




简介
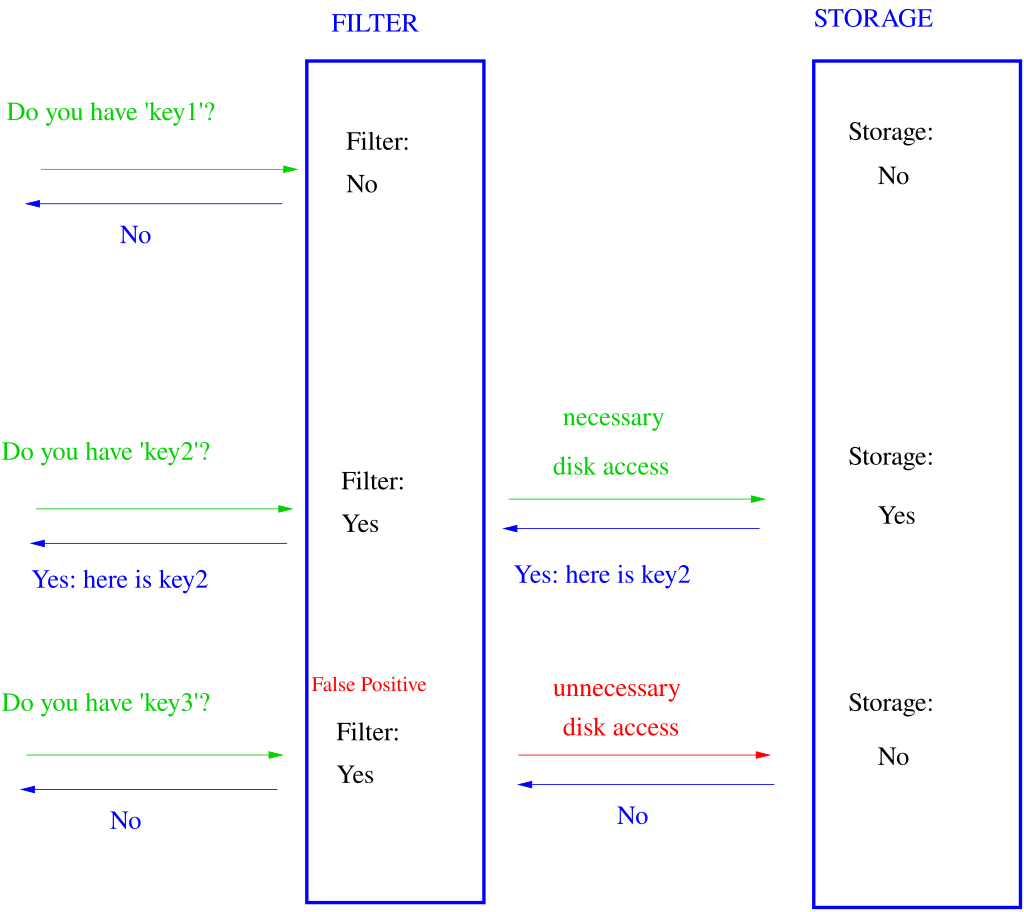
在postgresql有一个比较特殊的索引“布隆索引”,在大数据开发中大家肯定比较熟悉布隆过滤器了,布隆索引同样具有其独特的一个特性————“假阳性”。
所谓假阳性就是:
当bloom判断元素不存在元组中的时候,那元素一定不存在元组中。
当bloom判断元素存在元组中的时候,那元素可能不存在元组中。————这就是假阳性。
假阳性会造成数据失真吗?
不会!
基于bloom filter的运行原理,较高的误报率只会浪费较多的IO,占用过多了的RAM。
算法原理(为什么会出现假阳性)
以下是网络对于bloom的原理解释
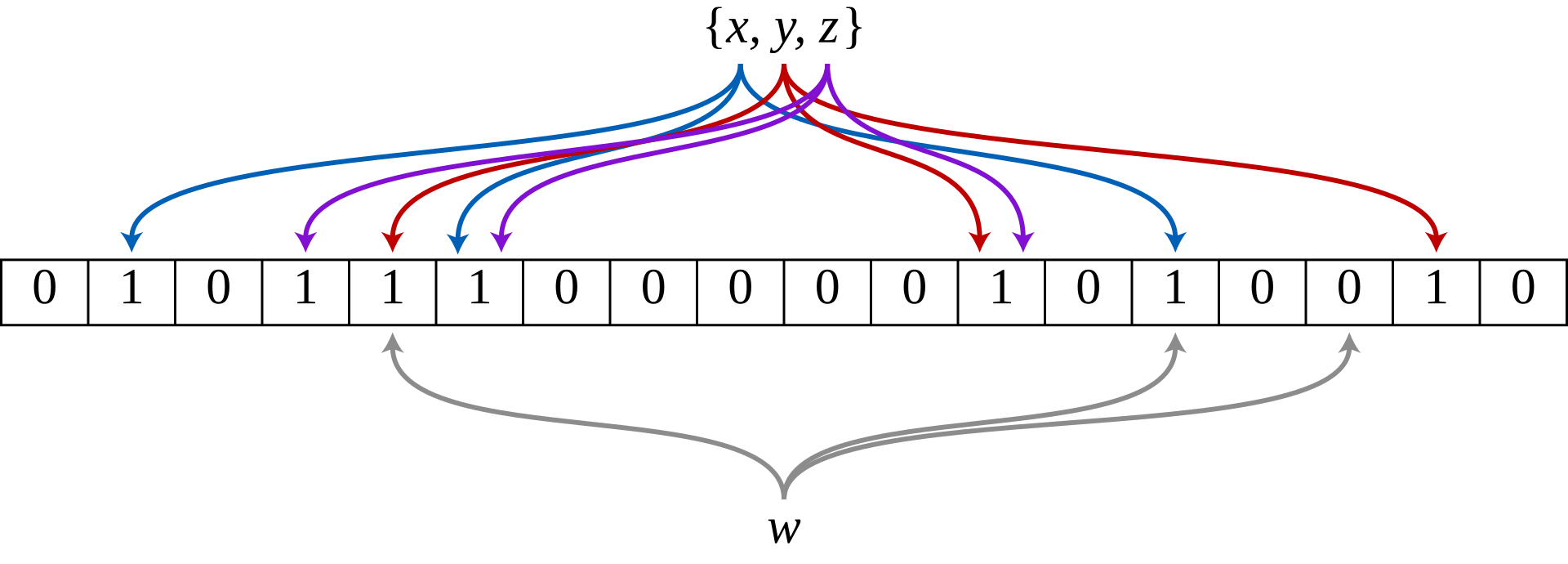
Bloom 过滤器是一个 m 位的位数组,全部设置为 0。它配备了 k 个不同的哈希函数,这些函数将集合元素映射到 m 个可能的数组位置之一。为了实现最佳效果,哈希函数应该是均匀分布且独立的。通常,k 是一个小常数,它取决于所需的错误率ε,而 m 与 k 和要添加的元素数量成正比。
要添加元素,请将其馈送到每个 k 哈希函数以获取 k 数组位置。将所有这些位置的位设置为 1。
要测试元素是否在集合中,请将其馈送到每个 k 哈希函数以获取 k 数组位置。如果这些位置的任何位为 0,则该元素肯定不在集合中;如果是,那么在插入时,所有位都将设置为 1。如果全部为 1,则元素在集合中,或者在插入其他元素期间偶然将位设置为 1,从而导致误报。在简单的 Bloom 过滤器中,无法区分这两种情况,但更高级的技术可以解决这个问题。
以下我的大白话
bloom会创建一个m 位的位数组,全部设置为 0。为每一个元素指定x个签名位。
当w元素进来,hash函数计算之后,发现签名位还是0,那说明元组一定没有这个元素。
当w元素进来,hash函数计算之后,发现签名位还是1,那说明该签名位上的其他元素进来过,但是该元素不一定进来过。
所以m值越高,其签名位对应的元素就越唯一,但是所需要的disk size就越高
pg创建bloom索引
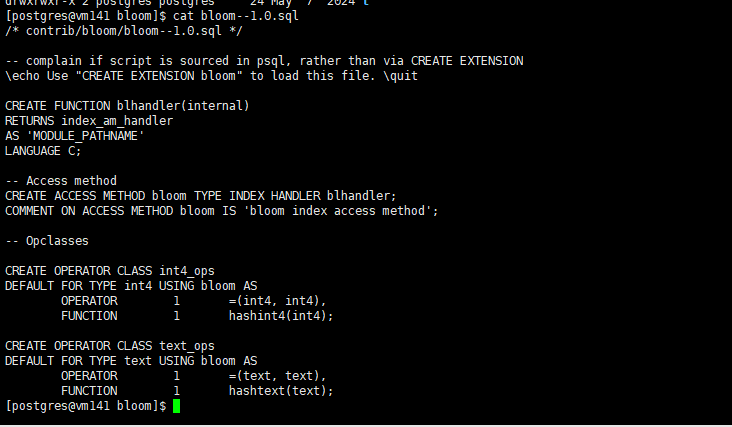
在Pg中bloom依赖于源码中contrib/bloom模块,构建时候 使用make world就会被引用,数据库就可以直接创建
create extension bloom;
在创建bloom 索引的初始,只包含了int4,text 两个数据类型的同类型比较,可以在contrib/bloom/bloom–1.0.sql 下查看到,
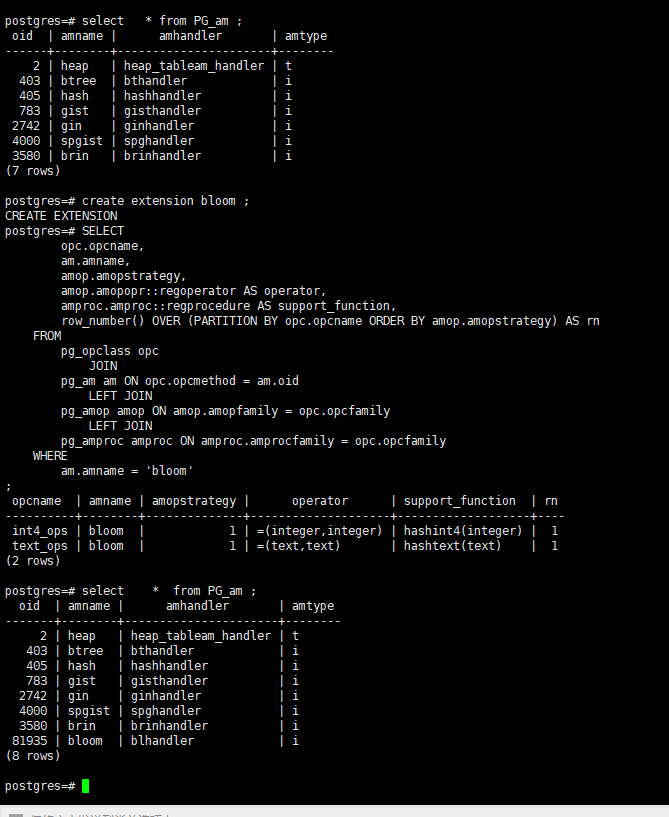
或者使用
SELECT
opc.opcname,
am.amname,
amop.amopstrategy,
amop.amopopr::regoperator AS operator,
amproc.amproc::regprocedure AS support_function,
row_number() OVER (PARTITION BY opc.opcname ORDER BY amop.amopstrategy) AS rn
FROM
pg_opclass opc
JOIN
pg_am am ON opc.opcmethod = am.oid
LEFT JOIN
pg_amop amop ON amop.amopfamily = opc.opcfamily
LEFT JOIN
pg_amproc amproc ON amproc.amprocfamily = opc.opcfamily
WHERE
am.amname = 'bloom';
剩下的操作符类就需要手工创建了。这里我认为常见的就是varchar numeric integer ,毕竟bloom只作为等值判断,增加时间类型的操作符类并不是一个明智之举。varchar 数据类型在pg查询引擎执行的时候,会自动转换::text进行比较,默认创建的text_ops就足够了,这个就不需要特殊处理了。
这里增加一个numeric的操作类
CREATE OPERATOR CLASS numeric_ops DEFAULT FOR TYPE numeric USING bloom AS
OPERATOR 1 =(numeric,numeric),
FUNCTION 1 hash_numeric(numeric);
bloom索引创建规则
CREATE INDEX <index_name> ON <table_name> USING bloom (<col1>,<col1>,<col3>)
WITH (length=80, <col1>=2, <col2>=2, <col3>=4);
这里length是签名位长度,
性能比较
首先bloom的使用场景,bloom使用于多字段表,查询谓语不稳定的情况下。谓语命中索引中的其中一个字段,便可进行索引扫描。传统的btree索引比bloom索引更快,但是需要很多 btree 索引来支持所有可能的查询。bloom相较于联合索引其索引扫描限制更少,但是size更大。
创建测试表
create table text_char
(
id varchar(100),
col1 varchar(100),
text_col text
);
插入测试数据
insert into text_char (id,col1,text_col ) select md5(id::text),md5((id*random()*103)::text), md5(id::text) from generate_series(21,3928562) as id ;
没有索引的情况下
postgres=# explain analyze select * from text_char where id = md5(21::text);
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------
Gather (cost=1000.00..134472.08 rows=1 width=99) (actual time=104.057..312.315 rows=1 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Parallel Seq Scan on text_char (cost=0.00..133471.98 rows=1 width=99) (actual time=231.689..300.720 rows=0 loops=3)
Filter: ((id)::text = '3c59dc048e8850243be8079a5c74d079'::text)
Rows Removed by Filter: 1309514
Planning Time: 0.284 ms
Execution Time: 312.332 ms
(8 rows)
创建bloom索引
create index idx_bloom on text_char using bloom(id,col1,text_col);
查询速度会更快,
postgres=# explain analyze select * from text_char where id = md5(21::text);
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------
Bitmap Heap Scan on text_char (cost=60284.07..60288.08 rows=1 width=99) (actual time=24.221..87.174 rows=1 loops=1)
Recheck Cond: ((id)::text = '3c59dc048e8850243be8079a5c74d079'::text)
Rows Removed by Index Recheck: 16014
Heap Blocks: exact=14229
-> Bitmap Index Scan on idx_bloom (cost=0.00..60284.07 rows=1 width=0) (actual time=22.545..22.545 rows=16015 loops=1)
Index Cond: ((id)::text = '3c59dc048e8850243be8079a5c74d079'::text)
Planning Time: 0.203 ms
Execution Time: 87.323 ms
(8 rows)

