




/01
背景
利用 kprobes 技术,用户可以定义自己的回调函数,然后在内核或者模块中很多函数中动态地插入探测点,当内核执行流程执行到指定的探测函数时,会调用该回调函数,用户即可收集所需的信息了,同时内核最后还会回到原本的正常执行流程。如果用户已经收集足够的信息,不再需要继续探测,则同样可以动态地移除探测点。因此 kprobes 技术具有对内核执行流程影响小和操作方便的优点。
可通过下面方法查询可使用kprobe的函数
1. bpftrace⬇️
bpftrace -l
2. 查看kallsyms⬇️
cat /proc/kallsyms
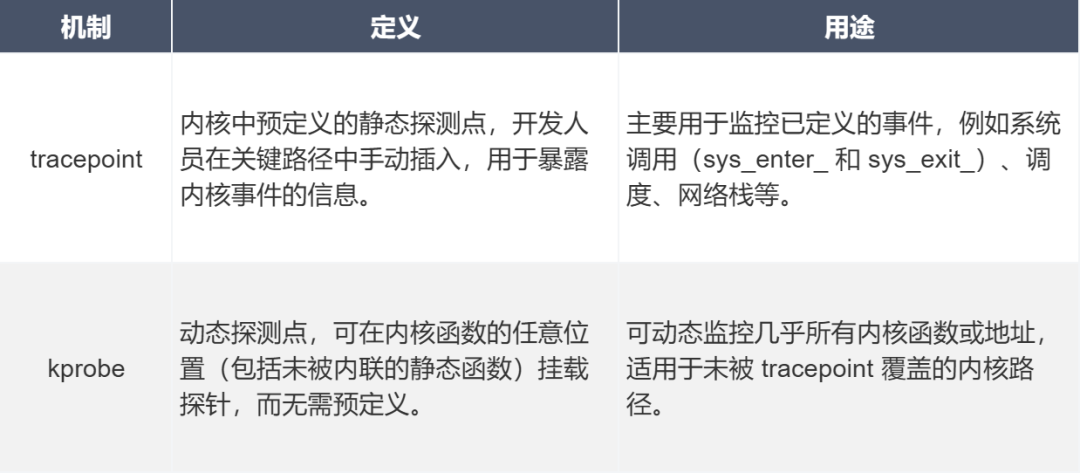
tracepoint 与 kprobe的区别
bpftrace简单验证
以跟踪系统调用为例,分别显示使用方式:
跟踪函数调用⬇️
bpftrace -e 'tracepoint:syscalls:sys_enter_execve
{ printf("PID %d called execve: %s\n", pid, str(args->filename)); print(args->argv) }'
跟踪exec返回结果⬇️
bpftrace -e 'tracepoint:syscalls:sys_exit_execve { printf("PID %d returned %d\n", pid, args->ret); }'
查询内核中sys_execve函数的定义如下⬇️
int sys_execve(const char *filename, char *const argv[], char *const envp[])
在bpftrace的输出中,args中tracepoint特有的参数,而filename是函数的输入变量。ret是返回值。
由于dsl语言不熟悉,只研究出来输出第一个argv⬇️
# 可以通过这个命令查看可用参数
bpftrace -lv tracepoint:syscalls:sys_enter_execve
bpftrace -e 'tracepoint:syscalls:sys_enter_execve { printf("PID %d called execve: %s\n", pid, str(args->filename)); print(str(*args->argv)) }
kprobe的用法有点不同⬇️
bpftrace -e 'kprobe:__x64_sys_execve { printf("do_fork called by PID %d\n", pid); }'
# 跟踪返回信息
bpftrace -e 'kretprobe:__x64_sys_execve { printf("do_fork called by PID %d\n", pid); }
由于bpftrace无法输出kprobe的参数,所以实际使用中,还需要使用ebpf来获取相关参数,才能完成跟踪定位。
当然,bcc有相关工具也是使用epbf跟踪kprobe,同样方便。本次只读使用go的ebpf包来实现相关功能:github.com/cilium/ebpf
/02
ebpf官方样例
github.com/cilium/ebpf/examples/kprobe
下有一个最简单的样例。
//go:build ignore
#include "common.h"
char __license[] SEC("license") = "Dual MIT/GPL";
struct bpf_map_def SEC("maps") kprobe_map = {
.type = BPF_MAP_TYPE_ARRAY,
.key_size = sizeof(u32),
.value_size = sizeof(u64),
.max_entries = 1,
};
SEC("kprobe/sys_execve")
int kprobe_execve() {
u32 key = 0;
u64 initval = 1, *valp;
valp = bpf_map_lookup_elem(&kprobe_map, &key);
if (!valp) {
bpf_map_update_elem(&kprobe_map, &key, &initval, BPF_ANY);
return 0;
}
__sync_fetch_and_add(valp, 1);
return 0;}
include common.h 包含了编译相关所需要的头文件信息,在headers目录下
定义了map kprobe_map用于保存执行exec的计数。
其中,key类型为uint32,值类型为uint64,最大元素个数为1。
因为key固定是0。
SEC("kprobe/sys_execve")定义了ebpf函数处理段
函数处理逻辑为:
从map中获取key=0的元素,如果未取到,则插入元素,值为1。
否则则更新元素,值加1
在main.go代码中定义了这个c程序的编译方式⬇️
go run github.com/cilium/ebpf/cmd/bpf2go bpf kprobe.c -- -I../header
通过这个命令,将c代码转换成go代码,由main.go来调用。
go的代码相对比较简单,就是加载kprobe函数,然后每秒获取一次map中的值,并输出打印。
/03
ebpf使用ringbuf传递数据
ringbuf为每个cpu上预留的缓冲区,由于每个cpu都有各自的缓冲区,所以不需要加锁。由于是环形结构,缓冲区的大小固定,当缓冲区写满后会覆盖旧数据。是个很高效的内核态与用户态交互方式。
上面的样例中,只是统计计数,并不知道是哪些进程在调用,有效的信息太少。
在 github.com/cilium/ebpf/examples/ringbuffer 中,就有相关样例,可以输出调用的进程名相关信息。
//go:build ignore
#include "common.h"
char __license[] SEC("license") = "Dual MIT/GPL";
struct event {
u32 pid;
u8 comm[80];
};
struct {
__uint(type, BPF_MAP_TYPE_RINGBUF);
__uint(max_entries, 1 << 24);
} events SEC(".maps");
// Force emitting struct event into the ELF.
const struct event *unused __attribute__((unused));
SEC("kprobe/sys_execve")
int kprobe_execve(struct pt_regs *ctx) {
u64 id = bpf_get_current_pid_tgid();
u32 tgid = id >> 32;
struct event *task_info;
task_info = bpf_ringbuf_reserve(&events, sizeof(struct event), 0);
if (!task_info) {
return 0;
}
task_info->pid = tgid;
bpf_get_current_comm(&task_info->comm, 80);
bpf_ringbuf_submit(task_info, 0);
return 0;
}
先定义event结构,表示往ringbuf中写入的数据结构。
定义eventsmap,用于保存event
从ringbuf中申请一块空间,用于保存数据bpf_ringbuf_reserve
结构体赋值后,提交bpf_ringbuf_submit,用户态就可读取
go代码中读取方式比较简单,这里不做过多分析
两种数据交互方式对比:
BPF_MAP_TYPE_RINGBUF
VS BPF_MAP_TYPE_PERF_EVENT_ARRAY
由于 cilium monitor
中输出的调试信息统一都是使用BPF_MAP_TYPE_PERF_EVENT_ARRAY
,所以针对这两种结构做个简单对比。
1.BPF_MAP_TYPE_RINGBUF
传递的数据结构单一,且在定义map时需要指定元素大小,会预占内存。
2.BPF_MAP_TYPE_PERF_EVENT_ARRAY
定义时,key为cpu的序号,value是不需要的(这个特殊的map,key与value都可以不定义)。总个数为cpu的个数。占用的资源固定。信息体统一放在ringbuf上,会复写。比如下面为cilium的 events 的定义。
3. 在 github.com/cilium/ebpf/examples/uretprobe 中有关于BPF_MAP_TYPE_PERF_EVENT_ARRAY
的样例,可作为参数。
/05
实现tcp重传跟踪
在bcc中用这个工具: /usr/share/bcc/tools/tcpretrans 可用于跟踪tcp重传。因为tcp出现网络异常,肯定会触发内核重传数据包,所以这个指标可作为网络监控手段。
由于python不太熟悉,所以准备使用go语言来实现同样功能。相关ebpf c代码可直接参考bcc。
//go:build ignore
#include "vmlinux.h"
#include "bpf_helpers.h"
//#include "common.h"
#include "bpf_endian.h"
#include "bpf_tracing.h"
#define AF_INET 2
char __license[] SEC("license") = "Dual MIT/GPL";
struct {
__uint(type, BPF_MAP_TYPE_PERF_EVENT_ARRAY);
} events SEC(".maps");
struct ipv4_data_t {
u32 pid;
u64 ip;
u32 seq;
u32 saddr;
u32 daddr;
u16 lport;
u16 dport;
u64 state;
u64 type;
};
//struct ipv4_data_t *unused_event __attribute__((unused));
//int tcp_retransmit_skb(struct sock *sk, struct sk_buff *skb, int segs);
SEC("kprobe/tcp_retransmit_skb")
//int BPF_KPROBE(kprobe__tcp_retransmit_skb, struct sock *sk, struct sk_buff *skb)
//{
int kprobe__tcp_retransmit_skb(struct pt_regs *ctx) {
// struct sock *sk;
// sk = (struct sock *)PT_REGS_PARM1(ctx);
// struct sock *sk;
// sk = (struct sock *)PT_REGS_PARM1_CORE(ctx);
// if (sk->__sk_common.skc_family != AF_INET) {
// return 0;
// }
struct ipv4_data_t ipinfo={};
// ipinfo.saddr = sk->__sk_common.skc_rcv_saddr;
// ipinfo.daddr = sk->__sk_common.skc_daddr;
// ipinfo.dport = bpf_ntohs(sk->__sk_common.skc_dport);
// ipinfo.lport = sk->__sk_common.skc_num;
bpf_perf_event_output(ctx, &events, BPF_F_CURRENT_CPU, &ipinfo, sizeof(ipinfo));
return 0;
}
通过上面代码,只实现了kprobe的注入,但无法获取地址信息。由于PT_REGS_PARM1_CORE(ctx)获取参数一直报错⬇️
program kprobe__tcp_retransmit_skb: load program: permission denied: 1: (69) r2 = *(u16 *)(r2 +16): R2 invalid mem access
暂时未找到解决方案。当我不获取参数时,是能在重传发生时接收到相关信息的。(通过其它工具辅助)
查询原因过程中,发现针对tcp重传有更方便跟踪的方法:tracepoint/tcp/tcp_retransmit_skb
tracepoint为基于内核进行二次封装后的实现,跟踪更为方便。
而且参数结构查询非常方便:
cat sys/kernel/debug/tracing/events/tcp/tcp_retransmit_skb/format 因为不同版本的内核,查出的结果会有不同。
我是基于4.18的内核,结构体大小为68字节。发现5.10版本多了一个字段,是72字节。
cat /sys/kernel/debug/tracing/events/tcp/tcp_retransmit_skb/format
name: tcp_retransmit_skb
ID: 1248
format:
field:unsigned short common_type; offset:0; size:2; signed:0;
field:unsigned char common_flags; offset:2; size:1; signed:0;
field:unsigned char common_preempt_count; offset:3; size:1; signed:0;
field:int common_pid; offset:4; size:4; signed:1;
field:const void * skbaddr; offset:8; size:8; signed:0;
field:const void * skaddr; offset:16; size:8; signed:0;
field:__u16 sport; offset:24; size:2; signed:0;
field:__u16 dport; offset:26; size:2; signed:0;
field:__u8 saddr[4]; offset:28; size:4; signed:0;
field:__u8 daddr[4]; offset:32; size:4; signed:0;
field:__u8 saddr_v6[16]; offset:36; size:16; signed:0;
field:__u8 daddr_v6[16]; offset:52; size:16; signed:0;
print fmt: "sport=%hu dport=%hu saddr=%pI4 daddr=%pI4 saddrv6=%pI6c daddrv6=%pI6c", REC->sport, REC->dport, REC->saddr, REC->daddr, REC->saddr_v6, REC->daddr_v6
基于上面的结构,编写的ebpf程序如下:
//go:build ignore
#include "vmlinux.h"
#include "bpf_helpers.h"
//#include "common.h"
#include "bpf_endian.h"
#include "bpf_tracing.h"
#define AF_INET 2
#define AF_INET6 10
struct event {
__u64 timestamp;
__u32 pid;
__u16 sport, dport;
__u8 saddr[4], daddr[4];
__u8 saddr_v6[16], daddr_v6[16];
__u16 family;
int state;
};
//基于文件生成结构 cat /sys/kernel/debug/tracing/events/tcp/tcp_retransmit_skb/format
struct tcp_retransmit_skb_ctx {
__u64 _pad0;
void *skbaddr;
void *skaddr;
// int state;
__u16 sport;
__u16 dport;
// __u16 family;
__u8 saddr[4];
__u8 daddr[4];
__u8 saddr_v6[16];
__u8 daddr_v6[16];
};
struct {
__uint(type, BPF_MAP_TYPE_PERF_EVENT_ARRAY);
} events SEC(".maps");
SEC("tracepoint/tcp/tcp_retransmit_skb")
int tracepoint__tcp__tcp_retransmit_skb(struct tcp_retransmit_skb_ctx *ctx)
{
struct event event = {};
event.timestamp = bpf_ktime_get_ns();
event.pid = bpf_get_current_pid_tgid() >> 32;
event.sport = ctx->sport;
event.dport = ctx->dport;
// event.family = ctx->family; // IP family - added this coz of IPv6.
// event.state = ctx->state; //TCP state
event.family=AF_INET;
// for debug
__bpf_printk("get family %d: %d->%d. \n", event.family, event.sport, event.dport);
// if (event.family == AF_INET) {
bpf_probe_read(event.saddr, sizeof(event.saddr), ctx->saddr);
bpf_probe_read(event.daddr, sizeof(event.daddr), ctx->daddr);
// } else if (event.family == AF_INET6) {
bpf_probe_read(event.saddr_v6, sizeof(event.saddr_v6), ctx->saddr_v6);
bpf_probe_read(event.daddr_v6, sizeof(event.daddr_v6), ctx->daddr_v6);
// }
bpf_perf_event_output(ctx, &events, BPF_F_CURRENT_CPU, &event, sizeof(event));
return 0;
}
char LICENSE[] SEC("license") = "GPL";
go 代码比较简单,可基于ebpf中已有的样例参考,将结构体输出。执行效果如下,会输出重传结果。
go run .
2024/12/20 20:57:21 Waiting for events...
2024/12/20 20:57:27 pid 0,1970-04-09T15:47:38+08:00, 2,source: 10.10.80.176:22, dest: 119.119.0.1:43500
2024/12/20 20:57:34 pid 0,1970-04-09T15:47:45+08:00, 2,source: 10.10.80.176:22, dest: 119.119.0.1:43500
2024/12/20 20:57:36 pid 0,1970-04-09T15:47:47+08:00, 2,source: 10.10.80.176:22, dest: 119.119.0.1:43500
2024/12/20 20:57:41 pid 0,1970-04-09T15:47:52+08:00, 2,source: 10.10.80.176:22, dest: 119.119.0.1:43500
/06
后续
有了重传的ip、端口等信息,就可以基于这些信息生成prometheus指标,配置相应的告警,因为重传就肯定涉及网络访问异常,直接与业务相关。
本期作者丨沃趣科技产品研发部
版权作品,未经许可禁止转载
往期作品快速浏览:



