




一、问题现象
部署环境:openGauss资源池化-1主2备
执行步骤: (1)cm_ctl stop -n 2
(2)cm_ctl start -n 2
问题发现: 13:55:41 stop 节点2数据库,发现13:55:19 节点3数据库进程退出,由于是自动化流水线运行测试套,环境中不会手动执行stop -n 3,因此为什么节点3数据库进程退出?
二、问题分析
2.1 初步猜测原因
首先查看节点3数据库日志pg_log中,发现日志"2024-12-10 13:55:19.282 [BACKEND] LOG: received fast shutdown request",根据内核代码分析能打印该日志的情况如下所示:
情况1:数据库内部线程发出的退出信号
情况2:测试用例脚本中存在cm_ctl stop -n 3
情况3:人为手动执行cm_ctl stop -n 3
情况4:cm仲裁将节点3 踢出
根据测试人员描述是在夜晚执行自动化测试套,不会出现原因2和原因3。
2.2 分析情况1
首先查看节点3数据库日志pg_log中是否有报错,日志如下:
2024-12-10 13:54:49.929 [DMS] LOG: [SS reform] Reform success, this is a standby:2 confirming new primary:0, list_stable:5, confirm ntries=1.
2024-12-10 13:54:49.929 [DMS] LOG: [SS reform] new cluster node bitmap: 5
2024-12-10 13:54:49.929 [DMS] LOG: [SS reform] Reform success, instance:2 is running. /* instance2 就是节点3,数据库中节点管理从0开始,CM中节点管理从1开始*/
2024-12-10 13:54:49.930 [DMS] LOG: [SS reform] reform done: pmState=4, SSClusterState=0, demotion=0-0, rec=0, dmsStatus=3.
2024-12-10 13:54:49.939 [BACKEND] LOG: gaussdb: fsync file “/data/ss_env/install/data/dn/gaussdb.state.temp” success
2024-12-10 13:54:49.939 [BACKEND] LOG: update gaussdb state file: db state(NORMAL_STATE), server mode(Standby)
2024-12-10 13:55:19.282 [BACKEND] LOG: received fast shutdown request
2024-12-10 13:55:19.282 [BACKEND] LOG: send to startup shutdown request
分析日志可知,在收到"received fast shutdown request" 之前数据库状态已经normal,并且在normal和收到 fast shutdown request 信息之间没有任何报错,说明节点3不是数据库内核线程发送 "SIGTERM/SIGINT"信号到PM线程(见内核代码pmdie函数),因此排除情况1。
2.3 分析情况4
(1) 首先根据代码倒推逻辑线
received fast shutdown request --> 执行gs_ctl stop dn 命令 --> 执行dms_control.sh中stop或者clean命令 --> cm调用dms_control.sh -clean或者dms_control.sh -stop --> cm检测到节点3异常
从逻辑线可以看到根因就是cm检测到节点3异常,那么检测出来的异常情况就是我们要找的原因。
(2) 通过日志验证逻辑线
节点3的pg_log日志:
2024-12-10 13:55:19.282 [BACKEND] LOG: received fast shutdown request
节点3的bin/gs_ctl日志:
[2024-12-10 13:55:19.282][3118304][][gs_ctl]: gs_ctl stopped, datadir is /data/ss_env/install/data/dn
节点3的dms_control.log日志:
2024-12-10 13:55:19 stop /data/ss_env/install/app/bin/gaussdb...
2024-12-10 13:55:27 check /data/ss_env/install/app/bin/gaussdb in /data/ss_env/install/data/dn fail.
2024-12-10 13:55:28 /data/ss_env/install/app/bin/gaussdb stopped in dir /data/ss_env/install/data/dn...
节点3的cm_agent日志:
2024-12-10 13:55:18.644 tid=云山欲雪 ProcessCmsMsg LOG: [CUS_RES] nodeId=3, cmInstId=6003, resInstId=6003, status=1, isWork=0;
2024-12-10 13:55:18.698 tid=云山欲雪 ProcessCmsMsg LOG: [UnregOneResInst]: cmd:(/data/ss_env/install/app/bin/dss_contrl.sh -unreg 2 /data/ss_env/install/dss_home /data/ss_env/install/data/dn) is executing.
2024-12-10 13:55:28.331 tid=云山欲雪 StartAndStop LOG: CleanOneResInst: clean inst cmd(/data/ss_env/install/app/bin/dms_contrl.sh -clean 6003 /data/ss_env/install/data/dn) success@重点@:发现了cm agent 调用了 dms_control.sh -clean,然后dms_control.sh脚本中调用了gs_ctl stop,因此停掉了节点3数据库。
找到主server对应的节点在节点1,如何确定主server:
在每个节点的cm_server日志中过滤日志信息"GetShareDiskLockMain",得到三个节点server日志如下
节点1(13:55:31之后是主server):
2024-12-10 13:55:31.174 tid=云山欲雪 GetShareDiskLockMain LOG: NotifyDdbRole: current ddbRole is 1, last ddbRole is 2.
2024-12-10 13:55:31.174 tid=云山欲雪 GetShareDiskLockMain DEBUG1: NotifyDdbRole: current ddbRole is 1.节点2(13:54:57之前是主server,之后不是主server,节点2在13:54:41开始stop节点2,13:54:53数据库进程退掉):
2024-12-10 13:54:57.793 tid=云山欲雪 GetShareDiskLockMain DEBUG1: NotifyDdbRole: current ddbRole is 1.
2024-12-10 13:55:11.885 tid=云山欲雪 GetShareDiskLockMain LOG: Starting get share disk lock thread.
2024-12-10 13:55:11.888 tid=云山欲雪 GetShareDiskLockMain DEBUG1: CmNormalArbitrate: cm_lock_disklock result -2. lockTime 0, lockNotRefreshTimes 0, lockFailBeginTime 1047131
2024-12-10 13:55:11.888 tid=云山欲雪 GetShareDiskLockMain LOG: NotifyDdbRole: current ddbRole is 2, last ddbRole is 0.
2024-12-10 13:55:11.888 tid=云山欲雪 GetShareDiskLockMain DEBUG1: NotifyDdbRole: current ddbRole is 2.节点3(一直都不是主server):
2024-12-10 13:55:18.234 tid=云山欲雪 GetShareDiskLockMain DEBUG1: NotifyDdbRole: current ddbRole is 2.
2024-12-10 13:55:19.238 tid=云山欲雪 GetShareDiskLockMain DEBUG1: CmNormalArbitrate: cm_lock_disklock result -2. lockTime 17, lockNotRefreshTimes 0, lockFailBeginTime 1186155
2024-12-10 13:55:19.238 tid=云山欲雪 GetShareDiskLockMain DEBUG1: NotifyDdbRole: current ddbRole is 2.
@结论1@:ddbRole是1代表是主,ddbRole是2代表是备,因此在stop节点2之前,节点2是cm的主server,stop节点2之后,节点1是cm的主server。
2.4 分析主server的仲裁情况
首先查看节点2 主server在被执行stop前后的情况:
2024-12-10 13:54:44.866 tid=云山欲雪 MaxClusterAb LOG: Network timeout:6
2024-12-10 13:54:44.866 tid=云山欲雪 MaxClusterAb LOG: Network base_time:2024-12-10 13:54:44
2024-12-10 13:54:44.866 tid=云山欲雪 MaxClusterAb LOG: [RHB] hb infos: |1970-01-01 08:00:00|2024-12-10 13:55:06|2024-12-10 13:55:09|
2024-12-10 13:54:44.866 tid=云山欲雪 MaxClusterAb LOG: [RHB] hb infos: |2024-12-10 13:54:39|1970-01-01 08:00:00|2024-12-10 13:54:39|
2024-12-10 13:54:44.866 tid=云山欲雪 MaxClusterAb LOG: [RHB] hb infos: |2024-12-10 13:54:47|2024-12-10 13:54:42|1970-01-01 08:00:00|2024-12-10 13:54:44.866 tid=云山欲雪 MaxClusterAb LOG: [FindMaxNodeCluster] the max node cluster: version is 36, total node num is 3, and node is 1, 2, 3, .
-----------------------------------------分界线:节点2数据库正在被stop-----------------------------------
2024-12-10 13:54:45.871 tid=云山欲雪 MaxClusterAb LOG: Network timeout:6
2024-12-10 13:54:45.871 tid=云山欲雪 MaxClusterAb LOG: Network base_time:2024-12-10 13:54:45
2024-12-10 13:54:45.871 tid=云山欲雪 MaxClusterAb LOG: [RHB] hb infos: |1970-01-01 08:00:00|2024-12-10 13:55:06|2024-12-10 13:55:10|
2024-12-10 13:54:45.871 tid=云山欲雪 MaxClusterAb LOG: [RHB] hb infos: |2024-12-10 13:54:39|1970-01-01 08:00:00|2024-12-10 13:54:39|
2024-12-10 13:54:45.871 tid=云山欲雪 MaxClusterAb LOG: [RHB] hb infos: |2024-12-10 13:54:48|2024-12-10 13:54:42|1970-01-01 08:00:00|2024-12-10 13:54:45.871 tid=云山欲雪 MaxClusterAb LOG: [FindMaxNodeCluster] the max node cluster: version is 36, total node num is 2, and node is 1, 3, .
@重点发现哈!!!@:在节点2的13:54:44时刻(节点2在13:55:41时刻测试用例执行stop节点2)发现,节点1时间:2024-12-10 13:55:06;节点2时间:2024-12-10 13:54:39;节点3时间:2024-12-10 13:54:42,发现在节点2数据库进程退掉之前,节点1时间和(节点2、节点3)的时间超过6s,节点2和节点3时间是一致的。得到@结论2@:节点1时间早于节点2和节点3的时间23s-28s左右,节点3时间早于节点2时间3-4s左右。
资源池化cm检测timeout代码如下:
static MaxClusterResStatus GetNodesConnStatByRhb(int idx1, int idx2, int timeout)
{
...... /* 其它代码 */
bool RhbTimeOutDirect = IsRhbTimeout(g_curRhbStat.hbs[idx1][idx2], g_curRhbStat.baseTime, timeout);
bool RhbTimeOutForward = IsRhbTimeout(g_curRhbStat.hbs[idx2][idx1], g_curRhbStat.baseTime, timeout);
write_runlog(DEBUG1, "云山欲雪 rhb timeout check result start node: %d, end node: %d, result: %d.\n",
idx1, idx2, RhbTimeOutDirect);
write_runlog(DEBUG1, "云山欲雪 rhb timeout check result start node: %d, end node: %d, result: %d.\n",
idx2, idx1, RhbTimeOutForward);
if (RhbTimeOutDirect && RhbTimeOutForward) {
return MAX_CLUSTER_STATUS_UNAVAIL;
}
return MAX_CLUSTER_STATUS_AVAIL;
}@插播代码解说@:RhbTimeOutDirect和RhbTimeOutForward是两个节点的正反向时间timeout检查返回的结果,如果超过6s,则值为true,反之为false。在2024年9月从"RhbTimeOutDirect || RhbTimeOutForward "修改为"RhbTimeOutDirect && RhbTimeOutForward",开源社区pr为https://gitee.com/opengauss/CM/pulls/254,修改的含义是指"两个节点之间只要单边满足超时限制则认为最大集群不可用"修改为"两个节点之间双边满足超时限制才认为最大集群不可用",即修改之后,单边超时不会影响最大集群状态。
所以在节点2停之前,即使检查到节点1时间与节点2和节点3不一致,但cm认为此情况正常,因为base_time是基于cm的主server节点2来判断超时,节点2和节点3时间一直是一致的,一直满足双边时间检测小于6s,而节点2和节点1虽然时间超过6s,但满足了单边检查(节点1给节点2发心跳,节点1记录自身时间t_12;节点2给节点1发心跳,节点2记录自身时间t_21,自身时间就是base_time时间;t_12与base_time时间比较相差超过6s,而t_21与base_time时间比较相差不会超过6s,因此节点1和节点2之间满足单边时间不超时),即@论点1@:在节点2被执行stop之前,即使日志中打印了timeout日志,但是超时仲裁机制被修改为单边检测之后,不会认为最大集群有问题,因此没有踢出时间不一致的节点1。
这一论点在节点2被完全stop之前打印日志"2024-12-10 13:54:44.866 tid=2736714 MaxClusterAb LOG: [FindMaxNodeCluster] the max node cluster: version is 36, total node num is 3, and node is 1, 2, 3, ."中得到完美验证,该日志表明三个节点都在最大可用集群中。
2.5 分析节点3被踢出原因
根据结论1,节点3接受到shutdown信号时,节点1是cm的主server;再根据结论2,结合节点3接受到shutdown信号的时间13:55:19可推出当时节点1对应的时间是13:55:41左右,因此查看节点1在13:55:41时刻的cm_server日志如下:
2024-12-10 13:55:41.123 tid=云山欲雪 MaxClusterAb LOG: Network timeout:6
2024-12-10 13:55:41.123 tid=云山欲雪 MaxClusterAb LOG: Network base_time:2024-12-10 13:55:41
2024-12-10 13:55:41.123 tid=云山欲雪 MaxClusterAb LOG: [RHB] hb infos: |1970-01-01 08:00:00|2024-12-10 13:55:38|2024-12-10 13:55:38|
2024-12-10 13:55:41.123 tid=云山欲雪 MaxClusterAb LOG: [RHB] hb infos: |2024-12-10 13:55:13|1970-01-01 08:00:00|2024-12-10 13:55:13|
2024-12-10 13:55:41.123 tid=云山欲雪 MaxClusterAb LOG: [RHB] hb infos: |2024-12-10 13:55:17|2024-12-10 13:55:17|1970-01-01 08:00:00|
2024-12-10 13:55:41.123 tid=云山欲雪 MaxClusterAb LOG: [FindMaxNodeCluster] the max node cluster: version is 37, total node num is 2, and node is 1, 2, .
日志可知:主server是节点1,base_time是基于节点1的时间,由于节点2和节点3之间互相发送的心跳时间t_23和t_32是基于自身时间,而根据结论2可推出: 节点3被仲裁踢出的时候,t_23和t_32 都与 base_time相差 23-28s左右,满足双边都超时的条件,函数GetNodesConnStatByRhb返回MAX_CLUSTER_STATUS_UNAVAIL。从上面节点2的cm_server日志中可知实际t_23=13:55:13和t_32=2024-12-10 13:55:17,与节点1的base_time时间确实相差23-28s左右,此时最大可用集群中的节点是"节点1和节点2",因此可得@论点2@:由于节点2再次被拉起,cm的主server利用节点心跳时间差值计算集群最大连通图,将节点3踢出。
论证论点2,查看节点2的cm_agent日志如下图:
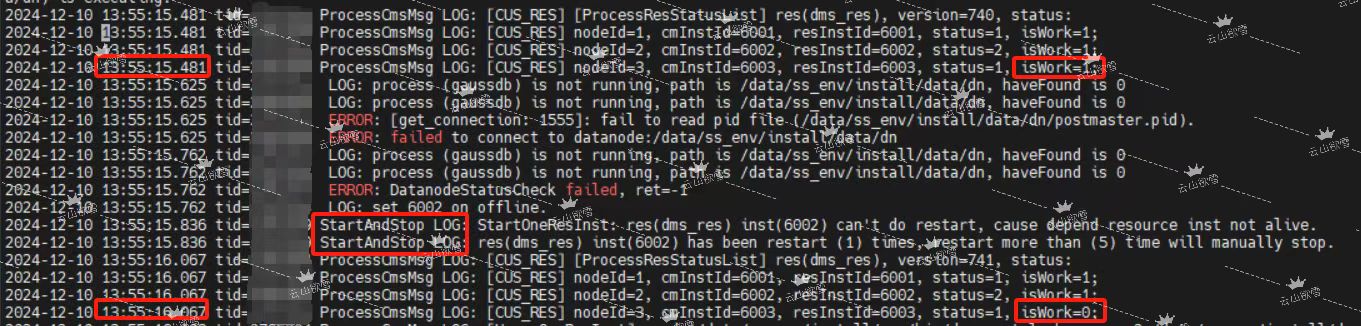
先忽略error信息,从日志可知此时节点2正在被拉起,只是数据库没拉起成功。而节点2被拉起的时间(13:55:14)和节点3被踢出的时间(13:55:19)基本一致(节点2比节点3晚3-4s左右,所以时间是对齐的)。
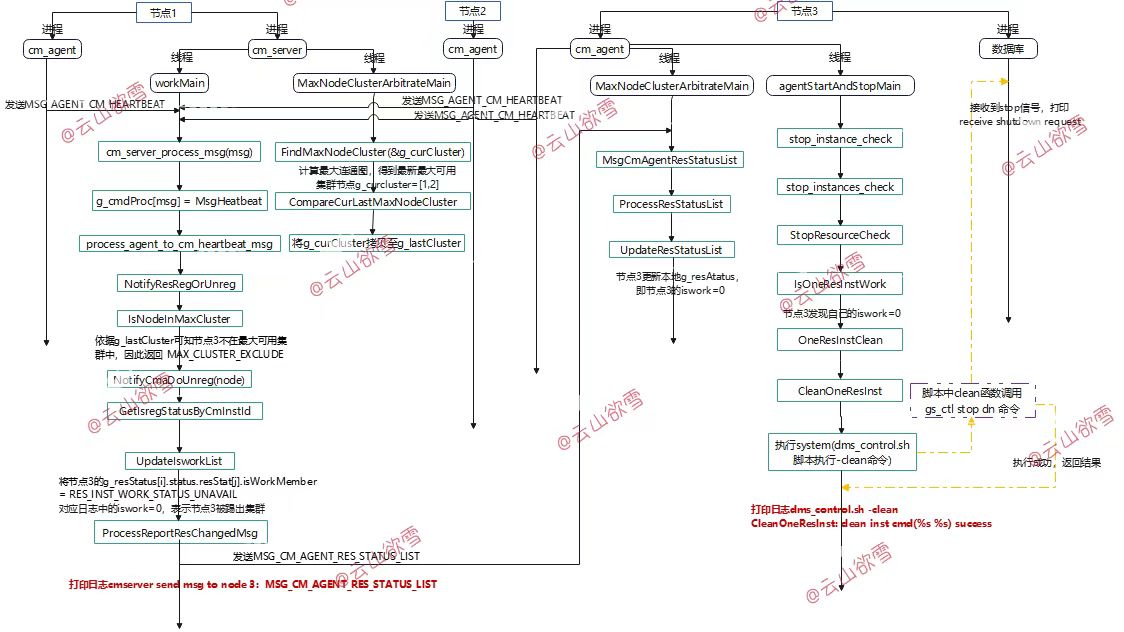
如下图分析代码可知,cm主server调用FindMaxNodeCluster函数,FindMaxNodeCluster中调用"CheckPoint2PointConn->GetNodesConnStatByRhb"函数判断了节点间心跳连接时间,由于节点2和节点3的心跳时间t_23和t_32基于节点1的base_time满足双边都超时的条件,函数GetNodesConnStatByRhb返回MAX_CLUSTER_STATUS_UNAVAIL,因此FindMaxNodeCluster函数中的算法计算出此时最大可用集群是[1,2,]。workMain线程调用NotifyResRegOrUnreg函数,函数中判断了每个节点是否在最大可用集群中,发现节点3不在,因此cm主server节点2先更新本地存储的节点3的iswork=0,然后发送MSG_CM_AGENT_RES_STATUS_LIST给节点3,节点3的MaxNodeClusterArbitrateMain线程收到后更新本地节点3的iswork=0,然后节点3的agentStartAndStopMain线程循环check到自己iswork=0,因此调用CleanOneResInst函数执行dms_contrl.sh -clean命令,脚本中clean函数又调用了gs_ctl stop dn命令,因此节点3数据库进程退出,节点3被踢出集群。与章节2.3的日志逻辑日志时间线一致。
@万众瞩目@: cm主server节点2仲裁kick out节点3的完整日志如下:
---------------------------------节点2加入集群---------------------------------
2024-12-10 13:55:41.123 tid=云山欲雪 MaxClusterAb LOG: [KeyEvent: KEY_EVENT_RES_ARBITRATE] [Instance: 0] [Details: node(2) join in cluster.]
---------------------------------找到最大可用集群[1,2,]------------------------
2024-12-10 13:55:41.123 tid=云山欲雪 MaxClusterAb LOG: Network timeout:6
2024-12-10 13:55:41.123 tid=云山欲雪 MaxClusterAb LOG: Network base_time:2024-12-10 13:55:41
2024-12-10 13:55:41.123 tid=云山欲雪 MaxClusterAb LOG: [RHB] hb infos: |1970-01-01 08:00:00|2024-12-10 13:55:38|2024-12-10 13:55:38|
2024-12-10 13:55:41.123 tid=云山欲雪 MaxClusterAb LOG: [RHB] hb infos: |2024-12-10 13:55:13|1970-01-01 08:00:00|2024-12-10 13:55:13|
2024-12-10 13:55:41.123 tid=云山欲雪 MaxClusterAb LOG: [RHB] hb infos: |2024-12-10 13:55:17|2024-12-10 13:55:17|1970-01-01 08:00:00|
2024-12-10 13:55:41.123 tid=云山欲雪 MaxClusterAb LOG: [FindMaxNodeCluster] the max node cluster: version is 37, total node num is 2, and node is 1, 2, .--------------------------发送MSG_CM_AGENT_RES_STATUS_LIST给节点3----------------------
2024-12-10 13:55:41.196 tid=云山欲雪 IO_WORKER LOG: cmserver send msg to node 3, msgtype: MSG_CM_AGENT_RES_STATUS_LIST
--------------------------节点3完全踢出集群-------------------------------------------------------
2024-12-10 13:55:42.129 tid=云山欲雪 MaxClusterAb LOG: [KeyEvent: KEY_EVENT_RES_ARBITRATE] [Instance: 0] [Details: node(3) kick out.]
2.6 思考
在无法修改仲裁机制的情况下,该问题属于正常仲裁踢出节点3,如果需要规避该问题,则在测试脚本运行前或者客户日常维护时,强制检查所有节点时间不一致问题,属于数据库运维范畴工作。
作者:云山欲雪(snow_coming_in_clouds)
