




在已经过去的 2024 年,RAG 的发展可以称得上是风起云涌,我们回顾全年,从多个角度对全年的发展进行总结。
首先用下图镇楼:
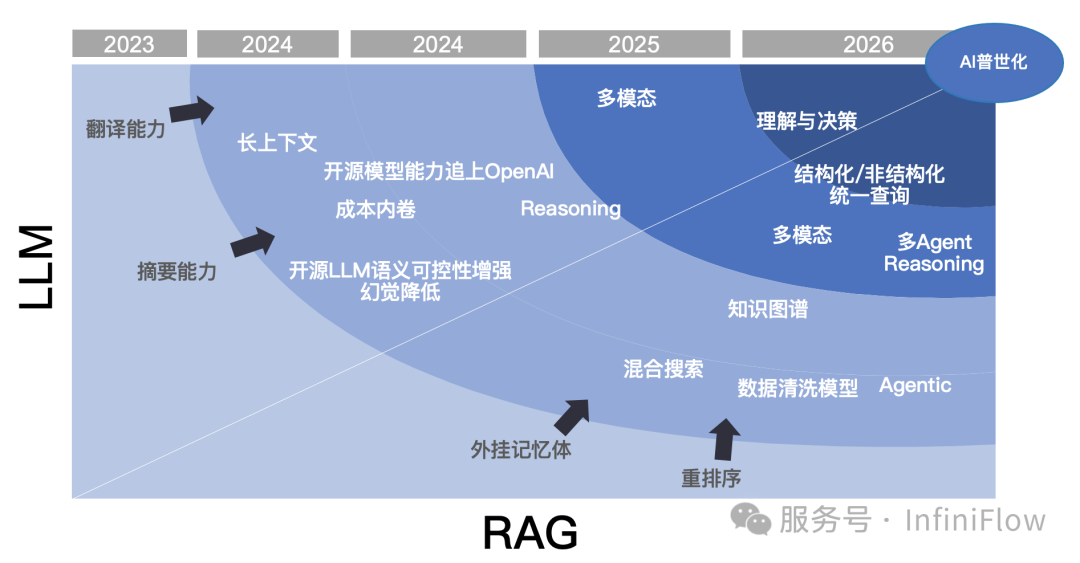
对于2024年的RAG来说,有一系列标志性事件:
但是如何让 RAG 在更多场景和企业用起来,并且可以匹配 LLM 能力的进展,RAG 一直都在面临着技术挑战,【参考 29】【参考 30】这些论文或者文章,是来自学术界对于 RAG 挑战的一些传统解法。这里边的一些原则并无问题,一些实践也已经广为接受,但从实际总结来看,RAG 面临的问题,主要就三类:
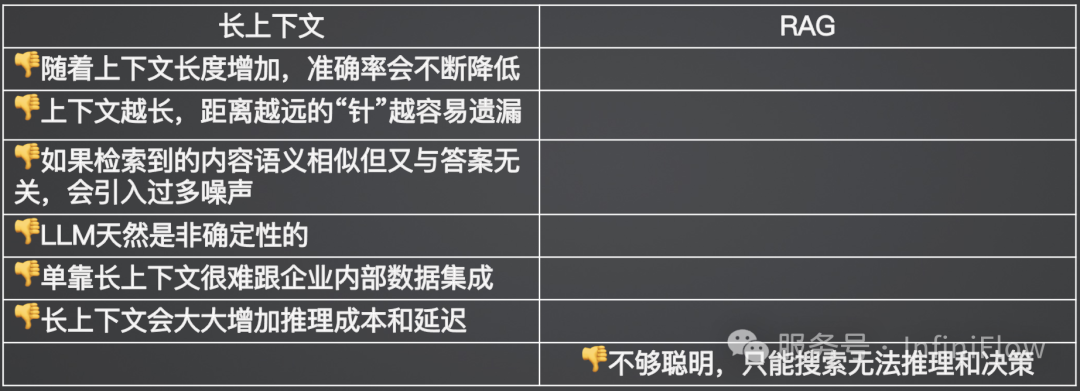
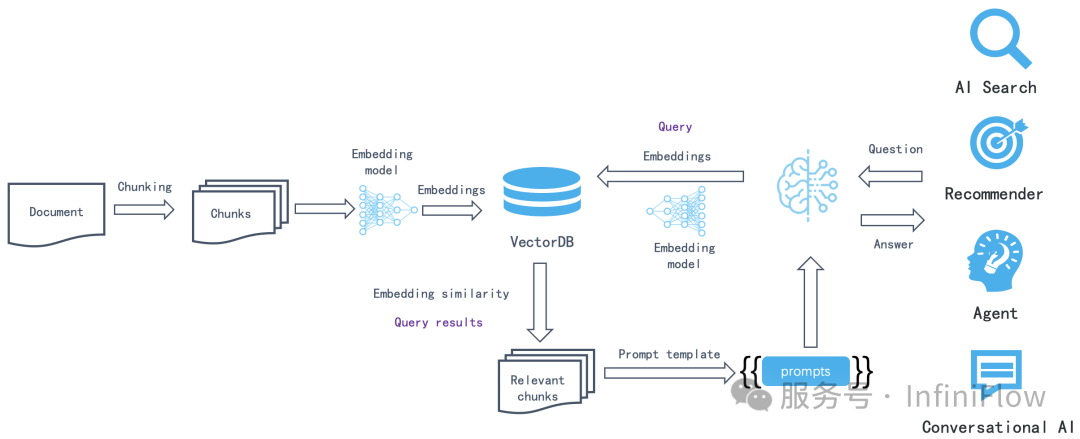
针对非结构化多模态文档无法提供有效问答。这意味着以 LLMOps 为代表的工作,只能服务纯文本类场景,而像 PDF、PPT,乃至类似图文结合的格式数据,就无法解锁其实际商业价值,这些数据往往在企业内部占据大多数比例。 采用纯向量数据库带来的低召回和命中率,从而无法针对实际场景提供有效问答,这主要是因为向量表征不仅缺乏对精确信息的表达,对语义召回也有损耗。 RAG 的本质是搜索,它能工作的前提在于根据用户的提问,可以“搜”到答案所在。但是在很多情况下,这个前提不存在,例如一些意图不明的笼统提问,以及一些需要在多个子问题基础之上综合才能得到答案的所谓“多跳”问答,这些问题的答案,都无法通过搜索提问来获得答案,因此提问和答案之间存在着明显的语义鸿沟。
因此,下边的这些标志性事件,都是围绕 RAG 本身的技术挑战发生。
2. 一系列多模态文档解析工具的崛起。
3. BM25 和混合搜索的崛起,向量数据库已不需要作为单独品类。
在 2024 年 4 月 1 日,我们开源了完整的 RAG 引擎 RAGFlow ,截止到年底已经超过了 2.5 万 github 星标,它最开始的 2 个设计亮点,已经成为普适性的 RAG 架构设计准则:
其中之一就是针对朴素 RAG 系统只提供基于文本的 Text Chunking 工具,RAGFlow 引入了针对非结构化数据进行 Semantic Chunking 的步骤,从而保证数据的入口质量。具体做法就是采用专门训练的模型来解析文档布局,避免简易的 Text Chunking 工具对不同布局内部数据的干扰。随后,开源社区利用模型来解析各种文档的工具越来越多,这种做法逐渐深入人心。
其二则是从一开始就坚决采用企业级搜索引擎提供混合搜索,来作为唯一的后端数据库。因为利用提供 BM25 能力的全文搜索,可以保证精确查询能力,尽管 BM25 已是近三十年前的技术,但 RAG 再次释放了这种古老技术的青春。今年开始许多向量数据库也开始提供 BM25 ,年中知名向量数据库 Qdrant 甚至提出了 BM25 的改进 BM42,不过事后发现是闹了乌龙。尽管声称提供 BM25 的数据库很多,但真正满足 RAG 要求的少之又少。可是 BM25 崛起已是事实,纯向量数据库已经没有必要作为一个单独的品类而存在,混合搜索的理念深入人心。
RAGFlow 可以说正是以上 2 个事件的始作俑者之一。
4. GraphRAG 的崛起。
微软年中开源 GraphRAG 是一个现象级事件,作为一个库而非端到端产品,能在短时间内获得大量关注,说明它确实解决了 RAG 的一些核心问题——这就是语义鸿沟。做搜索系统的人很早就在面临这样的麻烦,因为查询和答案之间并不总能保证可以匹配。当搜索系统升级到 RAG 之后,这样的问题被放大:搜索系统的查询是用户定义的几个关键词,而 RAG 的查询是用户的提问,从关键词到提问,用户的意图更加难以判断,因此放大了这种语义鸿沟问题。GraphRAG,就是缓解这种语义鸿沟的设计之一。
5. 以 Col-xxx 为代表的延迟交互模型崛起。
6. 基于 VLM 和延迟交互模型实现多模态 RAG。

本文更多站在产业和学术结合的角度,从最终实践,来把今年有代表性的工作做一个总结,这些工作其实有不少并不是以 RAG 为主题的论文来涵盖的范畴,因为在我们看来,RAG 始终并不是一个简单的应用,它是一个以搜索为中心,结合各类数据、基础组件、各类大模型小模型在一起协同工作的复杂系统,每个子问题都有对应的工作,所以不仅仅需要站在 RAG 本身来回顾,也需要有全局视角。
数据清洗
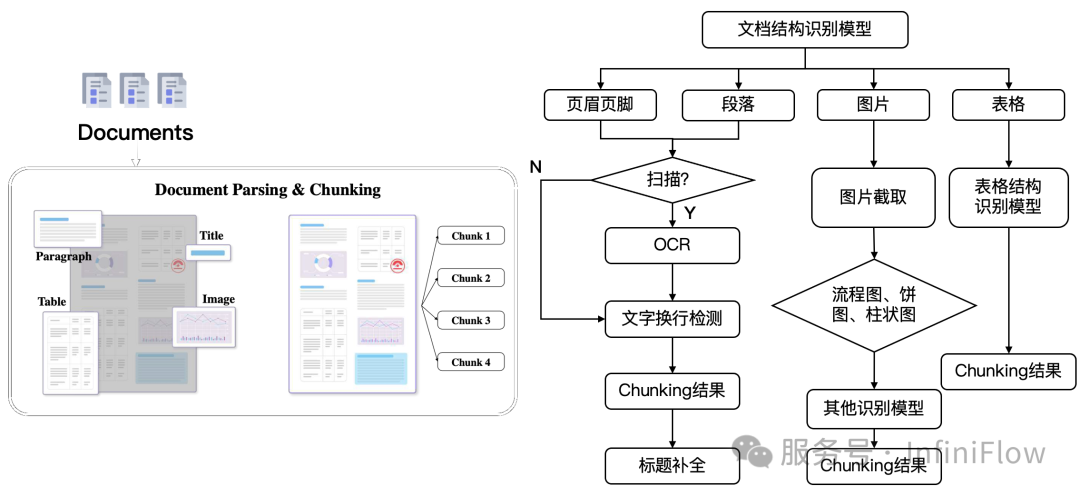
文档结构识别模型的任务,是识别出非结构化文档不同语义区域的坐标。这类模型在一些 OCR 系统中就提供相应的功能,例如知名的 PaddleOCR 【参考1】就提供了针对文档结构识别模型。因此,以上一系列工作,包括表格等等,也常被称作广义 OCR ,可以理解为 RAG 的入口,需要搭配这样一个广义 OCR 来实现。
RAGFlow 的 DeepDoc 模块,是较早实现完整这类模块的系统,它是 RAGFlow 刚开源就迅速增长的重要原因。如今,类似的系统已经有多个,例如 MinuerU【参考2】,Docling【参考3】等等。将文档智能用于 RAG 是个广阔的方向,因此这类工作的迭代大大加速。
从方法上,文档智能模型的工作也可以分为 2 代:
采用这类多模态模型提供文档智能的另一个好处,就是在文档布局中可以引入文本信息,今年的一个代表工作 M2Doc 【参考23】,在基于视觉的 Encoder-Decoder 架构上融合了 BERT,可以更好地确定文字和段落的语义边界。
在即将到来的 2025 年,基于 Encoder-Decoder 架构的工作,会有更大的发展,我们可以预期,完全有可能将这类模型做成统一的多模态文档解析模型,对于各类非结构化的文档,都可以精准还原成文本内容。
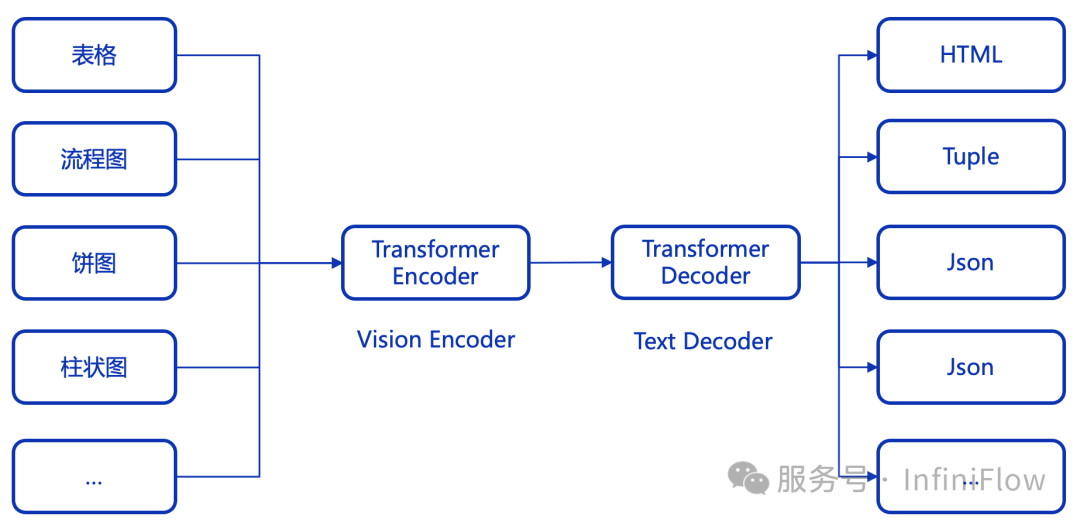
以上可以看作针对多模态非结构化文档数据的数据清洗。
那么针对文本文档,是否采用朴素的 Text Chunking 就可以了呢?答案依然是不够的,如果 Text Chunk 仅包含文本类信息,那么在检索过程中面临的主要问题,就从 Chunk 内容的混乱变成了语义鸿沟。关于这一点,我们在下文会有单独的章节来描述。
这里介绍从 Chunking 层面可以弥补的工作。
Jina 在今年推出了 Late Chunking 【参考24】,针对文本类数据,它把 Text Chunking 的步骤放到了 Embedding 之后。也就是说先用 Embedding 模型对整个文档的文本进行编码,然后在 Embedding 模型最后一步的均值 Pooling 之前输出 Chunking 的边界,这就是“Late”一词的由来。跟传统的 Text Chunking 方法相比,Late Chunking 可以更好地保留文本上下文信息。不过,Late Chunking 需要 Embedding 模型最后的输出是均值 Pooling,而大多数 Embedding 模型则是 CLS Pooling,因此并不能直接搭配。
2024 年工业界也针对文本类数据推出了 dsRAG【参考25】。它的主要贡献在于提供了自动上下文,就是利用大模型给每个 Text Chunk 添加上下文信息,用来解决原始文本不容易检索的问题。例如文本中如果包含疾病治疗方案,而治疗方案却没有疾病描述,那么检索时可能就无法命中这段文本。dsRAG 的另一个工作是通过聚类,来组合 Text Chunk 形成更长的文本,尽管评测分数良好,但这一点在实际使用未必奏效。
LLM 提供商 Anthropic Claude 在 9 月的时候也推出了 Contextual Retrieval 【参考26】,其中一个重要部分是 Contextual Chunking,顾名思义就是给每个 Text Chunk 引入特定于该 Chunk 的上下文解释。这个解释当然也是来自于 LLM 生成。因此,Contextual Retrieval 和 dsRAG 是类似的效果。
人大和上海算法创新研究院在 10 月推出了 Meta-Chunking 【参考45】,其主要目标在于寻找到文本段落内具有语言逻辑链接的句子集合的边界。具体做法是采用 LLM 进行分类,判断句子是否在一个 Chunk。相比前述工作,它并不能缓解语义鸿沟的问题,尽管也用到了 LLM。
相似时间点,上海人工智能实验室和北航联合推出了多粒度混合 Chunking 【参考46】,每个文档都被切割成较小粒度的 Chunk,通常由一两个句子组成。这些 Chunk 被视作图的节点,检索的时候,根据查询由模型来预测需要的 Chunk 粒度,然后在图结构中根据这个粒度决定图中遍历的深度——遍历越深,相当于最终的 Chunk 粒度越大。这种手段,实现较为复杂,但并没有缓解语义鸿沟方面的问题,只是动态决定返回大模型的上下文长度,避免上下文冗余,因此实际价值不如上述的一些方案大。
混合搜索
在 2024 年 4 月,来自 IBM Research 的一篇技术报告 BlendedRAG【参考7】,通过实验论证了对于 RAG 来说,采用更多的召回手段可以达到更好的效果。其中采用向量搜索 + 稀疏向量搜索 + 全文搜索的三路混合,可以达到最好的召回。
这其实很容易理解,因为向量可以表示语义、一句话乃至一篇文章,都可以只用一个向量来表示,这时向量本质上表达的是这段文字的“语义”,也就是这段文字跟其他文字在一个上下文窗口内共同出现概率的压缩表示 ,因此向量天然无法表示精确的查询。例如如果用户询问“2024年3月我们公司财务计划包含哪些组合”,那么很可能得到的结果是其他时间段的数据,或者得到运营计划、营销管理等其他类型的数据。而全文搜索和稀疏向量则主要是用来表达精确语义的。因此,将两者结合符合我们日常生活中对语义和精确的双重需求。
分词后删掉无意义的词
给剩余的词计算对应的词权重
给剩余的词产生基于二元分词的短语查询,它们和常规分词结果一起被送去作为查询
因此,一个对话“在原文中,教师应该在什么时候提问?”,它产生的查询可能会有如下的结果:
((原文中 OR "原文" OR ("原文"~2)^0.5)^1.0) OR ((教师)^0.9991 (提问)^0.000541 (应该)^0.000368 ("教师 应该 提问"~4)^1.5)((企业)^0.550884 (格局)^0.252471 (文章)^0.195081 (新发)^0.000607 (提到)^0.000261 (展)^0.000262 (适应)^0.000230 (应该)^0.000203 ("文章 提到 企业 应该 适应 新发 展 格局"~4)^1.5)
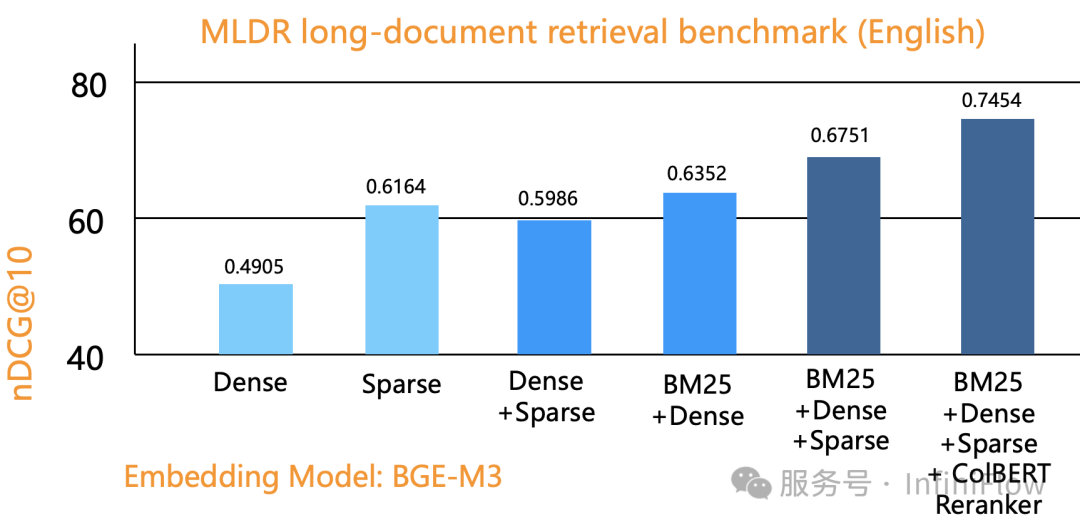
下图是我们利用 Infinity 数据库在一个公开评测数据集上,分别利用单路召回(向量、稀疏向量、全文搜索)、2 路召回、3 路召回评测的结果。纵坐标是排序质量,可以看到,3 路召回确实可以达到最好的效果,这用单一数据库完全验证了 BlendedRAG 的实验结果。图中最右侧是 3 路召回 + 基于张量的重排序得到的结果,关于这点,我们在下文还有提及。
2024 年 6 月, OpenAI 收购了数据库创业公司 Rockset,在 2023 年底的 GPT-4 Turbo 发布中,人们还找到了知名向量数据库 Qdrant 的影子,然而短短数月后,Rockset 就被收入囊中。这其中很重要的考虑,就是 Rockset 是为数不多可以替换 Elasticsearch 的选择,当然这还跟它采用了云原生架构有关,因此这样的 Data Infra 组件搭配 OpenAI ,可以很方便给各类用户提供基于 RAG 的 SaaS 服务。
排序模型
排序是任何搜索系统的核心。在 RAG 上下文里,排序和两个组件有关,一个是用来做粗筛的部分,这就是向量搜索依赖的 Embedding 模型,另一个是在精排阶段所用的 Reranker 模型。
重排序模型和 Embedding 模型的训练常常共享很多工作,对于 Embedding 模型来说,它通常采用 Encoder 架构,它的训练目标是使得语义相似的文本在向量空间距离更近,而 Reranker 则采用 Cross Encoder 架构,它的训练目标是预测查询和文档之间的分数。
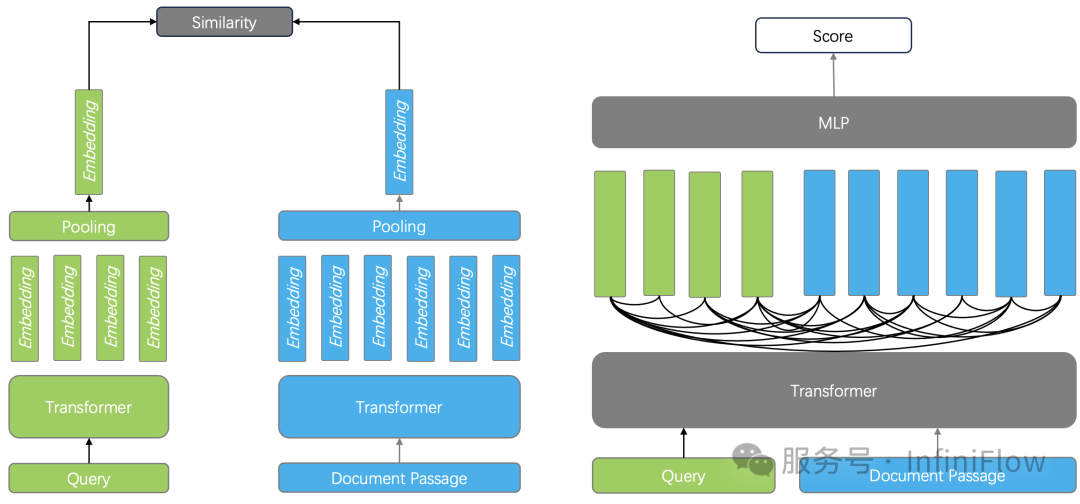
如下图所示,左边就是 Embedding 模型的工作方式:分别对查询和文档进行编码,然后经过 Pooling 后输出一个向量,在排序阶段只需要计算向量相似度。由于丢失了查询和文档中 Token 之间两两之间的交互信息,因此会丢失很多语义信息,所以向量搜索常用来做粗筛。
而作为 Reranker 的 Cross Encoder,它的 Encoder 网络可以跟 Embedding 模型完全一致,但它因为把查询和文档一起输入模型,最终只输出一个得分,因此则可以捕获 Token 之间两两之间的关系,所以它的排序质量要高出很多。
但 Cross Encoder 也有它的问题:对于 Encoder 来说,文档的 Embedding 在建立索引的离线阶段就可以完成,因此在线查询阶段只需要对查询进行编码,就可以快速得到答案。而 Cross Encoder 需要对每个查询-文档对进行交叉编码和模型输出,计算成本高昂,所以它只能用来做重排,并且粗筛的结果不能太多,否则会大大增加查询延迟。
评测 Embedding 模型和 Reranker 模型,通常可以观察 MTEB 榜单,在 2024 年上半年,Reranker 的榜单基本都是 Cross Encoder ,而到了下半年,榜单更多为基于 LLM 的重排序模型所占据。例如目前排名榜首的 gte-Qwen2-7B 【参考31】,是基于 Qwen2 7B 的基座模型微调而来。这类方案已经不是 Encoder 架构,而是标准 LLM 的 Decoder 架构,由于参数量更大,因此推理成本更高。
综合排序效果和成本,一种被称作延迟交互模型的重排序方案引起关注,这就是基于张量的重排序,如下图所示。
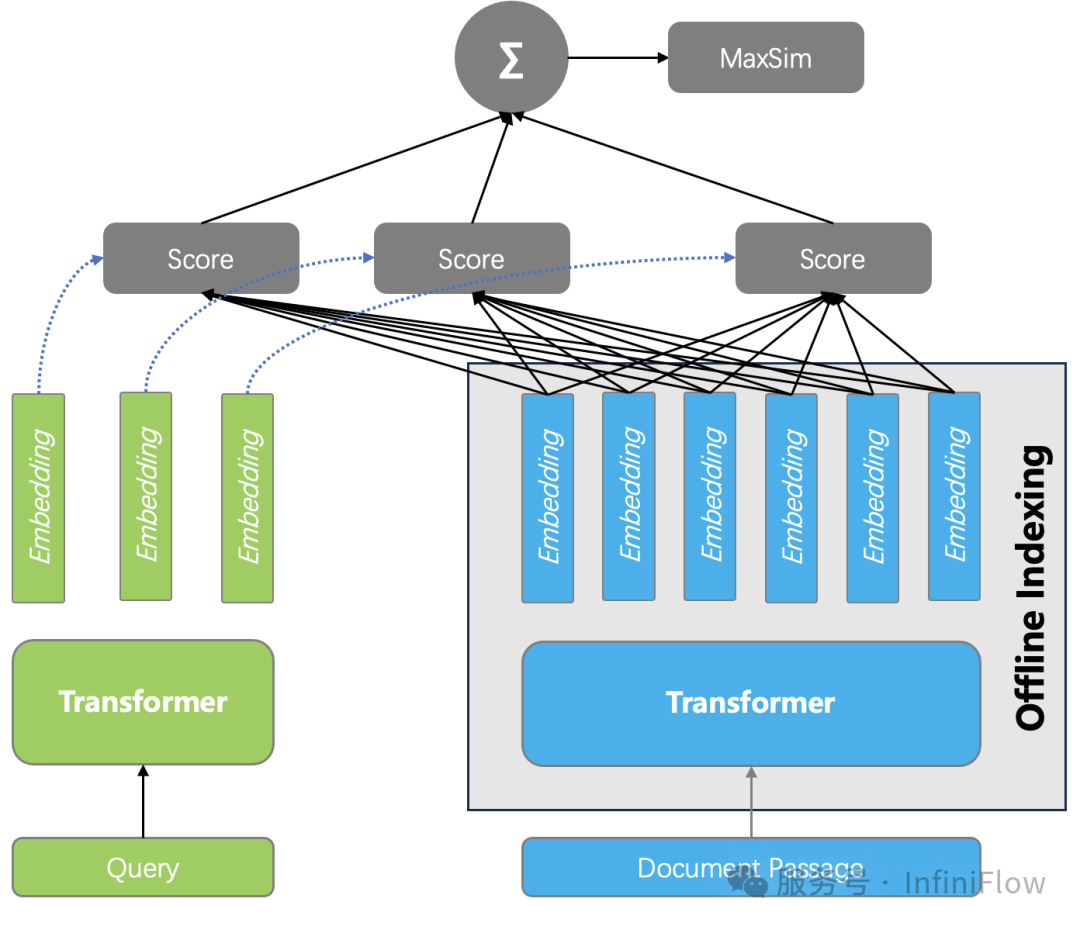
它的具体做法是:在索引阶段保存 Encoder 为每个 Token 生成的 Embedding,因此对于一个文档来说,就是用一个张量 Tensor (或者多向量)来表示一个文档,在查询的时候,只需要生成查询的每个 Token 的 Embedding,然后计算所有查询和 Text Çhunk 之间所有 Token 两两之间的相似度,累加就是最终文档得分。这种重排序,同样捕获了 Token 之间的交互信息,所以理论上可以做到跟 Cross Encoder 接近或者持平的效果。
而另一方面,由于在查询时不涉及复杂的模型推理,所以它的成本相比 Cross Encoder,或者基于 LLM 的 Reranker 要低得多,这甚至可以把排序做到数据库内部,因此带来的好处就是:即使粗筛的结果并不理想,但采用基于张量的重排序,可以对更多的结果进行重排,因此也有很大的概率弥补之前的召回。
下图是我们用 Infinity 数据库在单路召回,2 路召回,以及3 路召回的基础上,分别应用 Tensor Reranker 的评测效果对比:
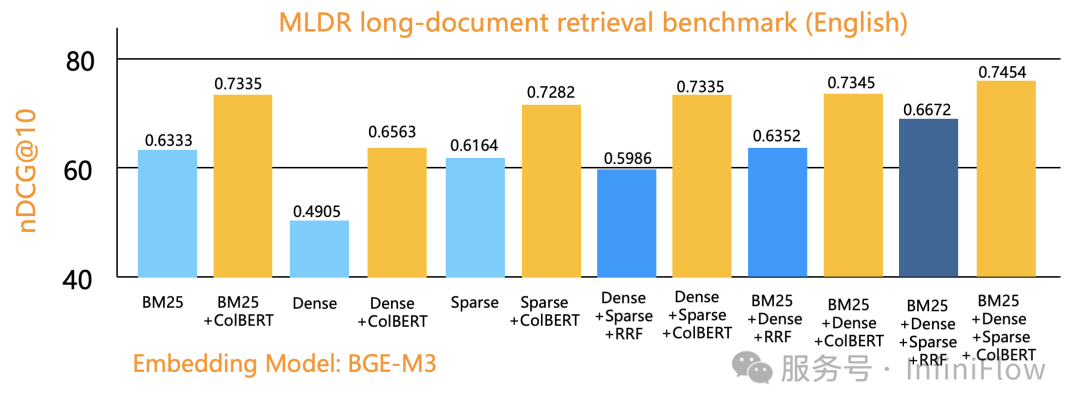
基于张量的重排序,来自于 2020 年一篇早期工作 ColBERT【参考32】及其改进 ColBERT v2【参考33】,但是它真正为业界重视起来正是 2024 年初,只是在当时,由于缺乏必要的数据库支持,因此不得不借助于 RAGatouille 【参考34】这样的 Python 算法封装来提供服务。Vespa【参考35】是最早将张量工程化的数据库系统,我们则在年中的时候,为 Infinity 数据库完整地提供了基于张量的重排序能力。目前,基于张量的重排序系统在行业使用并不多,除了 Infra 组件不够多之外,配套的模型缺乏也是重要原因。
语义鸿沟
2024 年上半年,微软公开了 GraphRAG 的论文【参考8】,在年中的时候,GraphRAG 正式开源,在很短时间内就超过了上万 github 星标,那么是什么原因导致 GraphRAG 如此火爆呢?这就来到我们前文提到的 RAG 的第三个痛点:语义鸿沟。
实际上解决语义鸿沟的工作有很多,除了在前文提到的 Chunking 阶段,在预处理阶段还可以做更多。一个知名且实用的工作就是 RAPTOR【参考9】。RAPTOR 首先把文本内容预聚类,接着利用 LLM 对聚类后的文本生成摘要,这些摘要数据连同原始文本一起被送到搜索系统。由于这些摘要数据提供了对文本更加宏观的理解,因此对一些意图不明的提问,还有需要跨 Chunk 的多跳提问,都可以产生合适的回答。RAPTOR 在年中的时候就已经被添加到了 RAGFlow 中,用来辅助回答复杂提问。
在 2024 年底的时候,在 RAPTOR 基础之上又有了 SiReRAG【参考17】,它对于文本召回有了更细粒度的定义:文本之间分别采用相似度和相关性衡量不同维度的需求,如下图所示:相似度就是直接采用向量或者全文搜索等其他手段计算 Text Chunk 之间的语义距离,这就是 RAPTOR 本身,也是图中左边的部分;相关性表示 Text Chunk 之间存在某种关联,它首先通过采用 LLM 从每个 Text Chunk 提取命名实体,再根据命名实体跟 Text Chunk 之间的关系构建层次化树状结构,就是图中右边的部分。
这样,在召回的时候,有多种不同的文本粒度共同提供混合召回,包括实体、实体分组、原始文本,因此可以继续增强对于数据宏观层面的理解,在意图不明和多跳问答查询上的召回有进一步提升。
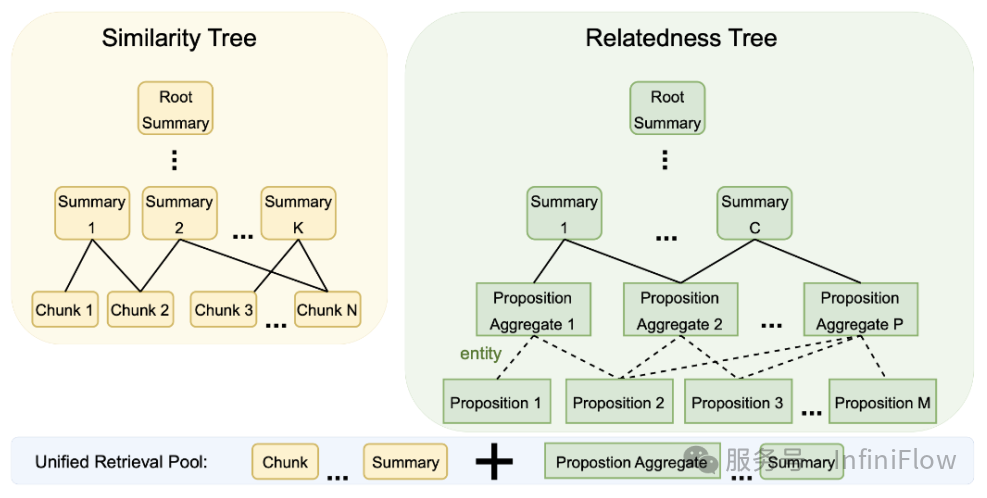
SiReRAG 其实跟 GraphRAG 已经很接近了,区别仅在于抽取出的实体如何进一步加工和组织。
下边来看 GraphRAG 本身:它利用大模型自动抽取文档内的命名实体,然后利用这些实体自动构建知识图谱。在图谱中,同样利用聚类产生实体聚集的“社区”,并利用 LLM 生成这些社区的摘要。在召回的时候,知识图谱的实体、边、以及社区摘要,它们连同原始文档一起来做混合召回。由于这些数据同样形成了文档中跨 Chunk 的关联信息,因此对于宏观性提问、多跳提问有着更好的效果。GraphRAG 可以看作是解决语义鸿沟的当下行之有效的策略和架构。
之所以用“架构”,是因为这其实代表了一种范式:如何用 LLM 来抽取知识图谱,通过辅助召回来解决复杂问答的设计。除了微软之外,同期还有很多其他厂家提出的 GraphRAG 方案,例如蚂蚁的 KAG【参考10】,Nebula 的 GraphRAG 【参考11】等等,它们侧重各有不同,例如 KAG 更加侧重知识图谱的完整性和可解释性,因此为了追求垂直领域的专业性,需要融合人工维护和专家知识元素。Nebula GraphRAG 主要强调与知名 LLM 框架如 LangChain 和 Llama Index 的深度集成体系,并且融合到 Nebula Graph 图数据库中。
在 GraphRAG 架构中,一个很大的痛点是 Token 消耗非常惊人,因此, GraphRAG 之后又出了很多变种,代表性的有 Fast GraphRAG【参考12】、LightRAG【参考13】,以及微软很快就要公开的 LazyGraphRAG【参考14】。
Fast GraphRAG 同样利用 LLM 抽取实体和关系,这点跟微软的 GraphRAG 并没有什么不同,但它省掉了“社区”及其摘要的生成,降低了对 LLM 请求的频率。在检索时, Fast GraphRAG 根据查询在知识图谱上找到最接近的实体,然后采用个性化 PageRank 在知识图谱上随机游走,获取子图,然后依靠子图生成最终答案。
PageRank 是一种有效策略,提到它,这里就不得不提及在 2024年另一篇影响力很大的知识图谱相关工作海马体 HippoRAG【参考15】,在这篇文章中提到了海马体索引理论,基于个性化 PageRank 的随机游走策略,和人类大脑根据记忆思考的方式很类似,因此把知识图谱构建好之后,在查询的时候按照个性化 PageRank 来检索知识图谱,可以模拟人类大脑基于长文本类信息进行回忆和思考的过程。
不论是 Fast GraphRAG,还是 HippoRAG,都可以用下图进行模拟。在这个图中,我们还添加了 GNN 的元素,这是因为在 2024 年,基于图神经网络来改进基于知识图谱问答的工作也出现了不少,例如【参考18】等,【参考19】还提供了这方面的概述。有兴趣了解的同学可以移步文献自行阅读。由于 GNN 的工作通常需要借助于用户数据进行额外训练,例如借助客户已有的问答数据对知识图谱中的命名实体产生更好的 Graph Embedding 表示,这些工作涉及到很高的定制化成本,因此不在本文的主要涵盖范围内。
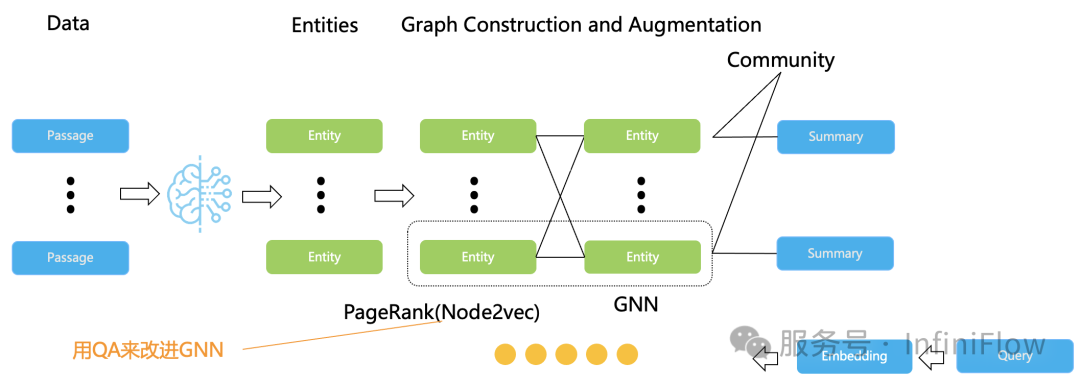
LightRAG 也是对 GraphRAG 的简化,它拿掉了社区,因此更加轻量级。而微软在接近 2024 年底提出的 LazyGraphRAG,则是对 GraphRAG 的完全简化,它甚至已经不依赖 LLM 来抽取知识图谱,只用一些本地小模型抽取名词,然后根据共现情况提取社区结构。至于社区的摘要,则只在查询时动态处理。
另一类降低 GraphRAG 开销的工作来自模型本身,既然 LLM 抽取代价昂贵,那么微调一个专用的小一些的模型,成本自然可以大幅下降。Triplex【参考16】就是这样的工作,它利用 3B 的 Phi-3 来抽取知识图谱。
从以上可以看出,GraphRAG 架构实质上是利用 LLM 给原始文档补充足够的信息,这些信息以易于连接的图格式组织在一起。搜索时,在文本相似度之外又添加引入基于各类实体产生的相关信息带来的辅助召回能力。因此,在 GraphRAG 中,知识图谱的价值并不在于给人来查看,而更多是为复杂和意图不清的提问提供更多依据和上下文。
尽管知识图谱出现已久,可它在过去的应用主要是伴随大量可解释类工作,例如数据导航等,所以需要人工和领域专家介入,这并不是 GraphRAG 的应用舒适区,即使由 LLM 抽取的命名实体和关系,它们依然存在着大量噪音。所以,鉴于 LLM 抽取知识图谱的能力限制,围绕 GraphRAG 的后续工作,除了降低成本之外,还在于如何把实体组织成更有效的结构,临近年底的时候,这方面分别出了 KG-Retriever【参考20】,Mixture-of-PageRanks【参考21】,前者把知识图谱连同原始数据在一起,构建成多层次的图索引结构,检索时采用不同粒度;后者在个性化 PageRank 的基础上,引入了基于时间的相关性信息。我们可以预计,这方面的工作在 2025 年还会有更多,但它们并不会改变 GraphRAG 这一类工作的本质。
我们来看具体数据建模:在 GraphRAG 中,知识图谱的实体、边,这些都是文字描述,此外还有根据实体之间聚类得到的社区以及由此生成的总结。一个典型的 GraphRAG 数据建模可以如下图所示:

一个功能完备的全文索引,除了提供相似度得分计算之外,还应该提供基于关键词的过滤能力。因此,对以上 Schema 中边的 <源实体名,目标实体名> 字段建立全文索引提供关键词过滤,就可以很方便地进行基于边和实体的子图检索。
除此之外,如果数据库可以提供无缝衔接的全文索引和向量索引,就可以针对 GraphRAG 提供非常方便的混合搜索,所有边、实体,乃至社区,它们的描述都被纳入全文搜索的范畴,连同向量一起,就提供了基于 GraphRAG 的 2 路混合召回。
从以上数据 Schema 也可以看出,这些数据只需要再增加一个类型字段,就可以连同原始的文本 Chunk 一起保存在同一张表,这就是把 GraphRAG 和 RAG 结合的 HybridRAG 【参考22】。显然,采用一个具备丰富索引能力的数据库,可以极大降低 GraphRAG 落地的工程难度,即便是诸如 KG-Retriever,Mixture-of-PageRanks 等各类改变图结构的工作,也可以通过调整索引格式以及增加特定索引的搜索方式,方便地支持。这其实也是我们从零来实现这样一个专门服务 RAG 的数据库的初衷之一。
Agentic 与 Memory
Agentic 是 2024 年 RAG 产业的一个热门词。也有很多媒体定义 2024 年是 Agent 元年,不论是否如此,Agent 都在很大层面上影响着 LLM 生态。本文不是 Agent 的回顾,但 Agent 确实在各方面,形成了跟 RAG 密不可分的关系:RAG 本身是 Agent 的重要算子,它可以解锁 Agent 访问内部数据的能力;Agent 直接用于 RAG,可以提供高级 RAG 能力,这就是所谓 Agentic RAG,例如 Self RAG【参考39】,Adaptive RAG 等等。
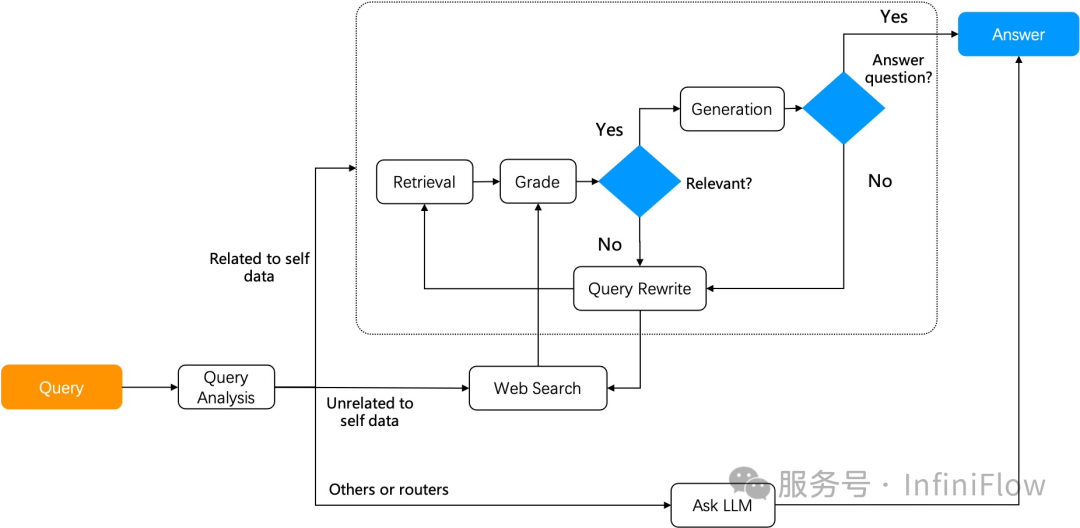
2024 年 Agent 的代表工作是工作流的广泛使用,无论 Agent 如何演进,工作流总是必不可少的,例如跟各类系统的集成,例如希望 Agent 以可控的方式执行等等。然而 Agent 是比工作流更大的范畴,它还承载了各种跟 Reasoning 相关的思考和决策,在 2024 年下半年,这方面的工作开始提速。
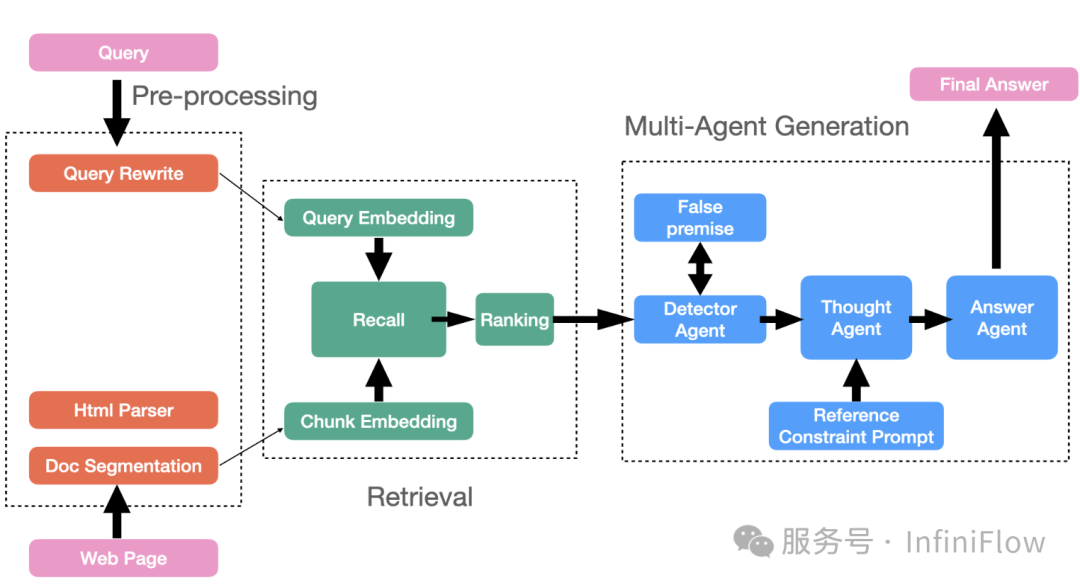
把 RAG 跟这样的 Agent 集成到一起,可以解锁更多的场景:例如下图的组合方式【参考41】,在这里,系统存在多个可以自主决策的 Agent ,它可以把复杂的问答分解为多个子任务,每个 Agent 负责特定的功能,这种分工可以提高系统的整体效率和准确性。图中,Detector Agent 旨在识别可能包含错误假设和前提的查询,这些查询会影响 LLM 回答的准确性;Thought Agent 负责处理和分析所有检索到的内容信息,它综合数据得到结论,并生成一系列详细的 Reasoning 思考结果;Answer Agent 利用 Through Agent 的输出产生答案,它的目的是在多轮对话中确保答案的输出受到最新的逻辑影响。
再例如 RARE【参考42】,它在 RAG 的基础上增加了 MCTS 蒙特卡洛树搜索框架,通过 2 个动作来在检索的基础上增强 Reasoning 能力:基于初始问题生成查询;基于生成的子问题进行查询。通过引入这些步骤,RARE 可以实现 RAG 在医疗场景下的复杂推理和常识推理。
伴随着这种 Reasoning 能力,可以看到 RAG 和 Agent 之间已经密不可分,交互更加频繁,因此,RAG 需要为 Agent 提供除上文提到的文档搜索之外的记忆管理功能。这些记忆信息包括:用户对话 Session,用户个性化信息等等。Agent 不仅仅需要调用 RAG 完成内部数据的搜索,还需要实时获取上下文信息。2024 年的现象级开源项目 Mem0,只是定义了一些记忆管理的 API,就迅速获得了大量 GitHub 星标。
然而我们需要看到的是,当前对于记忆管理的定义是一件很容易的事(主要特性是实时过滤和搜索),其背后的 Infra 组件能力也已经很成熟。因此,真正需要的是如何把记忆管理跟 Reaoning 结合,并伴随 LLM 能力的成长共同解锁更加复杂的企业级场景,而在一个标准化的 RAG 引擎上实现这些,是非常顺理成章的事情,也是开销最小和易用性最佳的选择,它必将成为 2025 年的重要和热门方向。
讲到这里,一定会有很多伙伴提出问题,就是未来的演进究竟是 RAG 把自己变成一个 Agent 平台,还是各种 Agent 平台把自己的 RAG 能力增强?这个趋势很难预测:正如我们在数字化时代,究竟是做数仓的,把做中台这种包含业务的事情也做下来,还是做业务的最终下沉自身技术能力提供更好的数仓,两者都有先例。
多模态 RAG
首先是 VLM 的涌现。如下图所示:我们看到,在过去以简单的图像搜索为主要场景的 VLM 在 2024 年年中得到了快速进化。

这意味着 VLM 对于图像的理解进入了深层次,它不仅仅停留在识别一些日常用品,而是可以对企业级多模态文档进行深度理解。我们以一个开源的 3B 小模型 PaliGemma【参考43】为例来说明这一点:
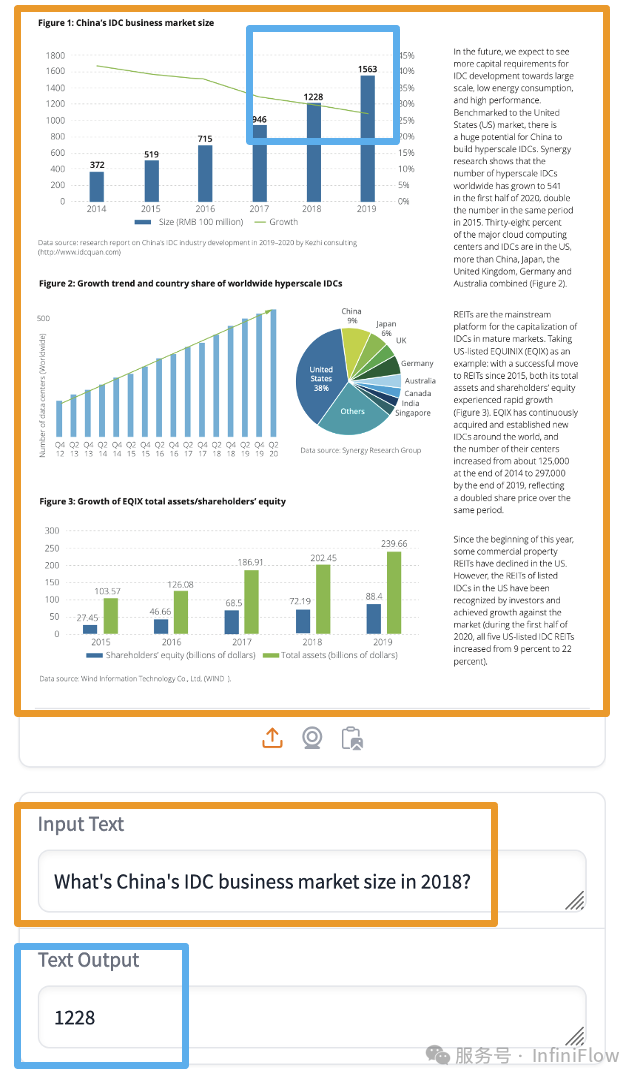
那么回到 RAG 本身,如果我们通过 RAG,根据用户的提问,可以在一大堆 PDF 中找到包含答案的图片和文字,就可以用 VLM 生成最后的答案。这就是多模态 RAG 的意义,它不仅仅可以用来回答日常用品这样的简易图像搜索。
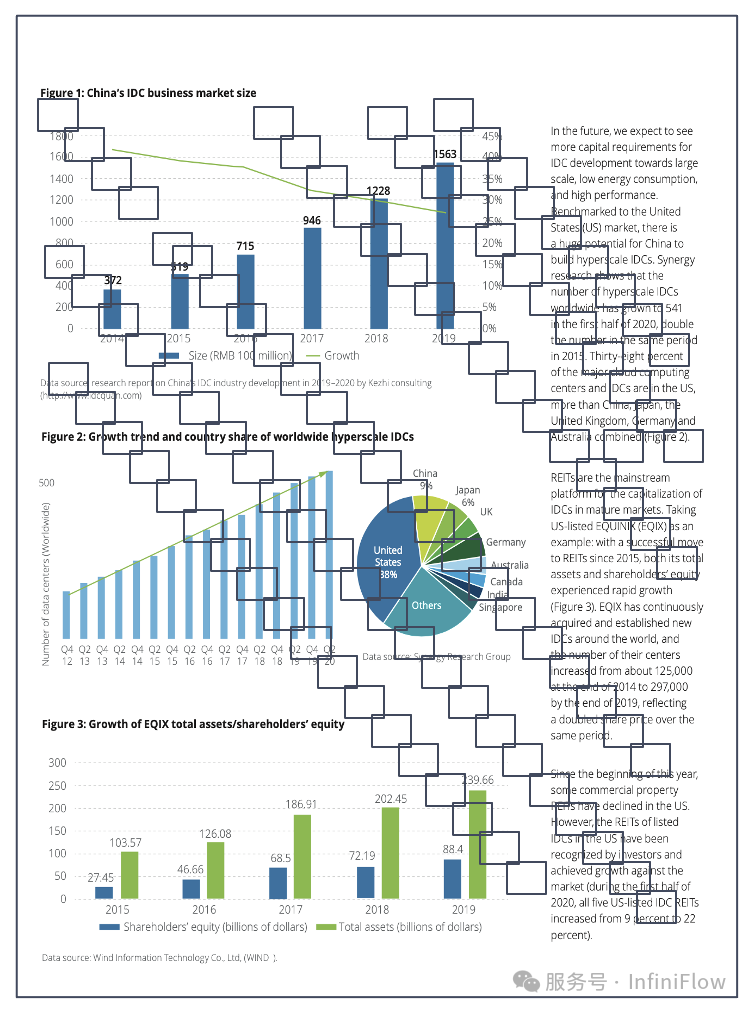
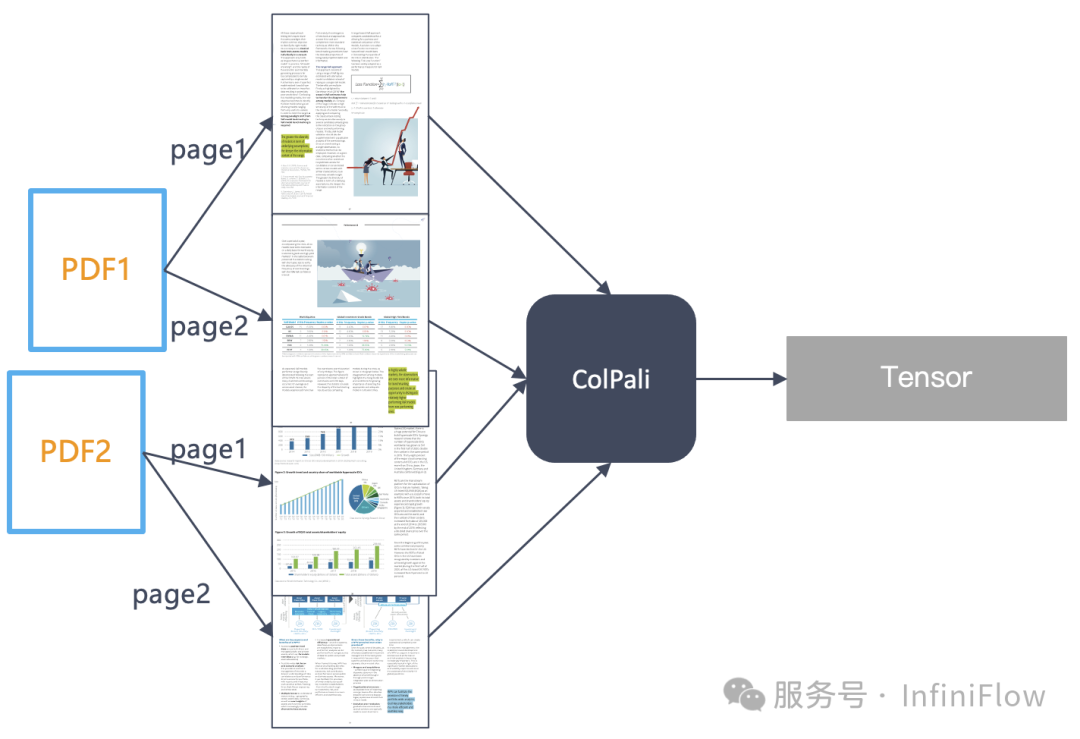
实现这一点,一种方案来自前文的介绍,也就是说我们采用模型来把多模态文档转成文本,然后再建立索引,提供检索。另一种就是根据 VLM 的进展,直接生成向量,规避掉复杂的 OCR 过程。对于后者,2024 年夏天出现的 ColPali【参考44】是开创性的工作,它把一张图片看作 1024个 Image Patch,分别生成 Embedding,因此一张图片就是用一个张量来表示:
而最终的排序,就通过张量来进行:
整个检索过程如下图所示:可以看到,它需要数据库不仅支持基于张量的重排序,还需要在向量检索阶段,支持多向量索引。这些结构,在我们的 Infinity 数据库,都已经做好了准备。

下图是多模态 RAG 召回的一个榜单,可以看到,基于张量的系列延迟交互模型,取得了大量领先的位置:
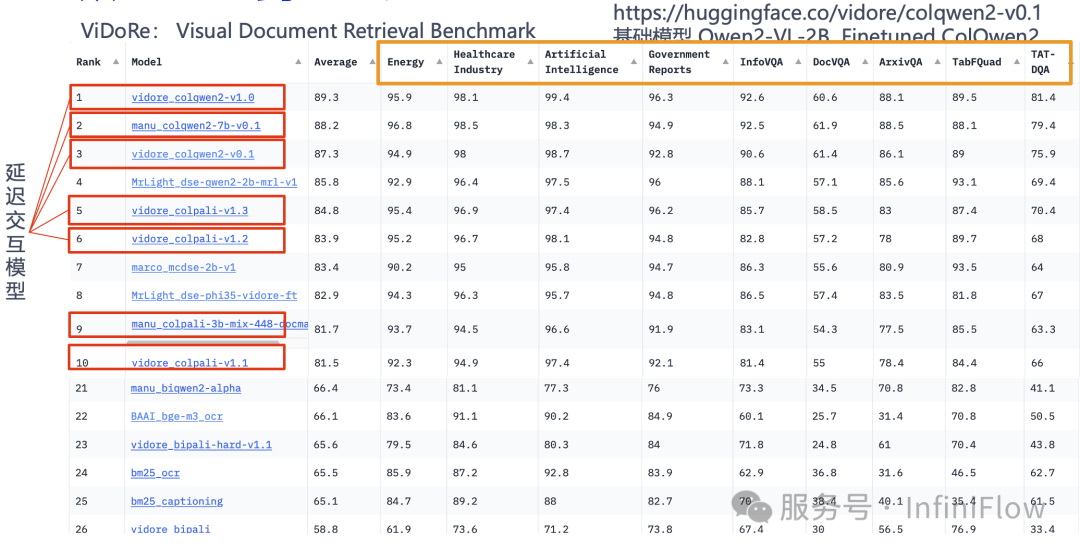
因此,张量不仅仅对于文本排序有着重要意义,对于多模态 RAG 也有广泛的使用场景。那么对于多模态 RAG 来说,究竟应该采用直接生成 Embedding,还是借助于广义 OCR 模型把文档先转为文字呢?在 ColPali 的原始论文中,作者推荐的做法是彻底丢掉 OCR,但是它对比的是采用 CNN 模型的 OCR,也就是在前文中我们提到的第一代模型。
当前两条路线的成功事实上都在依托于多模态模型本身能力的提升,因此我们的观点是,这 2 条路线将会并行很长时间,如果把 Embedding 当作是一种“通用”方案的话,那么基于 Encoder-Decoder 架构的 OCR 可以看作是一种“专用”方案,这是因为特定类别的数据当下还是需要训练特定的 Transformer 才可以解决好。RAG 始终都是把实践落地放在首要考虑因素,所以特定时期的特定任务,可能会专用优于通用,但最终是可以走向统一的。
2025 年,可以想象多模态 RAG 会快速崛起和演进,我们也将在合适的时机,把这些能力都添加到 RAGFlow。
以上从技术方面对 RAG 在 2024 年的发展主线做了总结和展望。可以看出,RAG 是个非常复杂的系统,尽管它并没有像 LLM 那样吸引海量的资金,但在真正使用中不仅不可或缺,还非常复杂。我们认为,RAG 这个名词定义非常好,它代表了一种架构模式,而非一个产品和场景应用。
从某种程度来说,RAG 就相当于过去的数据库,对外暴露的接口无比简单,内部却无比复杂,它不仅仅包含了数据库本身,还包含了各种小模型以及把它们串接起来的工具,从本质上来说,它就是过去的企业搜索引擎在大模型时代的进化,但它又大大超出了搜索引擎本身的范畴。在接下来的 2025 年,我们将持续进化 RAGFlow,欢迎大家继续关注 RAGFlow,始终致力于成为最好的 RAG 产品!
参考文献
PaddleOCR https://github.com/PaddlePaddle/PaddleOCR/ MinerU https://github.com/opendatalab/MinerU Docling https://github.com/DS4SD/docling Nougat https://github.com/facebookresearch/nougat GOT-OCR https://github.com/Ucas-HaoranWei/GOT-OCR2.0 StructEqTable https://github.com/UniModal4Reasoning/StructEqTable-Deploy Blended RAG: Improving RAG (Retriever-Augmented Generation) Accuracy with Semantic Search and Hybrid Query-Based Retrievers, https://arxiv.org/abs/2404.07220 , 2024 From local to global: A graph rag approach to query-focused summarization, https://arxiv.org/abs/2404.16130 2024 Recursive Abstractive Processing for Tree Organized Retrieval, https://arxiv.org/abs/2401.18059 2024 KAG https://github.com/OpenSPG/KAG Nebula GraphRAG https://www.nebula-graph.io/posts/graph-RAG Fast GraphRAG https://github.com/circlemind-ai/fast-graphrag LightRAG https://github.com/HKUDS/LightRAG LazyGraphRAG https://www.microsoft.com/en-us/research/blog/lazygraphrag-setting-a-new-standard-for-quality-and-cost/ HippoRAG https://arxiv.org/abs/2405.14831 Triplex https://huggingface.co/SciPhi/Triplex SiReRAG: Indexing Similar and Related Information for Multihop Reasoning https://arxiv.org/abs/2412.06206 Graph Neural Network Enhanced Retrieval for Question Answering of LLMs https://arxiv.org/abs/2406.06572 A Survey of Large Language Models for Graphs SIGKDD 2024 KG-Retriever: Efficient Knowledge Indexing for Retrieval-Augmented Large Language Models https://arxiv.org/abs/2412.05547 Mixture-of-PageRanks: Replacing Long-Context with Real-Time, Sparse GraphRAG https://arxiv.org/abs/2412.06078 HybridRAG: Integrating Knowledge Graphs and Vector Retrieval Augmented Generation for Efficient Information Extraction, Proceedings of the 5th ACM International Conference on AI in Finance, 2024 M2Doc-A Multi-Modal Fusion Approach for Document Layout Analysis, AAAI 2024 Late Chunking: Contextual Chunk Embeddings Using Long-Context Embedding Models https://arxiv.org/abs/2409.04701 dsRAG https://github.com/D-Star-AI/dsRAG/ Contextual Retrieval https://www.anthropic.com/news/contextual-retrieval A Comprehensive Survey of Retrieval-Augmented Generation (RAG: Evolution, Current Landscape and Future Directions https://arxiv.org/abs/2410.12837 Retrieval-Augmented Generation for Natural Language Processing: A Survey https://arxiv.org/abs/2407.13193 RAG的12个痛点和应对策略 https://towardsdatascience.com/12-rag-pain-points-and-proposed-solutions-43709939a28c Searching for Best Practices in Retrieval-Augmented Generation https://arxiv.org/abs/2407.01219 https://huggingface.co/Alibaba-NLP/gte-Qwen2-7B-instruct Colbert: Efficient and effective passage search via contextualized late interaction over bert, SIGIR 2020 Colbertv2: Effective and efficient retrieval via lightweight late interaction, arXiv:2112.01488, 2021. RAGatouille https://github.com/AnswerDotAI/RAGatouille Vespa https://github.com/vespa-engine/vespa JaColBERT https://huggingface.co/answerdotai/JaColBERTv2.5 Jina ColBERT v2 https://huggingface.co/jinaai/jina-colbert-v2 RAG七十二式:2024年度RAG清单 https://github.com/awesome-rag/awesome-rag Self RAG https://arxiv.org/abs/2310.11511 LangGraph https://github.com/langchain-ai/langgraph/ TCAF: a Multi-Agent Approach of Thought Chain for Retrieval Augmented Generation, SIGKDD 2024 RARE-Retrieval-Augmented Reasoning Enhancement for Large Language Models https://arxiv.org/abs/2412.02830 PaliGemma https://huggingface.co/spaces/big-vision/paligemma-hf ColPali: Efficient Document Retrieval with Vision Language Models, https://arxiv.org/abs/2407.01449 Meta-Chunking: Learning Efficient Text Segmentation via Logical Perception https://arxiv.org/abs/2410.12788
Mix-of-Granularity-Optimize the Chunking Granularity for Retrieval-Augmented Generation https://arxiv.org/abs/2406.00456
