




本次分为两个部分。第一部分介绍一个目前很火的大语言模型新的推理框架SGLang。第二部分分享一些大模型推理幻觉的一些研究工作。
SGLang
SGLang是一个对标vLLM的大语言模型推理框架, 系统的整体架构如下图,分为前端和后端。 前端是对调用大语言模型的一些常用操作的抽象,提供一系列原语。 后端是具体的对推理过程的优化。 SGLang的两点主要的优化是RadixAttention和Structured output。在此基础之上,作为大模型推理的基础框架, 后续也有很多其他的系统优化工作是在SGLang框架上的。

下图是一个使用SGLang框架的示例。

Motivation
SGLang的两个主要的优化点是:
在不同的请求之间共享KV Cache,复用更多的计算结果,减少计算量以达到加速的效果。
针对约束解码的情况, 通过压缩的状态机减少模型推理生成的token, 实现加速效果。
Radix-Attention
基础的kvcache是针对单个请求的,不同请求之间的kvcache是独立的。 而在推理模型的实际使用中,不同的请求之前往往会有大量重复的前缀(例如,一些常用的prompt,以及在推理时通过一些搜索、枚举的方法提高模型能力的技术等)。 这就提供了更多的优化空间。 RadixAttention可以看成是将不同请求的kvcache当成字符串, 将所有的请求构建成一个trie树。 此时对于新请求的kvcache,就可以看成是在这个缓存好的trie树上找到它的最长前缀, 实现最大程度的kvcache复用。
由于kvcache需要消耗显存, 而我们的显存是有限的, 我们只能存储下有限大小的trie树。 类似系统中的缓存, RadixAttention也需要一些机制去维护这个大小受限的trie树,同时尽可能地使得后续的请求能命中缓存。 一个额外的约束是在这个树结构的缓存中, 只能逐出叶子结点的元素,因为kvcache缓存的都是前缀,只有连续的前缀才是有效的。
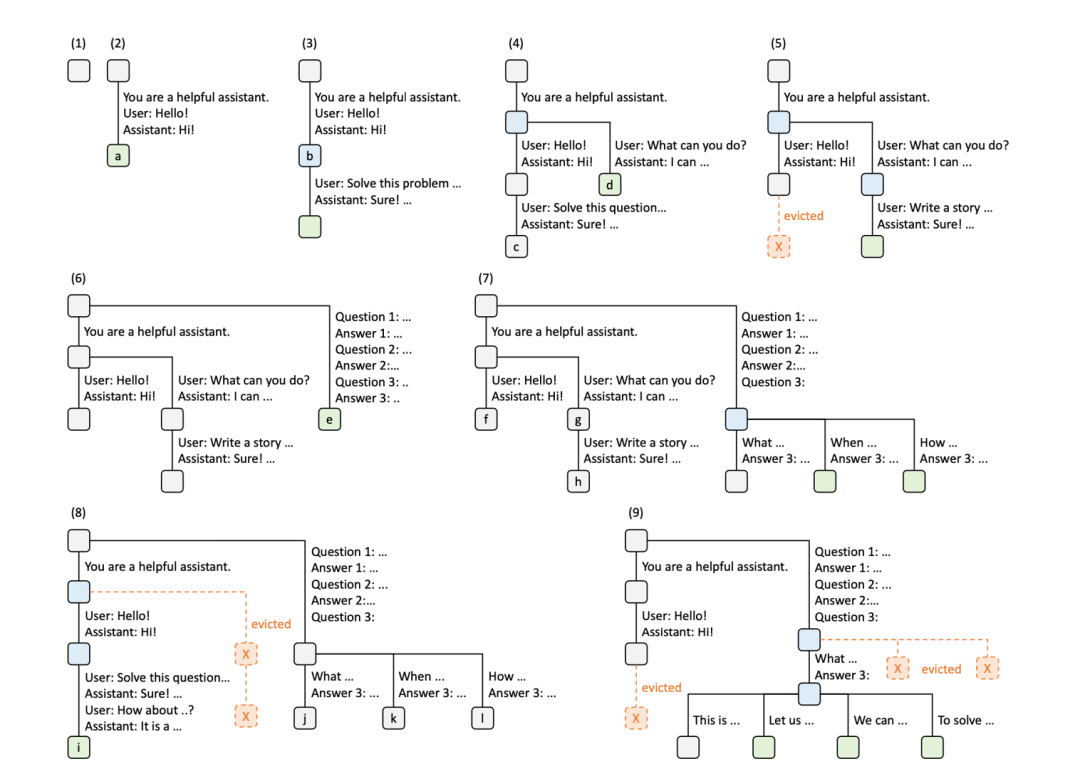
上图是维护radixattention的一个例子。 1~3是第一个请求多轮对话依次更新的过程。 4-5是处理第二个请求的过程。 前两个请求共享同样的system prompt "You are a helpful assistant." 在处理的时候查RadixAttention即可得到这个system prompt的kvcache,不需要重复计算。 接下来的tokens和已经缓存的不同,需要重新计算,并得到一个新的分叉。 注意到在5中, 生成的kvcache超出了存储空间的限制,开始执行缓存更新策略,逐出最不常用的叶子节点C。
6-8是三个新请求,这三个请求之前共享一样的前缀Question1、Question2, question 3不一样。在处理6的请求的时候处理完了question1~question3, 后续的7、8中新增的两个请求只有qestion3不一样,因此前两个question的处理结果可以复用,只需要分别prefill一个question 3即可。然后因为空间的限制,需要逐出之前的kvcache。 9是四个在6中的请求的基础上扩写生成answer的请求,前三个question都是一样的,因此都可以复用,只需要生成四个answer即可。
缓存更新策略
SGLang提出了一些启发式的方法在线地更新维护RadixAttention。 SGLang注意到对于离线的情况(提前知道后续的所有请求),最优解是存在的。 如果所有请求是同时到来的,那么只需要按照trie树的DFS顺序处理就是最优的。而对于在线的情况,这仍然是一个open problem。
Compressed Finite State Machine
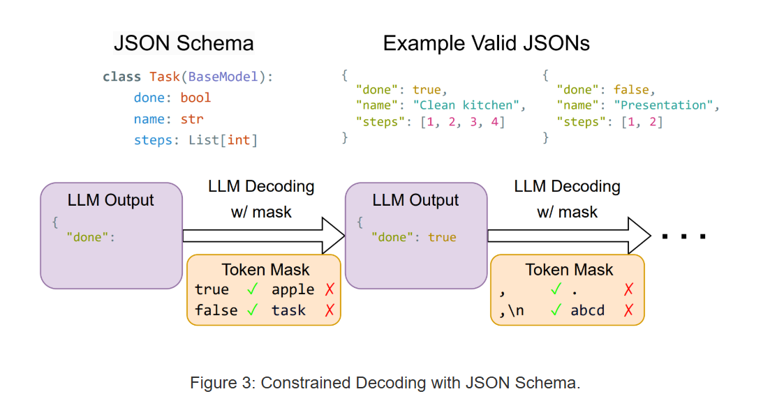
SGLang的另一个重点是结构化输出。 结构化输出是这样一类问题, 对于一些下游应用,我们希望模型的输出能完美的符合一些预定义的模式,方便下游程序处理。 例如希望模型的输出是JSON格式的,如下图。
常见的实现结构化输出的方法,是用有限状态机表达给定的格式约束。 对于状态机中的每一个状态,对应一个合法的token集合。 我们只需要在模型decode的过程中,根据模型的输出维护状态机的状态,得到当前状态下的合法token后,将这个约束强加在模型的输出分布上即可。
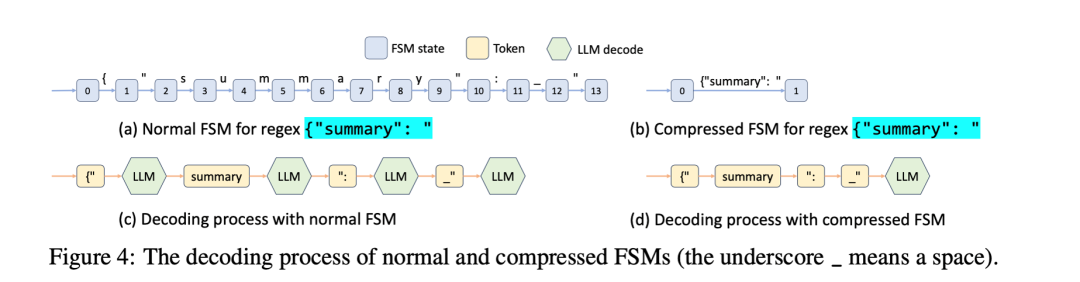
而这个过程还有进一步优化的空间。 注意到对于给定的约束,在很多的状态下,后续的可能结果都是唯一的。 比如在上图的例子中, json的第一个字段一定是{"summary": "
, 因此在模型输出{"
进入这个状态后,我们知道后续的输出一定是summary": "
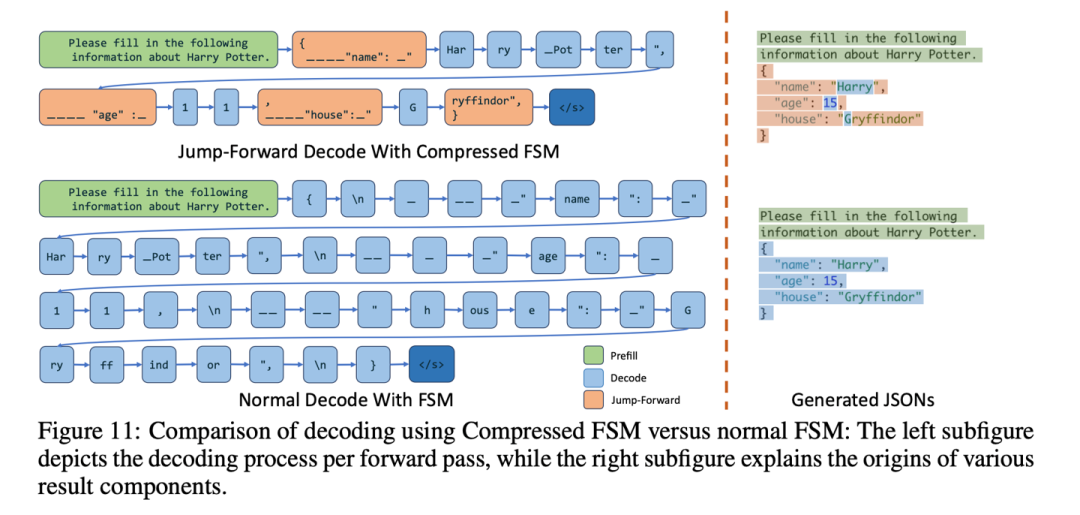
。此时我们就不需要让模型再自回归地一个token一个token地生成logits,然后再在结构化输出的约束下只能生成一个token。下图是压缩后的fsm和原始的fsm的一个对比。
SGLang的一些后续优化
这里再介绍SGLang的一系列后续优化中比较有意思的一个。
Lookahead Decoding
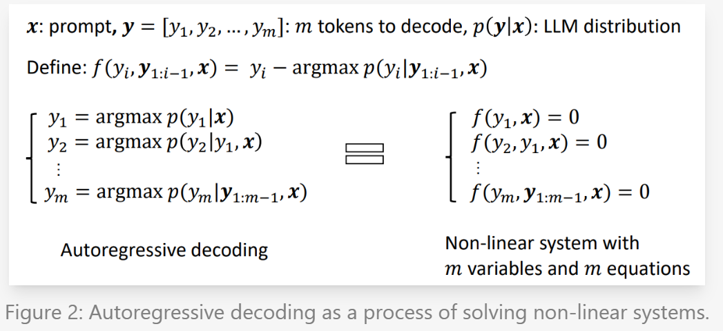
Lookahead Decoding是从Jacobi Decoding发展而来的一个并行解码技术。 Jacobi Decoding的核心思想是先用某种方式得到x的后续若干个token y的可能结果。 然后让模型把[x y]作为输出进行处理,然后用每个位置上的得到的logits更新y中的token,一直迭代直到所有token都被正确更新位置。 如果模型在一次处理的时候有多个token不需要被更新的话,那么就相当于一次推理生成了多个token。 因为prompt多几个token的推理开销是比较小的,在自回归过程中可以忽略不记,因此减少decode次数可以显著地加速模型的推理过程。
Lookahead Decoding注意到Jacobi Decoding是线性依赖的。 在推理过程中,如果上一步的y_k没有被接收,那么后续的所有生成结果都会被抛弃。 而在很多时候, 可能只是中间的某一个token生成错了,后面的一串token仍然是对的。 而这一部分正确的结果就直接被扔掉了,之后会需要再次计算得到之前已经得出过的结果。这一部分的计算是可以被省下来的。 Lookahead Decoding提出, 在中间一个token被拒绝后,其之后的token仍然以ngram的形式保留下来。 在后续的推理过程中, 如果哪一个之前保留的ngram被命中了,那么直接取这个ngram的结果为后续的生成结果,避免重复计算。
大模型幻觉
近期, 一些研究人员提出, 类似JSON的这类结构化输出指令,会导致大模型发生降智现象。 同时也有另外一批研究人员认为,前者的实验结果并不是大模型的效果不行,而是prompt水平不行。 大模型降智/犯错的一个常见原因被很多工作总结/称呼为幻觉,因此这里我也暂且这样称呼这一现象。 一些研究认为,大模型幻觉的一个可能的原因是,大模型的生成是自回归式的依次生成的,而每一个token都是在当前位置直接取最大似然估计得到的。这就导致大模型的输出可能每一步短视地看都很合理,但是在一个较长的上下文上就不正确了。 而在结构化输出中,每一步的结果都是被额外限制的,这很有可能会加剧前述的因素对模型效果的影响。 这里分享一些和模型幻觉、纠错有关的文章。
通过对比解码消除幻觉
大语言模型(LLMs)中的“幻觉”现象是指模型生成的内容与用户输入、先前上下文或既定事实相矛盾。
openai提出了TruthfulQA这个数据集。TruthfulQA是一项研究大型语言模型(LLMs)在生成答案时是否倾向于模仿人类错误或虚假信息的工作。该研究通过构建专门的数据集,测试模型在回答涉及常识错误、逻辑陷阱和偏见等问题时的表现,发现许多模型容易重复训练数据中的错误信息。TruthfulQA 揭示了模型在真实性上的局限性,并为进一步改进模型训练方法、提升答案可靠性提供了重要基准和方向。TruthfulQA发现, 随着参数量的增加,很多模型都在多数评估指标上达到了更好的效果。 但是这些模型仍然很可能给出一些错误的信息。 通过实现TruthfulQA发现那些在多数指标上表现更好的参数更多的模型,在这个数据集上表现会更差, 大模型在回答不了问题的时候更倾向于去生成一些看起来很对的答案。
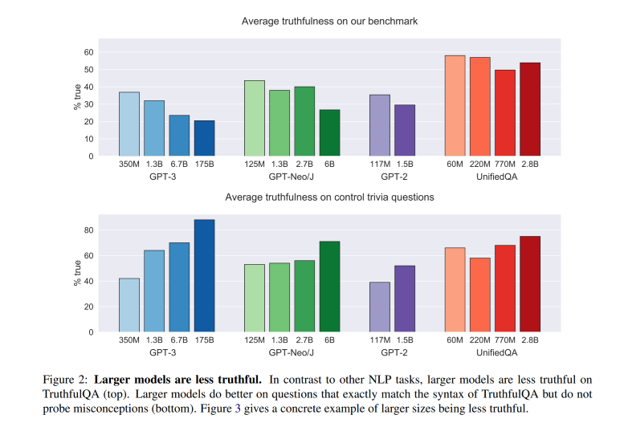
[4]这个工作提出用一种对比解码的方式提高模型生成可信结果的能力。 核心思想是, 构造一个很容易犯错的模型。 那么对于一个困难的任务,虽然原始模型很容易犯错,但是evil LLM更容易犯错,通过对比解码,只需要原始模型更不容易犯错,那么做差之后,那些错误结果的概率就会降低,此消彼长正确答案的概率就变高了,从而提高了模型回答正确的概率。
虽然在困难任务上, 原始模型比evil LLM强,更可能回答正确。 但是在一些基础能力上(比如输出文字的连贯性等), 这两个模型的能力可能没有什么差别,做差后很可能破坏模型的一些基础能力。 针对这个问题, 这个工作提出先取概率超过一个阈值的关键token,只在这些token上做对比解码。 这个筛选token的过程就能很大程度上保持模型的基础能力。
自我纠正是否能提升模型能力
对于模型回答错误的情况, 一些工作提出了模型生成答案-自我检查答案-纠正错误的范式,期望提高模型的能力。 这些工作认为相比对答对一个问题,验证一个答案是否正确更容易。类似在复杂度理论中P/NP的研究,目前很多人相信,能多项式时间验证的问题,并不一定能在多项式时间内解决。
[6]这篇工作指出,之前的很多self-correct的工作,指标的提升并不来自于自我纠正的生成范式,而是在检查验证先前的答案,提供反馈以纠正错误的时候,提供的反馈包含了更多的信息,因此提升了模型能力。 这个工作在三个较难的任务上实现了几种不同的范式,包括直接推理,用LLM进行检查验证,用一个可靠的经典方法检查验证;以及不同类型的反馈结果,包括只有一个正误,部分错误,全部的错误等等,组合而成多种推理范式,实验发现一个可靠的经典方法生成反馈能最大程度上地提高模型的表现, 相比而言用LLM生成的反馈对模型表现的提升有限。
通过重置提升模型生成的安全性
大模型的消除幻觉在一些关键领域至关重要, 例如一些安全相关的问题。 随着大语言模型的能力变得越来越强大,这些模型也更有潜力对社会造成实际的危害。 标准的解决安全问题的方法是针对特定的不安全的输入输出模式, 做一些后训练、对齐。 通过包括监督微调(SFT)和基于人类反馈的强化学习(RLHF)等技术,训练语言模型生成安全的响应,同时最大限度地减少不安全响应的可能性。
但是,[7]这篇指出,攻击的模式是无穷无尽的,无法对所有模式都进行对齐。 [7]认为模型识别出生成的内容是不安全的更容易一些。因此,引入了一个新的token [RESET],试图训练模型使得模型学习到这样一个能力: 生成到一半的时候,当模型认为当前生成的内容不安全的时候,生成一个reset,清空已经生成的内容,然后再生成安全的内容。 例如“我无法回答这个问题”。 实验发现一般只需要一次reset之后,模型就会生成安全的内容了。
[1] Zheng, Lianmin, et al. "Sglang: Efficient execution of structured language model programs." arXiv preprint arXiv:2312.07104 (2024).
[2] Fu, Yichao, et al. "Break the sequential dependency of llm inference using lookahead decoding." arXiv preprint arXiv:2402.02057 (2024).
[3] Tam, Zhi Rui, et al. "Let me speak freely? a study on the impact of format restrictions on performance of large language models." arXiv preprint arXiv:2408.02442 (2024).
[4] Zhang, Yue, et al. "Alleviating hallucinations of large language models through induced hallucinations." arXiv preprint arXiv:2312.15710 (2023).
[5] Lin, Stephanie, Jacob Hilton, and Owain Evans. "Truthfulqa: Measuring how models mimic human falsehoods." arXiv preprint arXiv:2109.07958 (2021).
[6] Stechly, Kaya, Karthik Valmeekam, and Subbarao Kambhampati. "On the self-verification limitations of large language models on reasoning and planning tasks." arXiv preprint arXiv:2402.08115 (2024).
[7] Zhang, Yiming, et al. "Backtracking improves generation safety." arXiv preprint arXiv:2409.14586 (2024).


欢迎关注北京大学王选计算机研究所数据管理实验室微信公众号“图谱学苑“
实验室官网:https://mod.wict.pku.edu.cn/
微信社区群:请回复“社区”获取
gStore官网:https://www.gstore.cn/
GitHub:https://github.com/pkumod/gStore
Gitee:https://gitee.com/PKUMOD/gStore

