




背景
最近在使用数据仓库 Greenplum 时,频繁遭遇网络异常报错,报错信息: [ERROR: Interconnect encountered a network error, please check your network.]。不仅如此,每晚执行的数据处理存储过程也接连报错,起初我一直怀疑是网络出了问题。于是,我仔细检查了网络流程,可并未发现明显异常,即便上报给网络工程师,也未能排查出有效线索。就在我一筹莫展之际,偶然间在一篇名为《ERROR: Interconnect encountered a network error, please check your network》的文章中发现,这个报错竟然与系统和网络的 MTU 值有关。
- 报错截图

测试复现
- 测试方向:系统层:MTU修改;数据库层参数:gp_max_packet_size、gp_interconnect_type复现报错;网支层:交换机因设备过旧最高支持1500,无法调整此次忽略。
测试环境
| IP | 主机名 |
|---|---|
| 10.10.5.121 | gpdb-master |
| 10.10.5.122 | gpdb-standby |
测试一、系统层:MTU修改
- gpdb-standby 网卡MTU值调为:500;gpdb-master 网卡MTU值调为:1500;
# gpdb-standby
[root@gpdb-standby ~]# ifconfig | grep mtu
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
# 修改mtu :500
[root@gpdb-standby ~]# ifconfig eth0 mtu 500
[root@gpdb-standby ~]# ifconfig | grep mtu
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 500
# gpdb-master
[root@gpdb-master ~]# ifconfig | grep mtu
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
- 测试ping 1000 包,无法ping 通

- gpdb-standby 网卡MTU值调回:1500
[root@gpdb-standby ~]# ifconfig eth0 mtu 1500
[root@gpdb-standby ~]# ifconfig | grep mtu
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
- 测试ping 1000 包,可ping 通

小结:
- 多次测试后小结:
| ping 包 | gpdb-master mtu 发送 | gpdb-standby mtu 接收 | 结果 |
|---|---|---|---|
| 1000 | 1500 | 1500 | 通 |
| 1000 | 500 | 1500 | 不通 |
| 500 | 500 | 1500 | 通 |
测试二、数据库层:gp_max_packet_size
- Greenplum 默认的报文大小是 8KB,由 gp_max_packet_size 控制
[gpadmin@gpdb-master ~]$ gpconfig -s gp_max_packet_size
Values on all segments are consistent
GUC : gp_max_packet_size
Master value: 8192
Segment value: 8192
- 修改参数:gp_max_packet_size =1400
[gpadmin@gpdb-master ~]$ gpconfig -c gp_max_packet_size -v 1400
[gpadmin@gpdb-master ~]$ gpstop -r
测试1:gp_max_packet_size=8192
[gpadmin@gpdb-master ~]$ psql
psql (9.4.26)
Type "help" for help.
postgres=# show gp_max_packet_size ;
gp_max_packet_size
--------------------
8192
(1 row)
- 存储过程调用耗时:00:03:12
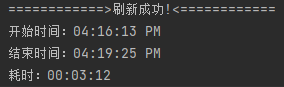
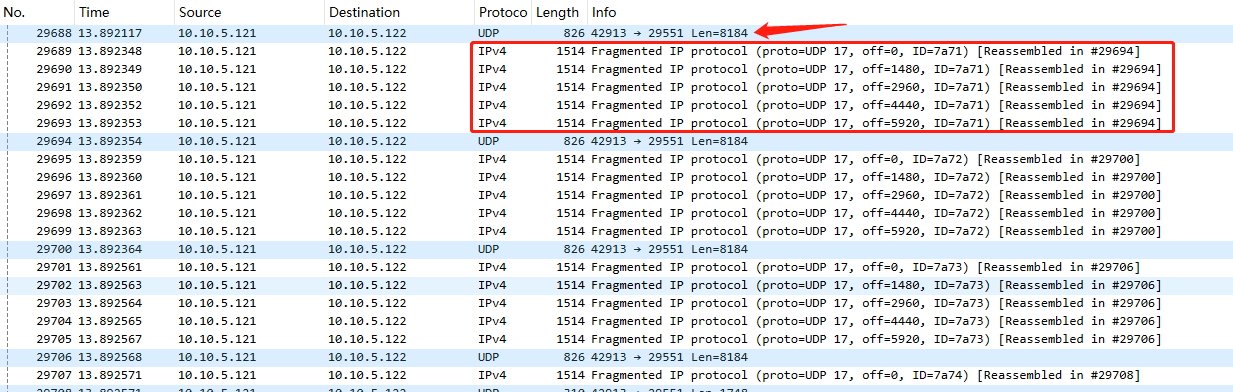
- tcpdump 抓包:协议:udp到10.10.5.122的包
tcpdump -i eth0 '((udp) and (dst host 10.10.5.122))' -w udp.capture.pcap
- 存在IPv4 拆包行为
测试2:gp_max_packet_size=1400
[gpadmin@gpdb-master ~]$ psql
psql (9.4.26)
Type "help" for help.
postgres=# show gp_max_packet_size ;
gp_max_packet_size
--------------------
1400
(1 row)
- 存储过程调用耗时:00:03:15
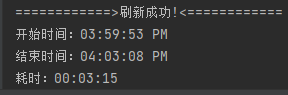
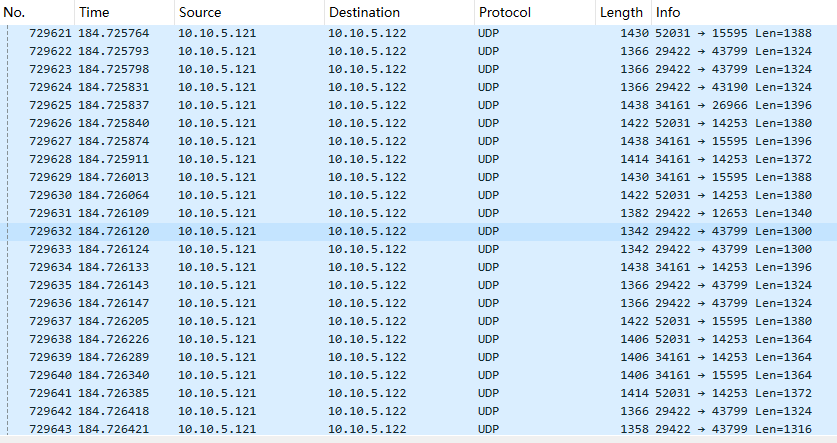
- 抓包,未见IPv4 拆包
测试三、数据库层:gp_interconnect_type
-
gp_interconnect_type:
设置interconnect的通信协议。有三种方式TCP/UDP/UDPIFC。对于复杂、slice多的查询,TCP多能够支持1000个segment实例。UDP能够支持更多的segment实例,且GP采用经过校验、检查的UDP,和TCP一样可靠。UDPIFC是UDP的流量控制版本,通过gp_interconnect_fc_method(默认:loss)来选择流控方式。 -
默认:gp_interconnect_type
postgres=# show gp_interconnect_type ;
gp_interconnect_type
----------------------
udpifc
(1 row)
[gpadmin@gpdb-master ~]$ gpconfig -s gp_interconnect_type
Values on all segments are consistent
GUC : gp_interconnect_type
Master value: udpifc
Segment value: udpifc
- 修改
[gpadmin@gpdb-master ~]$ gpconfig -c gp_interconnect_type -v TCP [gpadmin@gpdb-master ~]$ gpstop -r
- 查看
postgres=# show gp_interconnect_type;
gp_interconnect_type
tcp
(1 row)
postgres=# show gp_max_packet_size;
gp_max_packet_size
1400
(1 row)
- 存储过程调用耗时:00:06:01
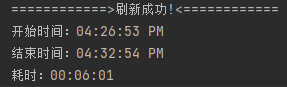
- 抓包:tcpdump -i eth0 ‘((tcp) and (dst host 10.10.5.122))’ -w tcp.capture.pcap
小结:
| 协议 | 参数值 | 耗时 | 备注 |
|---|---|---|---|
| udp | gp_max_packet_size:8192 | 00:03:12 | 有拆包 |
| udp | gp_max_packet_size:1400 | 00:03:15 | 无拆包 |
| tcp | gp_max_packet_size:1400 | 00:06:01 | tcp拆包 |
- 此次测试结论:gp_interconnect_type:udp; gp_max_packet_size:1400 无拆包行为,相对方案为优选
strace 追踪测试
- gp_max_packet_size
[gpadmin@gpdb-master ~]$ gpconfig -s gp_max_packet_size
Values on all segments are consistent
GUC : gp_max_packet_size
Master value: 8192
Segment value: 8192
- 查看会话进程号:
postgres=# SELECT pg_backend_pid();
pg_backend_pid
----------------
113726
(1 row)
postgres=# SELECT pid, usename, datname, query FROM pg_stat_activity;
pid | usename | datname | query
--------+---------------+-------------+--------------------------------------------------------------------------------------------
113726 | gpadmin | postgres | SELECT pid, usename, datname, query FROM pg_stat_activity;
- 根据进程PID:113726 进行追踪:strace -p 113726
如果一个进程已经在运行,你可以通过它的pid进行追踪,它会显示追踪后这个进程的系统调用。

- 执行:select * from bytea_test;
- sendto 信息
sendto(10, "87878787878787878787878787878787"..., 8192, 0, NULL, 0) = 8192
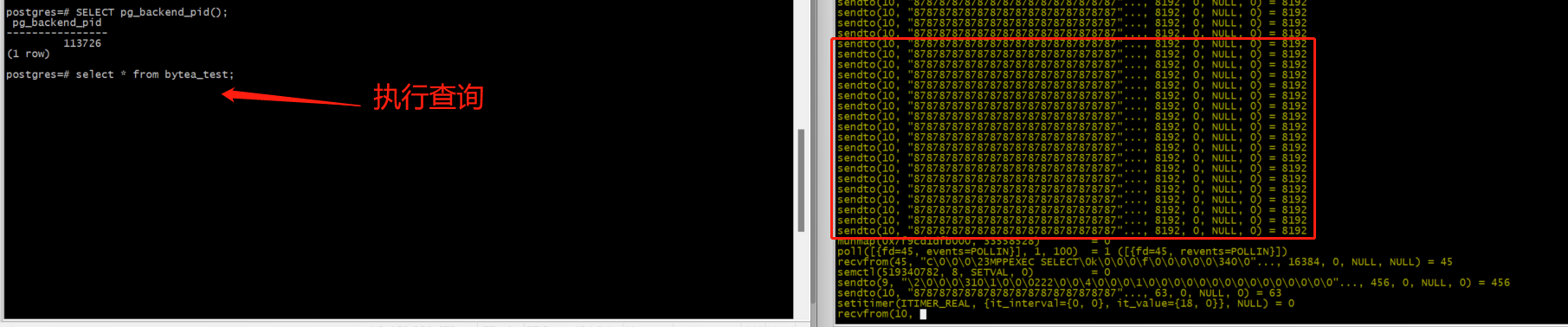
- 修改gp_max_packet_size:1492
[gpadmin@gpdb-master ~]$ gpconfig -c gp_max_packet_size -v 1492
20241227:10:33:17:117546 gpconfig:gpdb-master:gpadmin-[INFO]:-completed successfully with parameters '-c gp_max_packet_size -v 1492'
-- 重启
[gpadmin@gpdb-master ~]$ gpstop -r
[gpadmin@gpdb-master ~]$ gpconfig -s gp_max_packet_size
Values on all segments are consistent
GUC : gp_max_packet_size
Master value: 1492
Segment value: 1492
- strace 追踪仍然为:8192
小结:
- gp_max_packet_size 调整未对strace的追踪sendto未有影响
总结
- 避免出现查询时的网络异常,就需要禁止网络拆包:mtu 值:db 包<系统mtu值<网络交换机mtu值;
- UDP比TCP传输效率高一倍,因此建议使用:gp_interconnect_type=UDP;
- strace的追踪,与gp_max_packet_size 无关联,也可能是我的测试有遗漏,欢迎大家指正
- 通过此次测试,我们最终确定调整方案为:gp_max_packet_size=1400 低于系统和网络的MTU值(1500),目前来看此报错未再出现,查询效率也未降低。
欢迎赞赏支持或留言指正

「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
