




作者:Digital Observer(施嘉伟)
Oracle ACE Pro: Database
PostgreSQL ACE Partner
11年数据库行业经验,现主要从事数据库服务工作
拥有Oracle OCM、DB2 10.1 Fundamentals、MySQL 8.0 OCP、WebLogic 12c OCA、KCP、PCTP、PCSD、PGCM、OCI、PolarDB技术专家、达梦师资认证、数据安全咨询高级等认证
ITPUB认证专家、PolarDB开源社区技术顾问、HaloDB技术顾问、TiDB社区技术布道师、青学会MOP技术社区专家顾问、国内某高校企业实践指导教师
一 现象描述
XX客户于1月14号凌晨业务中断,检查数据库发现数据库集群宕机。
XX客户于2月14号春节初五早上业务异常,连接数据库无响应。
二 问题详细诊断
1月14号故障
1月14号凌晨2点,客户反馈业务中断,发现节点1无法连接,客户联系云工程师紧急处理,凌晨4点半节点1可以连接。
节点2连接正常,检查发现节点2集群服务异常。
检查节点2数据库日志发现:
在1点43分节点2等待事件log file parallel write超时80秒,LGWR挂起超过70秒,Lgwr为数据库核心进程,出现异常时会导致数据库不可用。

检查节点2 I/O使用情况:
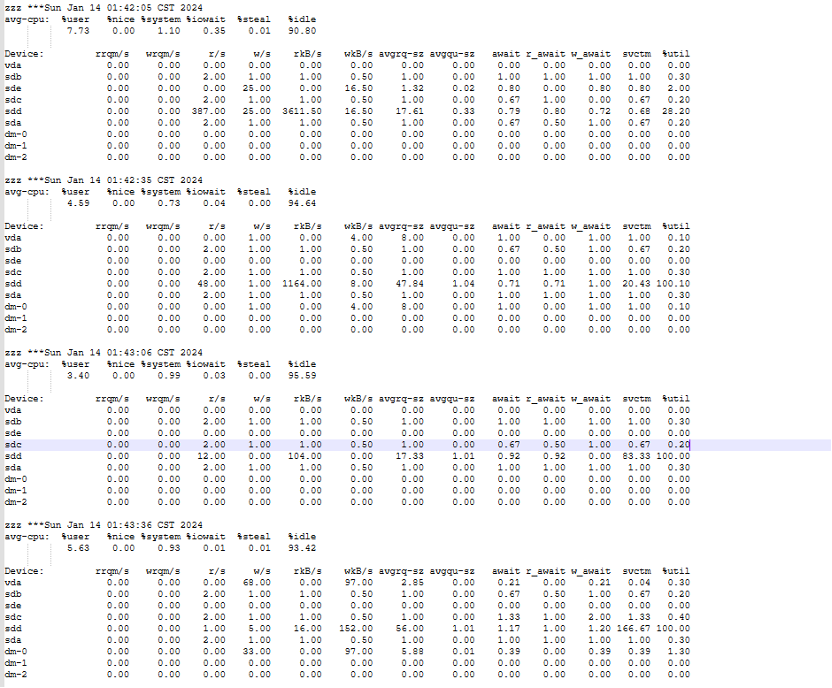
可以看到在1点42分开始 读写I/O很低的情况下%util跑满,说明I/O已经100%跑满,已经来不及处理。
再查看节点2集群日志
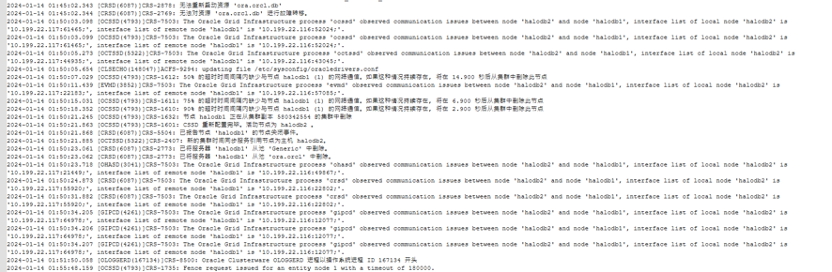
发现在1点50分节点2和节点1的私网通信异常,导致节点2被驱逐。
节点1数据库日志
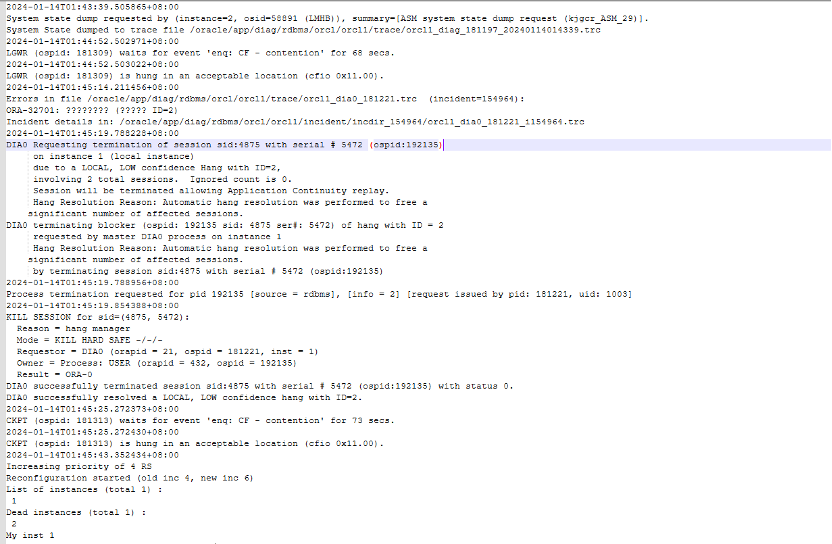
节点1在1点45分出现ORA错误 检查trc日志文件
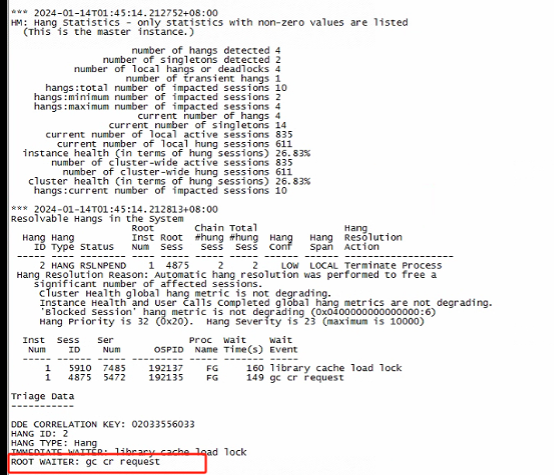
发现等待事件为gc等待
由于所有的跨节点访问都会先由lgwr进程写入日志,此时lgwr写入挂起导致无法响应gc请求,紧接着节点1 kill该会话,检测到节点2实例终止然后发起Reconfiguration。
4点13分在主机工程师修复节点1后,启动集群业务恢复正常。
检查节点1操作系统日志,数据库日志,集群日志未发现其他异常。
检查节点1主机重启记录,发现节点1在1点51分已经重启,重启失败操作系统进入救援模式
reboot system boot 3.10.0-1160.el7. Sun Jan 14 01:51 - 03:51 (02:00
2月14号故障
查看节点2数据库日志
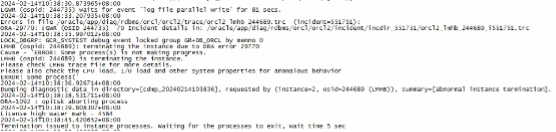
在2月14号10点38分 数据库出现lgwr异常,log file parallel write 写入异常。紧接着节点2实例终止。
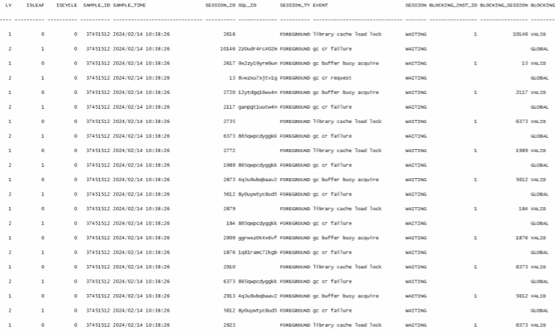
分析DBA_HIST_ACTIVE_SESS_HISTORY 可以看到在实例重启前会话最终都被gc事件阻塞
三 故障原因
在1月14号的故障中,1点42分节点2 lgwr异常导致节点2在1点43分宕机,节点2在1点50分主机异常重启,重启失败进入救援模式导致整个集群不可用。
在2月14号的故障中,10点37分15秒开始由于节点2 数据库核心进程lgwr异常,导致节点1的gc请求全部挂起,最终导致节点2宕机,在11点05分恢复正常。
在2次故障中,均由于lgwr进程异常挂起等待log file parallel write引起节点宕机,造成该等待事件的原因为磁盘等待IO写入,I/O响应出现了异常。
四 建议
1、将数据库由虚拟机平台迁到更加稳定物理机上。
2、排查虚拟化平台I/O等待的原因并解决。

