




Apache Doris FE JVM 堆内存异常怎么办?
OOM?GC异常?
Don't worry.
结合实际案例咱们一起来分析。

背景:

1
FE 内存问题总结
OOM 导致 FE 宕机
情况1:FE 堆内存OOM,遇到类似问题可以先查看 fe.out ,里边会有如下打印,出现FE OOM的情况时,需要分析FE JVM堆内存的占用情况。

可以在内存高的时候可以通过jmap,搜集内存占用的信息:
jmap -heap pid (打印新生代/老年代/总的堆内存大小)jmap -histo pid (排查内存高问题最常用,打印内存中对象的统计柱状图,最下面有total instance/ total bytes)jmap -histo:live pid (排查内存高问题最常用, 功能同上,只是会触发一次full gc然后统计)jmap -dump:file=xxx.hprof pid (dump当前java进程镜像,最好压缩一下,后续可以用jprofiler和jmap进行分析)
情况2:操作系统OOM-Killer杀掉java 进程可能机器上其他进程占据了一些内存,导致FE获取不到jvm -Xmx 配置的堆内存,操作系统启动OOM-Killer 线程杀掉了FE。
如果遇到问题可通过如下命令查看:
dmesg -T | grep -i java (看下是否是被系统系统kill)free -h (可以看看系统整体的内存使用情况,合理配置-Xmx
2. 堆内存占用高,导致 FE Master 退出
堆内存占用高,遇到gc降级,master pause时间过长,导致fe直接挂了,尤其是高频导入情况下事务和loadjob占用内存多,其他follower 参与选举后,原master退出,重新选举出来的master节点重复出现该问题。
情况1:可能导入保存的相关信息太多了,比如历史label太多,可调整fe的label保留参数
label_keep_max_second = 14400
streaming_label_keep_max_second = 14400
情况2:可能是gc降级的问题,可以修改gc算法为g1
修改方式如下:
在fe.conf里面修改 JAVA_OPTS 这部分内容,新增或修改 -XX:+UseG1GC修改后,可通过jmap -heap pid 命令确认垃圾回收器已经改为g1举例:# G1 JAVA OPTSJAVA_OPTS="-Djavax.security.auth.useSubjectCredsOnly=false -Xss4m -Xmx8192m -XX:+UnlockExperimentalVMOptions -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:+PrintGCDateStamps -XX:+PrintGCDetails -Xloggc:$DORIS_HOME/log/fe.gc.log.$CUR_DATE -Dlog4j2.formatMsgNoLookups=true"-Xmx改成一致的,注意下CUR_DATE这个环境变量,在老版本可能叫DATE
3.低版本遇到问题列举(所举例子都是低版本遇到的一些问题,建议遇到后先行规避,后续尽快升级到社区建议版本)
问题1:SchemaChange Job数量多,导致 FE OOM (新版本已优化)
根据jmap文件分析,如果是schema change job比较多,可以尝试调小 history_job_keep_max_second


问题3:cms垃圾回收器不及时,待回收临时对象多,导致内存使用高,遇到gc降级导致fe挂了,内存监控使用量呈锯齿状(2.1 已改为G1 )
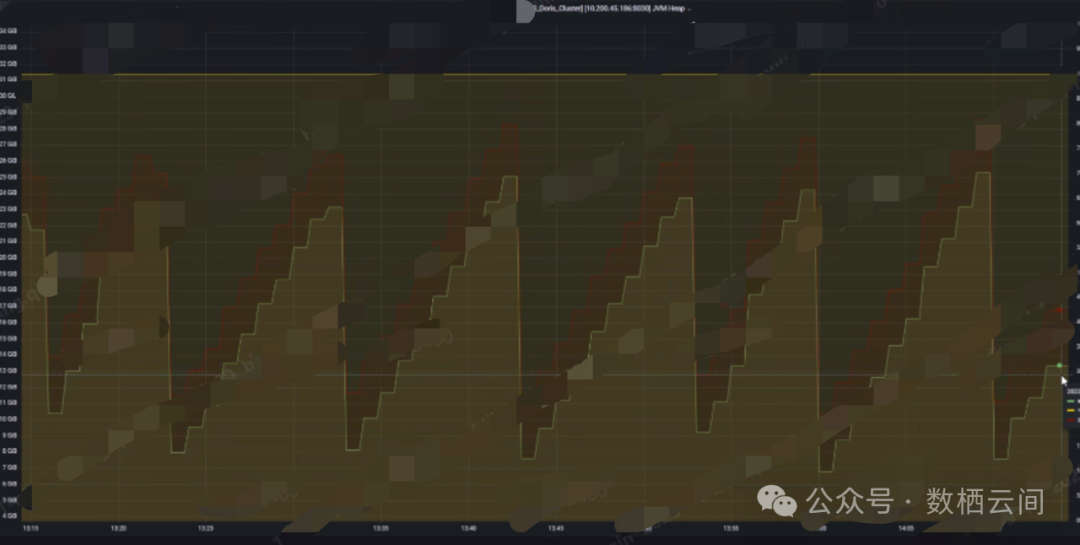
锯齿状参考上图,可以调整新生代的大小 8GB(根据实际内存合理调整)
锯齿状参考上图,可以调整新生代的大小 8GB(根据实际内存合理调整)在fe.conf里面JAVA_OPTS 修改jvm 参数-XX:CMSInitiatingOccupancyFraction=80 改成70(设置CMS垃圾收集器初始化标记阈值的百分比,默认80)-XX:NewSize=8G -XX:MaxNewSize=8G(设置新生代堆内存的初始大小为8GB,最大也为8GB
2
生产实际案例分析
1. 内存瞬间打满
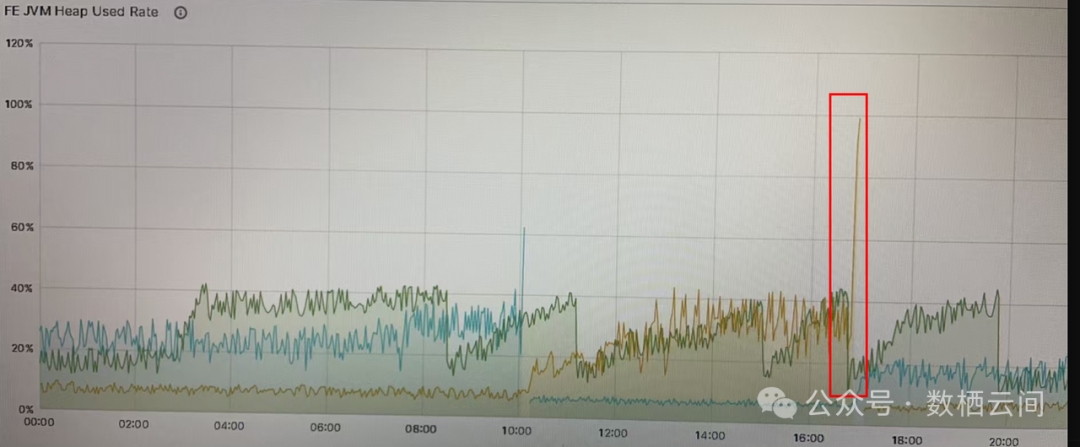
具体影响:
如果出现 JVM 内存瞬间打满的情况,可能会导致GC Pause时间长FE 出现卡顿的情况,同时有可能出现和其他Follower 通讯时间超过最大限制自动退出,甚至出现OOM 导致 FE 宕机。
事故背景:
Doris 版本:2.0.8
用户FE JVM 内存给到资源比较充足,但是业务上会偶尔会出现FE master 宕机的情况,但是没有OOM的日志,问题比较诡异。
排查问题所需基本信息:
fe问题时间段的相关日志信息(fe.log、fe.gc.log、fe.out)
JVM监控相关信息
jmap 信息
jmap -heap pid (打印新生代/老年代/总的堆内存大小)jmap -histo pid (排查内存高问题最常用,打印内存中对象的统计柱状图,最下面有total instance/ total bytes)jmap -histo:live pid (排查内存高问题最常用, 功能同上,只是会触发一次full gc然后统计)jmap -dump:file=xxx.hprof pid (dump当前java进程镜像,最好压缩一下,后续可以用jprofiler和jmap进行分析)
思路1: 首先确定是否OOM
确定OOM可以通过两种方式:
通过dmesg -T 看是否有OOM Killer触发的记录
[TIMESTAMP] Out of memory: Kill process [PID] ([PROCESS_NAME]) score [SCORE] or sacrifice child[TIMESTAMP] Killed process [PID] ([PROCESS_NAME]), UID [UID], total-vm:[VIRTUAL_MEMORY_SIZE]kB, rss:[RSS_SIZE]kB, swap:[SWAP_SIZE]kB
2. 在fe.out 中搜kill 关键字,如果有的话,那就是被kill 了
# -XX:OnOutOfMemoryError="kill -9 %p"# Executing bin/sh -c "kill -9 69489"...
思路2: 发现没有OOM,开始结合相关日志分析
3. 从fe.log 查看服务重启之前的日志,是否有什么异常日志,比如以下日志可以看到FE 其实是退出了
2024-11-05 07:01:38,147 WARN (MASTER 10.52.199.112_9010_1684148249610(3)|80) [Env.notifyNewFETypeTransfer():2421] notify new FE type transfer: UNKNOWN2024-11-05 07:01:38,147 INFO (stateListener|92) [Env$4.runOneCycle():2444] begin to transfer FE type from MASTER to UNKNOWN2024-11-05 07:01:38,147 ERROR (stateListener|92) [Env$4.runOneCycle():2521] transfer FE type from MASTER to UNKNOWN. exit2024-11-05 07:01:58,252 INFO (main|1) [DorisFE.start():142] Doris FE starting...
4. 接下来可以从GC 日志入手,分析GC日志。(这里可以直接用一些分析工具,比如:gceasy(https://gceasy.ycrash.cn/) 来进行分析 )通过分析GC 日志发现一个现象,在07:00:55 的时候,FE 内存突然打满到79.8G。从而导致 GC Pause 时间太长,导致 FE 超过心跳时间,无法选举,FE 退出了。
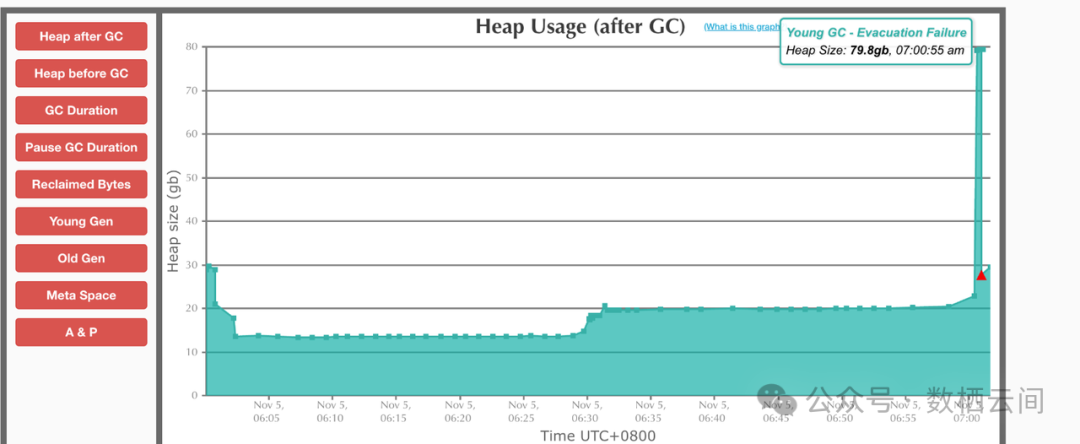
注意:如果有用户遇到这个情况,且后续不好排查的话,可以先调整心跳时间,不让FE 挂掉,但是会业务会卡顿一会。心跳时间参数:fe.conf bdbje_heartbeat_timeout_second
5. 出现这种情况,一般经验分析是有大的query导致的,可以在出问题的时间点抓一下,可以在fe.audit.log 中尝试抓下,看看有没有异常SQL。如果没有抓到异常SQL,那么就需要通过dump 进程镜像的方式来处理了。同时由于出现问题时间点不确定,需要在给FE加一些参数,在GC前和GC后分别取个dump文件,在dump文件的时候可能会导致master 卡顿,同时如果 FE 内存比较大,可能需要的空间比较多,GC前后都dump的话,可能需要放在足够的空间下。
如果要生成 JVM 的堆转储文件,可以使用以下参数启动JVM:-XX:+HeapDumpOnOutofMemorvError:当发生 00M 错误时,自动生成堆转储文件。-XX:HeapDumpPath=<path>:指定堆转储文件的输出路径。例如,-XX:HeapDumpPath=/path/to/dump.hprof上述问题加的参数如下:-XX:+HeapDumpAfterFullGC -XX:+HeapDumpBeforeFullGC -XX:HeapDumpPath=/path/to/dump.hprof
6.出问题后,将内存dump 出来后,可以通过 MAT(Memory Analyzer Tool) 或者 jprofiler 进行分析一波,或者将dump 文件发送给社区同学帮忙定位。MAT分析步骤不在这里赘述,可以通过官网查看工具使用方式(https://eclipse.dev/mat/),分析完成后会生成如下三个文件(注意这三个文件正在mat文件夹的平级目录存储)

7. 最后通过分析,发现用户提交了一个20多w行的query,导致FE JVM 现瞬时打满挂掉的情况。(由于用户侧信息比较敏感,不好展示)
处理方式:首先用户业务侧做下限制,不允许提交这么长的sql,其次这块有个限流的需求,后续会进行优化。
2. 内存逐渐升高不释放:
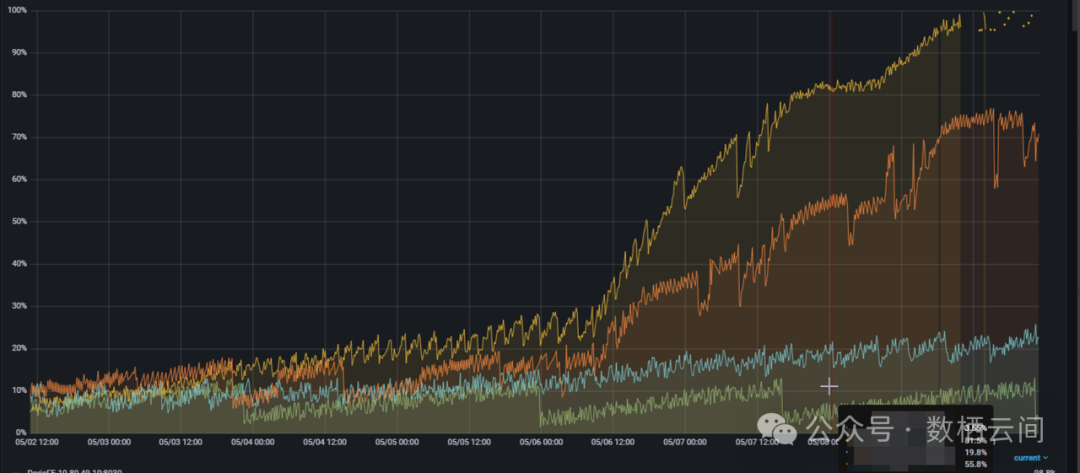
具体影响:
FE JVM 如果逐渐升高不释放的话,可能会出现GC的频率和停顿时间变长,会导致FE 响应变慢,从而影响业务,甚至出现OOM 导致服务宕机。
事故背景:
Doris 版本 2.0.9
用户生产环境中发现FE JVM 内存一直持续升高,且没有下降的趋势,用户比较担心内存一直不释放,影响到业务。
排查问题所需基本信息:
fe问题时间段的相关日志信息(fe.log、fe.gc.log、fe.out)
JVM监控相关信息
jmap 信息
排查思路
通过监控观察具体出问题的时间点。(因为一般问题不是持续存在的,一般是由于做了某些操作导致出现的这个问题。可以先从出问题的时间点入手,梳理下当时有没有做过什么操作,来缩小排查问题的范围。)
同步收集 jmap 信息,如下:
num #instances #bytes class name----------------------------------------------1: 176703170 9895377520 org.apache.doris.statistics.ColStatsMeta2: 181612143 8717382864 java.util.concurrent.ConcurrentHashMap$Node3: 178343719 5964429832 [C4: 178493980 5711807360 java.lang.String5: 184886611 4437278664 java.util.concurrent.atomic.AtomicLong6: 4122058 3511896496 [Ljava.util.concurrent.ConcurrentHashMap$Node;7: 4144245 431001480 java.util.concurrent.ConcurrentHashMap8: 4091062 392741952 org.apache.doris.statistics.TableStatsMeta9: 62019 192733880 [B10: 6052275 145254600 java.lang.Long11: 4091899 98205576 java.util.concurrent.......8830: 1 16 sun.util.locale.provider.AuxLocaleProviderAdapter$NullProvider8831: 1 16 sun.util.locale.provider.CalendarDataUtility$CalendarWeekParameterGetter8832: 1 16 sun.util.locale.provider.TimeZoneNameUtility$TimeZoneNameGetter8833: 1 16 sun.util.resources.LocaleData$LocaleDataResourceBundleControlTotal 929904444 39921563880
注意:有时通过以下信息定位不出问题,可以dump JVM 镜像,通过 jprofiler和 mat 工具进行分析。
3. 从 jmap 信息中可以清晰地看到:
Total bytes 39921563880 37G左右
org.apache.doris.statistics.ColStatsMeta和org.apache.doris.statistics.TableStatsMeta 占用比较多,疑似泄漏,需要进一步分析
4. 基本能够确定问题了(如果能到这里,可以直接将结果打包发给社区同学进行排查)
分析结果:
ColStatsMeta 对象是一列会对应一个,这有1.7亿个对象,说明表很多。
TableStatsMeta 对象是一张表对应一个,这里分析大概400多万个
但是用户反馈信息中并没有这么多表,于是排查发现用户有非常多的,Create/Drop Table的操作。
这种经常建表再删表的操作,会导致colstatsmeta的积累,就会有这个内存泄漏的问题。(2.0.15 已经修复)

结语

由于用户生产环境场景不同,所用的功能点和操作都不同,所以以上案例可以作为常规案例,如果有出现类似问题,可以先按照以上思路进行初步排查。有问题可以及时联系社区同学协助处理,防止生产出现事故







一臻数据致力于大数据AI时代的前沿内容分享,会持续分享更多有趣有用有态度的知识。同时也欢迎大家投稿,共建共进,帮助圈友们冲破认知壁垒,实现自我提升!
另外,整理了份《一臻数据知识库》,其中包含 Apache Doris 和 Data+AI 的学习资料、学习课程、白皮书、研究报告、行业标准 和 实践指南 等内容,会持续更新,欢迎关注公众号,免费领取。
资料获取 🔗 欢迎扫描下方二维码图片 备注【Doris】免费领取❗️

往期推荐

各位看官老爷,记得点个关注支持下哈!
