




3. RisingWave 其他使用场景
4. RisingWave 2.0 时代
编辑整理|李硕
内容校对|李瑶
RisingWave 介绍
1. 项目背景与基本信息
2. RisingWave 特点

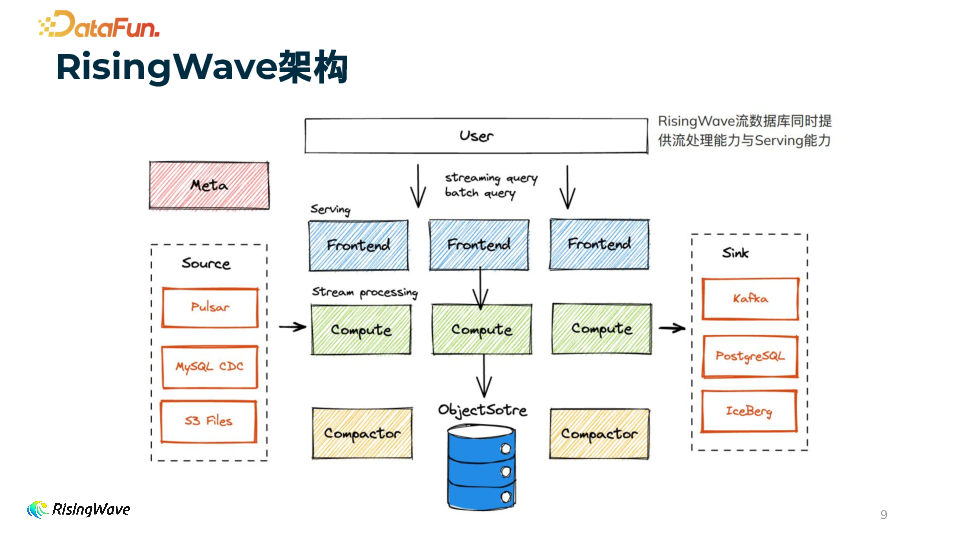
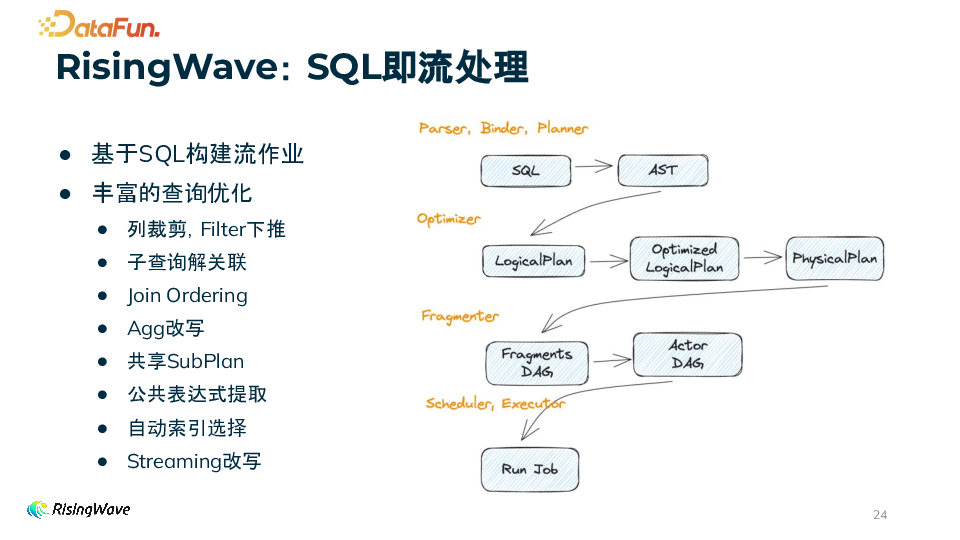
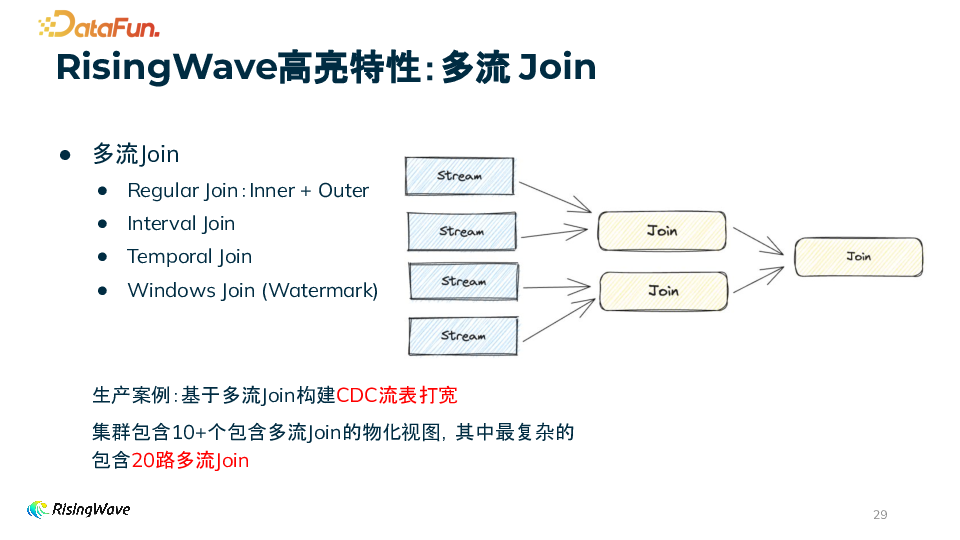
3. RisingWave 架构
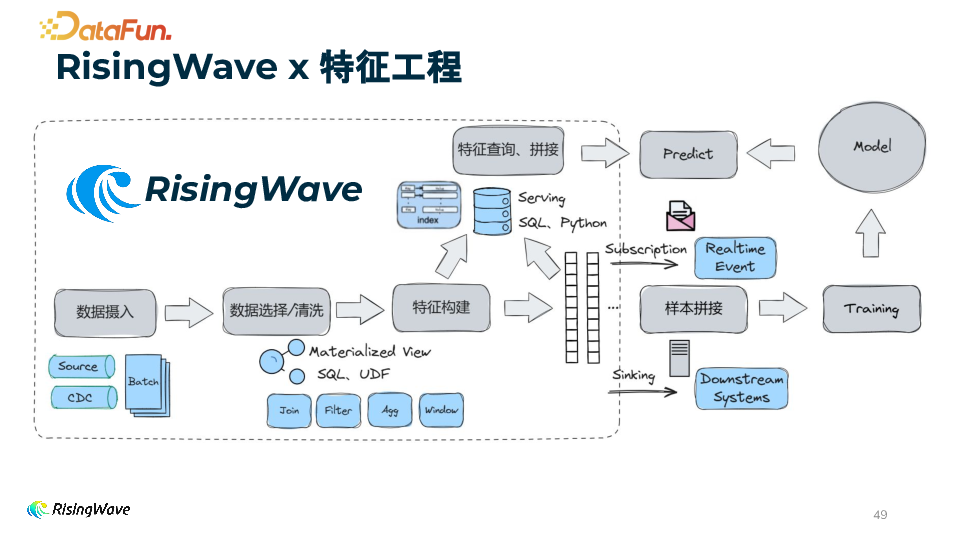
RisingWave 在实时特征工程中的应用
1. 特征工程步骤与链路
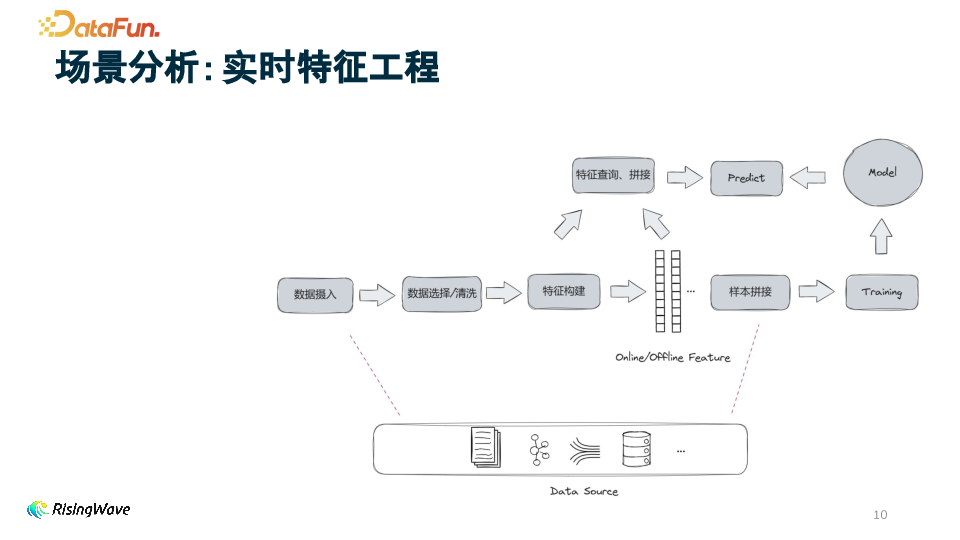
2. RisingWave 的助力
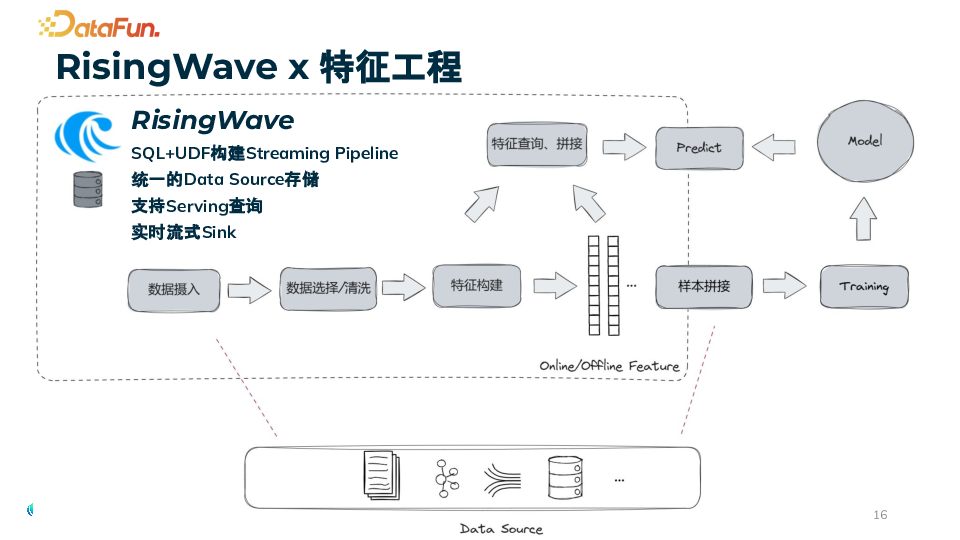
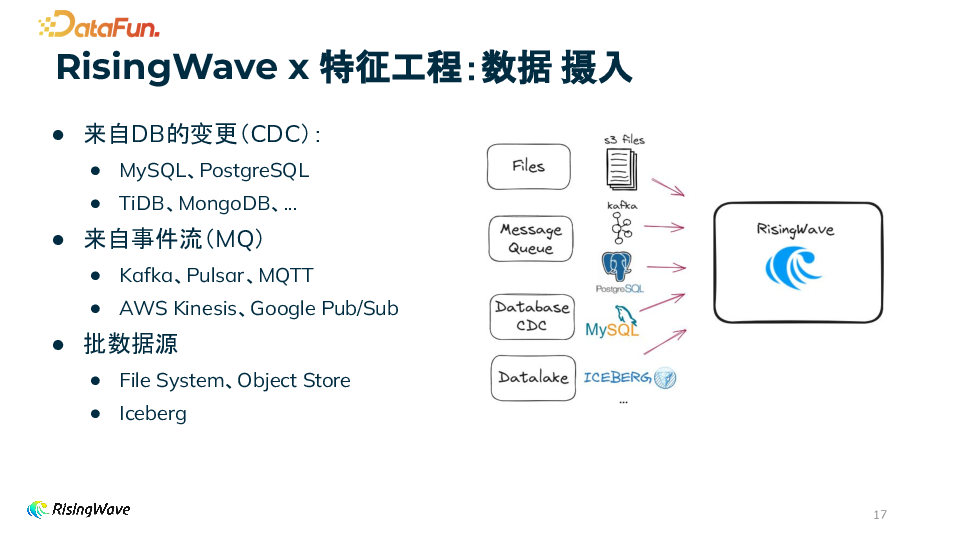
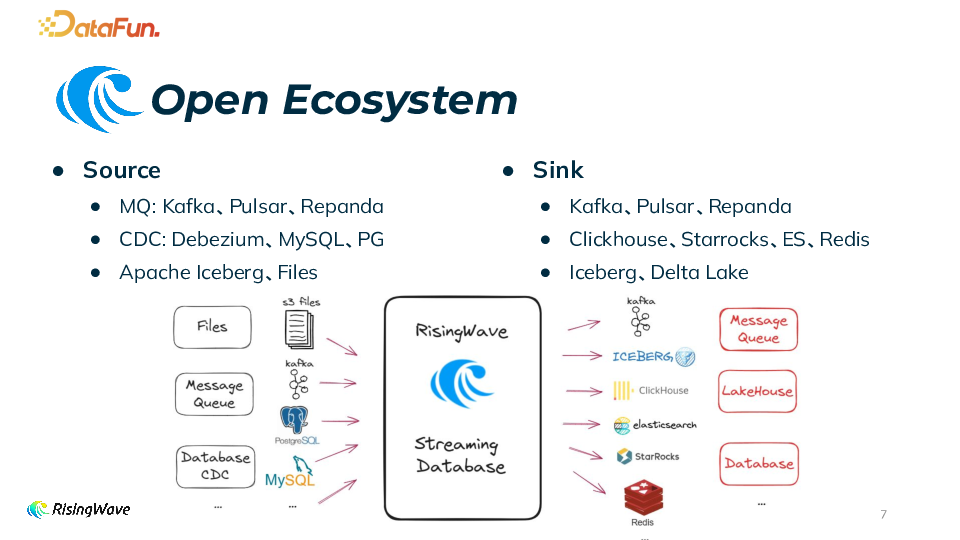
多样化数据源支持
消息队列(MQ):支持 Kafka、Pulsar、MQTT 等。
变更数据捕获(CDC):支持 MySQL、PostgreSQL、TiDB、MongoDB 等数据库的 CDC。
批处理数据源:支持 File System、Object Store、Iceberg 等。
消息编码支持
支持 AVRO、JSON、PROTOBUF、CSV、BYTES 等编码格式。
消息队列支持指定消费位置指定
支持从 Schema Registry 自动获取上游 Schema

数据源支持广泛
Table 可以消费所有 Source 支持的数据源,能够将各种来源的数据进行整合。
物化数据支持
将 Source 的数据物化到表,支持主键,便于数据的管理和查询。
上游 CDC 支持
支持常见的 OLTP 数据库(如 MySQL、PostgreSQL、Oracle、TiDB 等)和 NoSQL 数据库(如 MongoDB)的 CDC。
DML 支持
支持增删改查(DML)操作,方便对数据进行处理和维护。
消息格式支持
支持多种消息格式,如 PLAIN、DEBEZIUM、CANAL、MAXWELL、UPSERT 等,便于与不同系统进行数据交互。

离散化(Categorization)
可以使用 SQL 语句将数据离散化到多个桶中。例如,根据一定的条件将数据划分到不同的类别。
异常值处理(Filtering)
通过 WHERE 条件来处理异常值。例如,筛选出符合特定范围的数据,排除异常数据。
去重(Distinct On)
使用 DISTINCT ON 语句可以对指定列的数据进行去重操作,只保留一条记录。
缺失值处理(Coalescing)
利用 SQL 函数(如 LAG)来填补缺失值,使缺失值变为上一个有效值。

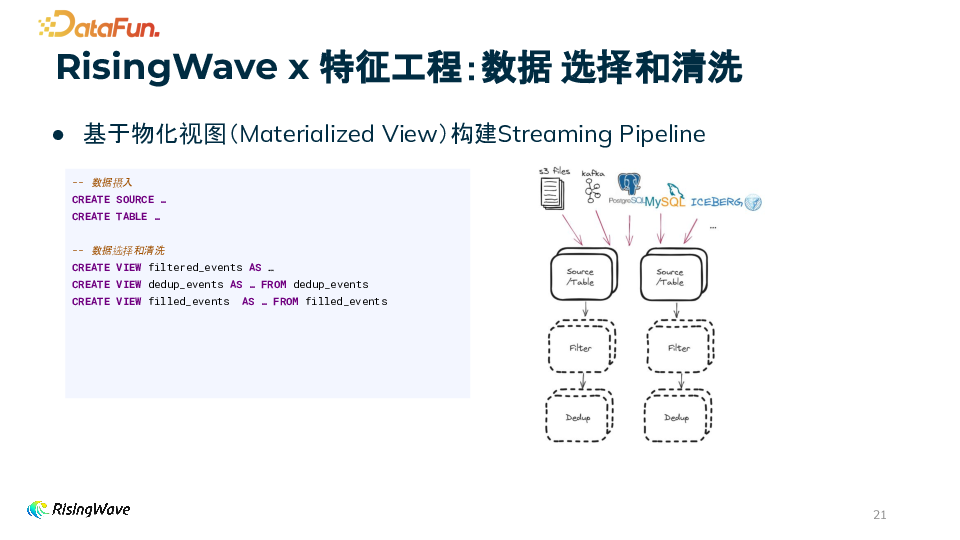
物化视图是一个增量实时维护流处理结果的抽象。当上游数据到来时,物化视图会自动、实时、同步地增量维护流处理的结果。
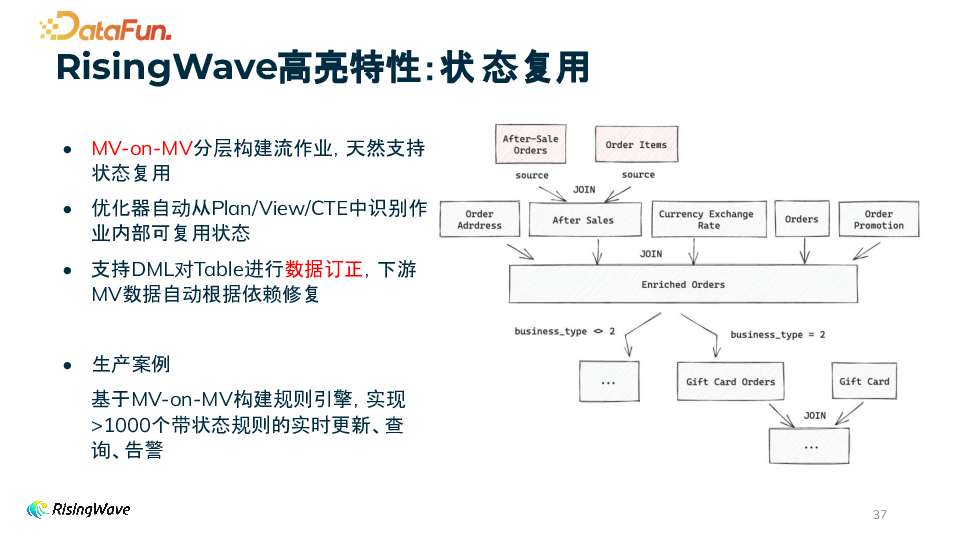
支持 MV - on - MV 构建层级化的流处理管道,可以堆叠物化视图来构建多层级的流处理流程。
物化视图支持丰富的 SQL 语法,包括 JOIN、窗口函数、子查询、分组等,还支持高级的流处理特性如 watermark,以及半结构化数据的处理函数。
物化视图的结果是实时可查询的,用户可以通过 SQL 查询来获取物化视图的结果,方便进行数据验证和调试。

通过 CREATE MATERIALIZED VIEW 语句实现,例如计算用户最近 30 天行为聚合统计,从清洗后的数据表(如 cleaned_events)中筛选出特定时间范围内(NOW() - INTERVAL '30 DAYS'到NOW())的数据,按用户 ID(user_id)和事件类型(event_type)进行分组,计算访问次数(COUNT())和最后访问时间(MAX(event_timestamp))。还可进一步计算如用户过去 30 天最常浏览的 Top2 商品类别,先按用户 ID 分区并按访问次数降序排序,然后选择排名前 2 的类别。

Hop Window 和 Tumble Window:如创建 2 分钟 hop 窗口聚合特征,从数据源(如 taxi_trips)中,以 completed_at 为时间字段,按 2 分钟间隔进行窗口聚合,计算行程数量(count(trip_id))和总距离(sum(distance))。同样,对于 2 分钟 tumble 窗口聚合特征,使用 TUMBLE 函数并设置相应参数实现。这些窗口计算为时间序列数据的分析提供了灵活的方式。

Session Window 与 Watermark:在源头表(如 user_views)上定义 5 分钟间隔的 watermark,用于处理乱序数据。然后创建 5 分钟 session 窗口聚合特征,按用户 ID 分区,以 viewed_at 为时间字段,计算每个会话的起始时间(first_value(viewed_at))和结束时间(last_value(viewed_at))。session 窗口能有效捕捉用户在一段时间内的连续行为,对于分析用户行为模式非常有用。

Inner Join 示例 计算用户过去一天内浏览的商品种类分布,通过 CREATE MATERIALIZED VIEW 将 user_clicks 表与 product_metadata 表进行 JOIN 操作,连接条件为 user_clicks.product_id = product_metadata.product_id,筛选出过去一天内的数据(user_clicks.event_time >= NOW() - INTERVAL '1 DAY'),按用户 ID 和商品类别分组,统计各类别浏览次数(COUNT())。 Outer Join 应用 可用于维度特征关联,如将 user_events 表分别与 product_info、store_info 和 user_info 表进行左外连接(LEFT OUTER JOIN),获取更丰富的用户行为相关信息,包括产品、店铺和用户自身的详细信息,为后续分析提供多维度数据。 Window Join 功能 实现窗口特征拼接,例如将两个以 completed_at 为时间字段、2 分钟间隔的窗口(TUMBLE (taxi_trips, completed_at, INTERVAL '2 MINUTES')和 TUMBLE (taxi_fare, completed_at, INTERVAL '2 MINUTES'))进行连接,连接条件为行程 ID(trip_id)和窗口起始时间(window_start)相等,按窗口起始时间排序,从而整合行程和费用相关的窗口特征,为分析出租车业务数据提供了全面的视角。

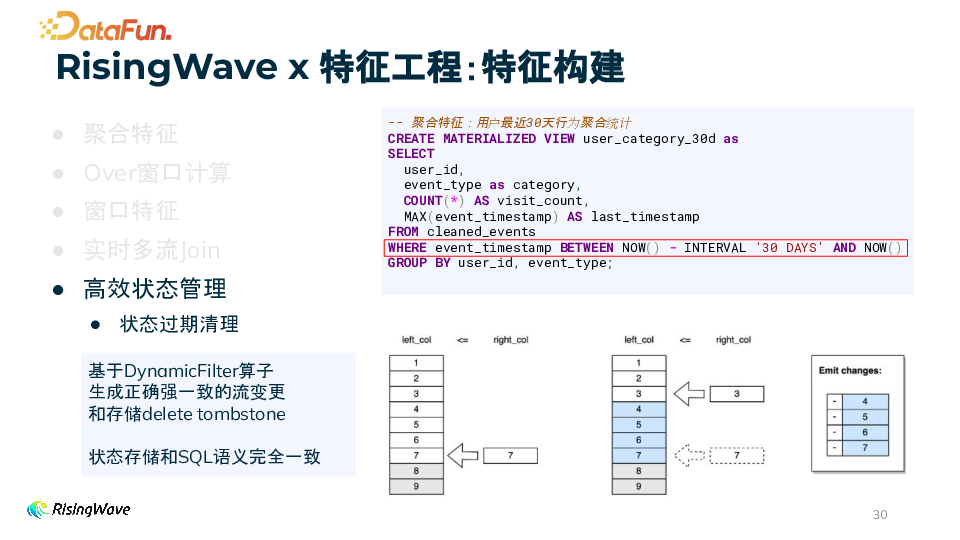
状态过期清理 基于 DynamicFilter 算子实现,能够生成正确强一致的流变更和存储 delete tombstone,确保状态存储和 SQL 语义完全一致。在处理如用户最近 30 天行为聚合统计等特征构建时,自动管理状态的过期,避免无效数据占用存储空间,保证数据的时效性和准确性。
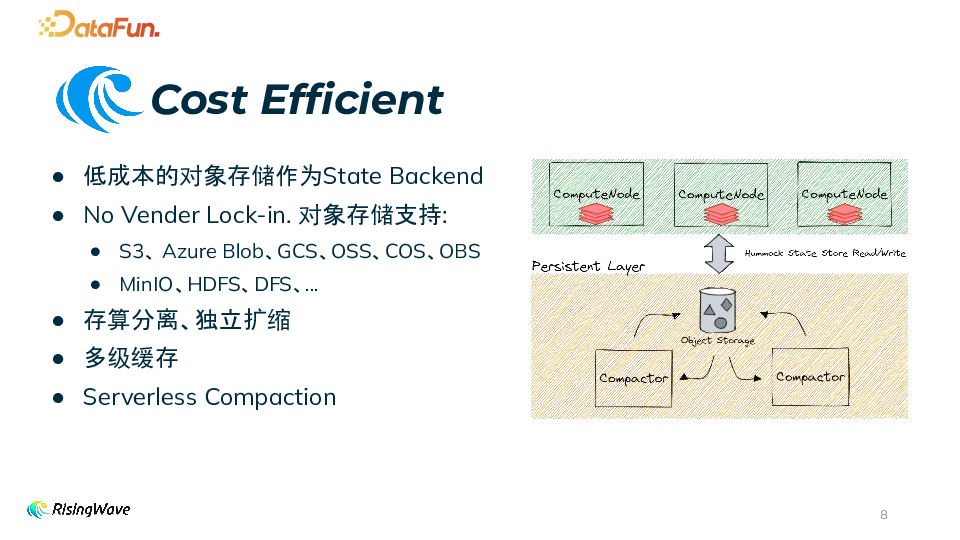
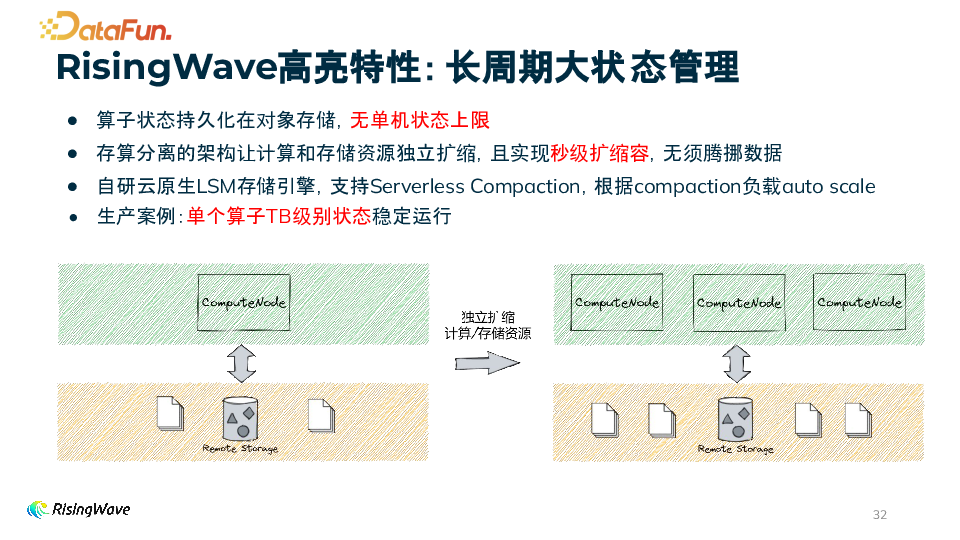
长周期大状态处理 算子状态持久化在对象存储,无单机状态上限。 基于存算分离架构可实现秒级扩缩容。 自研云原生 LSM 存储引擎。

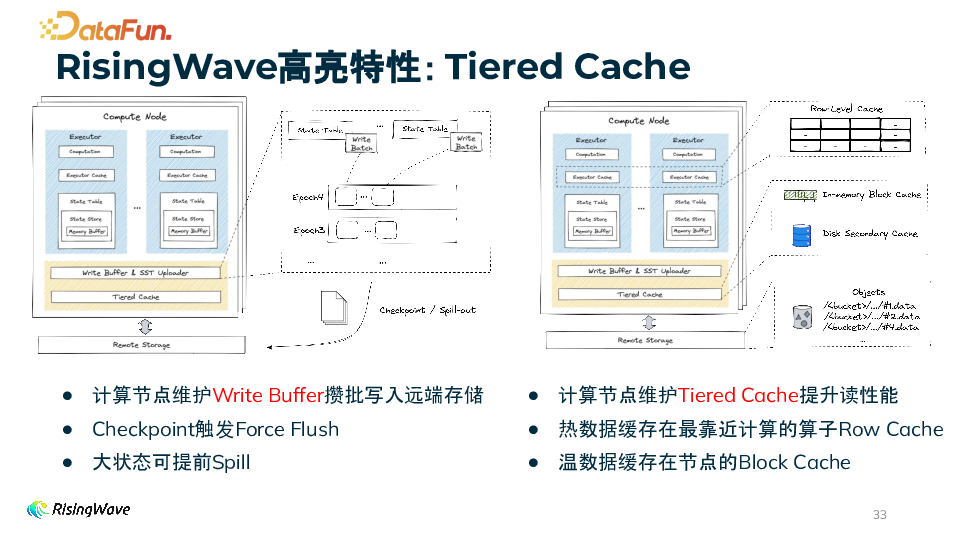
内部状态 SQL 可查 流算子内部状态抽象成关系型 State Table。 可以通过 SHOW INTERNAL TABLES 查看算子内部状态表,也可以通过 SQL 查询。 适用于排查线上数据问题、优化流作业 SQL、学习流算子的状态管理制等场景。

状态复用


可查询性 Materialized View 和 Table 均可查询,支持 Batch Query 和 Streaming Query。用户可以通过 SELECT 语句直接查询物化视图(如 user_feature)获取特征数据,例如查询特定用户 ID(user_id = 15213)的特征。这种查询方式方便快捷,能够满足不同场景下对特征数据的获取需求。 结果一致性与调试回溯 Streaming 和 Batch Query 结果一致,这一特性使得用户在开发和调试过程中更加便捷。用户在创建物化视图前可以先运行 Batch Query 来查看结果是否符合预期,进行数据验证和逻辑调试。如果发现问题,可以方便地回溯和排查,因为两种查询方式的结果具有一致性,保证了数据的可靠性和可追溯性。 支持创建索引加速 Serving 查询

索引创建与应用 支持在 Materialized View 和 Table 上创建索引来加速 Serving 查询。用户可以在 timestamp 列创建索引(如 CREATE INDEX idx_timestamp on user_feature(timestamp)),然后在查询时利用该索引加速对 timestamp 列的范围查询(如 SELECT FROM user_feature WHERE timestamp < NOW() - INTERVAL ‘1 days’)。通过创建合适的索引,可以显著提高查询性能,减少数据检索时间。 索引特性支持 支持指定 Include 列、Distributed 列,还支持表达式索引。例如,在 customers 表上创建索引加速点查(CREATE INDEX idx_c_phone on customer(c_phone)),在 orders 表上创建索引加速 JOIN 操作(CREATE INDEX idx_o_custkey ON orders(o_custkey)),以及在包含 JSONB 类型列的表上创建表达式索引。这些丰富的索引特性为优化查询提供了多种选择,适应不同的数据结构和查询需求。
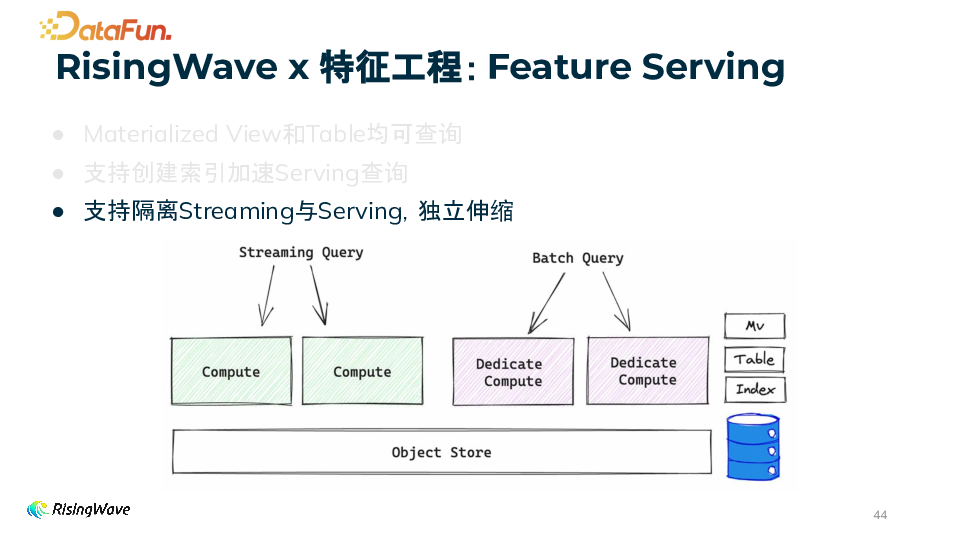
隔离 Streaming 与 Serving 支持隔离 Streaming 与 Serving,允许独立伸缩。这意味着用户可以根据实际需求分别调整 Streaming 和 Serving 的资源配置,优化系统性能。例如,在高并发查询场景下,可以为 Serving 分配更多的计算资源以满足查询需求,而不会影响 Streaming 的实时数据处理能力。 资源优化与灵活性 通过独立伸缩,用户可以更好地平衡系统资源的利用,提高系统的整体效率和稳定性。无论是处理大规模实时数据的摄入和处理(Streaming),还是应对高并发的特征查询(Serving),都能够灵活配置资源,确保系统在不同负载下的良好性能表现。
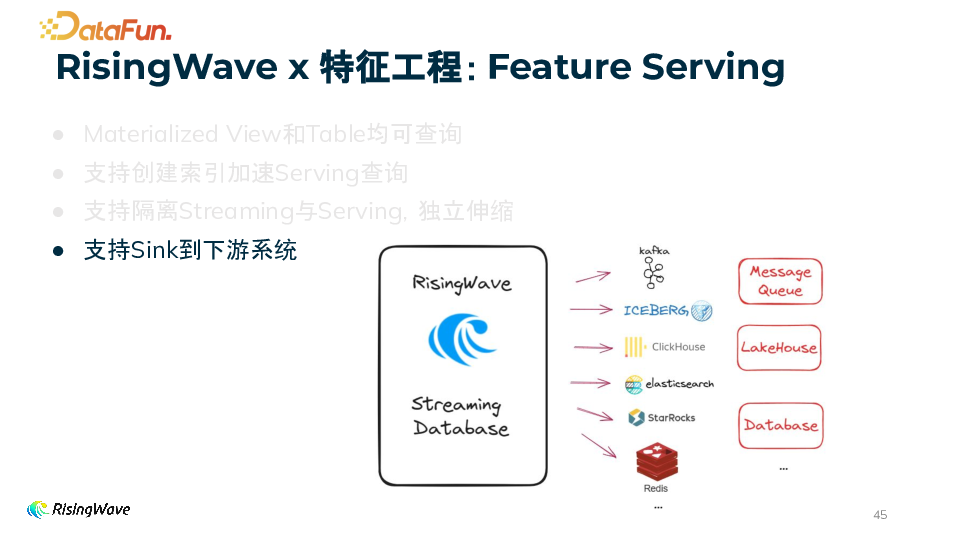
Sink 功能与支持的系统 通过 Sink 可以实时将数据发送到多种下游系统,支持的 Connector 包括 Redis、Kafka、JDBC、Clickhouse、StarRocks、Doris、ElasticSearch、Cassandra、File、Iceberg 等。用户可以根据实际业务需求选择合适的下游系统进行数据分发,实现数据的进一步处理和分析。 数据格式与输入源 支持多种数据格式,如 APPEND_ONLY、UPSERT、DEBEZIUM 等。Sink 的输入可以是 Table/Materialized View,也可以是 SQL query。



RisingWave 其他使用场景
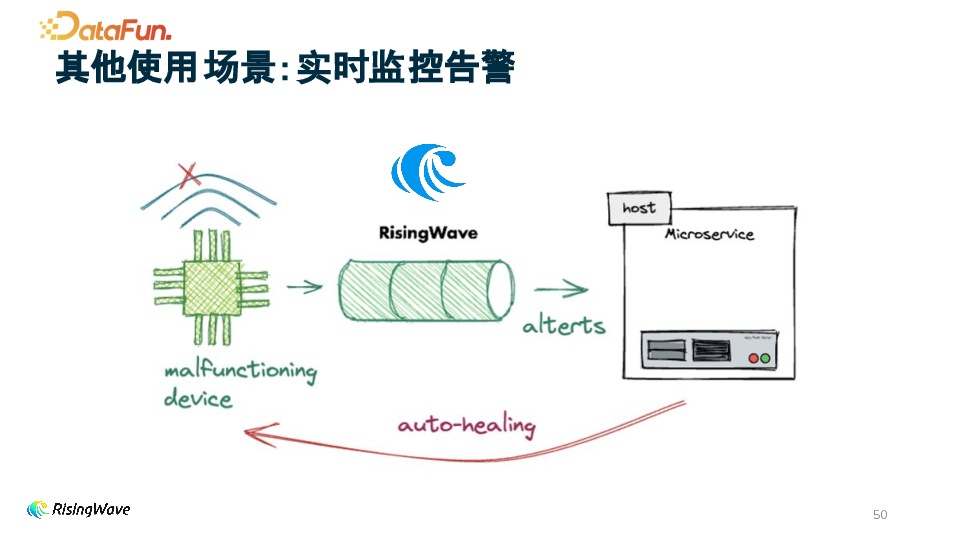
1. 实时监控告警
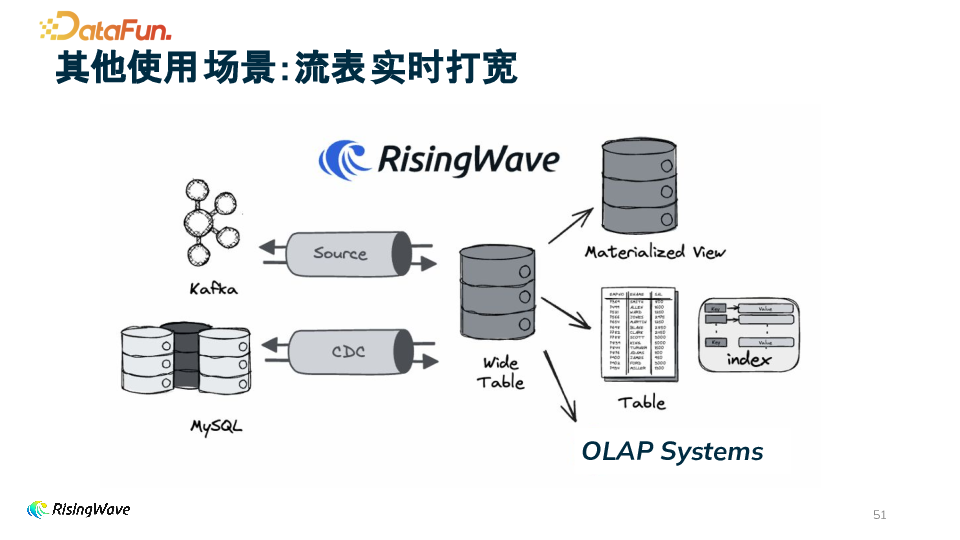
2. 流表实时打宽
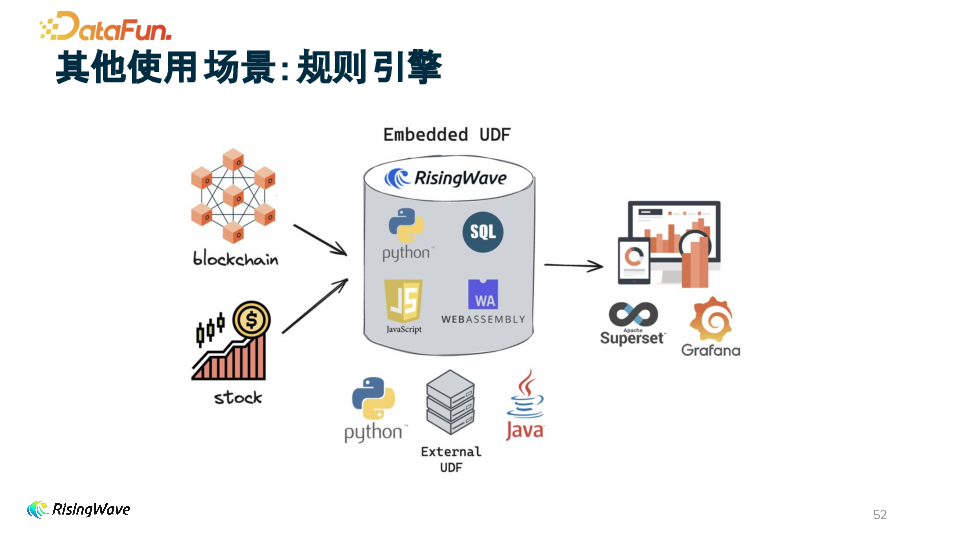
3. 规则引擎
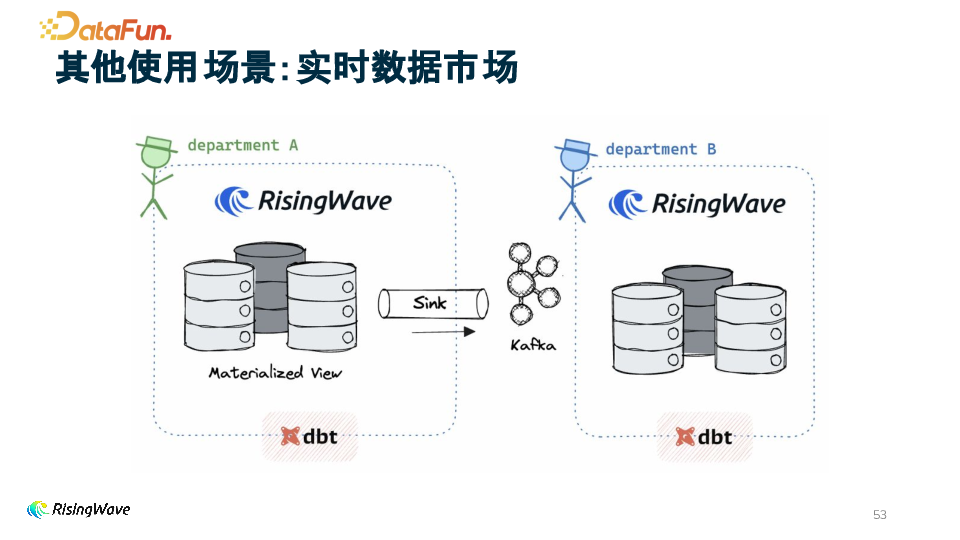
4. 实时数据市场
RisingWave 2.0 时代
关于 RisingWave


往期推荐
技术内幕
