个人观点,仅供参考。
部分内容用豆包润色了一下
今天咱来聊聊 TiDB 在 2024 年的那些事儿。这一年对于 TiDB 来说,真的是充满了惊喜与挑战,一路成长,一路突破。
一、发展
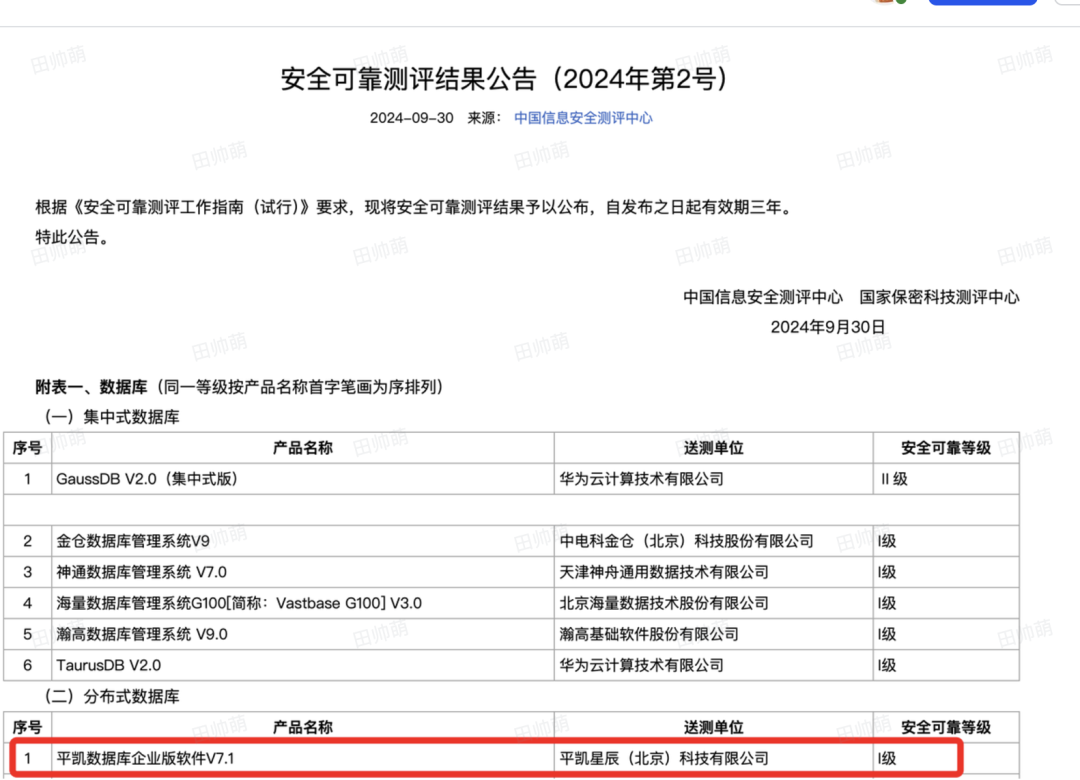
平凯数据库企业版软件 v7.1 (TiDB 企业版)成功通过信创,这可是一个重要的里程碑,为其在相关领域的应用打下了坚实基础。尤其是商业化的需求,会使TiDB在商业领域取得成功。1.2 serverless商业化
serverless 走向商业化,这无疑给用户带来了更多的选择和便利,让我们在使用 TiDB 时能够更加灵活地应对各种业务场景。
在数据库领域,TiDB 的每一次版本迭代都备受瞩目。
从 2024 年 1 月 25 日发布的 TiDB V7.6.0 到同年 12 月 19 日登场的 v8.5.0
这一年间 TiDB 在技术层面实现了诸多突破,TiDB 始终坚守稳定与性能双提升的理念,并且不断拓展在 SaaS、金融等关键场景的 “地盘”。
下面让我们从多个关键技术角度深入探究。
Active PD Follower:当集群规模变大时,Region 数量急剧增多,PD leader 处理心跳和调度任务的开销也较大,减轻PD leader节点压力。PD微服务:哪里性能是瓶颈,拆哪里,真正契合分布式数据库的架构理念,彻底告别PD性能瓶颈的困扰。并行攒批获取 TSO:TiDB 向 PD 发送 TSO RPC 请求时可以攒批处理,在不少场景下能减少查询等待时间,减少 PRC 请求事件。 #个人观点:进一步提升,只读事物,或者批量跑批等场景,能否不获取TSO,或者只获取一次TOS,目的减少TSO的获取。PD 优化提升 Region 心跳处理的性能,并支持集群中千万级 Regions 的规模。TiKV MVCC 内存引擎:TiKV MVCC 内存引擎简直是个宝藏功能。它能把最新写入的 MVCC 版本数据缓存到内存,这样在检索数据时就能快速跳过旧版本,直接找到最新数据。特别是在数据更新频繁或者历史版本保留时间长的情况下,数据扫描性能提升那是相当明显#进一步提升:让读写请求,单独缓存到内存,再实现内存刷盘到磁盘的高效操作,那肯定会让性能更上一层楼。计算下推:HashAgg(聚合算子)、Projection算子,下推到TiKV,提高性能减少TiDB OOM的发生。优化 KV 请求批处理策略:TiDB 根据最近请求的到达时间间隔动态批处理,特别适合高吞吐场景。降低 DELETE 操作的资源开销: 删除操作时候,忽略不必要的列。多租户:更加完善多租户的资源限制,TiDB 能够自动识别出运行超出预期的查询,并对该查询进行限流或取消处理。比如拉黑SQL,比如超时控制。Runaway Queries 提供了有效的手段来降低突发的 SQL 性能问题对系统产生的影响。实例级执行计划缓存:实例级执行计划缓存能够在内存中缓存更多执行计划,减少 SQL 编译时间,从而降低 SQL 整体运行时间,提升 OLTP 的性能和吞吐,同时更好地控制内存使用,提升数据库稳定性。全局索引:该功能扩展了 TiDB 分区表的使用场景,提升了分区表的性能,降低了分区表在一些查询场景的资源消耗。向量搜索:作为 AI 和大语言模型 (LLM) 的核心功能之一,向量搜索可用于检索增强生成 (Retrieval-Augmented Generation, RAG)、语义搜索、推荐系统等多种场景。进一步完善存算分离的架构,通过合并相同数据的读取操作,提升多并发下的数据扫描性能 新增 HashAgg 聚合计算模式,提升高 NDV 数据的聚合计算性能。优化 JOIN ON
条件中仅包含 JOIN KEY 等值条件时,半连接 (SEMI JOIN ) 及 LEFT OUTER SEMIJOIN 的执行性能。5、重大特性
这一年里 TiDB 还有好多重大特性。比如TiDB的proxy、并行排序,优化 KV 请求、攒批处理策略等等,每一个特性都凝聚着研发团队的心血。
6.MySQL兼容性
外键约束(从 v8.5.0 开始成为正式功能),这让我们在使用过程中更加方便。
在众多特性中,我个人特别看好和喜欢 Runaway Queries、TiKV MVCC 内存引擎和 PD 攒批这几个功能。
Runaway Queries 帮我们解决了很多突发的 SQL 性能问题,TiKV MVCC 内存引擎提升了数据检索效率,PD 攒批减少了 tidb grpc 获取。
为TiDB在金融领域,SaaS等场景打下坚实基础。
总之,2024 年的 TiDB 给我们带来了太多的惊喜和期待,相信在未来它还会不断进步,为我们的数据库应用带来更多的便利和创新。让我们一起期待 TiDB 的下一个精彩篇章吧!