




Orchestrator 是一款成熟的 MySQL 高可用中间件。采用 Go 语言编写,支持拓扑发现、集群重塑、拓扑恢复等功能。
主要功能
拓扑发现:Orchestrator 主动搜寻并记录 MySQL 节点的主从配置、复制状态等基础信息并进行拓扑映射。即使发生故障,它依然可以提供出色的可视化拓扑图。
集群重塑:Orchestrator 了解复制规则。它能准确识别复制类型:Binlog 位点复制、GTID 复制、伪 GTID 复制、Binlog Server。Orchestrator 还提供了复制检查功能,保证了副本的移动安全可靠。
拓扑恢复:Orchestrator 定义了 30 种故障模型,根据集群拓扑信息可精准识别故障类型。针对不同的故障类型还提供了 15 种恢复执行计划,大大降低了恢复失败的概率。
优势
相较于 MHA 它有以下优势:
可视化:Orchestrator 提供了整洁的可视化界面
拓扑发现:拓扑自动发现的能力,大大简化了集群管理
高可用:Orchestrator 自身基于 Raft 一致性算法实现高可用
安全:Orchestrator 强大的审计功能,让我们的每一步操作都有迹可循
精准:多达 30 种故障模型,大大降低了误切的可能性
高效:Orchestrator 为我们提供了 200+ 的 api 来帮助我们管理 MySQL
快速:3s 发现故障 7s 完成切换
高可用
Orchestrator 高可用的实现主要分为两步:
故障检测
函数入口:ContinuousDiscovery --> CheckAndRecover --> GetReplicationAnalysis
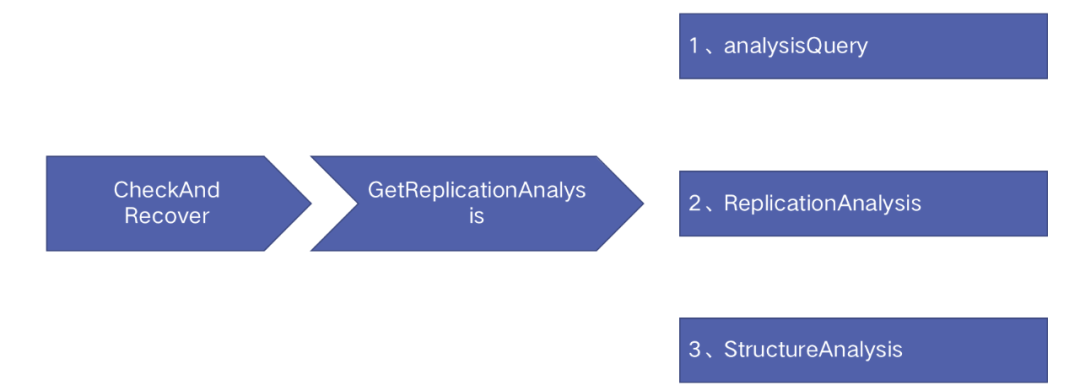
故障检测的工作周期为 1 秒,它的主要工作如上图所示:
集群拓扑信息获取:通过 select 语句从后端获取 Binlog 位点、探活是否有效、从库复制情况等集群拓扑信息;
定义故障类型:通过获取到的集群拓扑信息判定故障类型;
探测潜在故障:除了判定故障类型外还会探测集群可能存在的潜在故障。Orchestrator 一共定义了 err1236 在内的 15 种潜在故障类型;
故障恢复
函数入口:ContinuousDiscovery --> CheckAndRecover --> executeCheckAndRecoverFunction
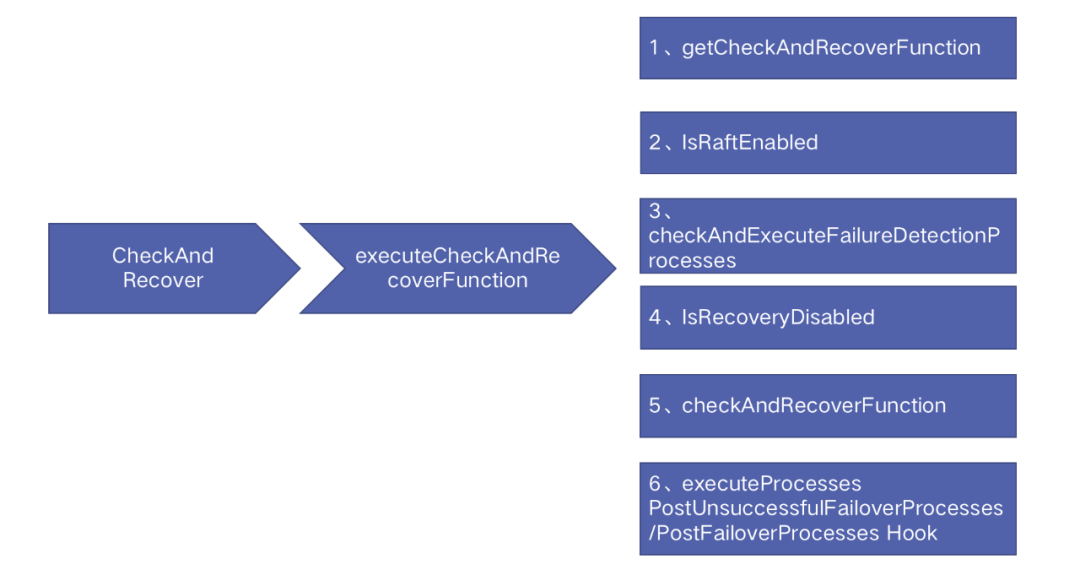
故障恢复的工作周期也是 1 秒,它的主要工作如下:
获取恢复执行计划:Orchestrator 一共定义了 15 种执行计划,根据不同的故障类型它会选择不同的执行计划;
leader 节点检查:Orchestrator 集群只有 leader 节点有权限执行恢复操作;
故障注册:对于每一个故障只有注册成功才能执行后续的恢复操作;
全局恢复设置检查:检查是否开启了全局恢复禁止,如果有则中断恢复;
执行步骤 1 中获取的执行计划;
调用 PostUnsuccessfulFailoverProcesses/PostFailoverProcesses 钩子 ;
执行计划
Orchestrator 定义了 15 种执行计划,本次详解故障类型 DeadMaster
故障定义:主节点无法访问,且所有从节点的复制都处于失败状态;
判断标准:1、主节点访问失败;2、从节点访问正常,且所有从节点复制都失败;
DeadMaster 的执行计划为:checkAndRecoverDeadMaster
函数入口:CheckAndRecover --> executeCheckAndRecoverFunction --> checkAndRecoverDeadMaster

详细流程如上图:
注册本次故障恢复;
调用 PreFailoverProcesses Hook ;
获取恢复类型:GTID、伪 GTID、Binlog 位点;
集群重塑:选主、集群拓扑调整;
给故障节点打上维护标签;
切换前地理位置检测:如果我们做了不允许跨 DC 故障转移的设置,本次恢复将中断;
检查新主的复制延时是否超过阀值,如果超过将中断本次恢复;
解析本次恢复,为本次恢复打上成功或者失败的标签;
新主执行:stop slave; 和 reset slave all;
新主执行:set read only false;
尝试旧主执行:set read only true;
在新主执行分离操作:在新主上利用 change master to master_host="//host" ... 命令给 master_host 加上注释标签,防止旧主复活后新主重新挂载。这一步和第 9 步互斥;
替换集群名;
调用 PostMasterFailoverProcesses Hook;
集群重塑
执行计划中最为关键的就是 RegroupReplicasGTID (集群重塑)这一步,接下来我们继续分析 Orchestrator 的集群重塑;
集群重塑一共有三个主要工作:选主、复制检查、结构调整;
选主
同 DC、同物理环境检查
提升权限检查:must > prefer
副本有效性检查:检查副本是否开启 Binlog、检查副本是不是伪副本( Binlog Server)
提升权限被禁止检查:候选副本被禁止参与选主(被禁止包含:PromoteRule 禁止和配置文件中 PromotionIgnoreHostnameFilters 参数禁止)
版本检查:版本不低于集群中大多数版本
Binlog 格式检查:Binlog 格式不小于集群中的最大 binlog 格式(比较规则:ROW>MIX>STATEMENT)
复制检查
主要是执行有效从节点到新主节点的复制可行性检查,具体如下:
检查新主是否开启 Binlog 日志;
检查新主是否开启 log_slave_updates 参数;
从节点和主节点版本比较:从库是否比主库版本小、从库是否是 Binlog server;
从库在开启 Binlog 和 log_slave_updates 的情况下检查从库的 Binlog 格式是否低于新主;
排除被复制筛选掉的从节点(VerifyReplicationFilters 参数控制开关);
检查 sever id 是否相等;
检查 uuid 是否相等且不得为空;
检查是否从库 sqldelay < 新主 sqldelay 且主库 sqldelay > ReasonableMaintenanceReplicationLagSeconds 参数;
结构调整
结构调整主要分为三步:
StopReplication:1、从节点有效性检查;2、执行 stop slave;
ChangeMasterTo: 1、检查从节点 io 线程和 sql 线程是否停止;2、新主 hostname 解析;3、执行 change master to master_host=?, master_port=?;
StartReplication:执行 start salve;


