




分布式数据库,其中一个重要能力就是水平线性扩展,通过增加分布式的节点来提升整体的性能,其中就会涉及到数据库的扩容和缩容。
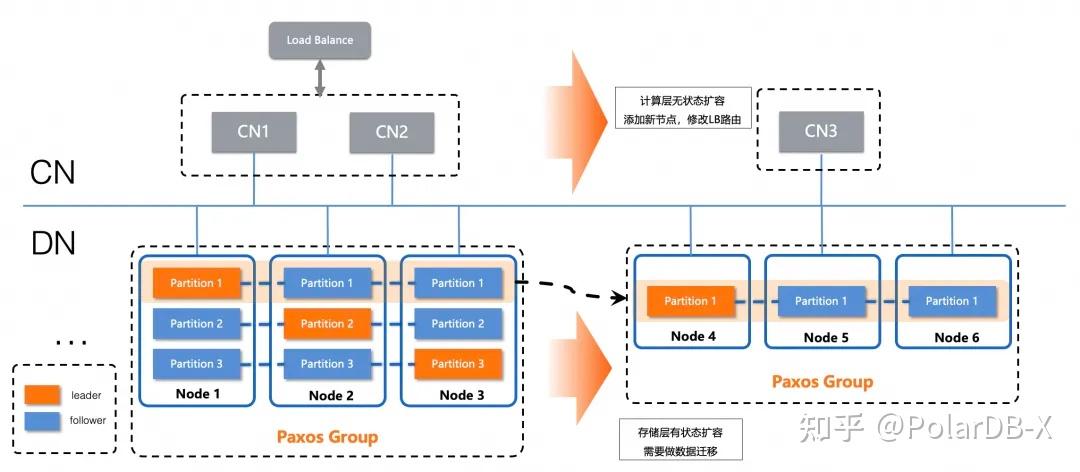
分布式数据库扩缩容的本质,就是数据分片的腾挪,整个过程涉及了全量+增量的组合。PolarDB-X v2.4.1版本,针对扩缩容能力做了全新的升级,数据腾挪的全量迁移方式,从原先默认的逻辑数据迁移演进到了基于物理文件迁移。
比如:逻辑数据的全量迁移,是通过TableScan的算子读取需要腾挪分片的所有行记录,然后通过新的Insert算子写入到指定的新节点分片中,这种方式的弊端比较明显:
- 需要读取Leader节点
,保证数据迁移的一致性,虽然仅是TableScan的读操作,也会对原节点有一定的CPU开销 - 写入目标节点,采用了逻辑Insert的方式,虽然可以走Batch批量处理优化提交,但本质上还是需要逻辑迭代执行,CPU开销比较大,执行的效率不够快
- 逻辑迁移,在分布式下的整体并行度不够大,没有充分发挥分布式多节点的效果,比如50个节点,一次性扩容25个节点,容易出现扩容耗时过长的问题
PolarDB-X v2.4.1版本,引入新的物理文件的全量迁移,可以很大程度上改善以前逻辑迁移方案的弊端:
- 数据读取,首先可以访问Follower节点,不对在线业务有影响,同时通过直接访问物理文件,不做逻辑解析,直接实现二进制的读取
- 写入目标节点,同样采用物理写入,将数据读取的二进制流直接写入目标节点,实现类似物理文件二进制拷贝的效果,CPU仅需要处理网络转发和IO落盘的操作,并不需要处理逻辑迭代
- 更大的并行度规划,引入了更确定的物理复制任务,可以将分布式的扩缩容拆分为多个物理复制的拷贝子任务的组合,通过MPP并行计算调度到多个节点,实现分布式的并行扩缩容
# 开启物理复制迁移
set global physical_backfill_enable=true;
# 关闭物理复制迁移
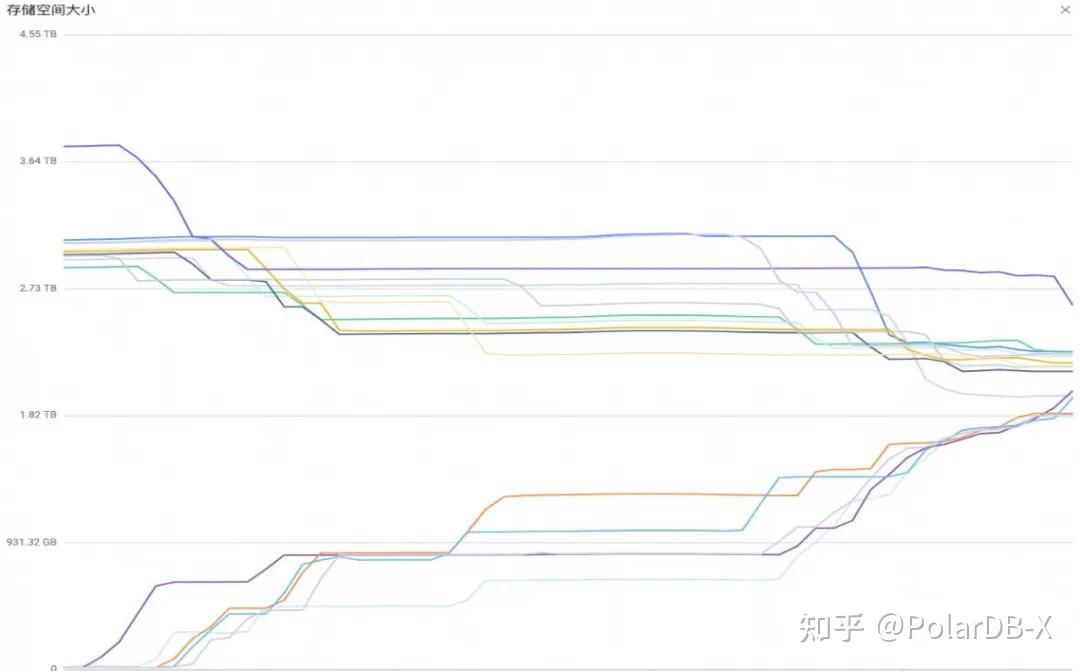
set global physical_backfill_enable=false;同时,我们设计了分布式大规模的扩缩容实验,实例规格:35个CN(8C32G) + 70个DN(8C32G),TPCC 50万仓(总计约45TB)
- DN缩容,70节点缩容为40节点,涉及总数据量19.53TB,总耗时80分5秒,总的迁移速度4096MB/s,平均单节点135.6MB/s
- DN扩容,40节点扩容为70节点,涉及总数据量17.51TB,总耗时68分6秒,总的迁移速度4439.4MB/s,平均单节点149.8MB/s
整个扩缩容期间,核心的CN/DN组件的资源水位线均正常,无CPU/内存/IOPS显著高出预期的现象。
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
