




业务背景与挑战
企业人才库是企业人力资源管理的重要工具,它能够协助整合和分析人才信息,有助于企业在招聘、培养、管理和留住人才等方面实现高效运作。中高端人才是企业人才库非常重要的组成部分,中高端人才的挖掘在企业招聘中也面临着非常大的挑战:
资源稀缺性:中高端人才的稀缺性导致招聘难度和成本显著增加。 流动性低:这类人才通常不频繁更换工作,导致市场上的流动性较低。 被动求职态度:他们往往对求职持被动态度,更倾向于等待机会而非主动寻找。
为了应对这些挑战,企业需要采取多元化的招聘策略,从开放域挖掘更多关于候选人的有效信息,来源包括行业会议、专业社交平台、公开演讲等。这些信息能够帮助企业更精准地触达潜在的中高端人才,提升招聘效率和成功率,从而在激烈的人才市场竞争中获得优势。
基于这样的背景,我们希望通过图智能技术来整合多源复杂的开放域信息,识别中高端人才,并探索与人才建立联系的有效路径。
关于 HugeGraph-AI
HugeGraph-AI 是基于分布式图数据库 Apache HugeGraph 构建的图AI生态套件,旨在深入探索 Graph 与 AI 融合的技术与应用场景。主要由以下几个核心模块组成:
GraphRAG:基于图谱的检索增强生成,相比朴素 RAG,GraphRAG 能够通过图谱理解和处理文本中的复杂关系,增强具有高阶相关性的查询。 Text2GQL:自然语言转换为图查询语言(GQL),使用户能够用自然语言与图数据库进行交互,提高了数据查询的便捷性和直观性,降低图谱使用成本。 GNN Adapter:图神经网络(GNN)适配器,它允许各种图神经网络模型与 HugeGraph 数据库无缝集成,从而可以利用图神经网络的强大能力进行图数据分析和挖掘。
通过这些模块的协同工作,HugeGraph-AI 能够更高效地组织和管理海量图数据,实现数据价值的最大化。CVTE 数据挖掘团队深度参与了该项目的建设,打通 Graph Data -> AI -> Applications 的链路,目前在企业内部多个场景下均有应用,本文章主要描述的是开放域中高端人才挖掘场景下人才信息库的构建与应用。
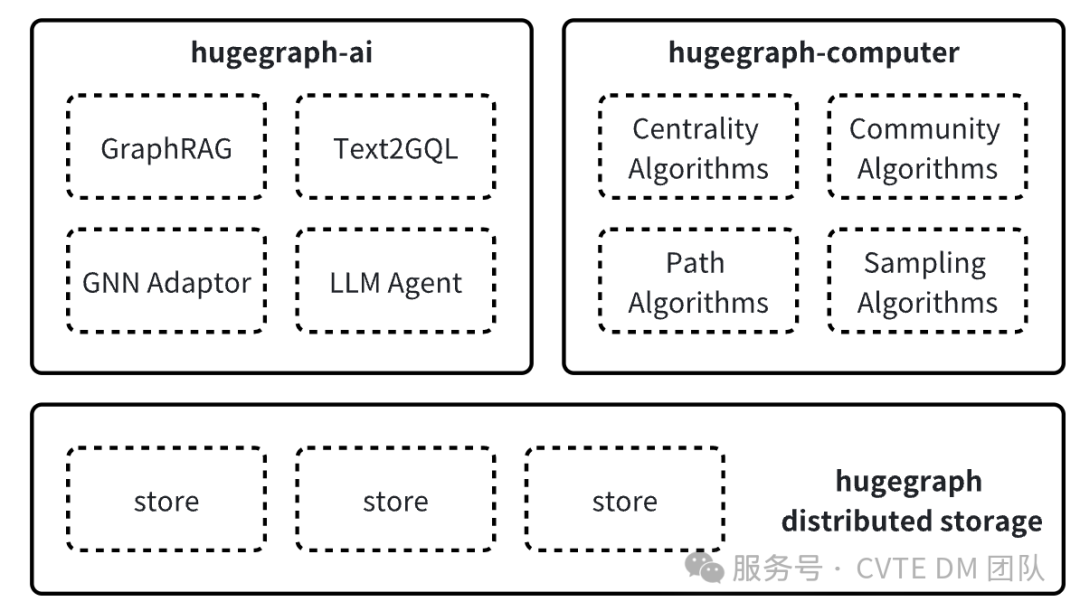
Apache HugeGraph 生态整体架构
业务场景
3.1. 人才库的构建
中高端人才库的数据来源包括学术论文、新闻(会议、论坛等)、技术文章、公开场合的发言演讲以及上市公司公开信息等,数据存在以下特点:
结构多样性:开放域数据包括非结构化数据,如文本、图像和视频,以及结构化数据,如表格和数据库记录。这种多样性要求采用灵活的处理方法来适应不同数据类型。 数据量大:开放域数据覆盖广泛的来源,包括互联网、公共数据库和开放数据集,因此数据量通常非常庞大。 动态实时性:由于数据源的持续更新,开放域数据也在不断变化,这要求数据收集和处理流程能够适应实时或近实时的数据流。 噪声问题:开放域数据中存在错误、过时或不一致的信息。
为了解决这些问题,人才库的构建选择基于 HugeGraph-AI 中 GraphRAG 的方案,同时结合了 GNN Adapter、Text2GQL 等模块解决相似推荐、关系检索等特定场景的问题,并且应用了 HugeGraph-Computer 的图中心性、社区发现等图算法对图关键信息进行挖掘,以增强结果的完整性和准确性。人才库构建整体流程如下:
数据爬取与预处理:从开放域中爬取相关数据,对文本进行切分,将相似的文本块合并。 关键实体关系抽取:在合并的文本块中,进行关键实体和关系的抽取,以构建人才库的基础信息。 子图之间的实体融合:对不同子图中的实体进行融合,确保信息的一致性和完整性,消除冗余。 摘要生成:对每个 Chunk 或子图生成摘要,以提取关键信息并简化数据结构,便于后续查询和分析。 社区发现与聚类: 采用 HugeGraph-Computer 中提供的社区发现算法对图进行社区聚类,将相似的实体和关系聚集在一起,形成更具结构化的信息块。 对每个社区进行摘要,以便于快速理解社区内的主要内容。 关键节点识别:通过图中心性算法识别图中的关键节点,增加这些节点的权重,以突出其在人才库中的重要性。在召回过程中,重点关注高权重节点,以提高检索的准确性和效率。
通过以上步骤,构建的开放域人才库将能够有效整合和管理多源数据,为企业的人才管理和决策提供强有力的支持。
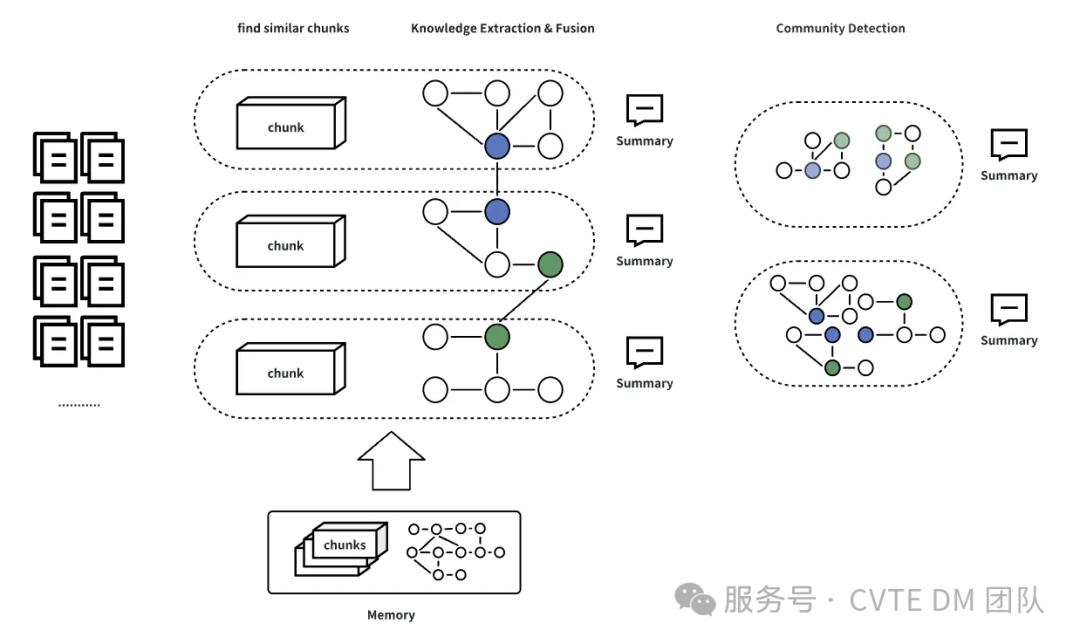
GraphRAG 图谱构建流程
3.2. 人才库的应用
1)关系类检索
用于查询特定实体之间的关系,例如有如下问题:
Pitt and Leonardo met while working at Microsoft?
首先识别问句中的关键实体(Pitt、Leonardo)和关系(work)以及相关组织信息(Microsoft),然后进行实体之间的路径分析,检索实体间最短路径,以及与这些实体相关的子图和对应的文本块(Chunks)信息,将这些信息结合即可推理出实体之间的关系信息。
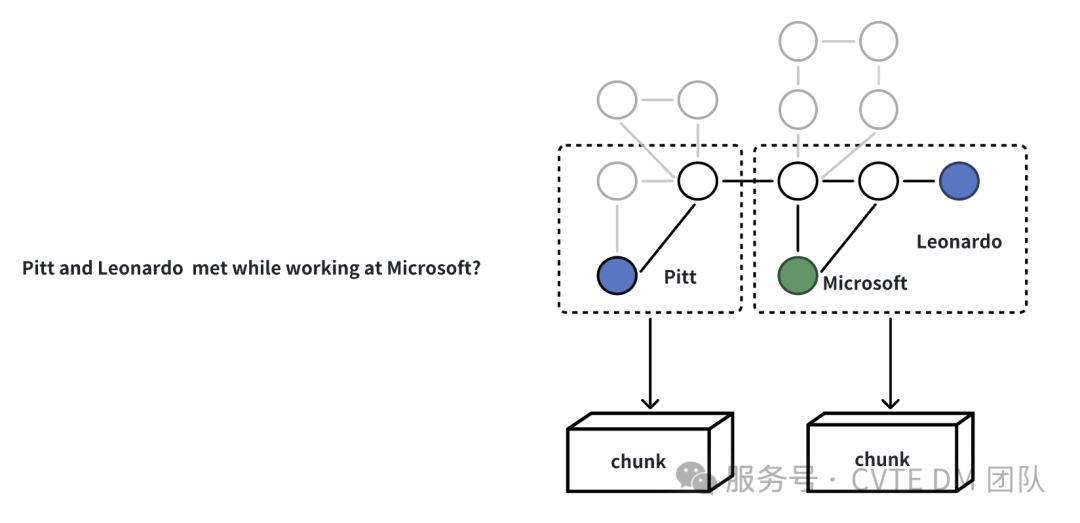
关系检索
2)相似候选人推荐
利用图神经网络(GNN)技术,对候选人节点的邻域特征进行聚合,这些特征包括技能、教育背景、工作经验、职位信息以及发表的学术论文等。通过计算这些特征的相似度,可以有效地识别出相似候选人或者与特定岗位需求相匹配的候选人。
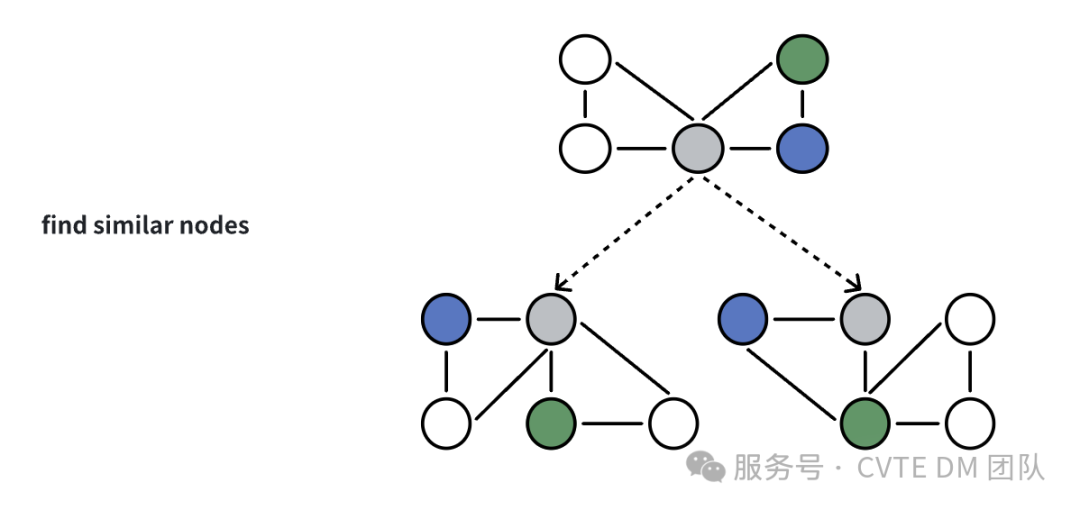
基于 GNN的 相似节点召回
3)候选人&公司介绍
关于候选人&公司介绍相关的问题,思路是尽可能多地检索并召回和目标相关的信息,因此采用混合召回策略,以最大化信息召回的广度和深度。
一方面通过结合向量和 BM25 的方法检索到相似的 Chunk,再通过 Chunk 对应的子图,以及子图之间的关联关系,进一步关联到相关 Chunk。 另一方面通过对问题进行实体识别,并将实体在图中检索,找到对应的节点,基于该节点进行 K-neighbors 的图检索,增强信息的完整性。 此外,基于 Global Search 的思路,对问题进行摘要总结,在 GraphRAG 构建的 Summary 中进行检索和召回,可以得到全局视角的答案。
最终,通过 LLM 整合召回结果,实现对检索目标全方面的介绍。
4)Text2GQL 图检索
Text2GQL 用于将用户的自然语言查询转换为可执行的图查询语言(GQL)。这一过程主要涉及以下几个关键步骤:
获取相关 Schema:识别图数据库 Schema 中与用户问题相关的元素,减少无关信息的干扰,降低输入复杂性。 获取历史相似查询对:通过结合用户的自然语言输入和相关的 Schema 片段,检索相似的历史查询,以及对应的 GQL 信息,用于指导大模型的生成。 GQL 生成:将自然语言、相关 Schema 和历史查询对作为 Prompt 输入给大语言模型,生成可执行的图查询语句。 图数据库执行和返回:生成的图查询语句将被发送到 HugeGraph 执行,查询得到的结果将返回给用户,完成从自然语言到图数据库查询的全过程。 模型微调:自然语言输入、相关的 Schema 和生成的图查询语句也可以作为训练数据,用于微调大语言模型,以提高其在特定领域的准确率。
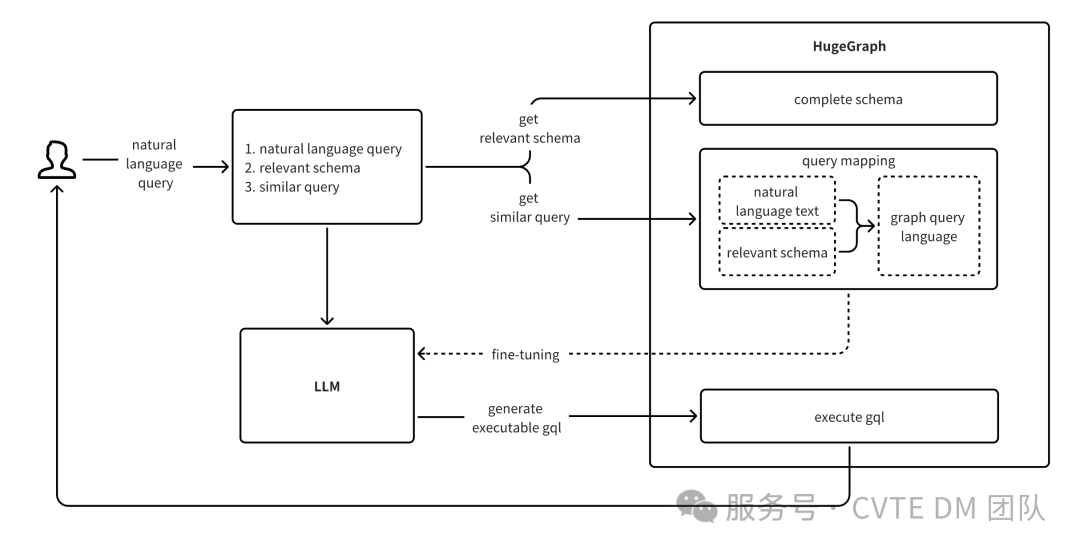
Text2SQL
在人才库的场景下,Text2GQL 可以应用于日常的人才库关系检索,降低路径检索的使用成本。例如有如下案例:如何通过现有关系网络联系到特定候选人,需要找到可行的联系路径。A是目标候选人,A与B是在同一家公司的同事关系,B与C共同发表过论文,C 当前所在公司的上级是 D,若人才库中已有 D 的联系方式,则可以构建出一条联系路径 D -> C -> B -> A。对于用户类似“如何联系到A”的问题,通过上述方案,会生成一条如下可执行的 Gremlin 查询语句 ,最终返回目标实体给用户。
g.V().has('name', 'A') // 从名为A的顶点开始
.repeat(out()) // 沿着出边进行遍历
.times(5) // 限制为5跳
.has('is_contactable', true) // 查找属性is_contactable为true的顶点
4. 总结
HugeGraph-AI 提供了多种灵活、低成本、高效的知识图谱构建和应用方案,为图数据库增加了更多可落地的可能。CVTE 数据挖掘团队在参与项目建设的同时,也在积极探索 HugeGraph-AI 更多场景下的企业级应用,使其在降本增效、产品创新等方面为企业提供更多的价值。
HugeGraph-AI 目前处于高速发展阶段,从第一版发布至今不到一年的时间已吸引 20+ 来自不同企业、高校的贡献者提交了 130+ Pull Requests,涉及 GraphRAG、Text2GQL、GNN 等多方面的技术。另外,Apache HugeGraph 和 HugeGraph-AI 近期均发布了 1.5.0 版本,各方面都有了很大的提升,欢迎 Star 关注 https://github.com/apache/incubator-hugegraph-ai。
欢迎加入我们!!
WENEEDYOU
📔项目主仓库地址:
https://github.com/apache/incubator-hugegraph-ai
https://github.com/apache/incubator-hugegraph
📬提交问题和建议:
https://github.com/apache/hugegraph-ai/issues
🍀贡献代码:
https://github.com/apache/hugegraph-ai/pulls
📧订阅社区开发邮件列表:
dev@hugegraph.apache.org
请点击文末“阅读原文”访问 hugegraph-ai 仓库,点击下方卡片可关注 hugegraph:
