








1. 车厢分配:通过(乘客编号 - 车次起始乘客编号)÷ 100(车厢座位数)并向上取整来确定。
2. 座位分配:
排数:总体是乘客编号最后两位 ÷5(每排座位数)并向上取整,针对乘客编号为 100 整数倍时结果异常的情况,通过小技巧转换处理。
列数:即具体座位(A,B,C,E,F),通过(乘客编号 - 1)÷5 的余数 + 1 确定,针对乘客编号为 5 整数倍时结果异常的情况,也通过小技巧转换处理。

1.首先生成列车的车票信息。借用自增数列t_sequence,通过与train连接,生成车厢号、座位号。另外,生成10%的无座车票。为便于对车票排序,额外生成是否有座说明列。
2.以出发站和到达站点对高铁车次分组,并按照是否有座对可售车票进行顺序编号,有座车票编号在前,无座车票编号在后。
3.乘客按照出发站和到达站点进行顺序编号。
4.车票和乘客顺序编号之后,根据出发站、到达站点、顺序编号对可售座票与乘客进行外连接,即完成车票分配。
性能优化考虑:
由于是全量数据连接操作,表字段个数少,且表连接操作都是在中间结果集之后进行的,创建索引没有多大意义,故无需额外创建索引。 若机器性能较好,可考虑添加并行hint,使用并行查询技术。 可在排序内存和hash连接内存分配上多给一些,消除在磁盘上的排序。

1. 每个乘客按行程规划分组生成需求序列号;
2. 所有火车按行程规划生成每个座位的供应序列号,先分配有座、再分配无座
3. 行程相同两个序列号相同,生成车票分配方案
增加一个行程方案,降低座位序列号计算量;用行程方案ID关联,降低最后JOIN关联字段消耗; 对火车进行预测,尽量少生成火车坐席; 添加了一个测试参数,可以将原始数据扩大N倍,用于性能测试; 加Hint *+ PARALLEL(8) */ ,官方测试环境4C8G,网上查了一下,据说ORACLE默认安装的时候每核2个线程,故参数设置为8,榨干服务器。

1. 构建带座位类型的列车表:复制 train 表,新增 seat_type 列,0 代表有坐票,1 代表无坐票,无坐票数量为有坐票的 10%,新表命名为 train_with_emapy。
2. 计算运行总计座位数:在 train_with_emapy 表中,利用窗口求和函数,按 <车次, seat_type> 在 <出发站, 到达站> 组内生成运行总计座位数 running_seat_count。
3. 在乘客表中,通过窗口计数函数,为 <出发站, 到达站> 组内的乘客生成从 1 开始的编号 passenger_rid。
4. 根据每个乘客在<出发站, 到达站>组里的编号里和车次在<出发站, 到达站>组里的编号范围,求出具体的车次号, 车票类型,车箱号 coach_number 和乘客在这个车次的编号 ans_id, 命名为 result
5. 生成0..100对应的 seat_number 的查找表 to_seat_number
6. 原乘客表 LEFT JOIN result 和 LEFT JOIN to_seat_number 得出最终答案

1. 该需求中主要影响SQL性能的为大表连接和排序,优先分配有票也是与顺序有关,结题中将主要围绕这两点展开:减少表连接行数,减少非必要的排序但要达到排序效果。
2. 选用PostgreSQL解题,PostgreSQL数组包含顺序,将乘客和座位表分别生成两个起始站-终点站聚合 数组,按起始站-终点站关联后展开,即可达到从头对齐后进行批量分配,极大的减少了表连接行数,可显著提升性能。
步骤(对应第N个CTE):
将乘客按起始站和终点站分组并聚合为数组
为每列车的座位编号生成车厢和座位信息:
座位信息按起始站-终点站聚合为数组:
合并乘客和座位信息:
返回最终的座位分配结果:
最终输出

进阶版相比普通版,主要是对普通版的有票乘客增加了计算票车厢和座位,以及对车次定员额外的 10%增加站票。
1. 有座票车厢和座位的计算方法:
将相同(起点站,终点站)的车次分成一个虚拟组,组内各个车次首尾相连,从第1趟车到最后一趟编写座位的总序号,座位总序号减去当前车次之前的座位总数就是在当前车次的座位序号,把当前车次的座位序号减一,得到从 0~本车次座位总和减一的新序号,因为每个车厢固定 100 个座位,所以把上述新序号除以100 的商取整再加一就是车厢号。
座位号类似,将新序号除以 5,商为 0 放在第一排,1 放在第二排,以此类推,余数为 0-2 编ABC号,3-4 编 EF号。
2. 无座票的序号和车厢计算方法:
将相同(起点站,终点站)的虚拟组座位总数除以 10,就是无座票的总张数,序号从虚拟组座位总数加一
开始编,每达到一个车次的额定人数的十分之一,就换下一个车次。无座票的座位统一填写‘无座’,车厢号为空。

1. 因为有10%的站票,而且必须买完所有坐票才能买站票,所以我们需要把座位票和无座票分开来卖。即把一列车变成成两列车卖,一列是有座的票,二列是10%的无座票。
2. 先处理有座的车,根据路径分组,车号排序。计算出每列车的起始编号。按照 200个座位一页拆分。比如800座的火车,拆分成4个页,也就是变成4条记录,以此类推。
3. 拆分后,使用窗口函数进行编号座位页号,根据路径分组,车号排序。因为每页的大小都是一样的。所以 路径+页号 是唯一的。
4. 同时,我们使用函数窗口,计算出同一条线路上的乘客编号。
5. 因为有页号,所以可以乘客编号可以对 200 取模,使用JOIN快速映射到记录。
6. 通过这次JOIN后,有座的票就分好了。同时可以根据编号减去列车的起始编号,获得列车上的座位序号,然后除法和取余计算出座位号。
7. 将上一步的结果筛选出未分配列车的乘客,和上面一样的方式,只是按照20一页来取模计算页号。因为无座,所以不需要算车厢号,座位号直接标记无座即可。
8. 将结果和之前有座乘客UNION ALL 一下,然后做最终排序就是结果。

第一诫:所有影响hash join性能的优化,在极致性能要求面前,都是负反馈。
1. tmp_train临时通过开窗函数,将坐票累加值、站票累加值都记录下来,为后面的记录乘客匹配做准备,人为创造票数区间。
2. 充分审题,还要要多审题,发现票数只有600,800,1200,1600四种,站票固定10%(60,80,120,160),则取公约数20为最合适的值,进行匹配,便于匹配的时候减少hash小表的数据量,进一步提升hash性能。
3. tmp_train_seed,2中已说明,只有四种可能,因此借train表当个序列(按最大1600+160,1-88)生成使用下,提升代码美观度,把train表按公约数20扩行。
4. passenger_rk表是passenger表的开窗所得,开了两个列,一个是纯顺序rk,便于后期算车厢后使用。一个是按公约数20做的分组,20个一组,正好可以匹配一个批次。
5. 按人员批次和火车批次,进行left join匹配,因全是等值条件,hash 效率较高,注意这里,不能贪一些过滤条件,比如使用or+between去判断,会得到负反馈性能。
6. hint parallel(8)充分利用oracle的并行特性叠加hash join,提升性能。匹配处理,行数正确,剩下的只是一些基本面字段通过数字求车厢号,以及substr处理座位号的问题了。
卷数据库:适当修改细节,将SQL放入doris中运行,观察执行情况,测试环境中,取速度更快的一个。
优化点:hash join+按20批次分组拆分。
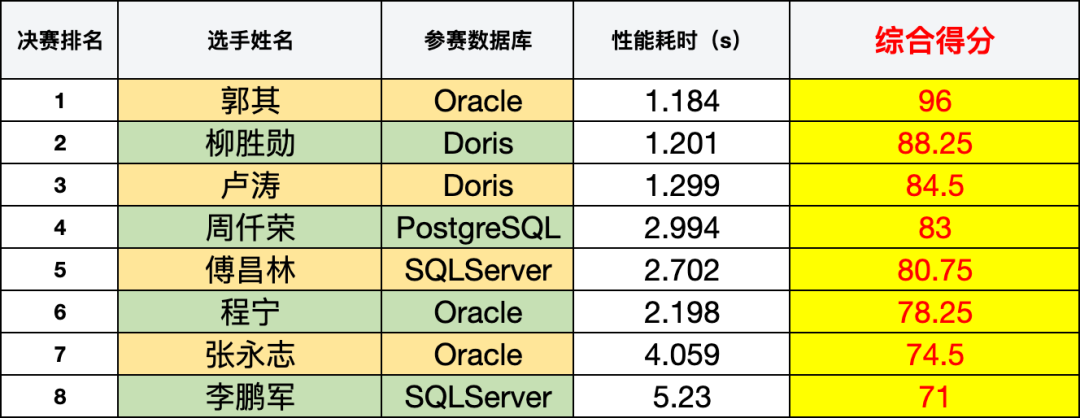
一等奖(1人):2024 华为最新款 WATCH D2 + 奖杯 二等奖(2人):高级行李箱1个 + 奖杯 三等奖(3人):华为蓝牙耳机1个 + 奖杯 阳光普照纪念奖(50人):充电宝1个


END




