




BlazingSQL 是 RAPIDS 生态系统的 GPU 加速 SQL 引擎,BlazingSQL 为各种 ETL 大数据集提供 SQL 接口,并且完全运行在 GPU 之上。其前身是 BlazingDB。现在在 Apache 2.0 许可下 100% 开源!
RAPIDS 包含一组软件库(BlazingSQL、cuDF、cuML、cuGraph),用来在 GPU 上执行端到端的数据科学计算和分析管道。
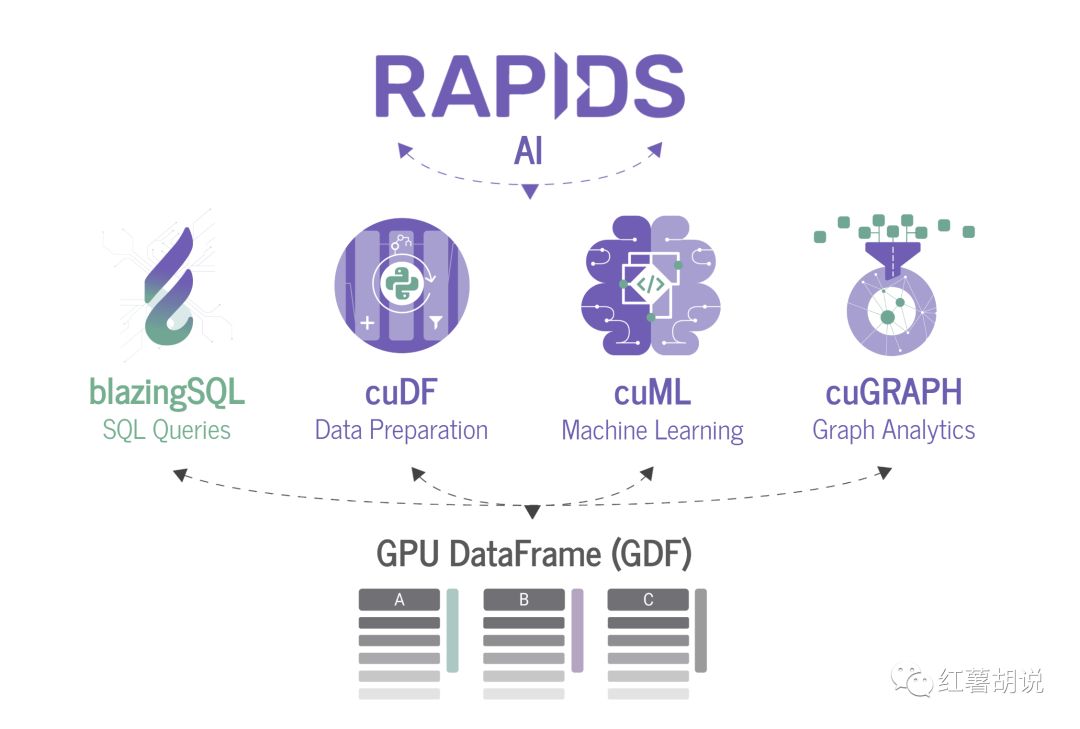
BlazingSQL是一个基于RAPIDS生态系统构建的GPU加速SQL引擎。RAPIDS基于Apache Arrow 柱状内存格式,cuDF是一个GPU DataFrame库,用于加载、连接、聚合、过滤和操作数据。
BlazingSQL是cuDF的SQL接口,具有支持大规模数据科学工作流和企业数据集的各种功能。
主要特性:
查询外部存储数据 - 单行代码可以注册远程存储解决方案,例如Amazon S3。
简单的SQL - 非常容易使用,运行SQL查询,结果是GPU DataFrames(GDF)。
互操作性 - 任何RAPIDS库都可以立即访问GDF以获取数据科学工作负载。
示例代码:
CVS 读取:
from blazingsql import BlazingContext
bc = BlazingContext()
# Create Table from CSV
bc.create_table('taxi', '/blazingdb/data/taxi.csv', delimiter= ',', names = column_names)
# Query
result = bc.sql('SELECT count(*) FROM main.taxi GROUP BY year(key)').get()
result_gdf = result.columns
#Print GDF
print(result_gdf)
JSON 处理:
from blazingsql import BlazingContext
import cudf
bc = BlazingContext()
# Load JSON into GPU DataFrame (GDF)
taxi_gdf = cudf.io.json.read_json('taxi.json')
# Create Table from GDF
bc.create_table('taxi', taxi_gdf)
# Query
result = bc.sql('SELECT count(*) FROM main.taxi GROUP BY year(key)').get()
result_gdf = result.columns
#Print GDF
print(result_gdf)
软件网址请点击“查看原文”
文章转载自红薯胡说,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
