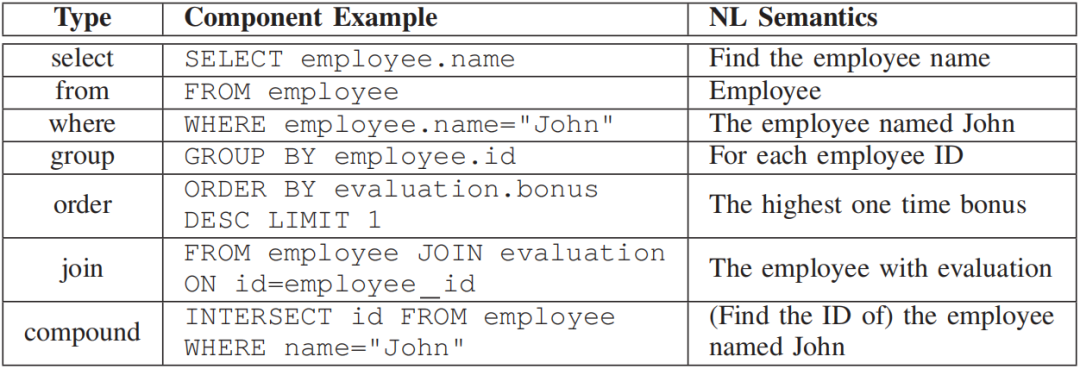
图3 SQL基本组件类型
定义2:组件级泛化
给定一组样本查询,组件级泛化是指通过重新组合样本查询中的基本组件来生成泛化查询的过程,这个过程生成的结果查询与样本查询在组件级别上是相似的。
基于以上定义,GAR使用解析树来表示SQL查询的组件特征。解析树是一种抽象的语法树,它根据语法表示SQL查询的语法结构。
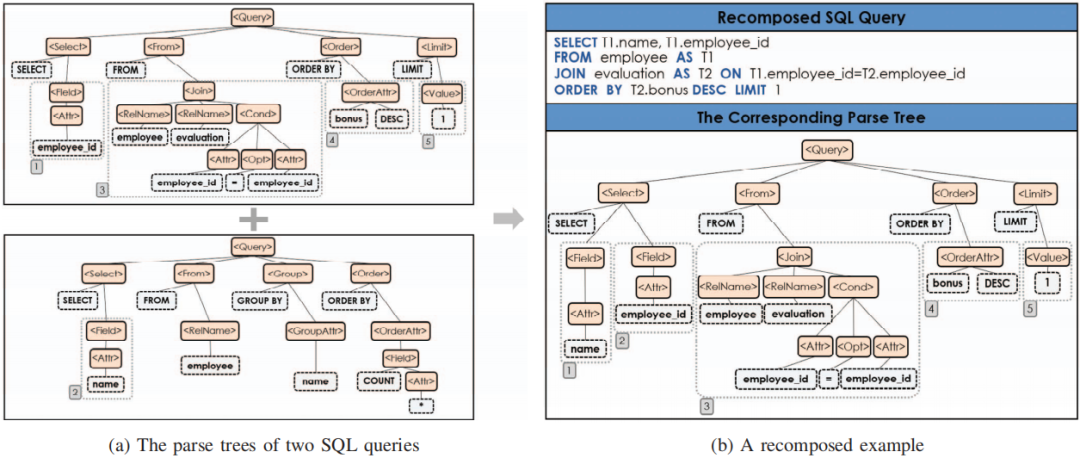
图4 解析树以及解析树的重组
图4a展示了两棵解析树,其中每棵解析树都是由一组子树(即组件)构成,而每棵子树都是由叶结点(虚线结点)和非叶结点(实线结点)组成。此外,还可以将一组子树重组为一棵新的解析树,如图4b所示,从而重组出一个新的SQL查询。

图5泛化算法伪代码
泛化流程:GAR递归地进行SQL查询的泛化。首先,从给定的查询解析
树中随机选择两棵解析树。然后,随机选择一个非叶结点类型,并从所选择的两棵解析树中分别选择两棵扎根于该结点类型的子树,打乱它们的次序来重组这两棵解析树。接着,对重组的解析树进行语法和语义检查,以确保其正确性。最后,将那些有效的重组解析树放回原始集合,并重复上述步骤,直到不再生成新的解析树。作者观察到,许多生成的泛化SQL查询在语法上是正确的,但在语义上与样本集合不相似,为此,作者引入了以下组合规则。
(1)连接规则:由于SQL查询中的连接操作往往会增加表达语义的抽象级别,所以GAR只会回答那些用户感兴趣连接操作。换句话说,重组的解析树中不会包含样本查询中未出现的连接操作。举个例子,在图4a中,“join”类型子树表示连接操作,假设该子树重新组合成一个新的“join”类型子树,其叶结点是“shop”表,而这个新的连接操作在样本查询中没有出现过,这种情况下,重组的新解析树将被去除。
(2)语法限制:由于SQL允许无限嵌套和其他方式来构建大量的SQL查询,GAR采用了一组约束条件来限制泛化后的SQL查询的语法复杂度。例如,WHERE子句定义了一个约束条件,指定了泛化后的SQL查询可以具有的最大谓词数。所有这些约束条件都是从给定的样本查询中收集而来,这表明泛化后的SQL查询的复杂度应该与样本查询中的复杂性相似。
(3)保持偏好:泛化后的SQL查询应该反映用户对目标数据库中特定语义的偏好,如果样本查询中某些子树出现的频率偏高,那么泛化过程应该生成更多包含这些子树的解析树。
(4)保持子查询:在大多数情况下,子查询通常作为整体出现在各种查询中。因此,在重组时子查询被视为一个整体,也就是说,在进行泛化时不改变子查询的任何子结点。
(5)屏蔽文字值:因为泛化过程不应该依赖于特定的文字值(例如,在WHERE子句中谓词中指定的字符串值),所以在将SQL查询转换为相应的解析树时,使用占位符屏蔽文字值。通过这种方式,既保留了SQL查询的语义结构,又无需考虑查询中使用的确切值。
2.3 SQL2NL
论文基于GRAPH-NL方法进行了改进。GRAPH-NL首先将SQL查询视为一个字符串,并将字符串拆分为表示查询中每个子句的块(类似于解析树中的子树),然后逐个子句地构建SQL查询图。接下来,GRAPH-NL为每个图元素(结点或边)分配一个标签,以表示其语义。最后,使用不同算法遍历查询图,串联沿途找到的基于元素的标签,使用一些描述性表达式(例如“查找”,“对于”等)生成NL表达式。
GAR遵循GRAPH-NL的方法,但进行了一些更改:
(1)GAR不使用查询图,而是使用解析树来表示SQL查询。类似地,GAR首先为解析树中的结点分配“标签”,然后以先序遍历的方式遍历解析树以生成NL表达式。
(2)为了支持子查询,GAR将每个子查询视为一个整体,并使用特定的结点类型来表示。
(3)通过利用数据库信息,GAR在生成方言表达式的同时添加了更多与数据库相关的语义。例如,对于查询语句中“bonus”的语义是指一年收入还是总收入,GAR通过检查该表的键信息(该表有员工id和年收入),推断出“bonus”是指一年收入。
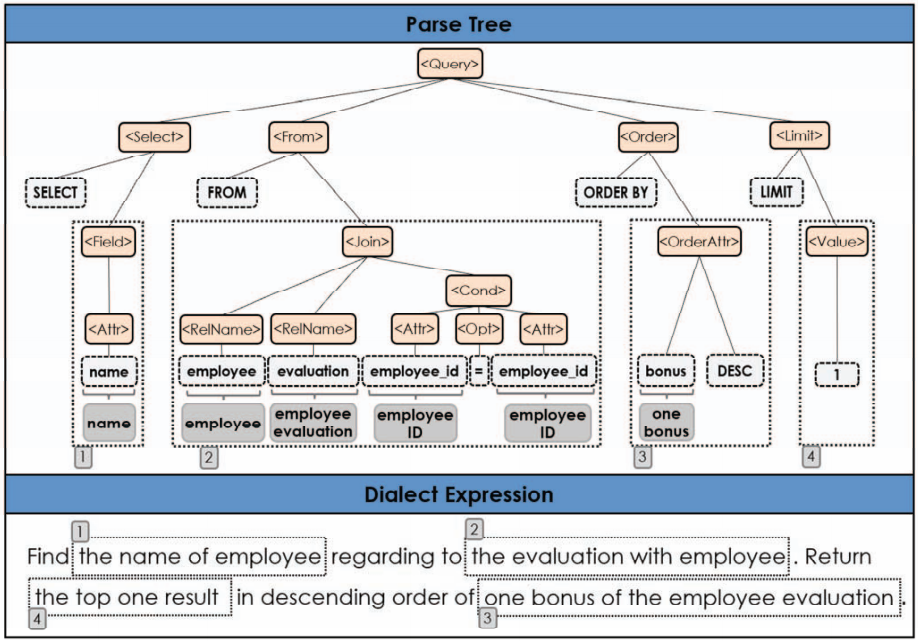
图6一个方言表达式生成的例子
3.3 NL语义匹配
GAR采用LTR(Learning-to-Rank)技术,使用两个独立的机器学习模型来构建NL语义匹配网络。在第一阶段,使用粗粒度的检索模型将相对较大的方言表达式集合缩小到相对较小的潜在最佳匹配集合,然后第二阶段使用细粒度的重排序模型,得到最终排名最高的方言表达式。
检索模型的训练数据是一个三元组集合,其中qi为NL查询,di为方言表达式,si为di和qi之间的语义相似度得分,计算si过程如下。初始将si设置为1,然后将用于获得di的SQL查询的每个子句与为qi提供的“gold”查询进行比较。如果有一个子句不相同,对si值增加惩罚。最后,直到比较了所有子句或si值下降到0,计算结束。
重排序模型的训练数据是一个三元组集合,其中qi为NL查询,di为方言表达式,li为二进制分数,评估di是否由qi的“gold”SQL查询生成,使用listwise方法进行训练。此外,为了提高训练效率,重排序模型选择使用检索模型产生的结果集合的子集合,即设置一个阈值k,只使用结果集合中的前k个方言表达式。
2.5 GAR-J
当SQL查询涉及到连接操作时,其表达的语义可能会变得更加抽象,直观的感觉是,连接操作的输出是一个新的表,它的语义不能直接从连接操作涉及的表的名称或它们的列的名称中推断出来。对此,论文提出在SQL到NL的连接操作中添加注释来辅助翻译过程,将GAR扩展为GAR-J。论文定义了四种连接注释:
(1)joining table,指定在连接操作中涉及哪些表。
(2)joining condition,指定在连接操作中使用的条件。
(3)joining description,提供对新表语义的描述。
(4)table key,提供新表的关键信息。
GAR-J通过将目标数据库提供的连接注释融入到翻译过程中,从而改善SQL到NL的翻译结果。GAR-J首先检查解析树,并将连接注释作为“标签”添加到树中。如果解析树的一组子树可以映射到SQL查询的连接操作,将连接操作的其他形式(例如,使用WHERE子句)转换为join形式来规范化解析树,然后在非叶结点上添加连接注释来表示“连接”语义。如果叶结点是星号(“*”),查看解析树以寻找与表注释或连接注释相关联的结点,然后使用“table Keys”注释信息对该星号结点进行注释。图7展示了在连接注释的辅助下,一个SQL查询翻译成NL查询的例子。
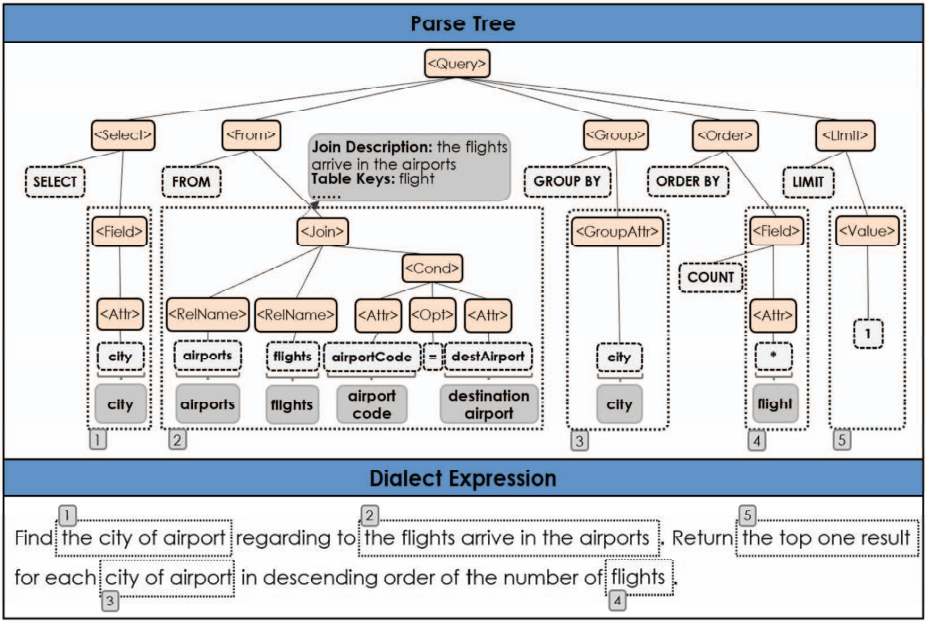
图7在连接注释的辅助下一个方言表达式生成的例子
四.实验
4.1 实验配置
论文实验使用三个NLIDB基准,GEO,SPIDER,MT-TEQL和一个自定的QBEN标准来评估GAR的性能,将GAR与四种最先进的基于机器学习的模型(GAP、SMBOP、RAT-SQL和BRIDGE)进行比较。
检索模型的嵌入层采用stsb-mpnet-base-v29预训练模型来初始化,使用Adam优化器,其学习率为25 -5,预热超过总步骤的前10%,以微调模型。
重新排序模型使用ROBERTA预训练模型初始化,使用学习率为5e-6的Adam优化器,并采用学习率计划,一旦训练指标在训练中停止改进,学习率将降低0.5倍。
4.2 评估指标
(1)Translation
Accuracy:如果排名靠前的SQL查询与“黄金”SQL完全匹配,那么就说翻译是准确的。这是性能的下限,因为语义正确的SQL可能在语法上不同于“黄金”SQL。该指标与SPIDER中引入的Exact Match指标相同。
(2)Execution
Accuracy:通过对底层关系数据库执行生成的SQL查询来评估执行结果是否与基本事实相匹配。该指标与SPIDER中引入的Execution Match
Accuracy指标相同。
(3)Translation
Precision at K:K是一个正整数,表示为NLIDB系统在前K个翻译结果中具有“gold”SQL查询的NL查询数除以NL查询总数。在实验中,K为1,3,10。
(4)Translation MRR:一种统计度量,可用于评估每个NL查询的SQL查询排序列表。MRR值越接近1,说明翻译排序方案越有效
4.3 准确率
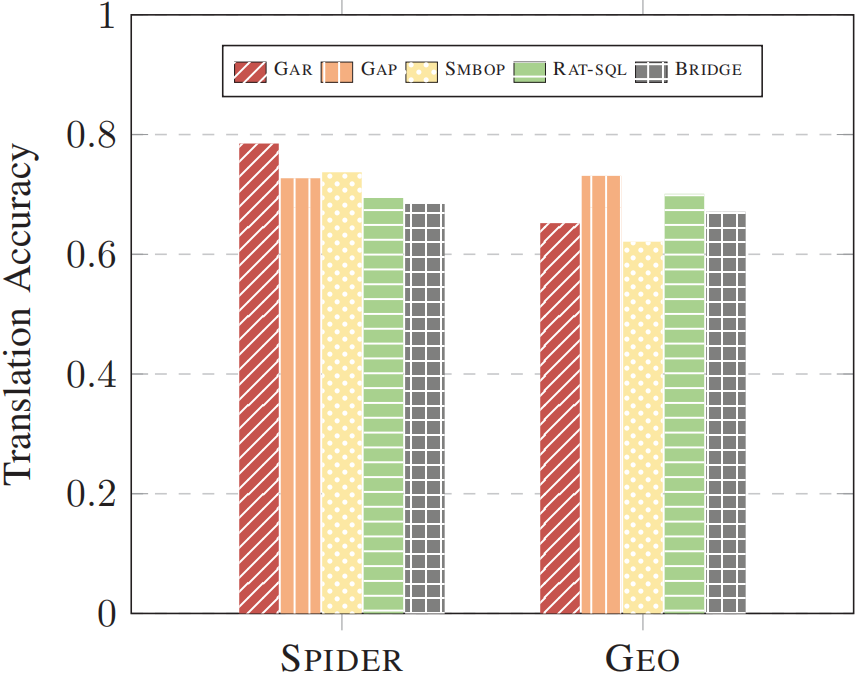
图8 三个基准上的翻译准确率对比
图7显示的是6种方法在三个基准上完成翻译任务的Translation Accuracy对比,可以看到,GAR-J和GAR的表现普遍都要优于其他方法,在QBEN和SPIDER上两者的准确率比其他方法都要高,尤其在QBEN上,GAR-J的准确率是其他方法的两倍多。
4.3 鲁棒性
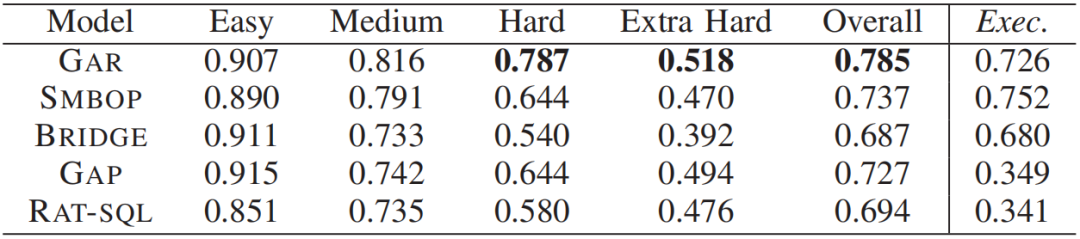
图9 (a)不同难度的SQL翻译任务的准确率
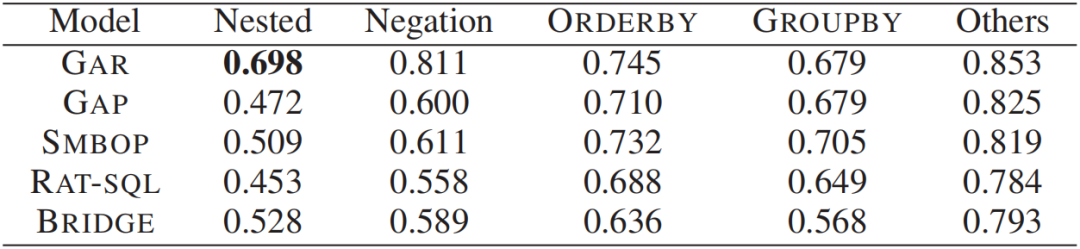
图9 (b) 不同类型的SQL翻译任务的准确率
图9 (a)和图9 (b)从难度和类型两个角度对5种方法的Translation Accuracy和Execution
Accuracy进行了比较。在难度角度,GAR在Hard,Extra Hard和Overall三类上的翻译准确率最高,可见GAR处理高难度SQL翻译任务的能力要比其他方法要强,并且总体能力也很优秀。在类型角度,GAR在Nested,Negation,ORDERBY和Others四类上的翻译准确率最高,可见对于各种类型的SQL翻译任务,GAR都具有良好的鲁棒性。
4.4 效率
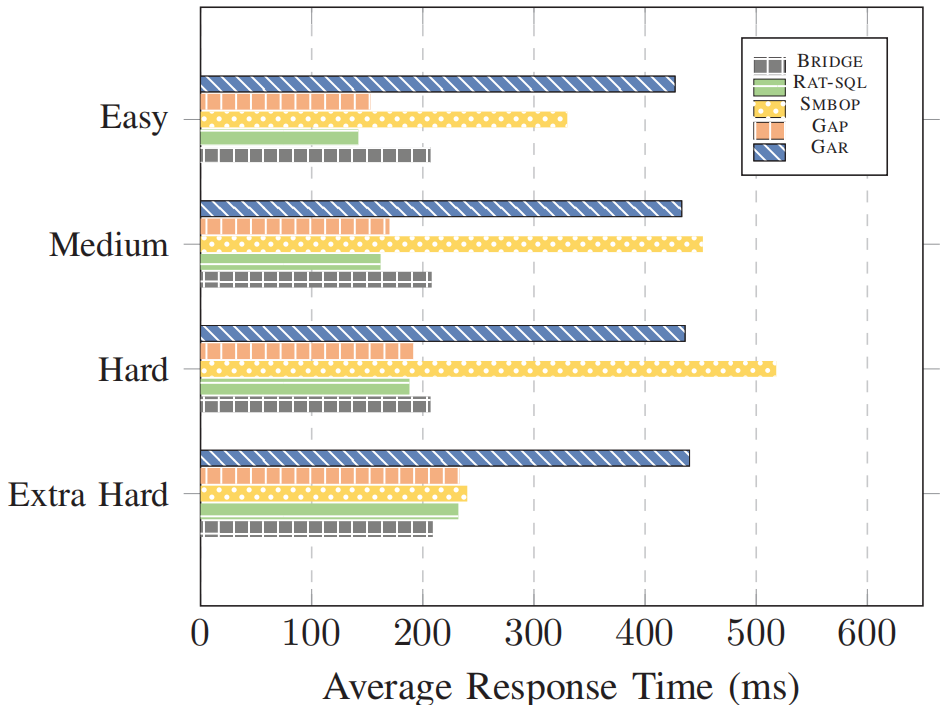
图10展示了5种方法完成不同难度的SQL翻译任务的用时。可以明显看出,GAR在各种难度上的表现都不好,用时几乎是其他方法的两倍(除了SMBOP),这与GAR需要对大量方言表达式进行检索以及排序有关。
五.总结
本文介绍了GAR,针对NL2SQL问题提出的一种实用的方法。GAR从样本查询中学习,生成大量在基本组件上相似的泛化SQL查询以及对应的NL查询,并利用LTR技术查找与用户输入的NL查询最匹配的结果。此外,通过将连接注释集成到SQL2NL过程中,GAR进一步扩展为GAR- J,提高了翻译精度。实验结果表明,GAR在现有的NLIDB基准测试中,准确率和鲁棒性基本优于现有方法,但是延迟较其他方法有所增加。
本文作者 张梓健 |  |
