




OLAP 引擎在得物的客服、风控、供应链、投放、运营、AB 实验等大量业务场景发挥重要作用,在报表、日志、实时数仓等应用场景都有广泛的应用。
得物引入和使用 OLAP 引擎的过程中,每个业务都基于自己的需求选择当时最适合自己的引擎。现在得物内部同时使用阿里云上的 Hologres、ADB、ClickHouse 与ECS 自建的开源 ClickHouse 与 StarRocks 5 种引擎产品,从业务使用成本和运维维护的角度长远看都是不利的。
物化视图缺乏透明改写能力
智能运营平台日常需要查询周/月/季/年 环比/同比,查询时间跨度长,并且为了加速查询建立了 40+ 物化视图。ClickHouse 没有自动的透明物化视图改写能力,需要由外部代码主动管理、创建物化视图和改写 SQL 去查询物化视图。在需要重刷历史数据时,由外部代码管理的物化视图的重刷尤为复杂。
缺乏离线导入功能
扩容困难
垂直扩容没有空间:集群使用的 ClickHouse 单机规格已经是顶配,没有升配空间。 水平扩容停机需停机一周:因为 ClickHouse 水平扩容后为了查询正确性考虑,已经按指定字段分桶的表,需要重新导入数据才能正确的 resharding,这个过程需要一周的停服扩容和导入。
业务方只能搭建了一个小一些的备份集群,存储最核心的数据,与主集群构成双活来分流部分查询,来减小主集群负载,这样增加了 50%+ 成本。
在得物增加了对 StarRocks 的研发投入后,智能运营下定决心基于 StarRocks 存算分离做 POC,并最终顺利迁移到自建的 StarRocks 上。
存算分离带来成本下降
StarRocks 存算分离架构:
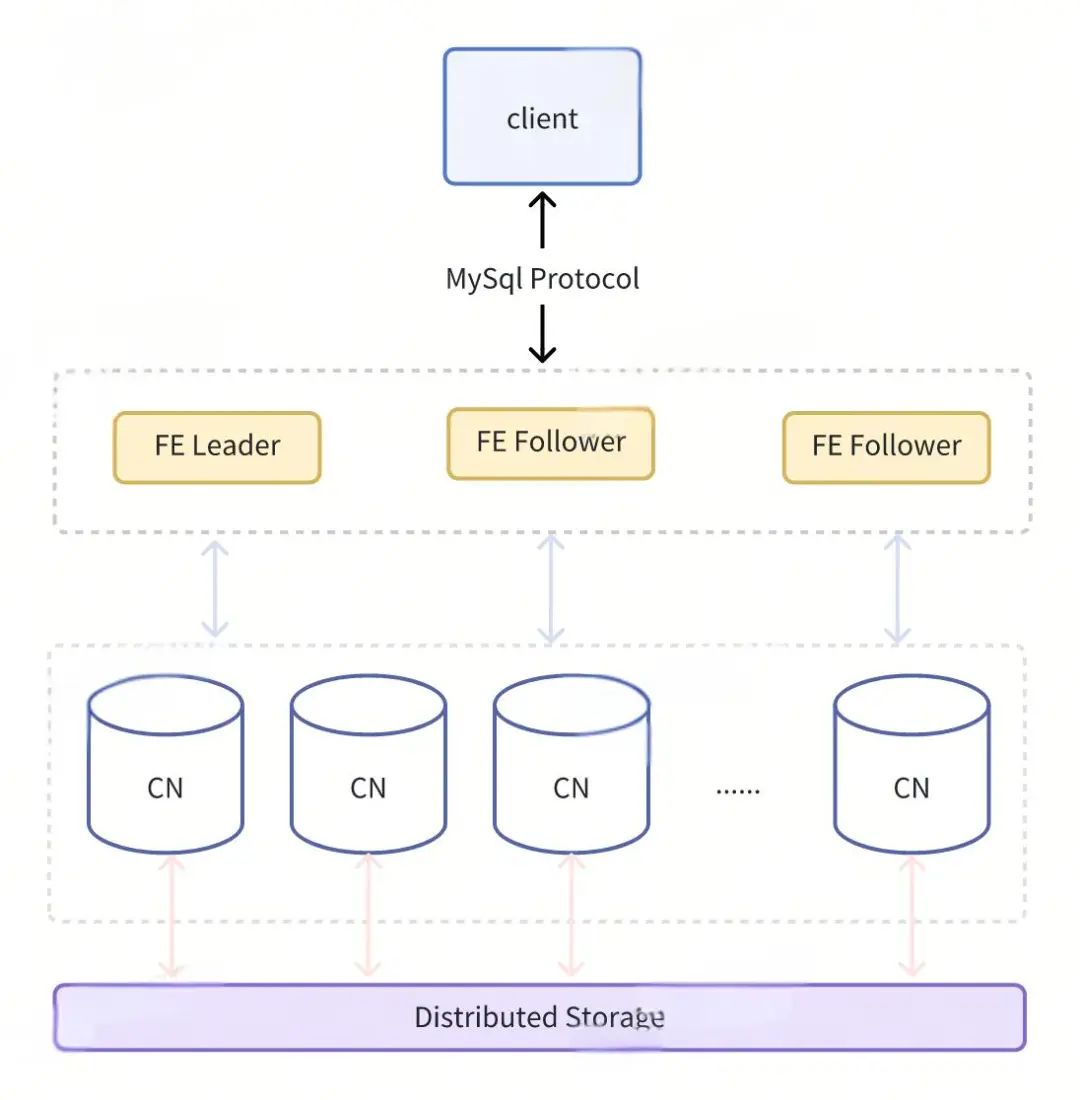
(CN 是 Compute Node,是无状态计算节点+本地缓存盘)
1.1 安全可靠使用的单副本
对比存算一体的 3 副本模式,存算分离使用单副本。存算分离的全量数据数据存储在远端对象存储上(上图的 Distributed Storage,我们使用的是阿里云的 OSS),即使 CN 节点挂了,其他 CN 节点也仍然可以查询到数据(虽然需要重新拉取缓存数据,查询耗时会增加),所以是可以安全可靠使用的单副本模式。这带来 2/3 的存储成本下降(本地盘只作为 data cache 之用)。
并且大量使用物化视图,减少基表实际需要存储在 data cache 中的数据量。

上图说明 506TB 的数据实际只在缓存中存储了 342TB
经过评估存算分离部署模式能带来 40%+ 的成本下降,存储成本下降 1 - (1/3*3/5)=4/5。
1.3 扩缩容无需搬迁数据
在复杂 SQL join 能力上大幅领先 ClickHouse
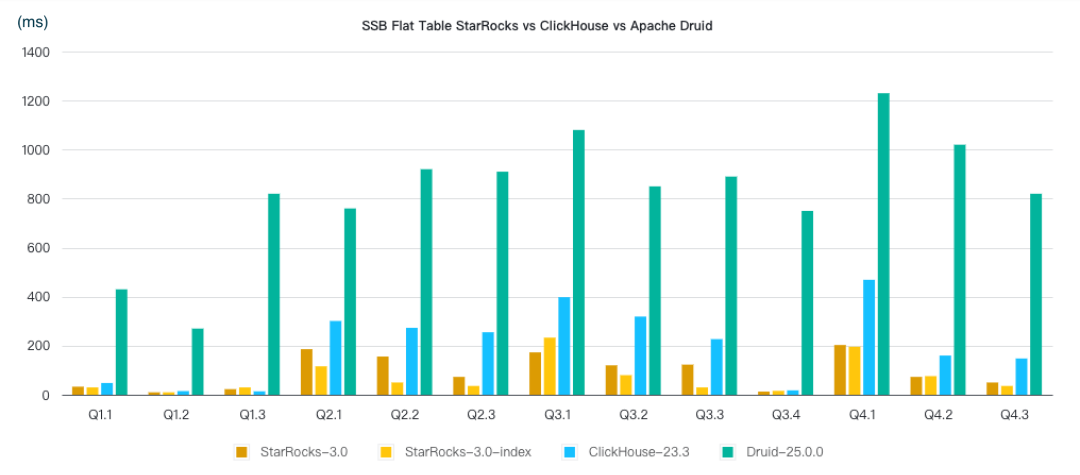
https://docs.starrocks.io/zh/docs/benchmarking/SSB_Benchmarking/
StarRocks 更适合星型模型,并且 StarRocks 与 ClickHouse 单表查询性能不相伯仲(数据来源:clickbench 单机性能测试 https://benchmark.clickhouse.com/)
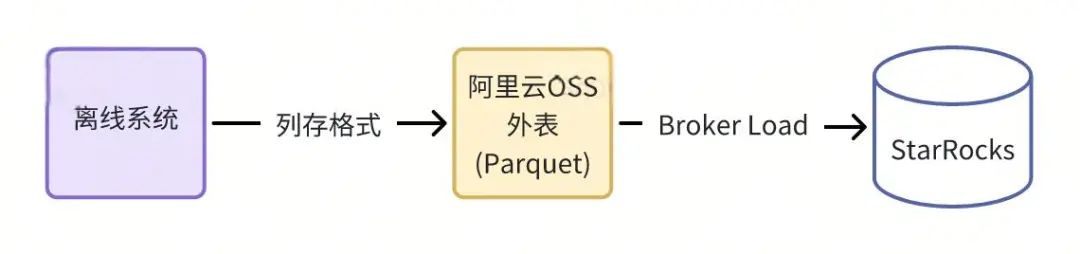
高效的离线导入
从 ClickHouse 换成 StarRocks 后,离线导入的流程发生了变化。
首先在离线平台新建一个 OSS 外表,然后执行离线平台的 insert sql select 语句从离线平台读取数据以 parquet 格式写入到 OSS 外表中,然后 StarRocks 从对象存储(OSS)直接 broker load 导入数据。对比 ClickHouse 只能 insert 导入,虽然还是使用 StarRocks 集群资源,但通过控制 Broker Load 并发可以把集群资源的消耗控制在可接受范围内。压测显示离线导入耗时比 ClickHouse 方案减少 2/3。
重度使用物化视图进行提效
4.1 透明物化视图改写
4.2 使用技巧
1、不命中物化视图时,在资源组中限制大表时间跨度超过8天就不允许查询。
2、approx_count_distinct 改写成 hll_union_agg(hll_hash(col)) 让查基表与查物化视图的结果完全一致
3、使用明细物化视图减少数据读取量
4、物化视图只基于单表,方便在各种 join sql 语句中复用
5、一个物化视图包括尽量多的指标,查询时一次性查多个指标
6、materialized_view_rewrite_mode=‘force‘ 让一个查询中多个 countdistinct也能命中物化视图
4.3 物化视图推荐

4、物化视图启用 collocate group
现在物化视图推荐功能已经初步上线,并还在持续优化中。
4.4 优化选择策略和性能
3、优先选中排序键匹配查询过滤条件的物化视图,再优先选行数最少的物化视图(https://github.com/StarRocks/starrocks/pull/51511)。
4.5 扩展物化视图可用场景
4.6 修复物化视图刷新问题
2、修复了 force 刷新不生效的问题(https://github.com/StarRocks/starrocks/pull/52081)
4、反馈给社区修复了 fast schema evolution 导致的 MV 非预期刷新问题
ClickHouse 灰度迁移 StarRocks
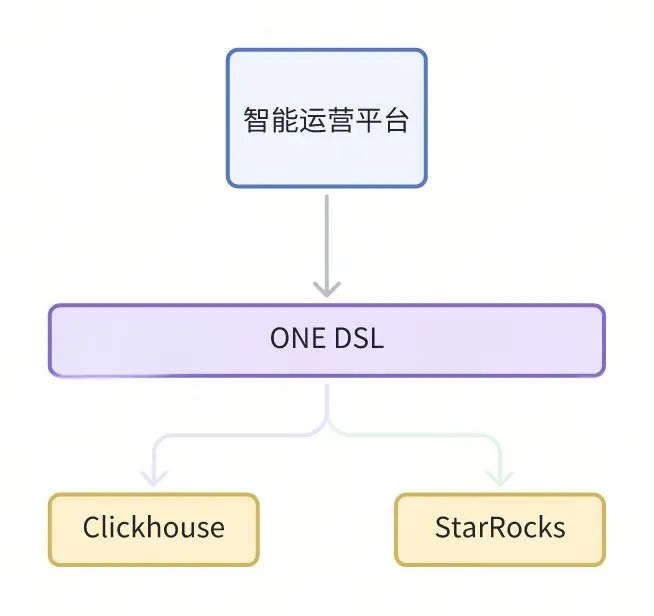
智能运营并不直接查询 StarRocks,而是经过中间的 ONE DSL 平台翻译 DSL(一种类 SQL)成 ClickHouse/StarRocks SQL 后发给后端引擎。通过查询时指定 DSL目标翻译类型,决定发到 ClickHouse 或者 StarRocks,这样在迁移过程中可以按接口灰度,然后逐个的迁移,有问题可以随时单独回滚某个接口。
语法兼容
我们仿造 StarRocks 中已有的 Trino 的 AstBuilder 实现了 ClickHouse 的 AstBuilder,通过新增 sql_dialect=clickhouse 选项,让兼容改动不污染 StarRocks 原来的行为。 我们兼容了业务方用到的 72 个函数,覆盖了最常用 ClickHouse 函数,业务方大部分情况下不需要修改查询 SQL,从而减小了迁移需要的工时。可以做到一个 ClickHouse 函数对应一个 StarRocks 函数或者多个函数的组合,并且将来新增一个 ClickHouse 函数映射是非常容易的。 我们还实现了 ClickHouse 的 ArrayJoin 函数,能在 StarRocks 中使用一样的方式进行列转行: -- StarRocks 原生写法 select u from tbl, unnest(array_column) -- ArrayJoin 的写法 select arrayJoin(array_column) from tbl
不过 ClickHouse 的 arrayJoin 语法仍然是不支持的,需要手工改写成 StarRocks的 unnest 语法。
此外,我们还实现了 ClickHouse 式的别名引用,可以在 select 的后段引用前段定义的别名(https://github.com/StarRocks/starrocks/pull/43919):
Select id as id_alias, sum(a) as b, concat(b, ',', '_') from xx where id_alias > 100 group by id_alias
2.2 ClickHouse表/物化视图转换工具
在引擎之外做了转换工具,能够以程序的方式将 ClickHouse 的建表和建物化视图的 DDL 转为 StarRocks 的 DDL,节约了手工转换的时间的同时也避免手工转换时可能发生的改写错误。
优化查询性能
前面提到的修复多个场景的物化视图命中问题和优化物化视图选择策略性能
分区字段查询带函数导致物化视图分区裁剪失败(https://github.com/StarRocks/starrocks/pull/46786) 优化数值与字符串类型隐式转换(https://github.com/StarRocks/starrocks/pull/50168):对应 sql 性能提升 20 倍。 优化 date/datetime 被当做字符串使用时的规则,从而命中稀疏索引命中(https://github.com/StarRocks/starrocks/pull/50643):对应 sql 性能提升 30 倍。 减少查询时存算分离 staros 的 rpc 调用次数(https://github.com/StarRocks/starrocks/pull/46913) + 简易 rpc 结果缓存:查询耗时普遍减少 3s+。
3.3 表结构优化
3.4 找到问题 SQL 让用户修改写法
通过持续对 I/O 高/CPU 高的查询针对性优化,发现有很多 StarRocks rule 不能等价转换,但从业务角度看是等价的小改动,可以显著提升性能的场景。
比如下面的极端 case 的改动提升了 250 倍性能,因为它导致估算的行数变少,从而优化了 join order 的顺序,生成了更好的 plan。
brand_id IN (SELECT brand_id FROM olap_znyy.st_itg_spu_info_allWHERE brand_level_name IN ('A级品牌', 'B级品牌', 'C级品牌'))改成brand_id IN (SELECT distinct brand_id FROM olap_znyy.st_itg_spu_info_allWHERE brand_level_name IN ('A级品牌', 'B级品牌', 'C级品牌'))
业务上会先 join 维度表取得更多字段,最后再 order by join 左分支中的字段再 limit。改成把 limit 放到 join 左分支中,然后再 join 维度表。这样减少了 join 的行数,降低 70% 耗时。
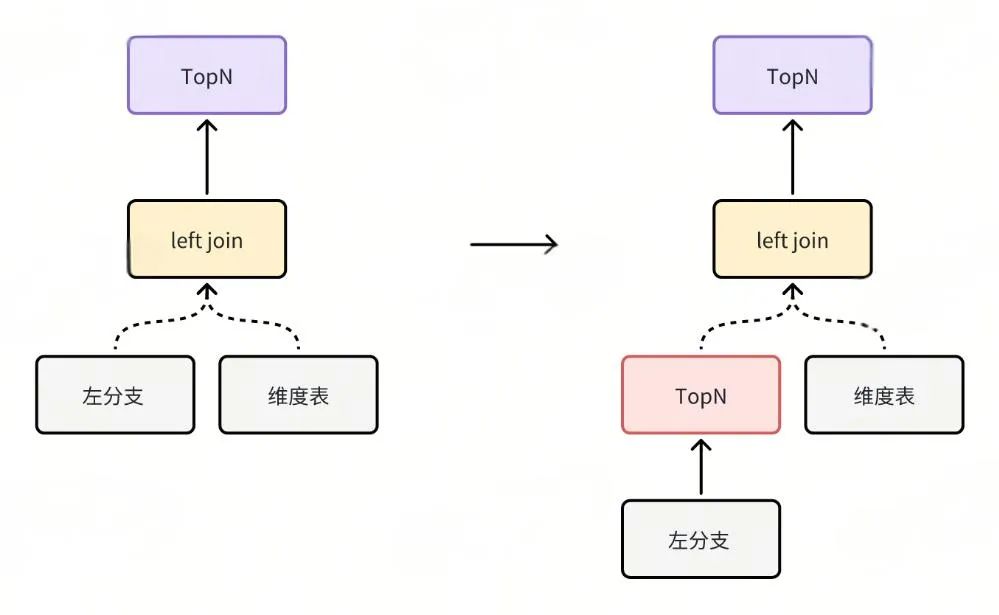
3、去除 join key 上不必要的函数调用
业务方 join on upper(query) 上,但所有 join 到的表的数据其实都是小写(这个信息只有业务方自己才知道),根本不需要转成大写后再 join。去除 upper 函数再 join提升至少一倍性能。
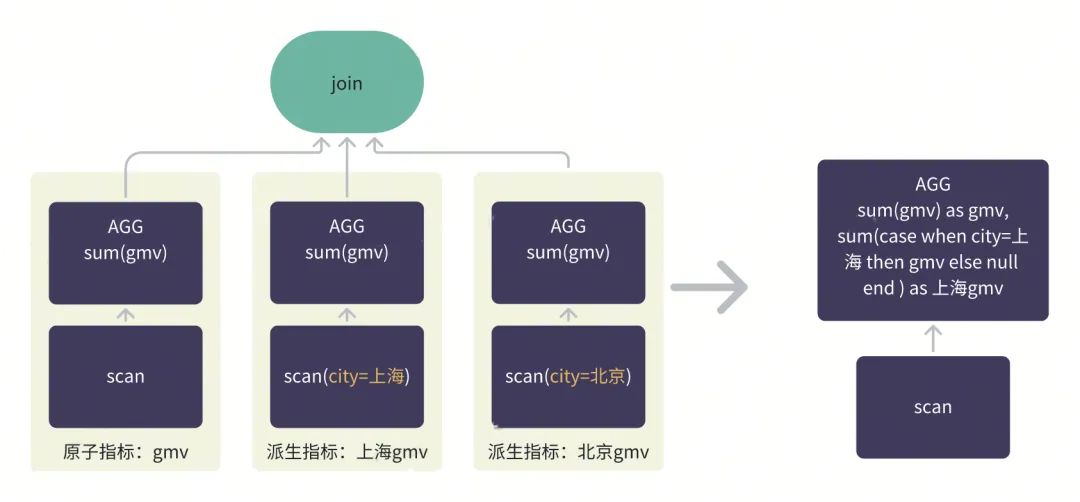
5、子查询合并,消除 join。收益性能提升约 50%
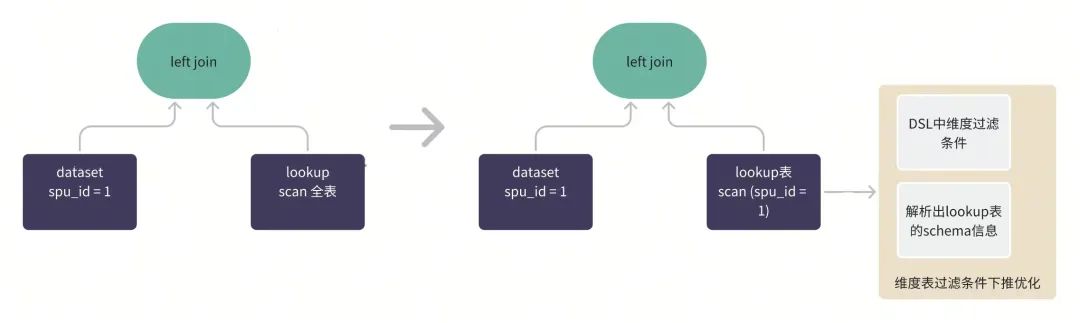
6、维度表过滤条件下推,收益:查询超时->0.1s
运维和可观测性增强
1. 资源水位 API
2. SQL 复杂度因子 API
3. 根据表名获取物化视图列表和物化视图的具体列信息 API
成本收益:智能运营底层 AP 引擎费用下降 40%,存储费用下降 5/6。 性能和体验收益:智能运营的大盘的 P95 耗时从最初的 8.5s 降低到当前的 4.3s;P0页面低基维度的耗时从最初的 9.07s 降低到 4.77s,高基维的 P95耗时从 24.38s 降低到 11.94s; 查询成功率从 98.57% 提升到 99.44%。 数据时效性收益:在双跑期间 ClickHouse 的基线 SLA 达成率是 99.42%,StarRocks 的基线 SLA 达成率是 100%。 稳定性收益:集群因为单节点异常导致集群不可用的时间从 15min 缩短到 30s 内。
我们与社区保持了密切的接触,会提交一些重大 issue,同时也贡献我们的修复给社区。迁移过程中共提交 PR 28 个,已 merge 24 个(https://github.com/StarRocks/starrocks/pulls?q=is%3Apr+author%3Akaijianding)。在迁移过程中,开发了 ClickHouse 函数兼容等 10+ 功能,修复 40+ 个问题(包括反馈给社区修复的)。
关于 StarRocks

行业优秀实践案例
泛金融:平安银行|南京银行|中原银行|中信建投|苏商银行|申万宏源|中欧财富|西南证券
互联网:微信|小红书|滴滴|B站|携程|同程旅行|芒果TV|得物|贝壳|汽车之家|腾讯音乐|饿了么|七猫|金山办公|Pinterest|欢聚集团|美团餐饮|58同城|网易邮箱|360|腾讯游戏|波克城市|37手游|游族网络|喜马拉雅|Shopee
新经济:蔚来汽车|理想汽车|吉利汽车|顺丰|京东物流|跨越速运|中通速运|大润发|华润万家|TCL |万物新生|百草味|多点 DMALL|酷开科技|vivo|聚水潭
