






01
摘要
02
主要内容

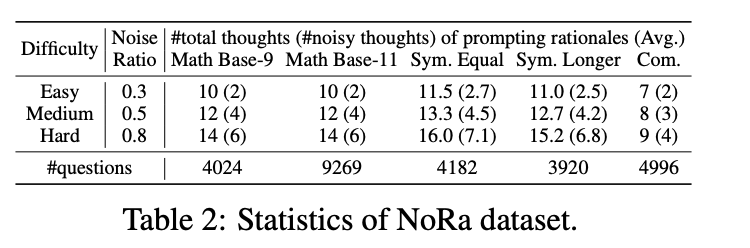
NoRA数据集
NoRa 数据集是一个专门用于评估LLM推理鲁棒性的数据集,包含了三种类型的推理任务:
数学推理 (NoRa-Math): 包括两种子任务: 九进制加法 (Base-9 Addition): 考察模型在不同进制下的计算能力。 十一进制加法 (Base-11 Addition): 进一步提升难度,考察模型对不同进制规则的理解和应用。 符号推理 (NoRa-Symbolic): 利用 SCAN 数据集,将自然语言转换为符号指令,包含两种子任务: 等长子任务 (Equal-length Subtask): 转换后的指令长度与示例和测试问题相同。 长长度子任务 (Longer-length Subtask): 转换后的指令长度比示例中的指令更长,更具挑战性。 常识推理 (NoRa-Commonsense): 基于 CLUTRR 数据集,考察模型对家庭关系路径的理解和推理能力。
实验中使用的Baseline方法
本文实验设计中采用了三大类Baseline方法:自我纠错方法、自我一致性方法和外部监督方法,以探索不同角度提升LLM的推理能力。以下是各方法的总结及其作用分析:
1. 自我纠错方法
目标:鼓励LLM自主发现问题并改正。
实现方式:通过明确的提示语,要求模型审查自己的答案,找出错误并加以改进。
作用:考察模型在无额外信息情况下的自我反思与改进能力。
目标:通过多轮精炼,减少噪声信息并重组逻辑结构。 实现方式:对带噪声的CoT(思维链)示例多次单独优化,最终组合成更清晰的上下文作为任务输入。 作用:适用于消除上下文噪声对模型推理的干扰,同时提升逻辑结构的清晰度。
2. 自我一致性方法
目标:通过对提示添加扰动来增强模型对输入噪声的鲁棒性。 实现方式:在每次推理中使用不同形式的带噪声提示,重复任务多次后采用多数投票选出答案。 作用:验证模型在面对不同形式输入时的一致性,同时提高抗干扰能力。
目标:通过部分内容随机掩码并重建,减少推理过程中噪声的影响。
实现方式:对带噪声的示例进行掩码处理,要求模型推理并填补缺失部分,重复多次后通过多数投票确定答案。
作用:提高模型的推理连贯性,同时通过填补掩码部分来训练模型的细粒度理解能力。
目标:通过采样多次模型输出来提升推理性能。
实现方式:对同一任务重复推理多次,选择最常见的答案作为最终输出。
作用:简单高效,适用于不需要对输入进行复杂处理的情况。
3. 外部监督方法
目标:结合ISC和真实答案的监督,进一步优化模型的输出。 实现方式:在每轮修正中提供真实答案,允许模型最多调整两次,直到获得正确答案。 作用:通过外部监督验证模型的修正能力,适用于任务中具有明确答案的场景。
目标:定位并纠正推理中的第一处错误。 实现方式:提供噪声推理中首个错误的具体位置,提示模型修正该错误并生成新的上下文。 作用:以较低的监督成本提高推理准确性,适用于复杂推理链条的优化。
目标:通过对比学习增强模型的泛化能力。 实现方式:提供干净推理(正示例)和带噪声推理(负示例)的对比示例,利用对比结构的提示引导模型推理。 作用:帮助模型更好地区分有效与无效推理过程,提升对新任务的适应性。
实验结论
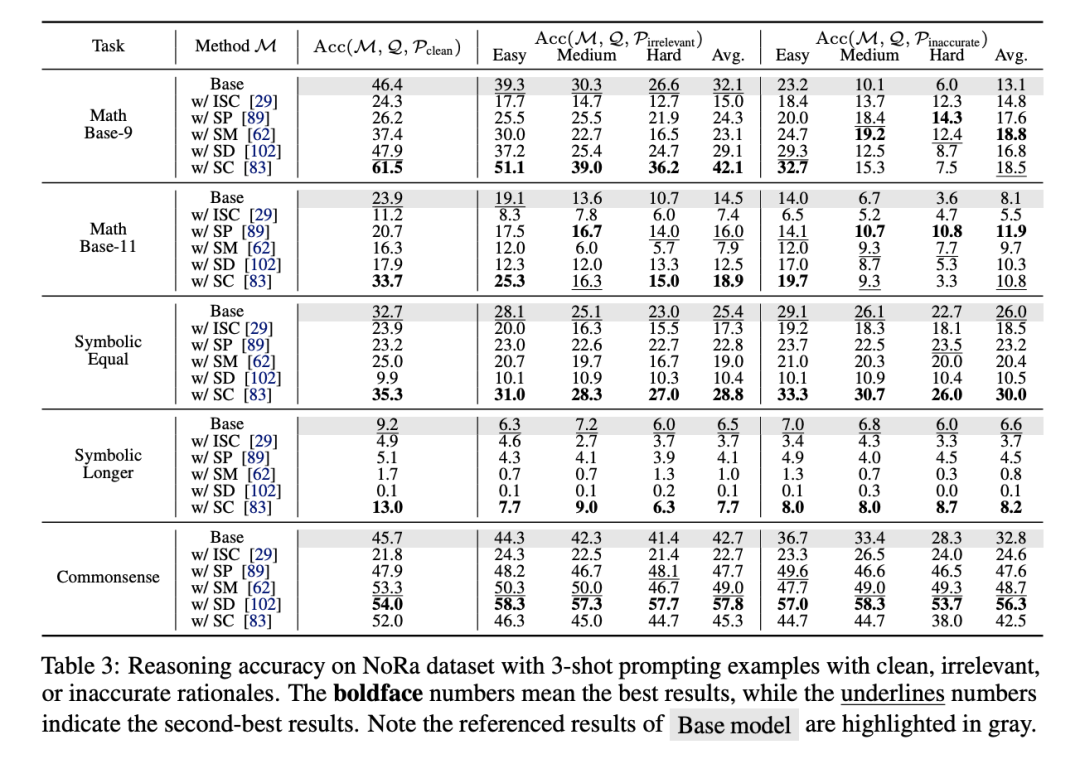
Observation 1: 自我纠错方法在带噪声推理任务上的表现较差
ISC 和 SP 方法过于依赖LLM的内在能力,但缺乏外部反馈的支持,容易导致错误修正(Miscorrection)。 SP 在常识任务中略有改进,但总体性能仍然低于基线模型。 结果表明,自我纠错方法难以有效应对噪声推理场景。
Observation 2: 自我一致性方法可以提升鲁棒性但无法真正去噪
SM 和 SD 方法原用于处理带噪声的问题输入(Noisy-Q),在处理带噪声推理步骤(Noisy-R)时,容易破坏逻辑链条的内在一致性。
SC 方法通过多次采样并进行投票,提升了模型在干净和带噪声任务下的表现,但未显式去噪。
代价:SC 需要较高的计算成本。
Observation 3: 调整温度对噪声推理有帮助
在3-shot 示例中,降低温度(例如从1降到更低值)可以提升噪声和干净推理的准确性。
但过低的温度(如0)会导致冗长、重复的响应,尤其在符号化任务中显著增加了Token消耗。
Observation 4: 使用更多带噪声示例可以提升大部分任务的推理准确性
增加带噪声的示例数量有助于模型在大多数任务中提高准确率。
限制性问题:在高噪声场景(如NoRa-Math任务)中,示例数量的增加反而会降低准确率,尤其在某些任务中表现甚至不如0-shot的水平。
Observation 5: 不同LLMs对噪声推理的脆弱性
Gemini-Pro 优于 GPT-3.5,但对噪声仍敏感,在不相关推理场景中性能下降2.4%-15.7%,在错误推理场下降7.8%-66.8%。
Mixtral 8x7B 表现略逊于 GPT-3.5,但噪声导致的性能下降范围较小。
Llama2-70B 表现相对较差,但对噪声的敏感性也更低。
Observation 6: 提示示例的映射破坏会退化推理,但仍优于无提示的情况
对问题、推理步骤(Rationales)、答案进行三种随机打乱测试。 尽管打乱后退化了推理能力,但依然优于完全无提示的情况。
LLM更依赖提示中抽象任务信息的学习,而非仅仅记忆具体问题和答案。 然而,噪声引入的误导比映射打乱对性能的影响更大,说明推理步骤的质量对推理结果的影响更为关键。
CD-CoT框架
输入一个干净 CoT 示例和一个噪声 CoT 示例。 通过对比学习,模型学习从干净示例中获取信息,并重述噪声示例中的理由。 生成多个重述后的理由,每个噪声示例生成 N 个重述理由。
对比重述后的理由与原始干净示例的答案。 选择那些重述后答案与原始答案一致的理由作为候选。 从每个候选集中随机选择 M 个理由。
将 M 个理由与干净示例和测试问题组合成 M 个不同的输入。 使用 LLM 对每个输入进行推理,生成 D 个不同的答案。
对 D 个答案进行投票,选择出现次数最多的答案作为最终答案。
03
总结
04
编者简介
