





这里谈谈排序与分组聚合。这两类操作往往存在一定相关性。
【系列文章】
1).常见排序操作
下面针对常见的排序类操作,抽象出一组测例,看看Oracle和国产库的行为如何。
❖ SORT UNIQUE
排序去重类,把查询语句的输出结果变为唯一集合的过程。使用场景包括:语句中使用了DISTINCT、子查询向主查询提供执行结果。在Oracle 10g以后的版本中,SORT UNIQUE 变成 HASH UNIQUE,利用新的HASH算法代替了传统的排序。但在使用子查询的场景下,因为优先执行子查询,子查询放在主查询之前。由于主查询的结果必须存在于子查询的结果中。在这里要将作为"M"集合的子查询转换为不允许重复元素存在的"1"集合,所以执行了SORT(UNIQUE)。
❖ SORT AGGREGATE
这是指在没有 GROUP BY 的前提下,使用统计函数对全部数据对象进行计算时所显示出来的执行计划。在使用SUM、COUNT、MIN、MAX、AVG等统计函数时并不执行一般排序动作。实际上是读取每一行数据为对象进行求和、计数、比较大小等操作,可通过一个全局变量+全表/全索引扫描来实现。
❖ SORT GROUP BY
该操作是将数据行向不同分组中聚集的操作,即依据查询语句中所使用的GROUP BY而进行相关操作,为了进行分组就只能排序。需要分组的数据量越大,代价就越大。在10gR2以后的版本中,哈希分组-HASH (GROUPBY)。在处理海量数据时使用哈希处理比使用排序处理更有效。
❖ SORT ORDER BY
当对一个不能满足索引列进行排序时,就需要一个SORT ORDER BY。这里可以有个优化,针对取出排序结果前几条的场景,是可以提前结束排序动作,节省资源。
❖ SORT JOIN
在表关联的场景中,如果行按照连接键排序,在排序合并连接时将会发生SORT JOIN。SORT JOIN 发生在出现MERGE JOIN的情况下,两张关联的表要各自做SORT,然后在MERGE。
2).Oracle 测试示例
-- SORT UNIQUE
SQL> explain plan for select distinct dept_id,emp_name from emp where salary<1100;
SQL> select * from table(dbms_xplan.display);
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 898 | 14368 | 16 (7)| 00:00:01 |
| 1 | HASH UNIQUE | | 898 | 14368 | 16 (7)| 00:00:01 |
|* 2 | TABLE ACCESS FULL| EMP | 898 | 14368 | 15 (0)| 00:00:01 |
---------------------------------------------------------------------------
SQL> explain plan for select * from dept where dept_id in (select dept_id from emp where salary<1100);
SQL> select * from table(dbms_xplan.display);
----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 100 | 2300 | 18 (6)| 00:00:01 |
| 1 | MERGE JOIN SEMI | | 100 | 2300 | 18 (6)| 00:00:01 |
| 2 | TABLE ACCESS BY INDEX ROWID| DEPT | 100 | 1500 | 2 (0)| 00:00:01 |
| 3 | INDEX FULL SCAN | DEPT_PK | 100 | | 1 (0)| 00:00:01 |
|* 4 | SORT UNIQUE | | 898 | 7184 | 16 (7)| 00:00:01 |
|* 5 | TABLE ACCESS FULL | EMP | 898 | 7184 | 15 (0)| 00:00:01 |
----------------------------------------------------------------------------------------
-- SORT AGGREGATE
SQL> explain plan for select sum(salary) from emp;
SQL> select * from table(dbms_xplan.display);
----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 5 | 10 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 5 | | |
| 2 | INDEX FAST FULL SCAN| IDX_EMP_SALARY | 10000 | 50000 | 10 (0)| 00:00:01 |
----------------------------------------------------------------------------------------
SQL> explain plan for select min(salary),max(salary) from emp;
SQL> select * from table(dbms_xplan.display);
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 5 | 15 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 5 | | |
| 2 | TABLE ACCESS FULL| EMP | 10000 | 50000 | 15 (0)| 00:00:01 |
---------------------------------------------------------------------------
-- SORT GROUP BY
SQL> explain plan for select dept_id,count(*) from emp group by dept_id;
SQL> select * from table(dbms_xplan.display);
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 100 | 300 | 16 (7)| 00:00:01 |
| 1 | HASH GROUP BY | | 100 | 300 | 16 (7)| 00:00:01 |
| 2 | TABLE ACCESS FULL| EMP | 10000 | 30000 | 15 (0)| 00:00:01 |
---------------------------------------------------------------------------
-- SORT(ORDER BY)
SQL> explain plan for select * from emp order by dept_id;
SQL> select * from table(dbms_xplan.display);
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 10000 | 273K| 16 (7)| 00:00:01 |
| 1 | SORT ORDER BY | | 10000 | 273K| 16 (7)| 00:00:01 |
| 2 | TABLE ACCESS FULL| EMP | 10000 | 273K| 15 (0)| 00:00:01 |
---------------------------------------------------------------------------
SQL> explain plan for select * from (select * from emp order by salary desc) where rownum<=10;
SQL> select * from table(dbms_xplan.display);
--------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 10 | 650 | 16 (7)| 00:00:01 |
|* 1 | COUNT STOPKEY | | | | | |
| 2 | VIEW | | 10000 | 634K| 16 (7)| 00:00:01 |
|* 3 | SORT ORDER BY STOPKEY| | 10000 | 273K| 16 (7)| 00:00:01 |
| 4 | TABLE ACCESS FULL | EMP | 10000 | 273K| 15 (0)| 00:00:01 |
--------------------------------------------------------------------------------
-- SORT JOIN
SQL> explain plan for select *+ use_merge(e d)*/ e.emp_name,d.dept_name from emp e,dept d where e.dept_id=d.dept_id;
SQL> select * from table(dbms_xplan.display);
----------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)|
----------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 10000 | 205K| 20 (15)|
| 1 | MERGE JOIN | | 10000 | 205K| 20 (15)|
| 2 | SORT JOIN | | 100 | 1000 | 4 (50)|
| 3 | VIEW | index$_join$_002 | 100 | 1000 | 3 (34)|
|* 4 | HASH JOIN | | | | |
| 5 | INDEX FAST FULL SCAN| DEPT_PK | 100 | 1000 | 1 (0)|
| 6 | INDEX FAST FULL SCAN| IDX_DEPT_NAME | 100 | 1000 | 1 (0)|
|* 7 | SORT JOIN | | 10000 | 107K| 16 (7)|
| 8 | TABLE ACCESS FULL | EMP | 10000 | 107K| 15 (0)|
----------------------------------------------------------------------------------
3).国产库测试示例
下面是针对上述测例,国产库的行为如何?先来看看整体结果
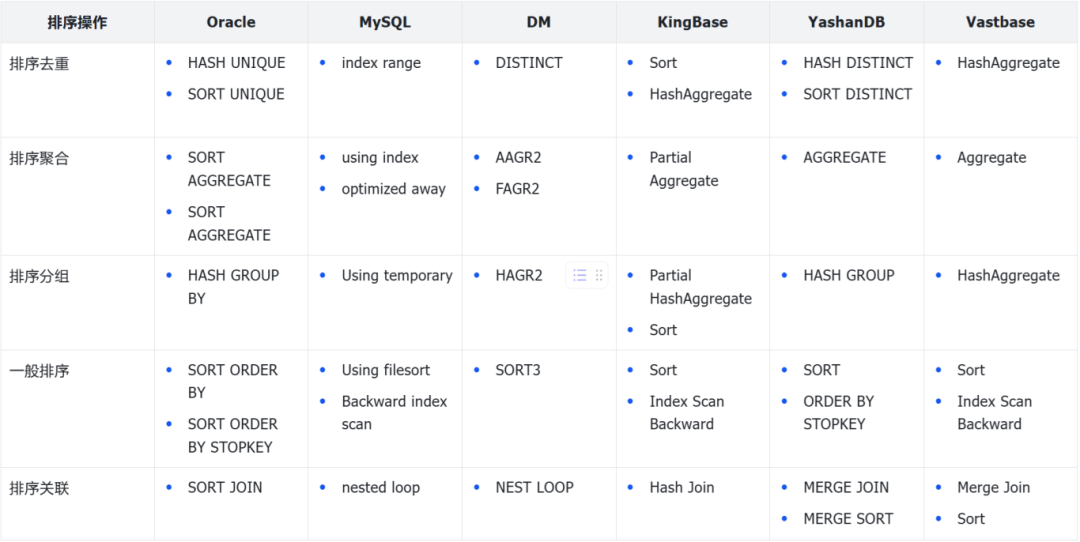
❖ MySQL
-- SORT UNIQUE
mysql> explain select distinct dept_id,emp_name from emp where salary<1100;
+----+-------------+-------+------------+-------+----------------+----------------+---------+------+------+----------+----------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+----------------+----------------+---------+------+------+----------+----------------------------------------+
| 1 | SIMPLE | emp | NULL | range | idx_emp_salary | idx_emp_salary | 5 | NULL | 459 | 100.00 | Using index condition; Using temporary |
+----+-------------+-------+------------+-------+----------------+----------------+---------+------+------+----------+----------------------------------------+
mysql> explain select * from dept where dept_id in (select dept_id from emp where salary<1100);
+----+--------------+-------------+------------+--------+---------------------+---------------------+---------+---------------------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+--------------+-------------+------------+--------+---------------------+---------------------+---------+---------------------+------+----------+-----------------------+
| 1 | SIMPLE | dept | NULL | ALL | PRIMARY | NULL | NULL | NULL | 100 | 100.00 | NULL |
| 1 | SIMPLE | <subquery2> | NULL | eq_ref | <auto_distinct_key> | <auto_distinct_key> | 5 | testdb.dept.dept_id | 1 | 100.00 | NULL |
| 2 | MATERIALIZED | emp | NULL | range | idx_emp_salary | idx_emp_salary | 5 | NULL | 459 | 100.00 | Using index condition |
+----+--------------+-------------+------------+--------+---------------------+---------------------+---------+---------------------+------+----------+-----------------------+
-- SORT AGGREGATE
mysql> explain select sum(salary) from emp;
+----+-------------+-------+------------+-------+---------------+----------------+---------+------+-------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+----------------+---------+------+-------+----------+-------------+
| 1 | SIMPLE | emp | NULL | index | NULL | idx_emp_salary | 5 | NULL | 10117 | 100.00 | Using index |
+----+-------------+-------+------------+-------+---------------+----------------+---------+------+-------+----------+-------------+
mysql> explain select min(salary),max(salary) from emp;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+------------------------------+
| 1 | SIMPLE | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | Select tables optimized away |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+------------------------------+
-- SORT GROUP BY
mysql> explain select dept_id,count(*) from emp group by dept_id;
+----+-------------+-------+------------+------+---------------+------+---------+------+-------+----------+-----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+-------+----------+-----------------+
| 1 | SIMPLE | emp | NULL | ALL | NULL | NULL | NULL | NULL | 10117 | 100.00 | Using temporary |
+----+-------------+-------+------------+------+---------------+------+---------+------+-------+----------+-----------------+
-- SORT(ORDER BY)
mysql> explain select * from emp order by dept_id;
+----+-------------+-------+------------+------+---------------+------+---------+------+-------+----------+----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+-------+----------+----------------+
| 1 | SIMPLE | emp | NULL | ALL | NULL | NULL | NULL | NULL | 10117 | 100.00 | Using filesort |
+----+-------------+-------+------------+------+---------------+------+---------+------+-------+----------+----------------+
mysql> explain select * from (select * from emp order by salary desc) a limit 10;
+----+-------------+-------+------------+-------+---------------+----------------+---------+------+------+----------+---------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+----------------+---------+------+------+----------+---------------------+
| 1 | SIMPLE | emp | NULL | index | NULL | idx_emp_salary | 5 | NULL | 10 | 100.00 | Backward index scan |
+----+-------------+-------+------------+-------+---------------+----------------+---------+------+------+----------+---------------------+
-- SORT JOIN
mysql> explain select e.emp_name,d.dept_name from emp e,dept d where e.dept_id=d.dept_id;
+----+-------------+-------+------------+--------+---------------+---------+---------+------------------+-------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+--------+---------------+---------+---------+------------------+-------+----------+-------------+
| 1 | SIMPLE | e | NULL | ALL | NULL | NULL | NULL | NULL | 10117 | 100.00 | Using where |
| 1 | SIMPLE | d | NULL | eq_ref | PRIMARY | PRIMARY | 4 | testdb.e.dept_id | 1 | 100.00 | NULL |
+----+-------------+-------+------------+--------+---------------+---------+---------+------------------+-------+----------+-------------+
❖ DM
-- SORT UNIQUE
SQL> explain select distinct dept_id,emp_name from emp where salary<1100;
1 #NSET2: [2, 885, 108]
2 #PRJT2: [2, 885, 108]; exp_num(2), is_atom(FALSE)
3 #DISTINCT: [2, 885, 108]
4 #BLKUP2: [1, 885, 108]; IDX_EMP_SALARY(EMP)
5 #SSEK2: [1, 885, 108]; scan_type(ASC), IDX_EMP_SALARY(EMP), scan_range(null2,exp_cast(1100)), is_global(0)
SQL> explain select * from dept where dept_id in (select dept_id from emp where salary<1100);
1 #NSET2: [1, 100, 138]
2 #PRJT2: [1, 100, 138]; exp_num(4), is_atom(FALSE)
3 #HASH LEFT SEMI JOIN2: [1, 100, 138]; KEY_NUM(1); KEY(DEPT.DEPT_ID=EMP.DEPT_ID) KEY_NULL_EQU(0)
4 #CSCN2: [1, 100, 138]; INDEX33555480(DEPT); btr_scan(1)
5 #BLKUP2: [1, 885, 60]; IDX_EMP_SALARY(EMP)
6 #SSEK2: [1, 885, 60]; scan_type(ASC), IDX_EMP_SALARY(EMP), scan_range(null2,exp_cast(1100)), is_global(0)
-- SORT AGGREGATE
SQL> explain select sum(salary) from emp;
1 #NSET2: [1, 1, 30]
2 #PRJT2: [1, 1, 30]; exp_num(1), is_atom(FALSE)
3 #AAGR2: [1, 1, 30]; grp_num(0), sfun_num(1), distinct_flag[0]; slave_empty(0)
4 #SSCN: [1, 10000, 30]; IDX_EMP_SALARY(EMP); btr_scan(1); is_global(0)
SQL> explain select min(salary),max(salary) from emp;
1 #NSET2: [1, 1, 30]
2 #PRJT2: [1, 1, 30]; exp_num(2), is_atom(FALSE)
3 #FAGR2: [1, 1, 30]; sfun_num(2), IDX_EMP_SALARY
-- SORT GROUP BY
SQL> explain select dept_id,count(*) from emp group by dept_id;
1 #NSET2: [2, 100, 30]
2 #PRJT2: [2, 100, 30]; exp_num(2), is_atom(FALSE)
3 #HAGR2: [2, 100, 30]; grp_num(1), sfun_num(1), distinct_flag[0]; slave_empty(0) keys(EMP.DEPT_ID)
4 #CSCN2: [1, 10000, 30]; INDEX33555484(EMP); btr_scan(1)
-- SORT(ORDER BY)
SQL> explain select * from emp order by dept_id;
1 #NSET2: [2, 10000, 163]
2 #PRJT2: [2, 10000, 163]; exp_num(6), is_atom(FALSE)
3 #SORT3: [2, 10000, 163]; key_num(1), partition_key_num(0), is_distinct(FALSE), top_flag(0), is_adaptive(0)
4 #CSCN2: [1, 10000, 163]; INDEX33555484(EMP); btr_scan(1)
SQL> explain select * from (select * from emp order by salary desc) a limit 10;
1 #NSET2: [4, 10, 205]
2 #PRJT2: [4, 10, 205]; exp_num(6), is_atom(FALSE)
3 #SORT3: [4, 10, 205]; key_num(1), partition_key_num(0), is_distinct(FALSE), top_flag(0), is_adaptive(0)
4 #HASH2 INNER JOIN: [3, 10, 205]; LKEY_UNIQUE KEY_NUM(1); KEY(DMTEMPVIEW_889193478.colname=EMP.ROWID) KEY_NULL_EQU(0)
5 #NEST LOOP INDEX JOIN2: [3, 10, 205]
6 #ACTRL: [3, 10, 205]
7 #DISTINCT: [3, 10, 42]
8 #PRJT2: [2, 10, 42]; exp_num(1), is_atom(FALSE)
9 #PRJT2: [2, 10, 42]; exp_num(1), is_atom(FALSE)
10 #SORT3: [2, 10, 42]; key_num(1), partition_key_num(0), is_distinct(FALSE), top_flag(1), is_adaptive(0)
11 #SSCN: [1, 10000, 42]; IDX_EMP_SALARY(EMP); btr_scan(1); is_global(0)
12 #CSEK2: [1, 1, 0]; scan_type(ASC), INDEX33555484(EMP), scan_range[DMTEMPVIEW_889193478.colname,DMTEMPVIEW_889193478.colname]
13 #CSCN2: [1, 10000, 163]; INDEX33555484(EMP); btr_scan(1)
-- SORT JOIN
SQL> explain select e.emp_name,d.dept_name from emp e,dept d where e.dept_id=d.dept_id;
1 #NSET2: [2, 10000, 156]
2 #PRJT2: [2, 10000, 156]; exp_num(2), is_atom(FALSE)
3 #HASH2 INNER JOIN: [2, 10000, 156]; LKEY_UNIQUE KEY_NUM(1); KEY(D.DEPT_ID=E.DEPT_ID) KEY_NULL_EQU(0)
4 #CSCN2: [1, 100, 78]; INDEX33555480(DEPT as D); btr_scan(1)
5 #CSCN2: [1, 10000, 78]; INDEX33555484(EMP as E); btr_scan(1)
SQL> explain select *+ use_merge(e d)*/ e.emp_name,d.dept_name from emp e,dept d where e.dept_id=d.dept_id;
1 #NSET2: [638801, 10000, 156]
2 #PRJT2: [638801, 10000, 156]; exp_num(2), is_atom(FALSE)
3 #SLCT2: [638801, 10000, 156]; E.DEPT_ID = D.DEPT_ID
4 #NEST LOOP INNER JOIN2: [638801, 10000, 156]
5 #CSCN2: [1, 10000, 78]; INDEX33555484(EMP as E); btr_scan(1)
6 #CSCN2: [1, 100, 78]; INDEX33555480(DEPT as D); btr_scan(1)
❖ KingBase
-- SORT UNIQUE
TEST=# explain select distinct dept_id,emp_name from emp where salary<1100;
QUERY PLAN
------------------------------------------------------------------------------------------------
Unique (cost=22893.03..23577.57 rows=91272 width=20)
-> Sort (cost=22893.03..23121.21 rows=91272 width=20)
Sort Key: dept_id, emp_name
-> Bitmap Heap Scan on emp (cost=2183.78..13500.68 rows=91272 width=20)
Recheck Cond: (salary < '1100'::double precision)
-> Bitmap Index Scan on idx_emp_salary (cost=0.00..2160.97 rows=91272 width=0)
Index Cond: (salary < '1100'::double precision)
TEST=# explain select * from dept where dept_id in (select dept_id from emp where salary<1100);
QUERY PLAN
------------------------------------------------------------------------------------------------------
Hash Join (cost=13731.14..13734.51 rows=100 width=29)
Hash Cond: (dept.dept_id = emp.dept_id)
-> Seq Scan on dept (cost=0.00..2.00 rows=100 width=29)
-> Hash (cost=13729.87..13729.87 rows=101 width=5)
-> HashAggregate (cost=13728.86..13729.87 rows=101 width=5)
Group Key: emp.dept_id
-> Bitmap Heap Scan on emp (cost=2183.78..13500.68 rows=91272 width=5)
Recheck Cond: (salary < '1100'::double precision)
-> Bitmap Index Scan on idx_emp_salary (cost=0.00..2160.97 rows=91272 width=0)
Index Cond: (salary < '1100'::double precision)
-- SORT AGGREGATE
TEST=# explain select sum(salary) from emp;
QUERY PLAN
---------------------------------------------------------------------------------------
Finalize Aggregate (cost=16384.55..16384.56 rows=1 width=8)
-> Gather (cost=16384.33..16384.54 rows=2 width=8)
Workers Planned: 2
-> Partial Aggregate (cost=15384.33..15384.34 rows=1 width=8)
-> Parallel Seq Scan on emp (cost=0.00..14342.67 rows=416667 width=8)
TEST=# explain select min(salary),max(salary) from emp;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------
Result (cost=1.01..1.02 rows=1 width=16)
InitPlan 1 (returns $0)
-> Limit (cost=0.42..0.50 rows=1 width=8)
-> Index Only Scan using idx_emp_salary on emp (cost=0.42..71128.49 rows=904233 width=8)
Index Cond: (salary IS NOT NULL)
InitPlan 2 (returns $1)
-> Limit (cost=0.42..0.50 rows=1 width=8)
-> Index Only Scan Backward using idx_emp_salary on emp emp_1 (cost=0.42..71128.49 rows=904233 width=8)
Index Cond: (salary IS NOT NULL)
-- SORT GROUP BY
TEST=# explain select dept_id,count(*) from emp group by dept_id;
QUERY PLAN
---------------------------------------------------------------------------------------------
Finalize GroupAggregate (cost=17430.40..17455.99 rows=101 width=13)
Group Key: dept_id
-> Gather Merge (cost=17430.40..17453.97 rows=202 width=13)
Workers Planned: 2
-> Sort (cost=16430.37..16430.63 rows=101 width=13)
Sort Key: dept_id
-> Partial HashAggregate (cost=16426.00..16427.01 rows=101 width=13)
Group Key: dept_id
-> Parallel Seq Scan on emp (cost=0.00..14342.67 rows=416667 width=5)
-- SORT(ORDER BY)
TEST=# explain select * from emp order by dept_id;
QUERY PLAN
----------------------------------------------------------------------------------
Gather Merge (cost=67056.00..164285.09 rows=833334 width=42)
Workers Planned: 2
-> Sort (cost=66055.98..67097.65 rows=416667 width=42)
Sort Key: dept_id
-> Parallel Seq Scan on emp (cost=0.00..14342.67 rows=416667 width=42)
TEST=# explain select * from (select * from emp order by salary desc) a limit 10;
QUERY PLAN
----------------------------------------------------------------------------------------------------
Limit (cost=0.42..1.24 rows=10 width=42)
-> Index Scan Backward using idx_emp_salary on emp (cost=0.42..71848.41 rows=1000000 width=42)
-- SORT JOIN
TEST=# explain select e.emp_name,d.dept_name from emp e,dept d where e.dept_id=d.dept_id;
QUERY PLAN
----------------------------------------------------------------------
Hash Join (cost=3.25..22914.40 rows=990099 width=28)
Hash Cond: (e.dept_id = d.dept_id)
-> Seq Scan on emp e (cost=0.00..20176.00 rows=1000000 width=20)
-> Hash (cost=2.00..2.00 rows=100 width=18)
-> Seq Scan on dept d (cost=0.00..2.00 rows=100 width=18)
❖ YashanDB
-- SORT UNIQUE
SQL> explain select distinct dept_id,emp_name from emp where salary<1100;
+----+--------------------------------+----------------------+------------+----------+-------------+
| Id | Operation type | Name | Owner | Rows | Cost(%CPU) |
+----+--------------------------------+----------------------+------------+----------+-------------+
| 0 | SELECT STATEMENT | | | | |
| 1 | HASH DISTINCT | | | 920| 9( 0)|
| 2 | TABLE ACCESS BY INDEX ROWID | EMP | TESTUSER | 920| 7( 0)|
|* 3 | INDEX RANGE SCAN | IDX_EMP_SALARY | TESTUSER | 920| 3( 0)|
+----+--------------------------------+----------------------+------------+----------+-------------+
SQL> explain select * from dept where dept_id in (select dept_id from emp where salary<1100);
+----+--------------------------------+----------------------+------------+----------+-------------+
| Id | Operation type | Name | Owner | Rows | Cost(%CPU) |
+----+--------------------------------+----------------------+------------+----------+-------------+
| 0 | SELECT STATEMENT | | | | |
| 1 | NESTED INDEX LOOPS INNER | | | 50| 8( 0)|
| 2 | SORT DISTINCT | | | 50| 8( 0)|
| 3 | TABLE ACCESS BY INDEX ROWID | EMP | TESTUSER | 920| 7( 0)|
|* 4 | INDEX RANGE SCAN | IDX_EMP_SALARY | TESTUSER | 920| 3( 0)|
| 5 | TABLE ACCESS BY INDEX ROWID | DEPT | TESTUSER | 1| 1( 0)|
|* 6 | INDEX UNIQUE SCAN | DEPT_PK | TESTUSER | 1| 1( 0)|
+----+--------------------------------+----------------------+------------+----------+-------------+
-- SORT AGGREGATE
SQL> explain select sum(salary) from emp;
+----+--------------------------------+----------------------+------------+----------+-------------+
| Id | Operation type | Name | Owner | Rows | Cost(%CPU) |
+----+--------------------------------+----------------------+------------+----------+-------------+
| 0 | SELECT STATEMENT | | | | |
| 1 | AGGREGATE | | | 1| 27( 0)|
| 2 | INDEX FAST FULL SCAN | IDX_EMP_SALARY | TESTUSER | 10000| 26( 0)|
+----+--------------------------------+----------------------+------------+----------+-------------+
SQL> explain select min(salary),max(salary) from emp;
+----+--------------------------------+----------------------+------------+----------+-------------+
| Id | Operation type | Name | Owner | Rows | Cost(%CPU) |
+----+--------------------------------+----------------------+------------+----------+-------------+
| 0 | SELECT STATEMENT | | | | |
| 1 | AGGREGATE | | | 1| 27( 0)|
| 2 | INDEX FAST FULL SCAN | IDX_EMP_SALARY | TESTUSER | 10000| 26( 0)|
+----+--------------------------------+----------------------+------------+----------+-------------+
-- SORT GROUP BY
SQL> explain select dept_id,count(*) from emp group by dept_id;
+----+--------------------------------+----------------------+------------+----------+-------------+
| Id | Operation type | Name | Owner | Rows | Cost(%CPU) |
+----+--------------------------------+----------------------+------------+----------+-------------+
| 0 | SELECT STATEMENT | | | | |
| 1 | HASH GROUP | | | 100| 48( 0)|
| 2 | TABLE ACCESS FULL | EMP | TESTUSER | 10000| 46( 0)|
+----+--------------------------------+----------------------+------------+----------+-------------+
-- SORT(ORDER BY)
SQL> explain select * from emp order by dept_id;
+----+--------------------------------+----------------------+------------+----------+-------------+
| Id | Operation type | Name | Owner | Rows | Cost(%CPU) |
+----+--------------------------------+----------------------+------------+----------+-------------+
| 0 | SELECT STATEMENT | | | | |
| 1 | SORT | | | 10000| 224( 0)|
| 2 | TABLE ACCESS FULL | EMP | TESTUSER | 10000| 46( 0)|
+----+--------------------------------+----------------------+------------+----------+-------------+
SQL> explain select * from (select * from emp order by salary desc) a limit 10;
+----+--------------------------------+----------------------+------------+----------+-------------+
| Id | Operation type | Name | Owner | Rows | Cost(%CPU) |
+----+--------------------------------+----------------------+------------+----------+-------------+
| 0 | SELECT STATEMENT | | | | |
| 1 | WINDOW | | | 10| 47( 0)|
| 2 | VIEW | | | 10000| 47( 0)|
| 3 | ORDER BY STOPKEY | | | 10000| 47( 0)|
| 4 | TABLE ACCESS FULL | EMP | TESTUSER | 10000| 46( 0)|
+----+--------------------------------+----------------------+------------+----------+-------------+
-- SORT JOIN
SQL> explain select e.emp_name,d.dept_name from emp e,dept d where e.dept_id=d.dept_id;
+----+--------------------------------+----------------------+------------+----------+-------------+
| Id | Operation type | Name | Owner | Rows | Cost(%CPU) |
+----+--------------------------------+----------------------+------------+----------+-------------+
| 0 | SELECT STATEMENT | | | | |
| 1 | NESTED INDEX LOOPS INNER | | | 10000| 48( 0)|
| 2 | TABLE ACCESS FULL | EMP | TESTUSER | 10000| 46( 0)|
| 3 | TABLE ACCESS BY INDEX ROWID | DEPT | TESTUSER | 1| 1( 0)|
|* 4 | INDEX UNIQUE SCAN | DEPT_PK | TESTUSER | 1| 1( 0)|
+----+--------------------------------+----------------------+------------+----------+-------------+
SQL> explain select *+ use_merge(e d)*/ e.emp_name,d.dept_name from emp e,dept d where e.dept_id=d.dept_id;
+----+--------------------------------+----------------------+------------+----------+-------------+
| Id | Operation type | Name | Owner | Rows | Cost(%CPU) |
+----+--------------------------------+----------------------+------------+----------+-------------+
| 0 | SELECT STATEMENT | | | | |
|* 1 | MERGE JOIN INNER | | | 10000| 2295( 0)|
| 2 | MERGE SORT | | | | |
| 3 | TABLE ACCESS FULL | EMP | TESTUSER | 10000| 46( 0)|
| 4 | MERGE SORT | | | | |
| 5 | TABLE ACCESS FULL | DEPT | TESTUSER | 100| 1( 0)|
+----+--------------------------------+----------------------+------------+----------+-------------+
❖ Vastbase
-- SORT UNIQUE
vastbase=> explain select distinct dept_id,emp_name from emp where salary<1100;
QUERY PLAN
--------------------------------------------------------------------------------------
HashAggregate (cost=156.97..165.97 rows=900 width=20)
Group By Key: dept_id, emp_name
-> Bitmap Heap Scan on emp (cost=23.23..152.47 rows=900 width=20)
Recheck Cond: (salary < 1100::double precision)
-> Bitmap Index Scan on idx_emp_salary (cost=0.00..23.00 rows=900 width=0)
Index Cond: (salary < 1100::double precision)
vastbase=> explain select * from dept where dept_id in (select dept_id from emp where salary<1100);
QUERY PLAN
--------------------------------------------------------------------------------------------------
Hash Join (cost=154.95..157.30 rows=100 width=30)
Hash Cond: (dept.dept_id = emp.dept_id)
-> Seq Scan on dept (cost=0.00..2.00 rows=100 width=30)
-> Hash (cost=154.82..154.82 rows=10 width=8)
-> HashAggregate (cost=154.72..154.82 rows=10 width=8)
Group By Key: emp.dept_id
-> Bitmap Heap Scan on emp (cost=23.23..152.47 rows=900 width=8)
Recheck Cond: (salary < 1100::double precision)
-> Bitmap Index Scan on idx_emp_salary (cost=0.00..23.00 rows=900 width=0)
Index Cond: (salary < 1100::double precision)
-- SORT AGGREGATE
vastbase=> explain select sum(salary) from emp;
QUERY PLAN
---------------------------------------------------------------
Aggregate (cost=243.00..243.01 rows=1 width=16)
-> Seq Scan on emp (cost=0.00..218.00 rows=10000 width=8)
vastbase=> explain select min(salary),max(salary) from emp;
QUERY PLAN
-----------------------------------------------------------------------------------------------------------
Result (cost=0.17..0.18 rows=1 width=0)
InitPlan 1 (returns $0)
-> Limit (cost=0.00..0.09 rows=1 width=8)
-> Index Only Scan using idx_emp_salary on emp (cost=0.00..785.75 rows=9000 width=8)
Index Cond: (salary IS NOT NULL)
InitPlan 2 (returns $1)
-> Limit (cost=0.00..0.09 rows=1 width=8)
-> Index Only Scan Backward using idx_emp_salary on emp (cost=0.00..785.75 rows=9000 width=8)
Index Cond: (salary IS NOT NULL)
-- SORT GROUP BY
vastbase=> explain select dept_id,count(*) from emp group by dept_id;
QUERY PLAN
---------------------------------------------------------------
HashAggregate (cost=268.00..269.01 rows=101 width=16)
Group By Key: dept_id
-> Seq Scan on emp (cost=0.00..218.00 rows=10000 width=8)
-- SORT(ORDER BY)
vastbase=> explain select * from emp order by dept_id;
QUERY PLAN
----------------------------------------------------------------
Sort (cost=882.39..907.39 rows=10000 width=44)
Sort Key: dept_id
-> Seq Scan on emp (cost=0.00..218.00 rows=10000 width=44)
vastbase=> explain select * from (select * from emp order by salary desc) a limit 10;
QUERY PLAN
------------------------------------------------------------------------------------------------
Limit (cost=0.00..0.89 rows=10 width=44)
-> Index Scan Backward using idx_emp_salary on emp (cost=0.00..794.25 rows=10000 width=44)
-- SORT JOIN
vastbase=> explain select e.emp_name,d.dept_name from emp e,dept d where e.dept_id=d.dept_id;
QUERY PLAN
---------------------------------------------------------------------
Hash Join (cost=3.25..351.51 rows=9901 width=24)
Hash Cond: (e.dept_id = d.dept_id)
-> Seq Scan on emp e (cost=0.00..218.00 rows=10000 width=20)
-> Hash (cost=2.00..2.00 rows=100 width=20)
-> Seq Scan on dept d (cost=0.00..2.00 rows=100 width=20)
vastbase=> explain select *+ use_merge(e d)*/ e.emp_name,d.dept_name from emp e,dept d where e.dept_id=d.dept_id;
QUERY PLAN
------------------------------------------------------------------------
Merge Join (cost=887.71..1036.99 rows=9901 width=24)
Merge Cond: (d.dept_id = e.dept_id)
-> Sort (cost=5.32..5.57 rows=100 width=20)
Sort Key: d.dept_id
-> Seq Scan on dept d (cost=0.00..2.00 rows=100 width=20)
-> Sort (cost=882.39..907.39 rows=10000 width=20)
Sort Key: e.dept_id
-> Seq Scan on emp e (cost=0.00..218.00 rows=10000 width=20)
数据库中的分组聚合是两类操作:分组操作是指用SQL语句将一个结果集分为若干组,并对这样每一组进行聚合计算;聚合操作则是基于多行记录返回数据数据:平均、最大、最小值等,聚合操作必须处理输入数据的每一行记录,因此通常和全表扫描联系在一起。
1).常见分组聚合操作
针对常见的分组聚合类操作,抽象出一组测例,看看Oracle和国产库的行为如何。
❖ 聚合:一般聚合
对整个结果集进行计算,一般都是走的全表扫描,如果有索引则会走索引快速全扫描。
❖ 聚合:极值
针对结果集的最大、最小值等计算,如果是索引列,可采用一些更优的做法,因为后者是有序的。
❖ 聚合:计数
对整个结果集进行计数,一般走全表扫描,如果有不可为空的列索引,优化器也是可以采用的。
❖ 分组:一般分组
一般分组下,可采用排序分组的方式,也可采用更为推荐的哈希分组,这样代价更小。
❖ 分组:分组+排序
如果针对分组后的结果还需要排序操作,上面说的哈希分组就不太合适。如果通过 SORT GROUP BY能解决分组问题的同时,还能提供有序的结果集输出,无疑效率是要比 HASH GROUP BY 更高的。
❖ 分组:分组过滤
针对分组数据进行过滤,可以有两种方式 WHERE 或 HAVING。如果记录可以通过WHERE来排除,应该在聚合发生之前就已经被排除。相比之下,HAVING在聚合完成之后对记录进行排除。参与聚合的记录越少,效果就越好,所以一般情况下WHERE子句在这方面比HAVING子句更可取。
2).Oracle 测试示例
-- 聚合:一般聚合
SQL> explain plan for select sum(salary) from emp;
SQL> select * from table(dbms_xplan.display);
----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 5 | 10 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 5 | | |
| 2 | INDEX FAST FULL SCAN| IDX_EMP_SALARY | 10000 | 50000 | 10 (0)| 00:00:01 |
----------------------------------------------------------------------------------------
-- 聚合:极值
SQL> explain plan for select max(salary),min(salary) from emp;
SQL> select * from table(dbms_xplan.display);
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 5 | 15 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 5 | | |
| 2 | TABLE ACCESS FULL| EMP | 10000 | 50000 | 15 (0)| 00:00:01 |
---------------------------------------------------------------------------
-- 聚合:计数
SQL> explain plan for select count(*) from emp;
SQL> select * from table(dbms_xplan.display);
------------------------------------------------------------------------
| Id | Operation | Name | Rows | Cost (%CPU)| Time |
------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 7 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | | |
| 2 | INDEX FAST FULL SCAN| EMP_PK | 10000 | 7 (0)| 00:00:01 |
------------------------------------------------------------------------
-- 分组:一般分组
SQL> explain plan for select dept_id,avg(salary) from emp group by dept_id;
SQL> select * from table(dbms_xplan.display);
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 100 | 800 | 16 (7)| 00:00:01 |
| 1 | HASH GROUP BY | | 100 | 800 | 16 (7)| 00:00:01 |
| 2 | TABLE ACCESS FULL| EMP | 10000 | 80000 | 15 (0)| 00:00:01 |
---------------------------------------------------------------------------
-- 分组:分组+排序
SQL> explain plan for select dept_id,avg(salary) from emp group by dept_id order by dept_id;
SQL> select * from table(dbms_xplan.display);
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 100 | 800 | 16 (7)| 00:00:01 |
| 1 | SORT GROUP BY | | 100 | 800 | 16 (7)| 00:00:01 |
| 2 | TABLE ACCESS FULL| EMP | 10000 | 80000 | 15 (0)| 00:00:01 |
---------------------------------------------------------------------------
-- 分组:分组过滤(WHERE/HAVING)
SQL> explain plan for select dept_id,count(*) from emp where salary<1500 group by dept_id;
SQL> select * from table(dbms_xplan.display);
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 100 | 800 | 16 (7)| 00:00:01 |
| 1 | HASH GROUP BY | | 100 | 800 | 16 (7)| 00:00:01 |
|* 2 | TABLE ACCESS FULL| EMP | 4499 | 35992 | 15 (0)| 00:00:01 |
---------------------------------------------------------------------------
SQL> explain plan for select dept_id,count(*) cnt from emp group by dept_id having count(*) >2;
SQL> select * from table(dbms_xplan.display);
----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 5 | 15 | 16 (7)| 00:00:01 |
|* 1 | FILTER | | | | | |
| 2 | HASH GROUP BY | | 5 | 15 | 16 (7)| 00:00:01 |
| 3 | TABLE ACCESS FULL| EMP | 10000 | 30000 | 15 (0)| 00:00:01 |
----------------------------------------------------------------------------
3).国产库测试示例
下面是针对上述测例,国产库的行为如何?先来看看整体结果
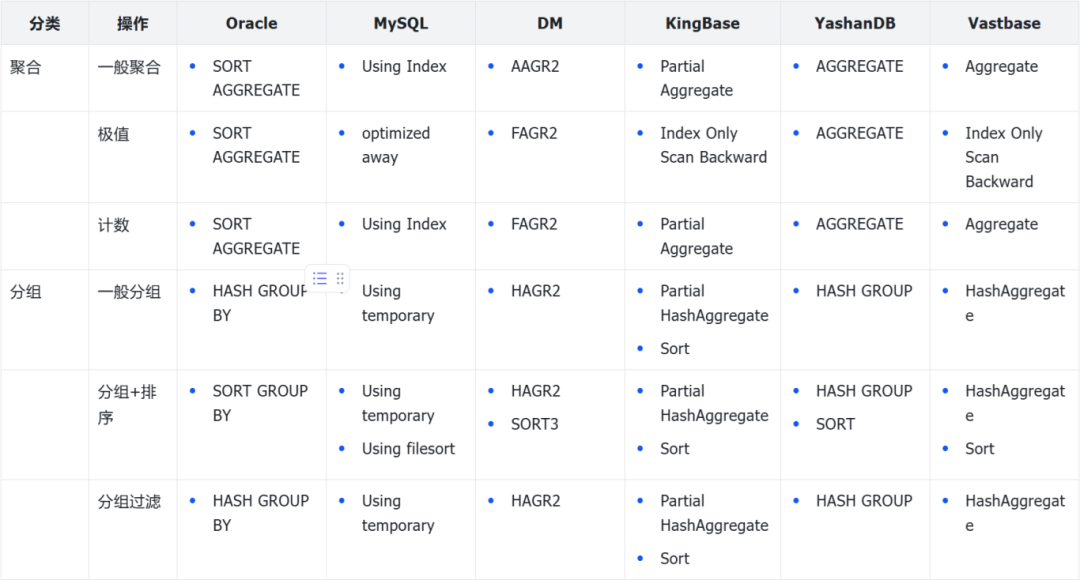
❖ MySQL
-- 聚合:一般聚合
mysql> explain select sum(salary) from emp;
+----+-------------+-------+------------+-------+---------------+----------------+---------+------+-------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+----------------+---------+------+-------+----------+-------------+
| 1 | SIMPLE | emp | NULL | index | NULL | idx_emp_salary | 5 | NULL | 10117 | 100.00 | Using index |
+----+-------------+-------+------------+-------+---------------+----------------+---------+------+-------+----------+-------------+
-- 聚合:极值
mysql> explain select max(salary),min(salary) from emp;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+------------------------------+
| 1 | SIMPLE | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | Select tables optimized away |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+------------------------------+
-- 聚合:计数
mysql> explain select count(*) from emp;
+----+-------------+-------+------------+-------+---------------+------------------+---------+------+-------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+------------------+---------+------+-------+----------+-------------+
| 1 | SIMPLE | emp | NULL | index | NULL | idx_emp_birthday | 4 | NULL | 10117 | 100.00 | Using index |
+----+-------------+-------+------------+-------+---------------+------------------+---------+------+-------+----------+-------------+
-- 分组:一般分组
mysql> explain select dept_id,avg(salary) from emp group by dept_id;
+----+-------------+-------+------------+------+---------------+------+---------+------+-------+----------+-----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+-------+----------+-----------------+
| 1 | SIMPLE | emp | NULL | ALL | NULL | NULL | NULL | NULL | 10117 | 100.00 | Using temporary |
+----+-------------+-------+------------+------+---------------+------+---------+------+-------+----------+-----------------+
-- 分组:分组+排序
mysql> explain select dept_id,avg(salary) from emp group by dept_id order by dept_id;
+----+-------------+-------+------------+------+---------------+------+---------+------+-------+----------+---------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+-------+----------+---------------------------------+
| 1 | SIMPLE | emp | NULL | ALL | NULL | NULL | NULL | NULL | 10117 | 100.00 | Using temporary; Using filesort |
+----+-------------+-------+------------+------+---------------+------+---------+------+-------+----------+---------------------------------+
-- 分组:分组过滤(WHERE/HAVING)
mysql> explain select dept_id,count(*) from emp where salary<1500 group by dept_id;
+----+-------------+-------+------------+------+----------------+------+---------+------+-------+----------+------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+----------------+------+---------+------+-------+----------+------------------------------+
| 1 | SIMPLE | emp | NULL | ALL | idx_emp_salary | NULL | NULL | NULL | 10117 | 39.28 | Using where; Using temporary |
+----+-------------+-------+------------+------+----------------+------+---------+------+-------+----------+------------------------------+
mysql> explain select dept_id,count(*) cnt from emp group by dept_id having count(*) >2;
+----+-------------+-------+------------+------+---------------+------+---------+------+-------+----------+-----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+-------+----------+-----------------+
| 1 | SIMPLE | emp | NULL | ALL | NULL | NULL | NULL | NULL | 10117 | 100.00 | Using temporary |
+----+-------------+-------+------------+------+---------------+------+---------+------+-------+----------+-----------------+
❖ DM
-- 聚合:一般聚合
SQL> explain select sum(salary) from emp;
1 #NSET2: [1, 1, 30]
2 #PRJT2: [1, 1, 30]; exp_num(1), is_atom(FALSE)
3 #AAGR2: [1, 1, 30]; grp_num(0), sfun_num(1), distinct_flag[0]; slave_empty(0)
4 #SSCN: [1, 10000, 30]; IDX_EMP_SALARY(EMP); btr_scan(1); is_global(0)
-- 聚合:极值
SQL> explain select max(salary),min(salary) from emp;
1 #NSET2: [1, 1, 30]
2 #PRJT2: [1, 1, 30]; exp_num(2), is_atom(FALSE)
3 #FAGR2: [1, 1, 30]; sfun_num(2), IDX_EMP_SALARY
-- 聚合:计数
SQL> explain select count(*) from emp;
1 #NSET2: [1, 1, 0]
2 #PRJT2: [1, 1, 0]; exp_num(1), is_atom(FALSE)
3 #FAGR2: [1, 1, 0]; sfun_num(1)
-- 分组:一般分组
SQL> explain select dept_id,avg(salary) from emp group by dept_id;
1 #NSET2: [2, 100, 60]
2 #PRJT2: [2, 100, 60]; exp_num(2), is_atom(FALSE)
3 #HAGR2: [2, 100, 60]; grp_num(1), sfun_num(1), distinct_flag[0]; slave_empty(0) keys(EMP.DEPT_ID)
4 #CSCN2: [1, 10000, 60]; INDEX33555484(EMP); btr_scan(1)
-- 分组:分组+排序
SQL> explain select dept_id,avg(salary) from emp group by dept_id order by dept_id;
1 #NSET2: [3, 100, 60]
2 #PRJT2: [3, 100, 60]; exp_num(2), is_atom(FALSE)
3 #SORT3: [3, 100, 60]; key_num(1), partition_key_num(0), is_distinct(FALSE), top_flag(0), is_adaptive(0)
4 #HAGR2: [2, 100, 60]; grp_num(1), sfun_num(1), distinct_flag[0]; slave_empty(0) keys(EMP.DEPT_ID)
5 #CSCN2: [1, 10000, 60]; INDEX33555484(EMP); btr_scan(1)
-- 分组:分组过滤(WHERE/HAVING)
SQL> explain select dept_id,count(*) from emp where salary<1500 group by dept_id;
1 #NSET2: [2, 45, 60]
2 #PRJT2: [2, 45, 60]; exp_num(2), is_atom(FALSE)
3 #HAGR2: [2, 45, 60]; grp_num(1), sfun_num(1), distinct_flag[0]; slave_empty(0) keys(EMP.DEPT_ID)
4 #SLCT2: [1, 4543, 60]; EMP.SALARY < var1
5 #CSCN2: [1, 10000, 60]; INDEX33555484(EMP); btr_scan(1)
SQL> explain select dept_id,count(*) cnt from emp group by dept_id having count(*) >2;
1 #NSET2: [2, 5, 30]
2 #PRJT2: [2, 5, 30]; exp_num(2), is_atom(FALSE)
3 #SLCT2: [2, 5, 30]; exp_sfun9 > var1
4 #HAGR2: [2, 100, 30]; grp_num(1), sfun_num(1), distinct_flag[0]; slave_empty(0) keys(EMP.DEPT_ID)
5 #CSCN2: [1, 10000, 30]; INDEX33555484(EMP); btr_scan(1)
❖ KingBase
-- 聚合:一般聚合
TEST=# explain select sum(salary) from emp;
QUERY PLAN
---------------------------------------------------------------------------------------
Finalize Aggregate (cost=16384.55..16384.56 rows=1 width=8)
-> Gather (cost=16384.33..16384.54 rows=2 width=8)
Workers Planned: 2
-> Partial Aggregate (cost=15384.33..15384.34 rows=1 width=8)
-> Parallel Seq Scan on emp (cost=0.00..14342.67 rows=416667 width=8)
-- 聚合:极值
TEST=# explain select max(salary),min(salary) from emp;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------
Result (cost=1.01..1.02 rows=1 width=16)
InitPlan 1 (returns $0)
-> Limit (cost=0.42..0.50 rows=1 width=8)
-> Index Only Scan Backward using idx_emp_salary on emp (cost=0.42..71128.49 rows=904233 width=8)
Index Cond: (salary IS NOT NULL)
InitPlan 2 (returns $1)
-> Limit (cost=0.42..0.50 rows=1 width=8)
-> Index Only Scan using idx_emp_salary on emp emp_1 (cost=0.42..71128.49 rows=904233 width=8)
Index Cond: (salary IS NOT NULL)
-- 聚合:计数
TEST=# explain select count(*) from emp;
QUERY PLAN
---------------------------------------------------------------------------------------
Finalize Aggregate (cost=16384.55..16384.56 rows=1 width=8)
-> Gather (cost=16384.33..16384.54 rows=2 width=8)
Workers Planned: 2
-> Partial Aggregate (cost=15384.33..15384.34 rows=1 width=8)
-> Parallel Seq Scan on emp (cost=0.00..14342.67 rows=416667 width=0)
-- 分组:一般分组
TEST=# explain select dept_id,avg(salary) from emp group by dept_id;
QUERY PLAN
----------------------------------------------------------------------------------------------
Finalize GroupAggregate (cost=17430.40..17456.24 rows=101 width=13)
Group Key: dept_id
-> Gather Merge (cost=17430.40..17453.97 rows=202 width=37)
Workers Planned: 2
-> Sort (cost=16430.37..16430.63 rows=101 width=37)
Sort Key: dept_id
-> Partial HashAggregate (cost=16426.00..16427.01 rows=101 width=37)
Group Key: dept_id
-> Parallel Seq Scan on emp (cost=0.00..14342.67 rows=416667 width=13)
-- 分组:分组+排序
TEST=# explain select dept_id,avg(salary) from emp group by dept_id order by dept_id;
QUERY PLAN
----------------------------------------------------------------------------------------------
Finalize GroupAggregate (cost=17430.40..17456.24 rows=101 width=13)
Group Key: dept_id
-> Gather Merge (cost=17430.40..17453.97 rows=202 width=37)
Workers Planned: 2
-> Sort (cost=16430.37..16430.63 rows=101 width=37)
Sort Key: dept_id
-> Partial HashAggregate (cost=16426.00..16427.01 rows=101 width=37)
Group Key: dept_id
-> Parallel Seq Scan on emp (cost=0.00..14342.67 rows=416667 width=13)
-- 分组:分组过滤(WHERE/HAVING)
TEST=# explain select dept_id,count(*) from emp where salary<1500 group by dept_id;
QUERY PLAN
---------------------------------------------------------------------------------------------
Finalize GroupAggregate (cost=17332.58..17358.17 rows=101 width=13)
Group Key: dept_id
-> Gather Merge (cost=17332.58..17356.15 rows=202 width=13)
Workers Planned: 2
-> Sort (cost=16332.56..16332.81 rows=101 width=13)
Sort Key: dept_id
-> Partial HashAggregate (cost=16328.18..16329.19 rows=101 width=13)
Group Key: dept_id
-> Parallel Seq Scan on emp (cost=0.00..15384.33 rows=188770 width=5)
Filter: (salary < '1500'::double precision)
TEST=# explain select dept_id,count(*) cnt from emp group by dept_id having count(*) >2;
QUERY PLAN
---------------------------------------------------------------------------------------------
Finalize GroupAggregate (cost=17430.40..17456.74 rows=34 width=13)
Group Key: dept_id
Filter: (count(*) > 2)
-> Gather Merge (cost=17430.40..17453.97 rows=202 width=13)
Workers Planned: 2
-> Sort (cost=16430.37..16430.63 rows=101 width=13)
Sort Key: dept_id
-> Partial HashAggregate (cost=16426.00..16427.01 rows=101 width=13)
Group Key: dept_id
-> Parallel Seq Scan on emp (cost=0.00..14342.67 rows=416667 width=5)
❖ YashanDB
-- 聚合:一般聚合
SQL> explain select sum(salary) from emp;
+----+--------------------------------+----------------------+------------+----------+-------------+
| Id | Operation type | Name | Owner | Rows | Cost(%CPU) |
+----+--------------------------------+----------------------+------------+----------+-------------+
| 0 | SELECT STATEMENT | | | | |
| 1 | AGGREGATE | | | 1| 27( 0)|
| 2 | INDEX FAST FULL SCAN | IDX_EMP_SALARY | TESTUSER | 10000| 26( 0)|
+----+--------------------------------+----------------------+------------+----------+-------------+
-- 聚合:极值
SQL> explain select max(salary),min(salary) from emp;
+----+--------------------------------+----------------------+------------+----------+-------------+
| Id | Operation type | Name | Owner | Rows | Cost(%CPU) |
+----+--------------------------------+----------------------+------------+----------+-------------+
| 0 | SELECT STATEMENT | | | | |
| 1 | AGGREGATE | | | 1| 27( 0)|
| 2 | INDEX FAST FULL SCAN | IDX_EMP_SALARY | TESTUSER | 10000| 26( 0)|
+----+--------------------------------+----------------------+------------+----------+-------------+
-- 聚合:计数
SQL> explain select count(*) from emp;
+----+--------------------------------+----------------------+------------+----------+-------------+
| Id | Operation type | Name | Owner | Rows | Cost(%CPU) |
+----+--------------------------------+----------------------+------------+----------+-------------+
| 0 | SELECT STATEMENT | | | | |
| 1 | AGGREGATE | | | 1| 14( 0)|
| 2 | INDEX FAST FULL SCAN | EMP_PK | TESTUSER | 10000| 14( 0)|
+----+--------------------------------+----------------------+------------+----------+-------------+
-- 分组:一般分组
SQL> explain select dept_id,avg(salary) from emp group by dept_id;
+----+--------------------------------+----------------------+------------+----------+-------------+
| Id | Operation type | Name | Owner | Rows | Cost(%CPU) |
+----+--------------------------------+----------------------+------------+----------+-------------+
| 0 | SELECT STATEMENT | | | | |
| 1 | HASH GROUP | | | 100| 48( 0)|
| 2 | TABLE ACCESS FULL | EMP | TESTUSER | 10000| 46( 0)|
+----+--------------------------------+----------------------+------------+----------+-------------+
-- 分组:分组+排序
SQL> explain select dept_id,avg(salary) from emp group by dept_id order by dept_id;
+----+--------------------------------+----------------------+------------+----------+-------------+
| Id | Operation type | Name | Owner | Rows | Cost(%CPU) |
+----+--------------------------------+----------------------+------------+----------+-------------+
| 0 | SELECT STATEMENT | | | | |
| 1 | SORT | | | 100| 49( 0)|
| 2 | HASH GROUP | | | 100| 48( 0)|
| 3 | TABLE ACCESS FULL | EMP | TESTUSER | 10000| 46( 0)|
+----+--------------------------------+----------------------+------------+----------+-------------+
-- 分组:分组过滤(WHERE/HAVING)
SQL> explain select dept_id,count(*) from emp where salary<1500 group by dept_id;
+----+--------------------------------+----------------------+------------+----------+-------------+
| Id | Operation type | Name | Owner | Rows | Cost(%CPU) |
+----+--------------------------------+----------------------+------------+----------+-------------+
| 0 | SELECT STATEMENT | | | | |
| 1 | HASH GROUP | | | 50| 37( 0)|
| 2 | TABLE ACCESS BY INDEX ROWID | EMP | TESTUSER | 4509| 36( 0)|
|* 3 | INDEX RANGE SCAN | IDX_EMP_SALARY | TESTUSER | 4509| 12( 0)|
+----+--------------------------------+----------------------+------------+----------+-------------+
SQL> explain select dept_id,count(*) cnt from emp group by dept_id having count(*) >2;
+----+--------------------------------+----------------------+------------+----------+-------------+
| Id | Operation type | Name | Owner | Rows | Cost(%CPU) |
+----+--------------------------------+----------------------+------------+----------+-------------+
| 0 | SELECT STATEMENT | | | | |
|* 1 | HASH GROUP | | | 33| 48( 0)|
| 2 | TABLE ACCESS FULL | EMP | TESTUSER | 10000| 46( 0)|
+----+--------------------------------+----------------------+------------+----------+-------------+
❖ Vastbase
-- 聚合:一般聚合
vastbase=> explain select sum(salary) from emp;
QUERY PLAN
---------------------------------------------------------------
Aggregate (cost=243.00..243.01 rows=1 width=16)
-> Seq Scan on emp (cost=0.00..218.00 rows=10000 width=8)
-- 聚合:极值
vastbase=> explain select max(salary),min(salary) from emp;
QUERY PLAN
-----------------------------------------------------------------------------------------------------------
Result (cost=0.17..0.18 rows=1 width=0)
InitPlan 1 (returns $0)
-> Limit (cost=0.00..0.09 rows=1 width=8)
-> Index Only Scan Backward using idx_emp_salary on emp (cost=0.00..785.75 rows=9000 width=8)
Index Cond: (salary IS NOT NULL)
InitPlan 2 (returns $1)
-> Limit (cost=0.00..0.09 rows=1 width=8)
-> Index Only Scan using idx_emp_salary on emp (cost=0.00..785.75 rows=9000 width=8)
Index Cond: (salary IS NOT NULL)
-- 聚合:计数
vastbase=> explain select count(*) from emp;
QUERY PLAN
---------------------------------------------------------------
Aggregate (cost=243.00..243.01 rows=1 width=8)
-> Seq Scan on emp (cost=0.00..218.00 rows=10000 width=0)
-- 分组:一般分组
vastbase=> explain select dept_id,avg(salary) from emp group by dept_id;
QUERY PLAN
----------------------------------------------------------------
HashAggregate (cost=268.00..269.26 rows=101 width=48)
Group By Key: dept_id
-> Seq Scan on emp (cost=0.00..218.00 rows=10000 width=16)
-- 分组:分组+排序
vastbase=> explain select dept_id,avg(salary) from emp group by dept_id order by dept_id;
QUERY PLAN
----------------------------------------------------------------------
Sort (cost=272.62..272.88 rows=101 width=48)
Sort Key: dept_id
-> HashAggregate (cost=268.00..269.26 rows=101 width=48)
Group By Key: dept_id
-> Seq Scan on emp (cost=0.00..218.00 rows=10000 width=16)
-- 分组:分组过滤(WHERE/HAVING)
vastbase=> explain select dept_id,count(*) from emp where salary<1500 group by dept_id;
QUERY PLAN
--------------------------------------------------------------
HashAggregate (cost=265.67..266.12 rows=46 width=16)
Group By Key: dept_id
-> Seq Scan on emp (cost=0.00..243.00 rows=4533 width=8)
Filter: (salary < 1500::double precision)
vastbase=> explain select dept_id,count(*) cnt from emp group by dept_id having count(*) >2;
QUERY PLAN
---------------------------------------------------------------
HashAggregate (cost=293.00..294.26 rows=101 width=24)
Group By Key: dept_id
Filter: (count(*) > 2)
-> Seq Scan on emp (cost=0.00..218.00 rows=10000 width=8)
