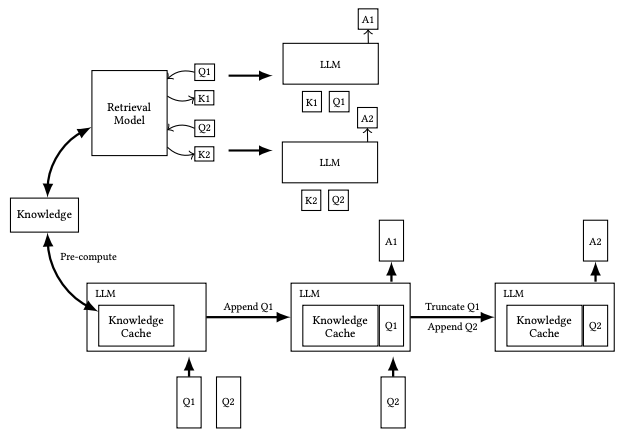
论文链接:https://arxiv.org/pdf/2412.15605代码链接:https://github.com/hhhuang/CAG检索增强生成(RAG)已广泛应用于通过集成外部知识提升语言模型的能力,但其实时检索过程带来的延迟、文档选择错误以及系统复杂性增加等问题,限制了其在某些场景中的高效应用。针对这些问题,本文提出了一种新的缓存增强生成(CAG)方法,通过利用长上下文语言模型(LLMs)扩展的上下文窗口,预先加载所有相关文档并预计算关键值(KV)缓存,无需实时检索即可高效生成答案。这种方法有效消除了检索延迟和错误,同时简化了系统架构。实验表明,在知识库规模有限且可管理的情况下,CAG 在效率和准确性上超越了传统 RAG,并为知识密集型任务提供了一种更简洁高效的解决方案。上图展示了传统RAG与CAG工作流程对比:上半部分展示了RAG管道,包括推理过程中的实时检索和参考文本输入,而下半部分描绘了CAG方法,该方法预加载了KV缓存,消除了推理时的检索步骤和参考文本输入。1. 外部知识预加载 (External Knowledge Preloading)
- 预处理文档:对选定的文档集合进行预处理,如格式化、分词等,以适应长语境模型的输入要求。
- 编码为键值缓存:将预处理后的文档编码成一个键值 (key-value) 缓存 。这个过程可以表示为:其中, 是一个编码函数,它将文档集合 转换为键值对的形式。
- 加载键值缓存:在推理阶段,将预计算的键值缓存 加载到长语境模型 中。
- 生成回答:利用加载的键值缓存,长语境模型生成回答 。这个过程可以表示为:其中, 是长语境模型, 是用户的查询, 是预加载的键值缓存。
随着推理的进行,键值缓存可能会增长。为了维持系统性能,可以截断最近添加的令牌。这个过程可以表示为:其中, 是一个截断函数,它从键值缓存 中移除最近添加的令牌本文提出了一种新的语言模型增强方法,即缓存增强生成(CAG),作为传统检索增强生成(RAG)的替代方案。CAG通过在大型语言模型(LLM)的扩展上下文中预先加载所有相关资源并缓存运行时参数,避免了实时检索的延迟和错误。与传统的RAG方法相比,CAG简化了系统架构,减少了推理时间,并提高了回答的准确性。对于具有受限知识库的应用,CAG提供了一种更简洁高效的方法,能够以较低的复杂性实现相当或更好的效果。然而,CAG方法主要适用于文档或知识库规模有限且可管理的场景,并且需要定期更新维护知识库。它难以适应不同场景和需求,无法实时获取最新信息,并且依赖于复杂的长语境模型,需要大量计算资源。因此,在选择 CAG 方法时,需要考虑这些局限性,并根据具体场景和需求做出合适的选择。